开始日期:22.4.19
操作系统:Ubuntu20.0.4
Link:Lab COW
个人博客:Lab COW
目录- Lab COW
- 写在前面
- Virtual address
- 参考链接
- Copy-on-Write
- 总结
- 写在前面
-
关于虚拟地址的概念,一直不是很清晰,book-riscv-rev2中给出的概念是:虚拟地址是用来给xv6操作的地址
P26
The RISC-V page table translates (or “maps”) a virtual address (the address that an RISC-V instruction manipulates) to a physical address (an address that the CPU chip sends to main memory).
-
事实上,这个说法没有错,但虚拟地址是怎么来的却没有说清楚,于是我翻阅了Modern operating systems和Computer Systems. A Programmer’s Perspective 3rd Edition,查询了虚拟内存的章节,里面提到:
Modern operating systemsP195
...Addresses can be generated using indexing, base registers, segment registers, and other ways.
These program-generated addresses are called virtual addresses and form the virtual address space.
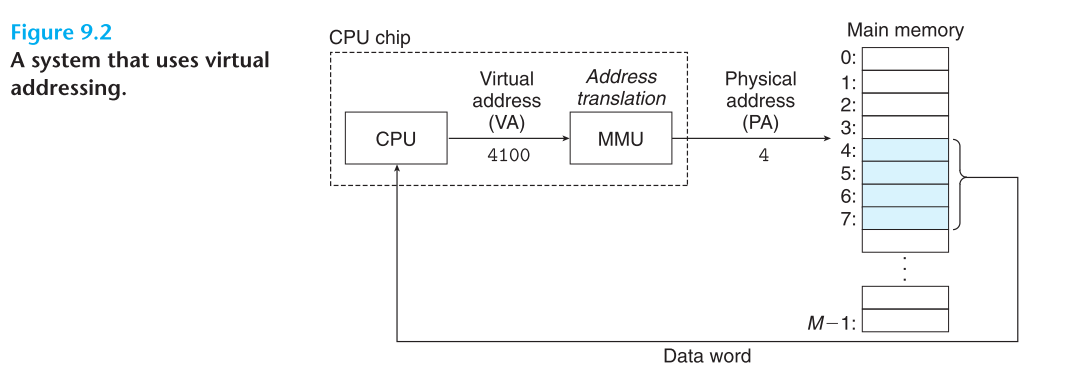
On computers without virtual memory, the virtual address is put directly onto the memory bus and causes the physical memory word with the same address to be read or written. When virtual memory is used, the virtual addresses do not go directly to the memory bus. Instead, they go to an MMU (Memory Management Unit) that maps the virtual addresses onto the physical memory addresses, as illustrated in Fig. 3-8.
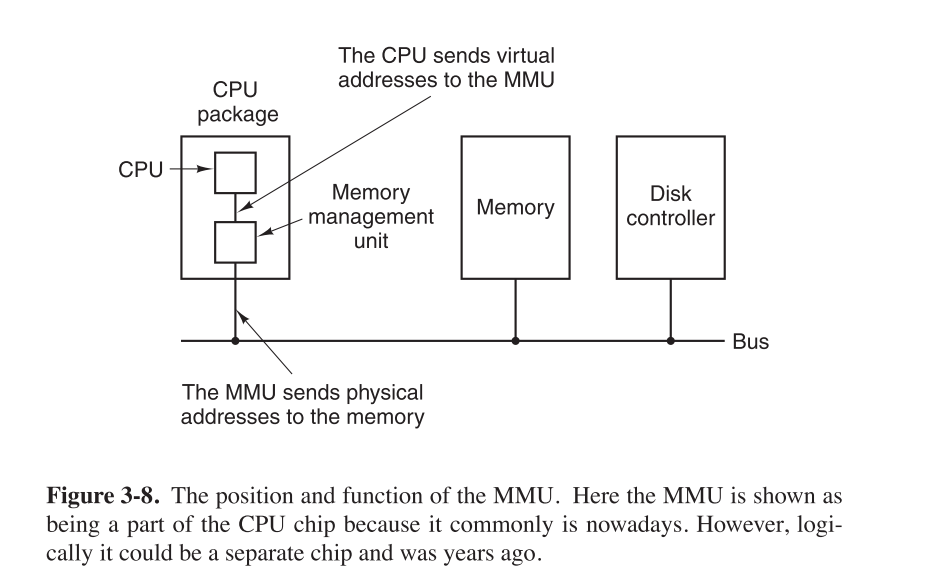
Computer Systems. A Programmer’s Perspective 3rd Edition
With virtual addressing, the CPU accesses main memory by generating a virtual address (VA), which is converted to the appropriate physical address before being sent to main memory.
- 综合来看, 程序调用cpu使用索引、基址寄存器、段寄存器或其它方式产生的地址就称为虚拟地址,它们的集合构成了一个虚拟地址空间
使用虚拟地址的方式,就是程序在cpu里跑的时候,cpu会生成虚拟地址,再转换为物理地址,发送到物理内存,找到一样的物理地址,从里面拿出数据来。
- 综合来看, 程序调用cpu使用索引、基址寄存器、段寄存器或其它方式产生的地址就称为虚拟地址,它们的集合构成了一个虚拟地址空间
-
在我们的xv6,所谓MMU,就是我们的对用户程序虚拟空间采用三级页表,对内核虚拟空间采用直接映射
-
从概念上想,一个CPU产生一个虚拟空间后,xv6会使用
stap切换页表,在相同的虚拟空间里使用不同的页表,虚拟空间指向的物理内存就不一样了
- Lab6: Copy-on-Write Fork for xv6
-
认真看hint和plan,大部分思路都提供,一部分思路需要自己多尝试或者参考= =
-
添加引用计数
ref_count-
我们分页时,只是在物理内存这一块分页,也就是
KERBASE ~ PHYSTOP -
为什么要用
lock,因为ref_count是共享的,容易出现覆盖,考虑如下例子Lab6: Copy-on-Write Fork for xv6
这里使用自旋锁是考虑到这种情况:进程P1和P2共用内存M,M引用计数为2,此时CPU1要执行
fork产生P1的子进程,CPU2要终止P2,那么假设两个CPU同时读取引用计数为2,执行完成后CPU1中保存的引用计数为3,CPU2保存的计数为1,那么后赋值的语句会覆盖掉先赋值的语句,从而产生错误 -
注意:
ref_count是全局变量,会自动初始化为0
/* kernel/kalloc.c */ struct { struct spinlock lock; struct run *freelist; uint8 ref_count[(PHYSTOP - KERNBASE) / PGSIZE]; // just use KERBASE ~ PHYSTOP memory(128M) // 128*1024*1024 / 4096 = 32768 pages } kmem; -
-
ref_count增加1- 记得要添加到声明到
defs.h中
/* kernel/kalloc.c */ // Increment a page's reference count when fork causes a child to share the page, void increment_refcount(uint64 pa){ acquire(&kmem.lock); kmem.ref_count[(pa - KERNBASE) / PGSIZE]++; release(&kmem.lock); } - 记得要添加到声明到
-
ref_count减少1- 每次取消对某个物理内存页的引用,最终都会调用到
kfree(),因此ref_count减少1在kfree()实现比较合理。同时,当ref_count减少到0时,即可释放这一物理页。 - 要先在
freerange()中,将全部ref_count初始化为1,因为调用kfree()时,会自动减1,要抵消这个自动减1。我们希望空闲链表组建之后,在未分配之前,所有物理页面的ref_count全为0
/* kernel/kalloc.c */ void freerange(void *pa_start, void *pa_end) { char *p; p = (char*)PGROUNDUP((uint64)pa_start); for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE){ acquire(&kmem.lock); kmem.ref_count[((uint64)p - KERNBASE) / PGSIZE] = 1; release(&kmem.lock); kfree(p); } } void kfree(void *pa) { struct run *r; if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP) panic("kfree"); // kfree() should only place a page back on the free list // if its reference count is zero. // decrement a page's count each time any process drops the page from its page table. // NOTE: if drops the page, we must call kfree() finally acquire(&kmem.lock); if(--kmem.ref_count[((uint64)pa - KERNBASE) / PGSIZE] == 0){ release(&kmem.lock); // Fill with junk to catch dangling refs. memset(pa, 1, PGSIZE); r = (struct run*)pa; acquire(&kmem.lock); r->next = kmem.freelist; kmem.freelist = r; release(&kmem.lock); } else release(&kmem.lock); } - 每次取消对某个物理内存页的引用,最终都会调用到
-
分配
kalloc一次物理页,就将这个物理页ref_count设置为1/* kernel/kalloc.c */ void * kalloc(void) { struct run *r; acquire(&kmem.lock); r = kmem.freelist; if(r){ // Set a page's reference count to one when kalloc() allocates it. kmem.ref_count[((uint64)r - KERNBASE) / PGSIZE] = 1; kmem.freelist = r->next; } release(&kmem.lock); if(r) memset((char*)r, 5, PGSIZE); // fill with junk return (void*)r; } -
得到物理页的
ref_countref_count仅限于在kernel/kalloc.c中使用,其它地方无法调用得到- 记得要添加到声明到
defs.h中
int get_refcount(uint64 pa) { return kmem.ref_count[(pa - KERNBASE) / PGSIZE]; } -
添加
PTE_COW,标识这个PTE是copy on write(写时复制)的物理页- riscv-privileged,P77,我们使用第8位当作标识位

#define PTE_COW (1L << 8) // 1 -> COW page - riscv-privileged,P77,我们使用第8位当作标识位
-
修改
uvmcopy- 调用
uvmcopy时,如果当前页面可以写,那就将其置为不可写,同时将其标识为cowpage。 - 最终我们不再分配一个新的物理页,而是直接映射到旧的物理页
- 当要写这个不可写但为cowpage的页面时,启动中断page fault ,此时我们才分配新的物理页
/* kernel/vm.c */ int uvmcopy(pagetable_t old, pagetable_t new, uint64 sz) { pte_t *pte; uint64 pa, i; uint flags; for(i = 0; i < sz; i += PGSIZE){ if((pte = walk(old, i, 0)) == 0) panic("uvmcopy: pte should exist"); if((*pte & PTE_V) == 0) panic("uvmcopy: page not present"); pa = PTE2PA(*pte); // Increment a page's reference count when fork causes a child to share the page, increment_refcount(PGROUNDDOWN(pa)); /* just clear PTE_W for page with PTE_W */ if (*pte & PTE_W){ /* clear PTE_W */ *pte &= (~PTE_W); /* set PTE_COW */ *pte |= PTE_COW; } flags = PTE_FLAGS(*pte); if(mappages(new, i, PGSIZE, pa, flags) != 0){ goto err; } } return 0; err: uvmunmap(new, 0, i / PGSIZE, 1); return -1; } - 调用
-
修改
usertrap,我们需要两个辅助函数-
r_scause() == 15的是我们要处理的store page fault- store是将数据从寄存器写到内存当中,我们就是要将一些数据从寄存器写到物理页内存当中

-
stval()的值此时是发生错误的虚拟地址,即fault_variscv-privileged P67
When a hardware breakpoint is triggered, or an instruction, load, or store address-misaligned, access-fault, or page-fault exception occurs, stval is written with the faulting virtual address.
-
如果遇到
fault_va超过p -> sz,说明地址错误了,无法处理- 这一点是
usertests测试的
- 这一点是
-
is_cowpage用来判断该页面是不是cowpage -
cow_page,为这个cowpage分配新的物理页,该函数需要考虑两个情况- 一是这个cowpage只有一个引用了,我们直接修改
pte的值即可 - 二是这个cowpage有多个引用,这时就要调用
kalloc()了 - 调用
mappages去映射时,将PTE_V清掉,防止panic: remap - 注意最后要将
ref_count减1
- 一是这个cowpage只有一个引用了,我们直接修改
-
如果不是cowpage或者分配失败都会将其
kill掉,之后变成zombie process -
处理完cowpage引发的
page fault,要回到原来的程序计数器(pc)自己重新执行即可,
万万不能将pc增加4 -
记得要添加到声明到
defs.h中
/* kernel/trap.c */ ... syscall(); } else if(r_scause() == 15){ // This is "store page fault", because I want write a page without PTE_W uint64 fault_va = r_stval(); if(fault_va > p->sz || is_cowpage(p->pagetable, fault_va) < 0 || cow_alloc(p->pagetable, PGROUNDDOWN(fault_va)) == 0 ) p->killed = 1; } else if((which_dev = devintr()) != 0){ ... /* It is cowpage? */ /* if YES return 0; else return -1 */ int is_cowpage(pagetable_t pagetable, uint64 va) { pte_t* pte = walk(pagetable, va, 0); return (*pte & PTE_COW ? 0 : -1); } /* allocte a phycial memory page for a cow page */ /* if OK return memory pointer of void*; else return 0 */ void* cow_alloc(pagetable_t pagetable, uint64 va) { pte_t *pte = walk(pagetable, va, 0); uint64 pa = PTE2PA(*pte); // refcount == 1, only a process use the cowpage // so we set the PTE_W of cowpage and clear PTE_COW of the cowpage if(get_refcount(pa) == 1){ *pte |= PTE_W; *pte &= ~PTE_COW; return (void*)pa; } // refcount >= 2, some processes use the cowpage uint flags; char *new_mem; /* sets PTE_W */ *pte |= PTE_W; flags = PTE_FLAGS(*pte); /* alloc and copy, then map */ pa = PTE2PA(*pte); new_mem = kalloc(); // If a COW page fault occurs and there's no free memory, the process should be killed. if(new_mem == 0) return 0; memmove(new_mem, (char*)pa, PGSIZE); /* clear PTE_V before map the page to avoid panic of 'remap' */ *pte &= ~PTE_V; /* note: new_mem is new address of phycial memory*/ if(mappages(pagetable, va, PGSIZE, (uint64)new_mem, flags) != 0){ /* set PTE_V, then kfree new_men, if map failed*/ *pte |= PTE_V; kfree(new_mem); return 0; } /* decrement a ref_count */ kfree((char*)PGROUNDDOWN(pa)); return new_mem; } -
-
在
copyout中,遇到cowpage时采用usertrap中处理page fault的方式- 注意如果处理失败要返回错误值
-1
int copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len) { ... n = len; if(is_cowpage(pagetable, va0) == 0) // if it is a cowpage, we need a new pa0 pointer to a new memory // and if it is a null pointer, we need return error of -1 if ((pa0 = (uint64)cow_alloc(pagetable, va0)) == 0) return -1; memmove((void *)(pa0 + (dstva - va0)), src, n); ... } - 注意如果处理失败要返回错误值
- 完成日期22.4.20
- 期间比较难以想到的就是实现
ref_count减少1,在kfree中添加这一功能,所有的物理页面取消映射时,最终都会调用kfree,因为要将其释放掉。 - debug一段时间,最好不要超过2小时,要立刻去休息,不然容易发懵
- result
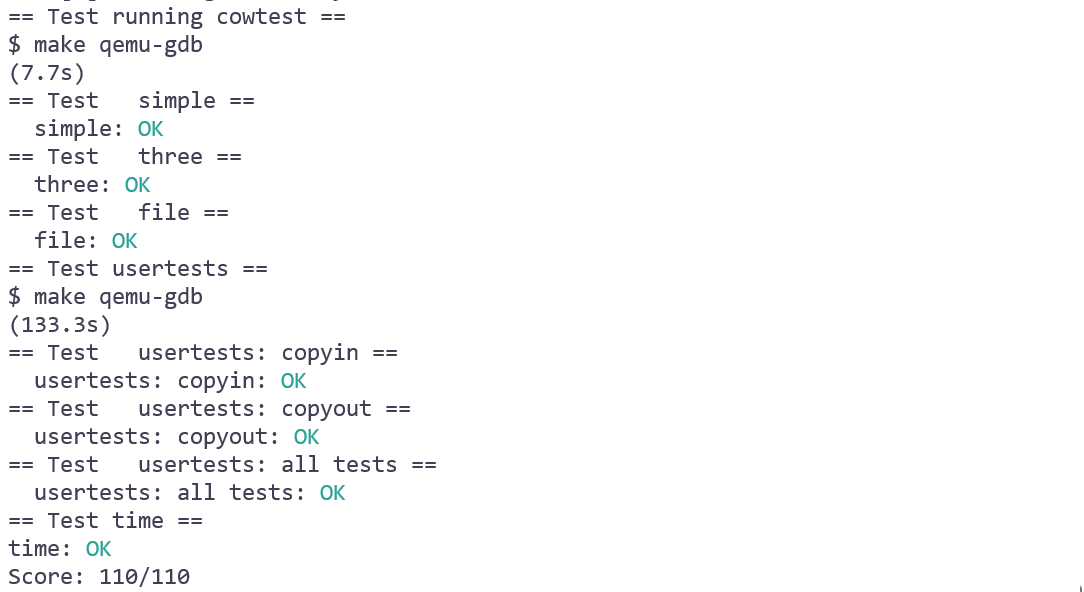
- 最近在听《萱草花》乃琳/珈乐和《北方》任素汐