最近,有用户反馈自己通过redis的hmset命令写入了一个单个field为1mb,总大小100m左右的命令,在512mb内存限制的容器当中执行,结果却触发了oom killer。最后查看/var/log/syslog日志,发现内容如下。并且:这个oom是在开启aof持久化的时候触发的。

你不禁会发出疑问:一个100MB的命令怎么会让内存限制为512MB的Redis实例被kill掉呢?
下面,我先列举一些关键的信息,然后再和大家一起分析。
- Redis版本:5.0.9
- Docker容器内存限制512MB。
- 操作系统,并关闭内存交换。
Distributor ID: Debian
Description: Debian GNU/Linux 10 (buster)
Release: 10
Codename: buster
- Redis基本配置
bind 0.0.0.0
port 6379
databases 16
maxmemory 512mb
maxmemory-policy volatile-lru
appendonly yes
dir "/home/dy1/data"
daemonize yes
logfile "/home/dy1/data/redis.log"
- 命令插入语句,以node.js为例
'use strict';
const { exit } = require('process');
const resdis = require('redis');
(
async () => {
const client = resdis.createClient({ url: 'redis://192.168.65.128:6379'});
client.on('error', (err) => console.log('Redis Client Error', err));
await client.connect();
const array = ["hmset" ,"test"]
for(let i=0;i<100;i++){
const a = Buffer.alloc(1024*1024,i); // 1024kb的buffer
array.push(`${Date.now()}_${i}`,a)
}
await client.sendCommand(array);
process.exit(0)
}
)();
关键信息提供了,接下来我们会先分析一个Redis命令的执行流程,在清楚一个命令的执行流程后,我们回过头分析哪些地方会使用到内存,就可以更加准确的分析其中的原因。
指令执行流程redis命令的运行基本是由事件驱动机制协调管理的,redis在服务初始化的时候会创建一个事件管理器对象aeEventLoop,这个对象通过io多路复用模型来实现事件循环执行,而在Linux系统上则是用epoll这个库实现的,这里事件循环本文不展开讲解。目前我们只需要知道,被注册到aeEventLoop的事件,会在相应事件触发后,执行设定的方法。
命令执行流程如下图所示:
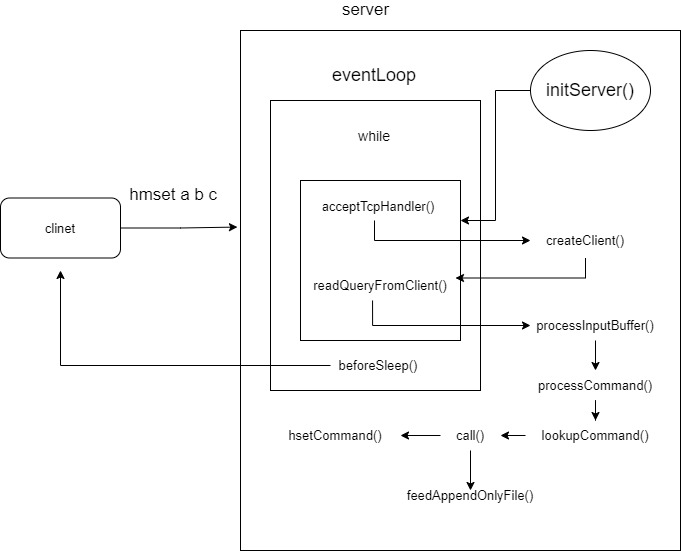
下面以一条简单的set命令为例子,介绍一下从用户发起命令请求到Redis完成处理并应答,然后执行持久化的流程是怎么样的。
Redis服务初始化阶段当你执行redis-server /path/to/conf/redis.conf启动一个Redis实例的时候,redis会进行一系列的检查工作,然后创建上面提到的aeEventLoop对象,并向aeEventLoop中注册一个事件函数,这个函数的名字就叫做acceptTcpHandler。顾名思义,它是用于处理客户端发起的连接请求,随后Redis完成初始化后,进入等待连接的状态。
void initServer(void) {
// 初始化server信息,创建aeEventLoop对象
...
server.el = aeCreateEventLoop(server.maxclients+CONFIG_FDSET_INCR);
/* 注册acceptTcpHandler实例函数 */
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
serverPanic(
"Unrecoverable error creating server.ipfd file event.");
}
}
// 后续的准备工作忽略
...
}
当客户端发起连接时,会触发acceptTcpHandler方法。这个方法最主要的作用就是为已建立的socket连接创建一个Redis客户端Client,并且向aeEventLoop注册针对当前连接的socket数据读取方法readQueryFromClient,至此客户端与redis已经建立好连接,并且客户端随时可以发送命令来操作Redis。
值得一提的是,client初始化的参数当中,有几个是我们需要重点注意的。
- querybuf 用于存放客户端发送的命令
- argc 用于标记当前命令的个数,如
set a b则argc=3 - argv 它是一个指针数组,用于存放每一个命令的信息,以
set a b为例,则argv[0]指向的就是set这个字符串。
client *createClient(int fd) {
client *c = zmalloc(sizeof(client));
/* 为当前连接注册readQueryFromClient方法 */
if (fd != -1) {
anetNonBlock(NULL,fd);
anetEnableTcpNoDelay(NULL,fd);
if (server.tcpkeepalive)
anetKeepAlive(NULL,fd,server.tcpkeepalive);
if (aeCreateFileEvent(server.el,fd,AE_READABLE,
readQueryFromClient, c) == AE_ERR)
{
close(fd);
zfree(c);
return NULL;
}
}
...
// 初始化当前连接的参数
uint64_t client_id;
atomicGetIncr(server.next_client_id,client_id,1);
c->querybuf = sdsempty();
c->argc = 0;
c->argv = NULL;
...
return c;
}
当客户端向redis发送set a b命令后,readQueryFromClient()方法将会被触发。这个方法会调用processInputBuffer方法,不间断的读取用户发送的命令,直到完成读取为止,与此同时,还会将命令放入querybuf当中,并将解析后的命令参数放入argc和argv中。在完成读取的时候处理命令。
/
void processInputBuffer(client *c) {
server.current_client = c;
/* 当已读取的pos小于querybuf长度时 会循环读取 */
while(c->qb_pos < sdslen(c->querybuf)) {
...
// 根据命令类型读取,并将命令保存到querybuf中,同时解析命令后放入argc和argv中
if (c->reqtype == PROTO_REQ_INLINE) {
if (processInlineBuffer(c) != C_OK) break;
} else if (c->reqtype == PROTO_REQ_MULTIBULK) {
if (processMultibulkBuffer(c) != C_OK) break;
} else {
serverPanic("Unknown request type");
}
/*无效命令,重置客户端 */
if (c->argc == 0) {
resetClient(c);
} else {
/* 执行命令,. */
if (processCommand(c) == C_OK) {
// 一些执行完毕后的处理
...
}
}
}
...
}
在经过一系列的准备工作后,redis执行命令所需要的参数都已经准备好了,接下来就是解析命令并检查执行环境,然后执行命令。弄清楚这一步,你就可以联通很多关于Redis的知识网络。
逻辑处理包括:
- 命令为quit则退出
- 调用
lookupCommand方法查找具体的命令处理函数,如set a b对应的就是setCommand - 如果配置开启密码,除auth命令外检查权限验证
- 集群模式相关,处理重定向问题。
- 处理maxmemory 情况,尝试进行回收一下,如果不行,则返回异常
- 当前为主实例且硬盘持久化出现问题,不允许写命令
- 处理repl_min_slaves_to_write配置,当从实例小于配置数,不允许执行写命令
- 检查是否为只读从实例,只读从实例不允许写操作
- 客户端类型为发布订阅 只允许部分命令
- 服务器为slave,但是没有连接 master 时,只会执行带有 CMD_STALE 标志的命令,如 info slave of等
- Redis正在加载数据库时,只会执行带有 CMD_LOADING 标志的命令。
- 执行lua脚本阻塞时,只会执行部分命令,其余都会拒绝
- 如果是事务命令,则开启事务,命令进入等待队列;否则直接执行命令。
int processCommand(client *c) {
// 命令为quit退出
...
/* 查找具体的命令处理函数 */
c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr);
if (!c->cmd) {
flagTransaction(c);
sds args = sdsempty();
int i;
for (i=1; i < c->argc && sdslen(args) < 128; i++)
args = sdscatprintf(args, "`%.*s`, ", 128-(int)sdslen(args), (char*)c->argv[i]->ptr);
addReplyErrorFormat(c,"unknown command `%s`, with args beginning with: %s",
(char*)c->argv[0]->ptr, args);
sdsfree(args);
return C_OK;
} else if ((c->cmd->arity > 0 && c->cmd->arity != c->argc) ||
(c->argc < -c->cmd->arity)) {
flagTransaction(c);
addReplyErrorFormat(c,"wrong number of arguments for '%s' command",
c->cmd->name);
return C_OK;
}
/* 检查权限验证 */
if (server.requirepass && !c->authenticated && c->cmd->proc != authCommand)
{
flagTransaction(c);
addReply(c,shared.noautherr);
return C_OK;
}
// 集群模式相关代码。。
/*处理maxmemory 情况,尝试进行回收一下,如果不行,则返回异常 */
if (server.maxmemory && !server.lua_timedout) {
int out_of_memory = freeMemoryIfNeededAndSafe() == C_ERR;
if (out_of_memory &&
(c->cmd->flags & CMD_DENYOOM ||
(c->flags & CLIENT_MULTI && c->cmd->proc != execCommand))) {
flagTransaction(c);
addReply(c, shared.oomerr);
return C_OK;
}
if (c->cmd->proc == evalCommand || c->cmd->proc == evalShaCommand) {
server.lua_oom = out_of_memory;
}
}
/* 当前为主实例且硬盘持久化出现问题,不允许写命令*/
...
/* 处理repl_min_slaves_to_write配置,当从实例小于配置数,不允许执行写命令 */
...
/*只读从实例不允许写操作 */
...
/* 客户端类型为发布订阅 只允许部分命令*/
...
/* 服务器为slave,但是没有连接 master 时,只会执行带有 CMD_STALE 标志的命令,如 info 等 */
if (server.masterhost && server.repl_state != REPL_STATE_CONNECTED &&
server.repl_serve_stale_data == 0 &&
!(c->cmd->flags & CMD_STALE))
{
flagTransaction(c);
addReply(c, shared.masterdownerr);
return C_OK;
}
/* 正在加载数据库时,只会执行带有 CMD_LOADING 标志的命令 */
if (server.loading && !(c->cmd->flags & CMD_LOADING)) {
addReply(c, shared.loadingerr);
return C_OK;
}
/* 执行lua脚本阻塞时,只会执行部分命令,其余都会拒绝 */
if (server.lua_timedout &&
c->cmd->proc != authCommand &&
c->cmd->proc != replconfCommand &&
!(c->cmd->proc == shutdownCommand &&
c->argc == 2 &&
tolower(((char*)c->argv[1]->ptr)[0]) == 'n') &&
!(c->cmd->proc == scriptCommand &&
c->argc == 2 &&
tolower(((char*)c->argv[1]->ptr)[0]) == 'k'))
{
flagTransaction(c);
addReply(c, shared.slowscripterr);
return C_OK;
}
/* 如果是事务命令,则开启事务,命令进入等待队列;否则直接执行命令。 */
if (c->flags & CLIENT_MULTI &&
c->cmd->proc != execCommand && c->cmd->proc != discardCommand &&
c->cmd->proc != multiCommand && c->cmd->proc != watchCommand)
{
queueMultiCommand(c);
addReply(c,shared.queued);
} else {
call(c,CMD_CALL_FULL);
c->woff = server.master_repl_offset;
if (listLength(server.ready_keys))
handleClientsBlockedOnKeys();
}
return C_OK;
}
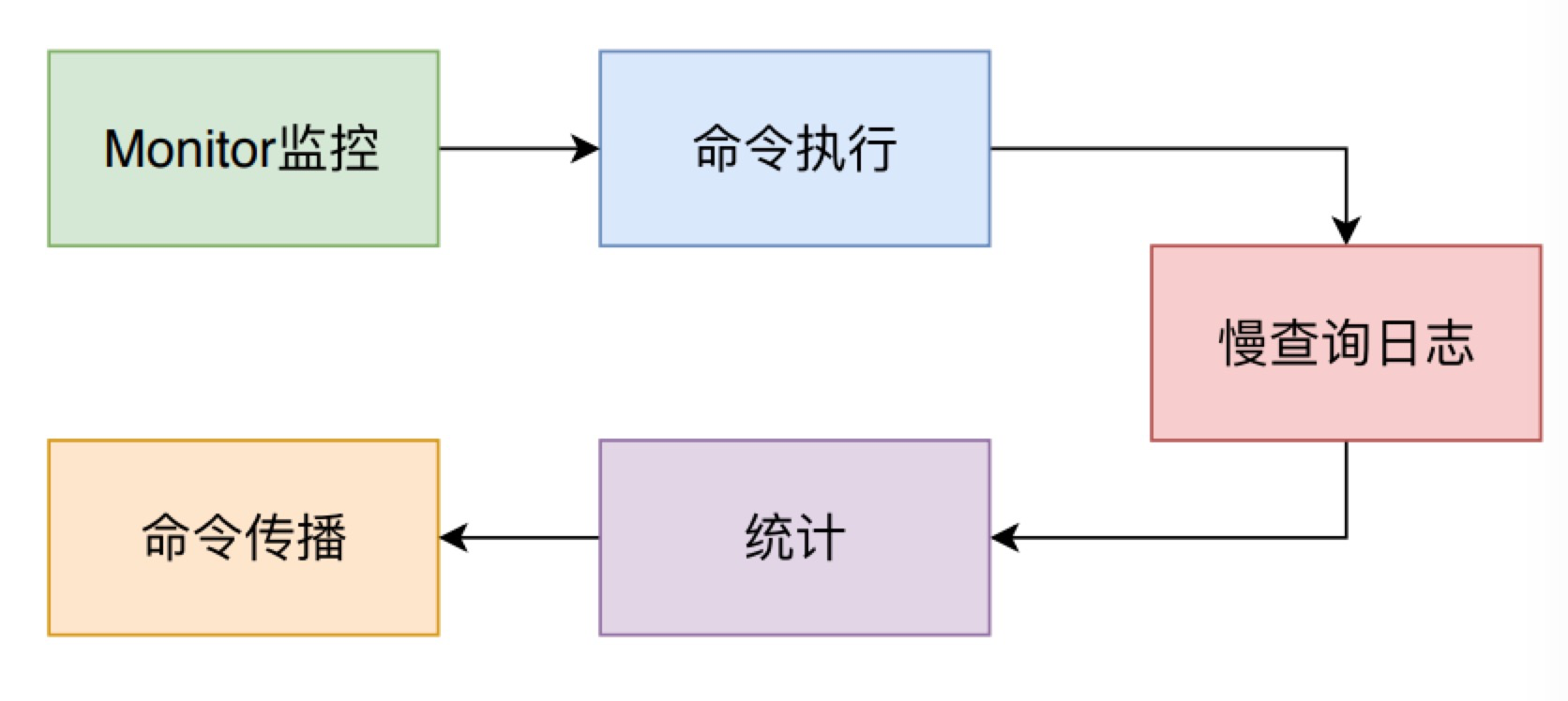
当调用call方法后,放回客户端的c.cmd指针,这里指针会指向一个具体的方法,如果你是set命令就会指向setCommand()方法。当然call()方法还有一些具体的流程如下图所示:
- 发送命令详情到执行了
monitor命令的客户端 - 执行命令
- 判断命令耗时是否需要记录慢日志。
- 统计命令的执行时间和次数
- 命令传播,将执行的命令发送给从实例和保存到aof中。
void call(client *c, int flags) {
long long dirty;
ustime_t start, duration;
int client_old_flags = c->flags;
struct redisCommand *real_cmd = c->cmd;
// 处理monitor 逻辑
...
/* Call the command. */
dirty = server.dirty;
updateCachedTime(0);
start = server.ustime;
c->cmd->proc(c);
duration = ustime()-start;
/* 根据执行时间,判断是否为慢命令 */
...
// 处理lua脚本相关的逻辑
...
// 统计命令的执行时间和次数
...
/* 这里处理命令的传播逻辑,传播一般指主从 以及写aof */
if (flags & CMD_CALL_PROPAGATE &&
(c->flags & CLIENT_PREVENT_PROP) != CLIENT_PREVENT_PROP)
{
...
// 调用propagate()方法,方法会将命令相关参数写入aof、主从相关的buf当中。
if (propagate_flags != PROPAGATE_NONE && !(c->cmd->flags & CMD_MODULE))
propagate(c->cmd,c->db->id,c->argv,c->argc,propagate_flags);
}
...
}
// 将命令相关参数写入aof、主从相关的buf当中。
void propagate(struct redisCommand *cmd, int dbid, robj **argv, int argc,
int flags)
{
if (server.aof_state != AOF_OFF && flags & PROPAGATE_AOF)
feedAppendOnlyFile(cmd,dbid,argv,argc);
if (flags & PROPAGATE_REPL)
replicationFeedSlaves(server.slaves,dbid,argv,argc);
}
至此,命令通过 c->cmd->proc(c);这段代码已经执行完毕,它的响应也在具体方法中写入Response buffer中。
在开头的图中,你会看到从readQueryFromClient()->processInputBuffer()->processCommand()->call()->hsetCommand()->addReply()这个调用链路中,一直都没有看到往客户端返回信息的方法。redis是怎么向客户端发送响应数据的呢?
答案就在aeEventLoop对象的循环方法中,方法aeMain是redis事件循环的具体逻辑,如下所示。
而beforesleep函数则包含了处理客户端响应结果返回的逻辑。
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
/* 每次Redis进入事件驱动库的主循环时,即在休眠以获取就绪文件描述符之前,都会调用此函数。 */
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
/* 开始处理事件*/
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}
下面是beforesleep主要逻辑,从注释中我们可以知道,这个方法每次Redis进入事件驱动库的主循环时。在休眠以等待新的文件描述符事件就绪之前,都会调用此函数。现在我们会关注响应部分,即redis通过handleClientsWithPendingWrites方法来对响应结果进行发送。
/* This function gets called every time Redis is entering the
* main loop of the event driven library, that is, before to sleep
* for ready file descriptors. */
void beforeSleep(struct aeEventLoop *eventLoop) {
/* 集群版方法 */
if (server.cluster_enabled) clusterBeforeSleep();
/* 执行一次过期值回收 */
if (server.active_expire_enabled && server.masterhost == NULL)
activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST);
...
/* 执行aof刷盘 */
flushAppendOnlyFile(0);
/* 处理客户端响应结果 */
handleClientsWithPendingWrites();
...
}
而到了handleClientsWithPendingWrites方法,其实就是朴实无华的遍历每个客户端,然后写入响应结果到socket文件中,当然还有一点小细节。那就是当一次写入不足以完成响应时,只能通过向aeEventLoop注册sendReplyToClient方法,以在后续事件循环中发送,避免阻塞其余客户端的响应。
int handleClientsWithPendingWrites(void) {
listIter li;
listNode *ln;
int processed = listLength(server.clients_pending_write);
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
listDelNode(server.clients_pending_write,ln);
/* If a client is protected, don't do anything,
* that may trigger write error or recreate handler. */
if (c->flags & CLIENT_PROTECTED) continue;
/* Try to write buffers to the client socket. */
if (writeToClient(c->fd,c,0) == C_ERR) continue;
/* 一次写入还没有完成响应,注册方法。 */
if (clientHasPendingReplies(c)) {
int ae_flags = AE_WRITABLE;
if (server.aof_state == AOF_ON &&
server.aof_fsync == AOF_FSYNC_ALWAYS)
{
ae_flags |= AE_BARRIER;
}
if (aeCreateFileEvent(server.el, c->fd, ae_flags,
sendReplyToClient, c) == AE_ERR)
{
freeClientAsync(c);
}
}
}
return processed;
}
在了解完命令的执行流程后,你可以清楚的知道如果执行的是开头的100MB的hmset命令,流程在哪些地方使用了较大的内存。下面我列举一下对应的方法:
readQueryFromClient()中接收客户端发送的命令并解析存放到client.agrv中hmsetCommand()将对应的参数写入Redis的DB当中。feedAppendOnlyFile()在命令完成写入,将执行的命令写入aof持久化的buffer当中。
在开始分析之前,我还需要介绍一款非常出名调试工具,名字叫做GDB。我们可以利用它”打入Redis内部“,定格每一个瞬间,以帮助我们分析每个阶段的内存占用。
执行gdb /path/to/redis-server ${pid}进入gdb调试界面。我们现在开始吧!
在此方法中,Redis需要按照协议解析命令,真正解析并保存到argv的方法路径是在readQueryFromClient->processInputBuffer->processMultibulkBuffer方法。这里就不列举源码了。其实就是方法会重复执行,每次执行解析一行命令,然后就是根据Redis的协议,生成一个Redis定义的字符串结构,并保存到argv中。
其中,如:
- 命令长度小于32kB则调用
createStringObject()创建一个字符串对象。 - 否则,调用
sdsMakeRoomFor申请适合的内存,随后再调用createObject创建字符串对象。
而这里内存占用的第一个元凶,就出在这个sdsMakeRoomFor方法中,它存在这么一段逻辑:
- 如果申请的长度小于1024KB,则赋予这个字符串对象使用长度两倍的内存空间。即:长度为50KB,它会申请100KB的内存空间。
- 否则,再原有长度的基础上额外再添加1024kb的空间。即:长度为1024kb时,它会申请2048kb的内存空间。
sds sdsMakeRoomFor(sds s, size_t addlen) {
// 前置处理
...
// SDS_MAX_PREALLOC =1024*1024
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
// 更具不同的逻辑调用s_realloc 或s_malloc 申请内存
...
return s;
}
因此,我们在Redis将命令解析完毕并准备进入processCommand()方法打上一个断点,观察一下此时的内存占用是多少。

可以看到,此时:
Redis自己统计的内存使用量used_memory为: 264126272 约等于251.89MB
操作系统统计的内存使用量rss为:273690624 约等于 261.01MB
hmsetCommand()经过一系列的检查和处理,Redis来到了执行命令的方法hmsetCommand。而主要的处理逻辑正方法hashTypeSet当中。而hashTypeSet的主要逻辑就是:
- 判断当前的hash类型是ziplist数据结构还是hashtable数据结构。
- 查找要set的key值是否存在
- 若不存在,则将要插入的value,也就是argv里面的值,调用sdsup()方法复制一份。
- 判断是否需要删除argv的值,这里因为开启了aof,后续要用到,所以不会删除。
- 返回成功。
void hsetCommand(client *c) {
// 查找目标hash集合对象
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
hashTypeTryConversion(o,c->argv,2,c->argc-1);
// 以field value 的形式写入目标hash集合中
for (i = 2; i < c->argc; i += 2)
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
/* HMSET (deprecated) and HSET return value is different. */
// 后置处理
...
}
int hashTypeSet(robj *o, sds field, sds value, int flags) {
int update = 0;
// ziplist格式,忽略
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
...
} else if (o->encoding == OBJ_ENCODING_HT) {
dictEntry *de = dictFind(o->ptr,field);
if (de) {
// field已存在,删除原有value,并写入当前value
sdsfree(dictGetVal(de));
if (flags & HASH_SET_TAKE_VALUE) {
dictGetVal(de) = value;
value = NULL;
} else {
dictGetVal(de) = sdsdup(value);
}
update = 1;
} else {
sds f,v;
// key不存在,则field 和value 都复制并写入。
if (flags & HASH_SET_TAKE_FIELD) {
f = field;
field = NULL;
} else {
f = sdsdup(field);
}
if (flags & HASH_SET_TAKE_VALUE) {
v = value;
value = NULL;
} else {
v = sdsdup(value);
}
dictAdd(o->ptr,f,v);
}
} else {
serverPanic("Unknown hash encoding");
}
/* 因为需要写aof,这里不满足条件,不会释放value和field */
if (flags & HASH_SET_TAKE_FIELD && field) sdsfree(field);
if (flags & HASH_SET_TAKE_VALUE && value) sdsfree(value);
return update;
}
因为复制了一份argv的数据,所以这里的内存会再次暴增,我们把断点停到命令执行完毕那一行代码,查看内存容量。

Redis自己统计的内存使用量used_memory为: 395204296约等于376.89mb
操作系统统计的内存使用量rss为:405184512 约等于 386.41mb
feedAppendOnlyFile()命令执行完毕后,由于Redis配置的aof持久化,进入feedAppendOnlyFile()。这会进入catAppendOnlyGenericCommand()方法,它就是把argv中的值再解析成RESP格式的命令,如$3\r\nset$4\r\ntest$3\r\babc,然后再写入一个临时buf里面。
注意!!这里写入的是临时buf,并不是aof_buf。所以,他还需要将临时buf再复制一份到aof_buf里面,虽然在feedAppendOnlyFile结束后会将临时buf的内存释放。但是还是会造成一个超高的内存峰值。
void feedAppendOnlyFile(struct redisCommand *cmd, int dictid, robj **argv, int argc) {
sds buf = sdsempty();
robj *tmpargv[3];
// 一大堆特殊命令判断
if (dictid != server.aof_selected_db) {
} else {
/* 最后进入此,解析argv并放入buf中 */
buf = catAppendOnlyGenericCommand(buf,argc,argv);
}
/* 复制buf到aof_buf中 */
if (server.aof_state == AOF_ON)
server.aof_buf = sdscatlen(server.aof_buf,buf,sdslen(buf));
/* 如果aof正在进行,则追加到aof_buf末尾 */
if (server.aof_child_pid != -1)
aofRewriteBufferAppend((unsigned char*)buf,sdslen(buf));
// 释放临时buf
sdsfree(buf);
}
我们在catAppendOnlyGenericCommand执行完毕后打上断点,内存如下所示

随后在sdscatlen后打上断点,内存使用量如下

最终内存实际占用量来到了恐怖的:882995200 约等于842.08MB。
因为这是我本地模拟调试的Redis实例,所以我并没有开启Cgroup内存限制,而如果是在Docker里面限制了内存的实例,此时已经OOM了。
小结本文主要以一个hmset命令为例,介绍了Redis从接收请求到执行结果返回所需要进行的步骤。以及介绍了当你在开启了AOF持久化执行hmset命令插入一个bigkey时,Redis需要使用的内存会远超你的想象。因此,在开发中要尽量避免使用BigKey,它不仅会使内存峰值暴增,同时读写的时候也会大幅度降低Redis的响应速度和并发度。
另外,Redis算是一众开源项目中比较容易学习的,由于篇幅原因本文侧重点是介绍大体的使用流程,但其实它还有精妙的数据结构设计没有被提及。不过,有了上面的流程介绍,你可以自己随心所欲的通过GDB进入Redis内部,一步一步的进行学习和理解。把Redis运行起来吧!
最后一点,其实Redis在启动的时候有对内核参数做告警,如所示:
# WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
# WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
# WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled.
这其中的设置也影响了内存的使用量,具体情况可以自己去探索一遍~~
【本文来源:韩国服务器 http://www.558idc.com/kt.html欢迎留下您的宝贵建议】