1):Elastic Stack简介 ↓ ↓ ↓
1.1:简介
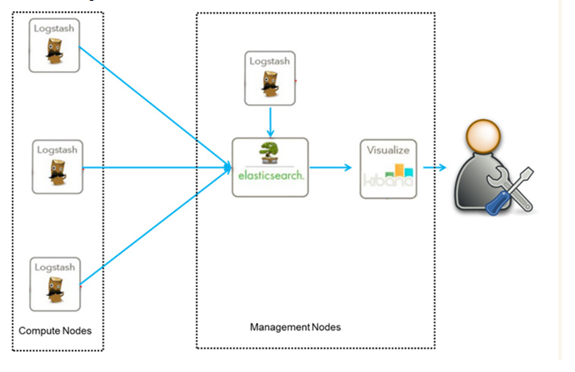
随着elk的发展,又有新成员Beats、elastic cloud的加入,所以就形成了Elastic Stack。
所以说,ELK是旧的称呼,Elastic Stack是新的名字。
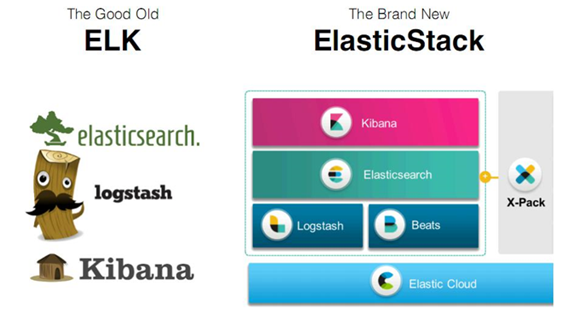
1.2:特色
处理方式灵活:elasticsearch是目前最流行的准实时全文检索引擎,具有高速检索大数据的能力。
配置简单:安装elk的每个组件,仅需配置每个组件的一个配置文件即可。修改处不多,因为大量参数已经默认配在系统中,修改想要修改的选项即可。
接口简单:采用json形式RESTFUL API接受数据并响应,无关语言。
性能高效:elasticsearch基于优秀的全文搜索技术Lucene,采用倒排索引,可以轻易地在百亿级别数据量下,搜索出想要的内容,并且是秒级响应。
灵活扩展:elasticsearch和logstash都可以根据集群规模线性拓展,elasticsearch内部自动实现集群协作。
数据展现华丽:kibana作为前端展现工具,图表华丽,配置简单。
2.3:组件介绍
Elasticsearch ↓
Elasticsearch 是使用java开发,基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。
它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash ↓
Logstash 基于java开发,是一个数据抽取转化工具。
一般工作方式为c/s架构,client端安装在需要收集信息的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch或其他组件上去。
Kibana ↓
Beats ↓
Beats 平台集合了多种单一用途数据采集器。
它们从成百上千或成千上万台机器和系统向 Logstash 或 Elasticsearch 发送数据。
Beats由如下组成:↓
Packetbeat 是一款轻量型网络数据包分析器,能够将数据发送至 Logstash 或 Elasticsearch。
Filebeat:
轻量型日志采集器。当您要面对成百上千、甚至成千上万的服务器、虚拟机和容器生成的日志时,请告别 SSH 吧。
Filebeat 将为您提供一种轻量型方法,用于转发和汇总日志与文件,让简单的事情不再繁杂。
Metricbeat :
轻量型指标采集器。Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据,从 CPU 到内存,从 Redis 到 Nginx,不一而足。
可定期获取外部系统的监控指标信息,其可以监控、收集 Apache http、HAProxy、MongoDB、MySQL、Nginx、PostgreSQL、Redis、System、Zookeeper等服务。
Winlogbeat:
轻量型 Windows 事件日志采集器。用于密切监控基于 Windows 的基础设施上发生的事件。
Winlogbeat 能够以一种轻量型的方式,将 Windows 事件日志实时地流式传输至 Elasticsearch 和 Logstash。
Auditbeat:
轻量型审计日志采集器。收集您 Linux 审计框架的数据,监控文件完整性。
Auditbeat 实时采集这些事件,然后发送到 Elastic Stack 其他部分做进一步分析。
Heartbeat:
面向运行状态监测的轻量型采集器。通过主动探测来监测服务的可用性。
通过给定 URL 列表,Heartbeat 仅仅询问:网站运行正常吗?Heartbeat 会将此信息和响应时间发送至 Elastic 的其他部分,以进行进一步分析。
Functionbeat:
面向云端数据的无服务器采集器。在作为一项功能部署在云服务提供商的功能即服务 (FaaS) 平台上后,Functionbeat 即能收集、传送并监测来自您的云服务的相关数据。
Elastic cloud:

2):Elasticsearch 是什么
2.1:搜索是什么 ?
概念:用户输入想要的关键词,返回含有该关键词的所有信息。
场景:
1、互联网搜索:谷歌、百度、各种新闻首页
2、站内搜索(垂直搜索):企业OA查询订单、人员、部门,电商网站内部搜索商品(淘宝、京东)场景。
2.2:数据库做搜索的弊端
2.2.1:站内搜索(垂直搜索):数据量小,简单搜索,可以使用数据库。
问题出现:
l 存储问题。电商网站商品上亿条时,涉及到单表数据过大必须拆分表,数据库磁盘占用过大必须分库(mycat)。
l 性能问题:解决上面问题后,查询“笔记本电脑”等关键词时,上亿条数据的商品名字段逐行扫描,性能跟不上。
l 不能分词。如搜索“笔记本电脑”,只能搜索完全和关键词一样的数据,那么数据量小时,搜索“笔记电脑”,“电脑”数据要不要给用户。
2.2.2:互联网搜索,肯定不会使用数据库搜索。数据量太大。PB级。
2.3:全文检索、倒排索引 和 Lucene
全文检索:
倒排索引。数据存储时,经行分词建立term索引库。见画图。
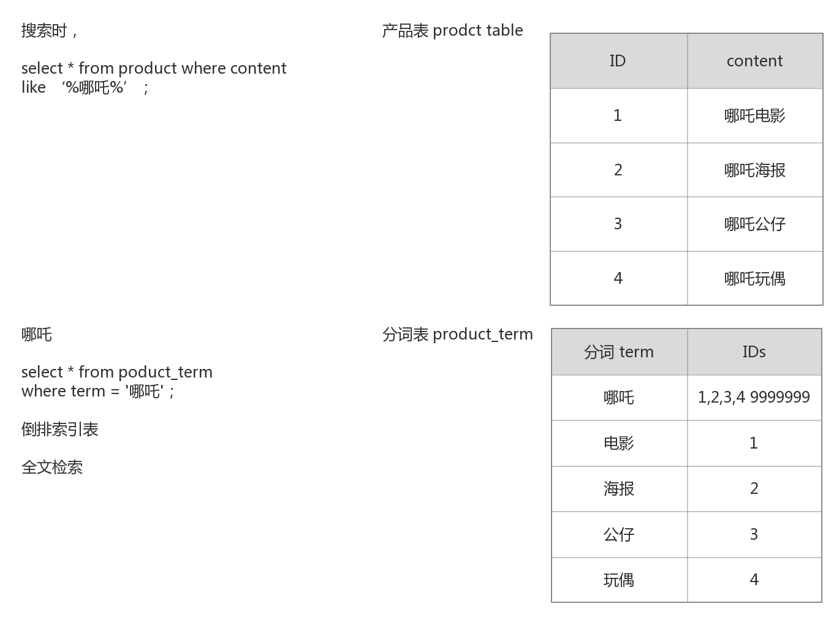
倒排索引源于实际应用中需要根据属性的值来查找记录。
这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。
由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
带有倒排索引的文件我们称为倒排
Lucene:
就是一个jar包,里面封装了全文检索的引擎、搜索的算法代码。开发时,引入lucen的jar包,通过api开发搜索相关业务。底层会在磁盘建立索引库。
2.4:什么是 Elasticsearch
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。
根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
官网:https://www.elastic.co/cn/products/elasticsearch
2.5:Elasticsearch 的功能 ?
2.5.1:分布式的 搜索引擎 和 数据分析引擎
搜索:互联网搜索、电商网站站内搜索、OA系统查询
数据分析:电商网站查询近一周哪些品类的图书销售前十;新闻网站,最近3天阅读量最高的十个关键词,舆情分析。
2.5.2:全文检索,结构化检索,数据分析
全文检索:搜索商品名称包含java的图书select * from books where book_name like "%java%"。
结构化检索:搜索商品分类为spring的图书都有哪些,select * from books where category_id='spring'
数据分析:分析每一个分类下有多少种图书,select category_id,count(*) from books group by category_id
2.5.3:对海量数据进行近实时的处理
分布式:ES自动可以将海量数据分散到多台服务器上去存储和检索,经行并行查询,提高搜索效率。相对的,Lucene是单机应用。
近实时:数据库上亿条数据查询,搜索一次耗时几个小时,是批处理(batch-processing)。而es只需秒级即可查询海量数据,所以叫近实时。秒级。
2.6:Elasticsearch 的使用场景
国外:
1、维基百科,类似百度百科,“网络七层协议”的维基百科,全文检索,高亮,搜索推荐
2、Stack Overflow(国外的程序讨论论坛),相当于程序员的贴吧。遇到it问题去上面发帖,热心网友下面回帖解答。
3、GitHub(开源代码管理),搜索上千亿行代码。
4、电商网站,检索商品
5、日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
6、商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅《java编程思想》的监控,如果价格低于27块钱,就通知我,我就去买。
7、BI系统,商业智能(Business Intelligence)。大型连锁超市,分析全国网点传回的数据,分析各个商品在什么季节的销售量最好、利润最高。
成本管理,店面租金、员工工资、负债等信息进行分析。从而部署下一个阶段的战略目标。
国内:
1、百度搜索,第一次查询,使用 es。
2、OA、ERP系统站内搜索。
2.7:Elasticsearch 的使用场景
可拓展性:
大型分布式集群(数百台服务器)技术,处理PB级数据,大公司可以使用。小公司数据量小,也可以部署在单机。大数据领域使用广泛。
技术整合:
将全文检索、数据分析、分布式相关技术整合在一起:lucene(全文检索),商用的数据分析软件(BI软件),分布式数据库(mycat)
部署简单:
开箱即用,很多默认配置不需关心,解压完成直接运行即可。拓展时,只需多部署几个实例即可,负载均衡、分片迁移集群内部自己实施。
接口简单:
使用restful api经行交互,跨语言。
功能强大:
Elasticsearch作为传统数据库的一个补充,提供了数据库所不不能提供的很多功能,如全文检索,同义词处理,相关度排名。

人生无常大肠包小肠