@
目录- 1、JUC 简介
- 2、线程和进程
- 3、并非与并行
- 4、线程的状态
- 5、wait/sleep的区别
- 6、Lock 锁(重点)
- 1、Lock锁
- 2、公平非公平:
- 3、ReentrantLock 构造器
- 4、Lock 锁实现步骤:
- 7、synchronized 和 lock 锁的区别
- 8、生产者和消费者问题(通信问题)
- 1、Synchronized 版本
- 2、JUC 版本
- 9、八个有关锁的问题
- 关于锁的八个问题
- 问题1:两个同步方法,先执行发短信还是打电话?
- 问题2:如果发短信延迟2秒,谁先执行
- 问题3 加上一个没有锁的普通方法,谁先执行
- 问题4:两个对象,一个调用发短信,一个调用打电话,谁先执行
- 问题5:原来的两个同步方法,变为静态同步方法,一个对象调用,谁先执行
- 问题6:创建两个实例,调用两个静态同步方法,谁先执行
- 问题7:一个静态同步方法、一个同步方法、一个对象调用,谁先执行
- 问题8:两个对象,一个调用静态同步方法,一个调用普通同步方法,谁先执行
- 小结
- 10、集合类的安全问题
- 1、List 不安全
- 2、Set 不安全
- 11、Callable(简单)
- 12、JUC 常用辅助类
- 1、CountDownLatch
- 2、CyclickBarrier
- 3、Semaphore
- 13、ReadWriteLock 读写锁
- 14、阻塞队列
- 1、Blockqueue
- 2、SynchronizedQueue
- 15、线程池(重点)
- 1、线程池:三大方法
- 2、线程池:七大参数
- 3、四大拒绝策瑜:
- 16、为什么要使用线程池?
- 17、线程池线程复用的原理是什么?
- 18、AQS的理解
- 1、ReentrantLock和AQS的关系
- 2、ReentrantLock加锁和释放锁的底层原理
- 19、线程创建的三种方式
- 20、为什么启动start(),就调用run方法
- 21、线程的生命周期
- 21、线程安全:
- 线程安全解决问题方案:
- 1、互斥阻塞同步:也就是加锁sychronized和ReenrtrantLock,加锁优缺点?
- 22、线程同步机制
- 23、run()方法和sart()方法有什么区别
- 24、线程是否可以被重复启动
- 25、volatile
- 26、java多线程之间的三种通信方式
- 1、synchronized来保证线程安全
- 2、通过Lock()
- 3、BlockingQueue
- 27、说一说synchronized的底层实现原理
- 28、CAS
- 1、概念
- 2、CAS可能产生ABA问题:
- 29、锁升级初步
- 1、偏向锁:
- 2、轻量级锁
- 3、锁重入锁
- 4、自旋锁什么时候升级为重量级锁
- 5、为什么有自旋锁还需要重量级锁
- 6、偏向锁是否一定比自旋锁效率高
- 30、ThreadLocal机制
- 31、ThreadLocal机制的内存泄露
- 留言:
多线程JUC并发篇
1、JUC 简介什么是 JUC ?
-
JUC 就是 java.util.concurrent 下面的类包,专门用于多线程的开发
为什么使用 JUC ? -
以往我们所学,普通的线程代码,都是用的thread或者runnable接口
-
但是相比于callable来说,thread没有返回值,且效率没有callable高
-
进程就是一个应用程序
-
线程是进程中的一个实体,线程本身是不会独立存在的。
进程是代码在数据集合上的一次运行活动, 是系统进行资源分配和调度的基本单位。
线程则是进程的一个执行路径, 一个进程中至少有一个线程,进程中的多个线程共享进程的资源。
操作系统在分配资源时是把资源分配给进程的, 但是CPU 资源比较特殊, 它是被分配到线程的, 因为真正要占用CPU 运行的是线程, 所以也说线程是CPU 分配的基本单位。
java默认有几个线程? 两个 main线程 gc线程
Java 中,使用 Thread、Runnable、Callable 开启线程。
3、并非与并行 Java 没有权限开启线程 、Thread.start() 方法调用了一个 native 方法 start0(),它调用了底层 C++ 代码。
并发多线程操作同一个资源,交替执行
- CPU一核, 模拟出来多条线程,天下武功,唯快不破,快速交替
并行(多个人一起行走, 同时进行)
- CPU多核,多个线程同时进行 ; 使用线程池操作
-
新建
-
就绪
-
阻塞
-
运行
-
死亡
-
来自不同的类:wait来自object类, sleep来自线程类
-
关于锁的释放:wait会释放锁, sleep不会释放锁
-
使用范围不同:wait必须在同步代码块中,sleep可以在任何地方睡
-
是否需要捕获异常:wait不需要捕获异常,sleep需要捕获异常
Synchronized 传统的锁
之前我们所学的使用线程的传统思路是:
-
单独创建一个线程类,继承Thread或者实现Runnable
-
在这个线程类中,重写run方法,同时添加相应的业务逻辑
-
在主线程所在方法中new上面的线程对象,调用start方法启动
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aFbI65Pz-1650013582522)(https://pizximfzuc.feishu.cn/space/api/box/stream/download/asynccode/?code=Nzg2NDU1MDkyYTk1YWVlZDJjMzM3M2QxODNlMWM4NWRfeUZORjNjcWtmd3ZrR1FmWEZ2MkVWdjZMWGtHenpsM3JfVG9rZW46Ym94Y25qVzdjWERnR2owZVlMRXU4S3pTT1VjXzE2NTAwMTM0OTI6MTY1MDAxNzA5Ml9WNA)]](http://img.558idc.com/uploadfile/allimg/boke/e48a1dcbfe9a4a67aeb1716563b60e9c.png)
可以看到,
Lock是一个接口,有三个实现类,现在我们使用
ReentrantLock 就够用了
查看
ReentrantLock 源码,构造器
-
公平锁::十分公平, 可以先来后到,一定要排队
-
非公平锁::十分不公平,可以插队(默认)
-
ReentrantLock 默认的构造方法是非公平锁(可以插队)。
-
如果在构造方法中传入 true 则构造公平锁(不可以插队,先来后到)。
- 创建锁,new ReentrantLock()
- 加锁,lock.lock()
- 解锁,lock.unlock()
- 基本结构固定,中间的业务自己灵活修改
-
synchronized 是内置的 Java 关键字,Lock 是一个 Java 类
-
synchronized 无法判断获取锁的状态,Lock可以判断是否获取到了锁
-
synchronized 会自动释放锁,Lock 必须要手动释放锁!如果不释放锁,会产生死锁
-
synchronized 假设线程1(获得锁,然后发生阻塞),线程2(一直等待); Lock 锁就不一定会等待下去,可使用 tryLock 尝试获取锁
-
synchronized 可重入锁,不可以中断的,非公平的;Lock锁,可重入的,可以判断锁,是否公平(可自己设置)
-
synchronized 适合锁少量的代码同步问题,Lock 适合锁大量的同步代码
8、生产者和消费者问题(通信问题) 1、Synchronized 版本总体来说,synchronized 本来就是一个关键字,很多规则都是定死的,灵活性差;Lock 是一个类,灵活性高
解决线程之间的通信问题,比如线程操作一个公共的资源类
基本流程可以总结为:
-
等待:判断是否需要等待
-
业务:执行相应的业务
-
通知:执行完业务通知其他线程
public class ConsumeAndProduct {
public static void main(String[] args) {
Data data = new Data();
// 创建一个生产者
new Thread(()->{
for (int i = 0; i < 10; i++) {
try {
data.increment();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"A").start();
// 创建一个消费者
new Thread(()->{
for (int i = 0; i < 10; i++) {
try {
data.decrement();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"B").start();
}
}
//这是一个缓冲类,生产和消费之间的仓库,公共资源类
class Data{
// 这是仓库的资源,生产者生产资源,消费者消费资源
private int num = 0;
// +1,利用关键字加锁
public synchronized void increment() throws InterruptedException {
// 首先查看仓库中的资源(num),如果资源不为0,就利用 wait 方法等待消费,释放锁
if(num!=0){
this.wait();
}
num++;
System.out.println(Thread.currentThread().getName()+"=>"+num);
// 通知其他线程 +1 执行完毕
this.notifyAll();
}
// -1
public synchronized void decrement() throws InterruptedException {
// 首先查看仓库中的资源(num),如果资源为0,就利用 wait 方法等待生产,释放锁
if(num==0){
this.wait();
}
num--;
System.out.println(Thread.currentThread().getName()+"=>"+num);
// 通知其他线程 -1 执行完毕
this.notifyAll();
}
}
思考问题:如果存在ABCD4个线程是否安全?
- 不安全,会有虚假唤醒
查看 api 文档

解决办法:if 判断改为 while,防止虚假唤醒
-
因为 if 只会执行一次,执行完会接着向下执行 if() 外边的代码
-
而 while 不会,直到条件满足才会向下执行 while() 外边的代码
修改代码为:
// ...
// 使用 if 存在虚假唤醒
while (num!=0){
this.wait();
}
// ...
while(num==0){
this.wait();
}
锁、等待、唤醒 都进行了更换
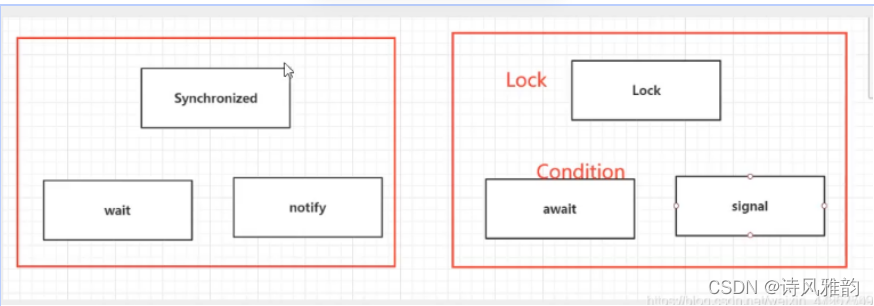
改造之后,确实可以实现01切换,但是ABCD是无序的,不满足我们的要求,
Condition 的优势在于,精准的通知和唤醒线程!比如,指定通知下一个进行顺序。
重新举个例子,
三个线程 A执行完调用B,B执行完调用C,C执行完调用A,分别用不同的监视器,执行完业务后指定唤醒哪一个监视器,实现线程的顺序执行
锁是统一的,但监视器是分别指定的,分别唤醒,signal,之前使用的是 signalAll
private Lock lock = new ReentrantLock();
private Condition condition1 = lock.newCondition();
private Condition condition2 = lock.newCondition();
private Condition condition3 = lock.newCondition();
private int num = 1; // 1A 2B 3C
public void printA(){
lock.lock();
try {
while (num != 1){
condition1.await();
}
System.out.println(Thread.currentThread().getName() + " Im A ");
num = 2;
condition2.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void printB(){
lock.lock();
try {
while (num != 2){
condition2.await();
}
System.out.println(Thread.currentThread().getName() + " Im B ");
num = 3;
condition3.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public void printC(){
lock.lock();
try {
while (num != 3) {
condition3.await();
}
System.out.println(Thread.currentThread().getName() + " Im C ");
num = 1;
condition1.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
深入理解锁
关于锁的八个问题 问题1:两个同步方法,先执行发短信还是打电话?经过测试,一直是先发短信
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rsXbJVS7-1650013582524)(https://pizximfzuc.feishu.cn/space/api/box/stream/download/asynccode/?code=NzExNGI3OTliYmQ5MTk5ZmVjMjYzNzAxM2MwYmQwMGJfM3l3b1NKWndKYVA5cjRrVHc4SWdxektzOGQxSmZKeHVfVG9rZW46Ym94Y25nTkhuUVdVdllwVWhiYVZXS09Oak0xXzE2NTAwMTM0OTI6MTY1MDAxNzA5Ml9WNA)]](http://img.558idc.com/uploadfile/allimg/boke/f61626937ffa42a6b716db1992615546.png)
结果依旧是先发短信,后打电话
分析:
-
并不是由于发短信在前导致的
-
本案例中,方法前加synchronized,锁的其实该方法的调用者,也就是 phone 实例,两个方法共用同一个 phone 对象的锁,谁先拿到,谁先执行
-
在主线程中,先调用发短信,所以先执行,打电话等释放锁再执行
观察发现,先执行了 hello
分析原因:
- hello 是一个普通方法,不受 synchronized 锁的影响,不用等待锁释放。
结论,先打电话,后发短信
分析原因:
- 两个对象两把锁,互不影响,1拿到锁还需要等待3秒,2拿到对象立刻就能打电
结果,始终是先发短信,后打电话
分析原因:
静态方法前面加锁,锁的其实是这个方法所在的Class类对象(非静态那个是实例对象,注意区分)
Class类对象也是全局唯一,使用的是通一把锁,所以先发短信,后打电话
虽然和上面的实例对象都是对应了全局唯一的锁,但原理还是有所不同
主线程先执行了发短信,打电话就必须等锁释放再执行
问题6:创建两个实例,调用两个静态同步方法,谁先执行结果,现发短信,后打电话
原因分析:
- 虽然实例对象是两个,但是两个静态同步方法对应的锁是Class类对象的锁,还是全局唯一
结果:先打电话,后发短信
原因分析:
-
静态同步方法和普通同步方法分别对应了不同的锁,互不干扰
-
发短信需要延迟3秒,所以打电话先执行了
结果,先打电话,后发短信
分析原因:
同问题7相同,两个方法对应了不同的锁,互不干扰
发短信还需要等待3秒,所以打电话先执行完了
小结无外乎两种锁,一个是new实例的锁,一个是Class对象的锁
实例的锁,与当前的实例唯一对应,Class对象的锁与这个类唯一对应
如果两个方法等同一个锁,必须一个先执行完,释放锁,另一个才可以执行
如果两个方法等不同的锁,互不影响,谁先谁后看具体情况
10、集合类的安全问题在主线程中,代码是顺序执行的,再结合锁的原理,综合判断线程执行的顺序
在 JUC 并发编程情况下,适用于单线程的集合类将出现并发问题
1、List 不安全运行出现并发修改异常,
java.util.ConcurrentModificationException
解决方案:
解决方案1:
-
ArrayList 换成 Vector,Vector 方法里加了锁
-
Vector出现比较早,由于锁导致方法执行效率太低,不推荐使用
解决方案2:
-
使用 Collection 静态方法,返回一个带锁的 List 实例
List
list = Collections.synchronizedList(new ArrayList<>());
解决方案3:
-
使用 JUC 提供的适合并发使用的 CopyOnWriteArrayList
List
list = new CopyOnWriteArrayList<>();
分析:
CopyOnWrite 表示写入时复制,简称COW,计算机程序设计领域的一种优化策略
多线程调用list时,读取时没有问题,写入的时候会复制一份,避免在写入时被覆盖
这也是一种读写分离的思想
CopyOnWriteArrayList 比 Vector 强在哪里?前者是写入、复制,且使用 lock 锁,效率比 Vector 的synchronized 锁要高很多
2、Set 不安全Set 和 List 同理可得:多线程情况下,普通的 Set 集合是线程不安全的
-
使用 Collection 工具类的 synchronized 包装的 Set 类
Set
set = Collections.synchronizedSet(new HashSet<>());
-
使用 JUC 提供的 CopyOnWriteArraySet 写入复制
Set
set = new CopyOnWriteArraySet<>();
思考,HashSet 底层到底是什么?
- hashSet底层就是一个HashMap;hashSet只使用了hashMap的key
得到的信息:
可以有返回值
可以抛出异常
方法不同,run() => call()
使用时注意
-
Callable 的泛型也是 call 方法的返回值类型
-
Callable 的实现类无法直接放在 Thread 中,还需要先放在 -
-
FutureTask 中,再放在 Thread 中FutureTask 就相当于适配类,起到牵线的作用
注意:
-
运行结果会产生缓存,目的是为了提高效率
-
get方法可能会产生阻塞,所以放在了最后
减法计数器
原理:
countDownLatch.countDown(); //数量减1
countDownLatch.await();// 等待计数器归零,然后再向下执行
每次有线程调用countDown()数量-1,假设计数器变为0,countDownLatch.await();就会被唤醒,继续执行
2、CyclickBarrier加法计数器,与 CountDownLatch 正好相反
相当于设定一个目标,线程数达到目标值之后才会执行
3、Semaphore计数信号量,比如说,有6辆车,3个停车位,汽车需要轮流等待车位
常用在需要限流的场景中,
原理:
-
*semaphore.acquire() 获得资源,如果资源已经使用完了,就等待资源释放后再进行使用!
-
*semaphore.release() 释放,会将当前的信号量释放+1,然后唤醒等待的线程!
用途:
-
*多个共享资源互斥的使用!
-
*并发限流,控制最大的线程数!
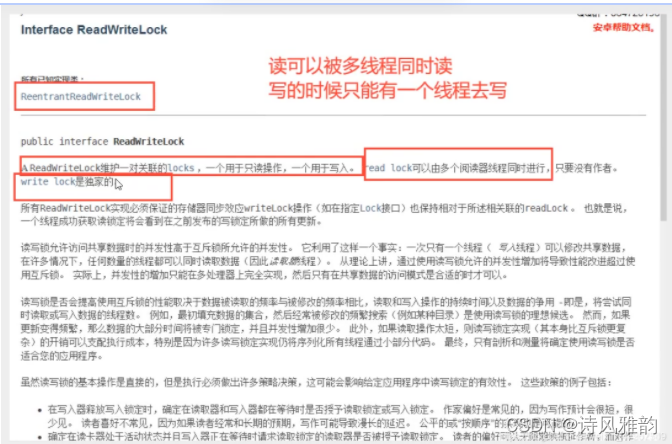
ReadWriteLock,这是一个更加细粒度的锁
// 自定义缓存
class MyCache{
private volatile Map<String,String> map = new HashMap<>();
private ReadWriteLock readWriteLock= new ReentrantReadWriteLock();
// 存,写,写入的时候只希望只有一个线程在写
public void write(String key, String value) {
readWriteLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "线程开始写入");
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "线程开始写入ok");
} catch (Exception e) {
e.printStackTrace();
} finally {
readWriteLock.writeLock().unlock();
}
}
// 取,读,所有线程都可以读
public void read(String key) {
readWriteLock.readLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "线程开始读取");
map.get(key);
System.out.println(Thread.currentThread().getName() + "线程读取ok");
} catch (Exception e) {
e.printStackTrace();
} finally {
readWriteLock.readLock().unlock();
}
}
}
小结:
- 读-读 可以共存
- 读-写 不能共存
- 写-写 不能共存
也可以这样称呼,含义都是一样,名字不同而已
- 独占锁(写锁)一次只能由一个线程占有
- 享锁(读锁)一次可以有多个线程占有
阻塞队列 BlockQueue 是Collection 的一个子类
应用场景:多线程并发处理、线程池
BlockingQueue 有四组 API
方式 抛出异常 不会抛出异常,有返回值 阻塞等待 超时等待
添加操作 add() offer() 供应 put() offer(obj,int,timeunit.status)可设置时间
移除操作 remove() poll() 获得 take() poll(int,timeunit.status)可设置时间
判断队列首部 element() peek() 偷看,偷窥 SynchronizedQueue 同步队列
同步队列没有容量,进去一个元素,必须等待取出来之后,才能再往里面放一个元素
2、SynchronizedQueue- SynchronizedQueue使用 put 方法和 take 方法
- Synchronized 和 其他的 BlockingQueue 不一样 它不存储元素;
- put了一个元素,就必须从里面先 take 出来,否则不能再 put 进去值!
- 并且 SynchronousQueue 的 take 是使用了 lock 锁保证线程安全的。
池化技术
线程池重点:三大方式、七大参数、四种拒绝策略
程序的运行的本质:占用系统的资源 ! 优化CPU资源的使用 ===>池化技术(线程池、连接池、内存池、对象池…)
池化技术:实现准备好一些资源,有人要用,就来我这里拿,用完之后还给我
线程池的好处:
- 降低资源消耗
- 提高响应速度
- 方便管理
如何优化:
- 线程复用,可以控制最大并发数,管理线程
查看阿里巴巴开发手册

- ExecutorService threadPool = Executors.newSingleThreadExecutor();//单个线程
- ExecutorService threadPool2 = Executors.newFixedThreadPool(5); //创建一个固定的线程池的大小
- ExecutorService threadPool3 = Executors.newCachedThreadPool(); //可伸缩的(不会出现OOM)
之前我们所学知识,直接创建线程,现在我们通过线程池来创建线程,使用池化技术
> ExecutorService service = Executors.newCachedThreadPool();//可伸缩的,遇强则强,遇弱则弱
> try {
> for (int i = 0; i < 10; i++) {
> service.execute(() -> {
> System.out.println(Thread.currentThread().getName() + "ok");
> });
> }
> //线程池用完要关闭线程池
> } finally {
> service.shutdown();
> }
public ThreadPoolExecutor(int corePoolSize,//核心线程数 也就是一直工作的线程数量
int maximumPoolSize,//最大线程数,如果核心心线程数使用完
long keepAliveTime,//非核心线程的存活时间
TimeUnit unit,//非核心线程的存活时间单位
BlockingQueue<Runnable> workQueue,//阻塞队列
ThreadFactory threadFactory,//线程工厂
RejectedExecutionHandler handler) //拒绝策略
提交优先级
execute()提交方法中源码中的几个if里面都会调用执行方法addWorker(Rannale firstTask,boolean core )
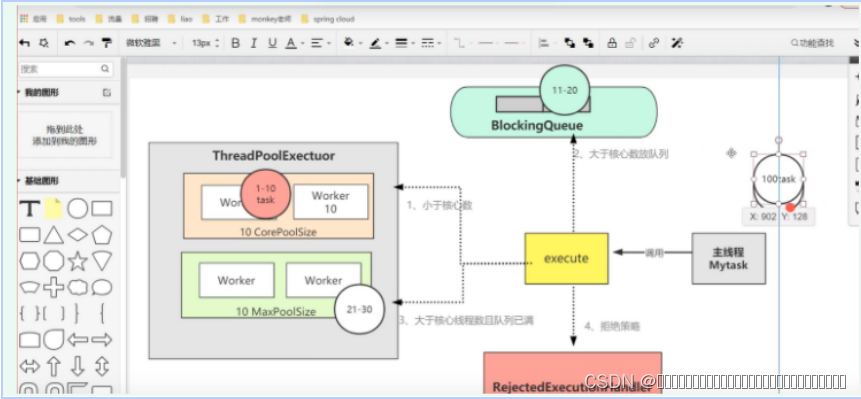
执行优先级
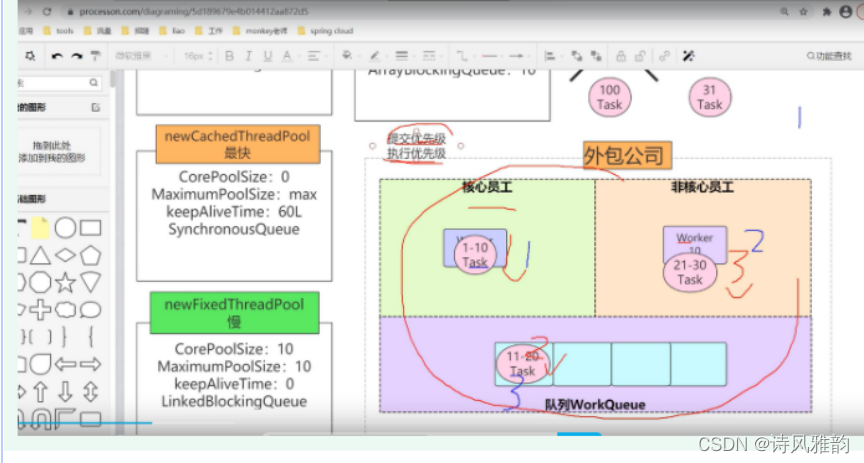
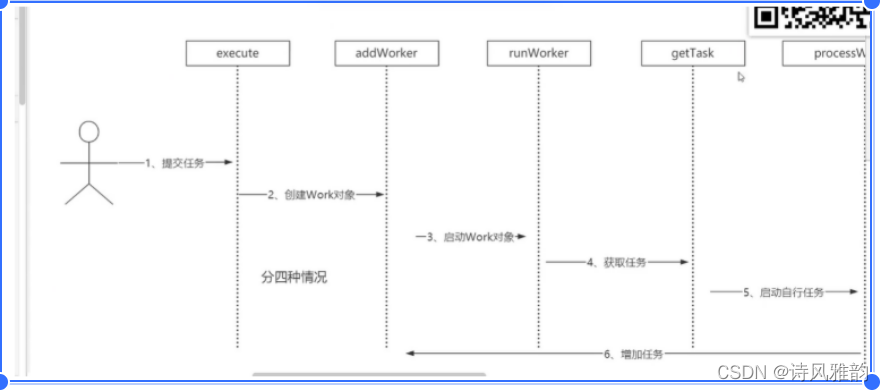
执行优先级:
addWorker(Rannale firstTask,boolean core )
submit()与execute()区别
1、submit()有返回值,execute()没有返回值
3、四大拒绝策瑜:2、submit()方法里面调用了execute()方法

为了减少创建和销毁线程的次数,让每个线程可以多次使用,可根据系统情况调整执行的线程数量,防止消耗过多内存,所以我们可以使用线程池.
17、线程池线程复用的原理是什么?首先线程池内的线程都被包装成了一个个的java.util.concurrent.ThreadPoolExecutor.Worker,然后这个worker会马不停蹄的执行任务,执行完任务之后就会在while循环中去取任务,取到任务就继续执行,取不到任务就跳出while循环(这个时候worker就不能再执行任务了)执行 processWorkerExit方法,这个方法呢就是做清场处理,将当前woker线程从线程池中移除,并且判断是否是异常的进入processWorkerExit方法,如果是非异常情况,就对当前线程池状态(RUNNING,shutdown)和当前工作线程数和当前任务数做判断,是否要加入一个新的线程去完成最后的任务(防止没有线程去做剩下的任务).
那么什么时候会退出while循环呢?取不到任务的时候(getTask() == null)
/java/util/concurrent/ThreadPoolExecutor.java:1127
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {...执行任务...}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
//(rs == SHUTDOWN && workQueue.isEmpty()) || rs >=STOP
//若线程池状态是SHUTDOWN 并且 任务队列为空,意味着已经不需要工作线程执行任务了,线程池即将关闭
//若线程池的状态是 STOP TIDYING TERMINATED,则意味着线程池已经停止处理任何任务了,不在需要线程
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
//把此工作线程从线程池中删除
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
//allowCoreThreadTimeOut:当没有任务的时候,核心线程数也会被剔除,默认参数是false,官方推荐在创建线程池并且还未使用的时候,设置此值
//如果当前工作线程数 大于 核心线程数,timed为true
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//(wc > maximumPoolSize || (timed && timedOut)):当工作线程超过最大线程数,或者 允许超时并且超时过一次了
//(wc > 1 || workQueue.isEmpty()):工作线程数至少为1个 或者 没有任务了
//总的来说判断当前工作线程还有没有必要等着拿任务去执行
//wc > maximumPoolSize && wc>1 : 就是判断当前工作线程是否超过最大值
//或者 wc > maximumPoolSize && workQueue.isEmpty():工作线程超过最大,基本上不会走到这,
// 如果走到这,则意味着wc=1 ,只有1个工作线程了,如果此时任务队列是空的,则把最后的线程删除
//或者(timed && timedOut) && wc>1:如果允许超时并且超时过一次,并且至少有1个线程,则删除线程
//或者 (timed && timedOut) && workQueue.isEmpty():如果允许超时并且超时过一次,并且此时工作 队列为空,那么妥妥可以把最后一个线程(因为上面的wc>1不满足,则可以得出来wc=1)删除
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
//如果减去工作线程数成功,则返回null出去,也就是说 让工作线程停止while轮训,进行收尾
return null;
continue;
}
try {
//判断是否要阻塞获取任务
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
java并发包下的很多API都是基于AQS来实现加锁和释放等功能,AQS是并java发包的基础类。
举个列子,ReentrantLock、ReentrantReadWr
iteLock底层都是基于AQS来实现的。ReentrantLock内部包含已个AQS对象。
AQS的全称是AbstractQueueSynchonizer,抽象队列同步锁。
2、ReentrantLock加锁和释放锁的底层原理如果现在有一个线程过来尝试用ReentrantLock的lock()方法进行加锁,会发生什么?
很简单,这个AQS对象内部有一个核心的变量state,是int类型的,代表加锁的状态。初始情况下为0.
另外AQS内部还有一个关键变量,用来记录加锁线程是哪个线程,初始化状态下,这个线程是null。
[MISSING IMAGE: image-20220324164210432, image-20220324164210432 ]
接着线程1跑过来会调用ReentrantLock的lock()方法尝试加锁,这个加锁的过程,是直接用CAS操作将state值进行0->1的。如果之间前没有人加过锁,那么state为0,此时线程1加锁成功
一旦线程加锁成功后,就可以设置当前线程就是自己。
下图就是线程1的加锁过程
其实到这就知道了AQS就是并发包里的一个核心组件,里面有state变量,加锁 线程变量等核心东西,维护了加锁状态。你会发现ReentrantLock就是一个外面的API,内部的核心锁机制都是依赖AQS组件的
这个ReentrantLock之所以以Reentrant开头,意思是它可以可重入锁。
可重入锁的意思是,就是你可以对ReentrantLock对象多次执行lock()加锁和unlock()释放锁,也就是可以对一个锁加多次,叫做可重入加锁
明白这个后看这个state变量,其实每次线程1可重入加锁一次,那么他会判断当前线程就是自己,那么他自己就可以冲重入多次加锁。每次都state+1,别的没有变化。
线程1加锁完成后,那么线程2跑来加锁会发生什么呢?
我们看看互斥锁怎么实现的,线程2跑来发现state不是0,所以CAS重0->1就失败,因为不为0说明被加锁锁了,那么就会去看当前加锁线程是否是自己,不是的话自己就加锁失败。
看图示意:
[MISSING IMAGE: image-20220324170008447, image-20220324170008447 ]
接着,线程2就会将自己放入到AQS的一个等待队列,因为自己尝试加锁失败了,此时就要将自己放入队列中等待,等待线程1释放锁之后,自己就可以重新尝试加锁了。
能够看到,AQS是如此的核心,AQS内部还有一个等待u队列,专门放哪些加锁失败的线程。
[MISSING IMAGE: image-20220324170416331, image-20220324170416331 ]
接着,线程1在执行完自己的业务后,就会释放锁!他释放锁的过程很简单,就是将AQS内部的state变量值递减到,将“加锁线程”也是设置为null,彻底释放锁了。
19、线程创建的三种方式接下来,会从等待队列中唤醒对头的线程2,线程2重新尝试加锁。还是用CAS将state变为1,当前线程为自己线程,同时线程2自己就可以出队了。
-
1、Thread类
是Java中表示线程的类,里面包含了一个线程运行过程中方法run()方法
使用Thread类创建并启动线程的步骤:
1.写一个类,继承Thread类
2.覆盖Thread类中的run()方法
3.创建线程的实例对象
4.调用线程的实例对象的start()方法去启动线程
注意:
1.启动线程调用start()方法
2.启动线程之后会自动调用run()方法
3.需要线程完成某件事情,将对应的代码添加到run()方法中即可
-
2、实现Runnale接口(推荐使用)
步骤:
-
写一个类实现Runnable接口
-
实现Runnable接口中的run()
-
创建Thread类创建对象,并将第三步创建的对象作为参数传递到构造方法中
-
调用Thread创建对象的start()方法,启动线程
采用匿名内部类方式创建线程(固定格式)
public static void main(String[] args) {
Thread th = new Thread() {
public void run() {
System.out.println("匿名内部类的run方法");
};
};
th.start();
}
-
3、实现Callable接口,并与future
-
4、线程池结合使用
关注源码可以发现,在start()方法中,默认调用了一个JNI方法,这个方法是java平台用于和本地C代码进行相互操作的API
21、线程的生命周期线程的生命周期就是线程的状态
- 1新建状态 new
当使用new关键字创建线程实例后,该线程就属于新建状态,但是不会执行
- 2、就绪状态Runnable
当调用start()方法时,该线程处于就绪状态,表示可以执行,但是不一定会立即执行,而是等待cpu
分配时间片进行处理
- 3、运行状态(Running)
当为该线程分配到时间片后,执行该方法的run方法,就处于运行状态
- 4、暂停状态(包括休眠、等待、阻塞等)(Block)
当线程调用sleep()方法,主动放弃CPU资源,或者线程吊用阻塞IO方法时,比如控制台的Scannner输入方法
- 死亡状态(dead)
当线程的run()方法执行完成之后就处于死亡状态
注意:
1.当线程创建时,并不会立即执行,需要调用start方法,使其处于就绪状态
2.线程处于就绪状态时,也不会立即执行线程,需要等待CPU分配时间
3.当线程阻塞时,会让出占有的CPU,当阻塞结束时,线程会进入就绪状态,重新等待CPU,而不是直接进入到运行状态
-
Thread.yield():
让出当前CPU时间片,该线程会从运行状态进入到就绪状态,此时继续与其他线程抢占CPU
-
Thread.sleep(time):
让线程休眠time毫秒,该线程会从运行状态进入到阻塞状态,不会与其他线程抢占CPU。当time毫秒过后,该线程会从阻塞状态进入到就绪状态,重新与其他线程抢占CPU
异步的效率会比同步的高,但是异步存在数据安全问题
多线程并发执行,也就是线程异步处理,并发执行存在线程安全问题
21、线程安全:在实际开发中,使用多线程程序的情况很多,如银行排号系统、火车站售票系统等。这种多线程的程序通常会发生问题,以火车站售票系统为例,在代码中判断当前票数是否大于0,如果大于0则执行将该票出售给乘客的功能,但当两个线程同时访问这段代码时(假如这时只剩下一张票),第一个线程将票售出,与此同时第二个线程也已经执行完成判断 是否有票的操作, 并得出结论票数大于0,于是它也执行售出操作,这样就会产生负数。所以在编写多线程程序时,应该考虑到钱程安全问题。实质上线程安全问题来源于两个线程同时存取单一对象的数据。
线程安全解决问题方案: 1、互斥阻塞同步:也就是加锁sychronized和ReenrtrantLock,加锁优缺点? 22、线程同步机制为了避免多线程的安全问题,需要在公共访问的内容上加锁,加锁之后,当一个线程执行该内容时,其他线程无法执行该内容,只有当该线程将此部分内容执行完了之后,其他线程才可以执行。
- 1.找到多线程公共执行的内容
- 2.在此内容上合适的位置加上锁
锁:
1、****synchronized可以加在方法上,也可以加在代码块中
加在方法上,在返回值前面加synchronized既可,
比如:public synchronized void run() {}表示给run方法整体加上了锁。
加在代码块上:
synchronized(this) {
//需要同步执行的代码
}
注意:加锁之后,被加锁的代码就变成了同步,会影响效率,所以应该尽量减小加锁的范围
2、也可以用RantantLock
23、run()方法和sart()方法有什么区别run()方法是线程的执行体,他的方法代表线程需要完成的任务,而start()方法用来启动线程。
24、线程是否可以被重复启动 25、volatile 26、java多线程之间的三种通信方式 1、synchronized来保证线程安全如果线程之间是通过synchronized来保证线程安全,则可以利用wait()、notify()、notifyAll()来实现通信
2、通过Lock()如果线程之间是通过Lock()来保证线程安全的,则可以利用await()、signal()、signalAll()来说实现线程通信
这三个方法都是Condition接口中的方法。
3、BlockingQueuejdk1.5中提供了BlockingQueue接口,虽然四Queue的子接口,但是主要用途并不是作为容器,而是作为线程的通信工具。BlockingQueue具有一个特征:当生产者线程试图向BlockingQueue中放入一个元素,如果该队列已满,则该线程阻塞;
27、说一说synchronized的底层实现原理一、synchronized作用在代码块时,它的底层是通过monitorenter、monitorexit指令来实现的。
-
*monitorenter:
每个对象都是一个监视器锁(monitor),当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1。如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
-
*monitorexit:
执行monitorexit的线程必须是objectref所对应的monitor持有者。指令执行时,monitor的进入数减1,如果减1后进入数为0,那线程退出monitor,不再是这个monitor的所有者。其他被这个monitor阻塞的线程可以尝试去获取这个monitor的所有权。
monitorexit指令出现了两次,第1次为同步正常退出释放锁,第2次为发生异步退出释放锁。
二、方法的同步并没有通过 monitorenter 和 monitorexit 指令来完成,不过相对于普通方法,其常量池中多了 ACC_SYNCHRONIZED 标示符。JVM就是根据该标示符来实现方法的同步的:
当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取monitor,获取成功之后才能执行方法体,方法执行完后再释放monitor。在方法执行期间,其他任何线程都无法再获得同一个monitor对象。
三、总结
28、CAS 1、概念 2、CAS可能产生ABA问题:两种同步方式本质上没有区别,只是方法的同步是一种隐式的方式来实现,无需通过字节码来完成。两个指令的执行是JVM通过调用操作系统的互斥原语mutex来实现,被阻塞的线程会被挂起、等待重新调度,会导致“用户态和内核态”两个态之间来回切换,对性能有较大影响
ABA解决问题:加一个版本号
版本号:数值型或者布尔型
29、锁升级初步- new->偏向锁->轻量级锁(无锁、自旋锁、自适应自旋3)->重量级锁
2、轻量级锁在锁对象的对象头中记录⼀下当前获取到该锁的线程ID,该线程下次如果⼜来获取该锁就
3、锁重入锁由偏向锁升级⽽来,当⼀个线程获取到锁后,此时这把锁是偏向锁,此时如果有第⼆个 线程来竞争锁,偏向锁就会升级为轻量级锁,之所以叫轻量级锁,是为了和重量级锁区分开来,轻 量级锁底层是通过⾃旋来实现的,并不会阻塞线程
sychnronized必须记录重入次数,因为要解锁必须对应次数
4、自旋锁什么时候升级为重量级锁偏向锁 自旋锁 ->线程栈->LR+1
5、为什么有自旋锁还需要重量级锁竞争加剧:有线程超过10次,或者自旋锁线程数超过CPU核数的一半,1.6以后加入自适应自旋,JVM自己控
自旋是消耗CPU资源的,如果时间过长或者自旋线程数多,CPU会被大量消耗
6、偏向锁是否一定比自旋锁效率高重量级锁有等待队列,所有拿不到锁的进入等待队列,不需要消耗CPU资源
不一定,在明确知道会有多线程竞争的情况下,偏向锁肯定会涉及锁撤销,这时候直接使用自旋锁
30、ThreadLocal机制JVM启动过程,会有很多线程竞争(明确),所以默认情况下启动是不会启动偏向锁,过一会时间再打开
对于ThreadLocal而言,常用的方法,就是get/set/initialValue方法。
ThreadLocal提供一个线程(Thread)局部变量,访问到某个变量的每一个线程都拥有自己的局部变量。说白了,ThreadLocal就是想在多线程环境下去保证成员变量的安全。
你会看到,set需要首先获得当前线程对象Thread;
然后取出当前线程对象的成员变量ThreadLocalMap;
如果ThreadLocalMap存在,那么进行KEY/VALUE设置,KEY就是ThreadLocal;
如果ThreadLocalMap没有,那么创建一个;
31、ThreadLocal机制的内存泄露说白了,当前线程中存在一个Map变量,KEY是ThreadLocal,VALUE是你设置的值。
首先来说,如果把ThreadLocal置为null,那么意味着Heap中的ThreadLocal实例不在有强引用指向,只有弱引用存在,因此GC是可以回收这部分空间的,也就是key是可以回收的。但是value却存在一条从Current Thread过来的强引用链。因此只有当Current Thread销毁时,value才能得到释放。
因此,只要这个线程对象被gc回收,就不会出现内存泄露,但在threadLocal设为null和线程结束这段时间内不会被回收的,就发生了我们认为的内存泄露。最要命的是线程对象不被回收的情况,比如使用线程池的时候,线程结束是不会销毁的,再次使用的,就可能出现内存泄露。
那么如何有效的避免呢?
留言:事实上,在ThreadLocalMap中的set/getEntry方法中,会对key为null(也即是ThreadLocal为null)进行判断,如果为null的话,那么是会对value置为null的。我们也可以通过调用ThreadLocal的remove方法进行释放!
这是本人今年春招找实习工作准备总结,记录在此,如有需要的老铁可以看看,如有问题可以留言指导