目录 数组定义 栈队列字典堆等 stack queue set unordered_set map unordered_map 优先队列 sort 字符串string c_str() 字符串分割 strtok() strtok_r() 二叉树节点定义 数组定义 点击查看代码 //一维数组定义
- 数组定义
- 栈队列字典堆等
- stack
- queue
- set && unordered_set
- map && unordered_map
- 优先队列
- sort
- 字符串string
- c_str()
- 字符串分割
- strtok()
- strtok_r()
- 二叉树节点定义
点击查看代码
//一维数组定义
int num[10];
vector<int> num(10, 0)//定义一个包含十个int的数组,初始值为0
//二维数组定义
int array[3][4] = {{1, 2, 3, 4}, {5, 6, 7, 8}, {9, 10, 11, 12}};
vector<vector<int> > array(rows,vector<int>(columns, 0));//定义二维数组,值初始化为0
栈
点击查看代码
#include<stack>
stack<int> sta;//定义一个栈sta
int x;
sta.empty(); //堆栈为空则返回真
sta.pop(); //移除栈顶元素
sta.push(x); //在栈顶增加元素
s.size(); //返回栈中元素数目
s.top(); //返回栈顶元素
队列
点击查看代码
#include<queue>
queue<int> que; //定义一个queue的变量
int x;
que.empty; //查看是否为空 是的话返回1,不是返回0
que.push(x); //从已有元素后面增加元素
que.size(); //输出现有元素的个数
que.front(); //显示队列第一个元素
que.back(); //显示队列最后一个元素
que.pop(); //删除队列第一个元素
集合set就是集合,STL的set用二叉树实现,集合中的每个元素只出现一次(参照数学中集合的互斥性),并且是排好序的(默认按键值升序排列)
set具有迭代器set<int>::iterator i 定义一个迭代器,名为i 可以把迭代器理解为C语言的指针
C++ STL中set与unordered_set区别和map与unordered_map区别类似:
- set基于红黑树实现,红黑树具有自动排序功能,因此set内部所有数据任何时候都是有序的
- unordered_set基于哈希表实现,数据插入和查找的时间复杂度很低,几乎是常数时间,代价是消耗更多的内存,没有自动排序功能。
点击查看代码
#include<set>
set<int> q; //以int型为例 默认按键值升序
set<int,greater<int>> p; //降序排列
int x;
q.insert(x); //将x插入q中
q.erase(x); //删除q中的x元素,返回0或1,0表示set中不存在x
q.clear(); //清空q
q.empty(); //判断q是否为空,若是返回1,否则返回0
q.size(); //返回q中元素的个数
q.find(x); //在q中查找x,返回x的迭代器,若x不存在,则返回指向q尾部的迭代器即 q.end()
q.lower_bound(x); //返回一个迭代器,指向第一个键值不小于x的元素
q.upper_bound(x); //返回一个迭代器,指向第一个键值大于x的元素
q.rend(); //返回第一个元素的的前一个元素迭代器
q.begin(); //返回指向q中第一个元素的迭代器
q.end(); //返回指向q最后一个元素下一个位置的迭代器
q.rbegin(); //返回最后一个元素
- map: map内部实现了一个红黑树(红黑树是非严格平衡二叉搜索树,而AVL是严格平衡二叉搜索树),红黑树具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素。因此,对于map进行的查找,删除,添加等一系列的操作都相当于是对红黑树进行的操作。map中的元素是按照二叉搜索树(又名二叉查找树、二叉排序树,特点就是左子树上所有节点的键值都小于根节点的键值,右子树所有节点的键值都大于根节点的键值)存储的,使用中序遍历可将键值按照从小到大遍历出来。
- unordered_map: unordered_map内部实现了一个哈希表(也叫散列表,通过把关键码值映射到Hash表中一个位置来访问记录,查找的时间复杂度可达到O(1),其在海量数据处理中有着广泛应用)。因此,其元素的排列顺序是无序的。
- map和unordered_map的使用unordered_map的用法和map是一样的,提供了 insert,size,count等操作,并且里面的元素也是以pair类型来存贮的。其底层实现是完全不同的,上方已经解释了,但是就外部使用来说却是一致的。
点击查看代码
#include <iostream>
#include <unordered_map>
#include <map>
#include <string>
using namespace std;
int main()
{
//注意:C++11才开始支持括号初始化
unordered_map<int, string> myMap={{ 5, "张大" },{ 6, "李五" }};//使用{}赋值
myMap[2] = "李四"; //使用[ ]进行单个插入,若已存在键值2,则赋值修改,若无则插入。
myMap.insert(pair<int, string>(3, "陈二"));//使用insert和pair插入
//遍历输出+迭代器的使用
auto iter = myMap.begin();//auto自动识别为迭代器类型unordered_map<int,string>::iterator
while (iter!= myMap.end())
{
cout << iter->first << "," << iter->second << endl;
++iter;
}
//查找元素并输出+迭代器的使用
auto iterator = myMap.find(2);//find()返回一个指向2的迭代器
if (iterator != myMap.end())
cout << endl<< iterator->first << "," << iterator->second << endl;
system("pause");
return 0;
}
优先队列具有队列的所有特性,包括基本操作,只是在这基础上添加了内部的一个排序,它本质是一个堆实现的
定义:priority_queue<Type, Container, Functional>
Type 就是数据类型,Container 就是容器类型(Container必须是用数组实现的容器,比如vector,deque等等,但不能用 list。STL里面默认用的是vector),Functional 就是比较的方式,当需要用自定义的数据类型时才需要传入这三个参数,使用基本数据类型时,只需要传入数据类型,默认是大顶堆
点击查看代码
#include<iostream>
#include<queue>
using namespace std;
int main(){
//升序队列,小顶堆
priority_queue<int, vector<int>, greater<int>> up_q;
//降序队列,大顶堆
priority_queue<int, vector<int>, less<int>> down_q;
//对于基础类型,默认是大顶堆
priority_queue<int> default_q;
//等同于priority_queue<int, vector<int>, less<int>> down_q
//greater 和 less 是std实现的两个仿函数
//和队列的操作基本相同
up_q.top(); //访问队头元素
up_q.empty(); //队列是否为空
up_q.size(); //返回队列内元素个数
up_q.push(); //插入元素到队尾 (并排序)
up_q.emplace(); //原地构造一个元素并插入队列
up_q.pop(); //弹出队头元素
up_q.swap(value, value); //交换内容
}
自定义数据类型
点击查看代码
#include<iostream>
#include<queue>
using namespace std;
struct student{
int score;
string name;
int student_number;
//重载<运算符,用于优先级比较,以成绩排名
bool operator<(const student& stu) const {
return this->score < stu.score;//大顶堆
}
//构造函数
student(int sco, string na, int sn):score(sco), name(na), student_number(sn){}
};
//自定义比较函数
struct student_compare_score_greater{
bool operator() (const student& stu_a, const student& stu_b){
return stu_a.score > stu_b.score;//小顶堆
}
};
int main(){
student s1(89, "wang", 1001001);
student s2(76, "Li", 1001721);
student s3(100, "Zhao", 1001321);
priority_queue<student> p5;
p5.push(s1);
p5.push(s2);
p5.push(s3);
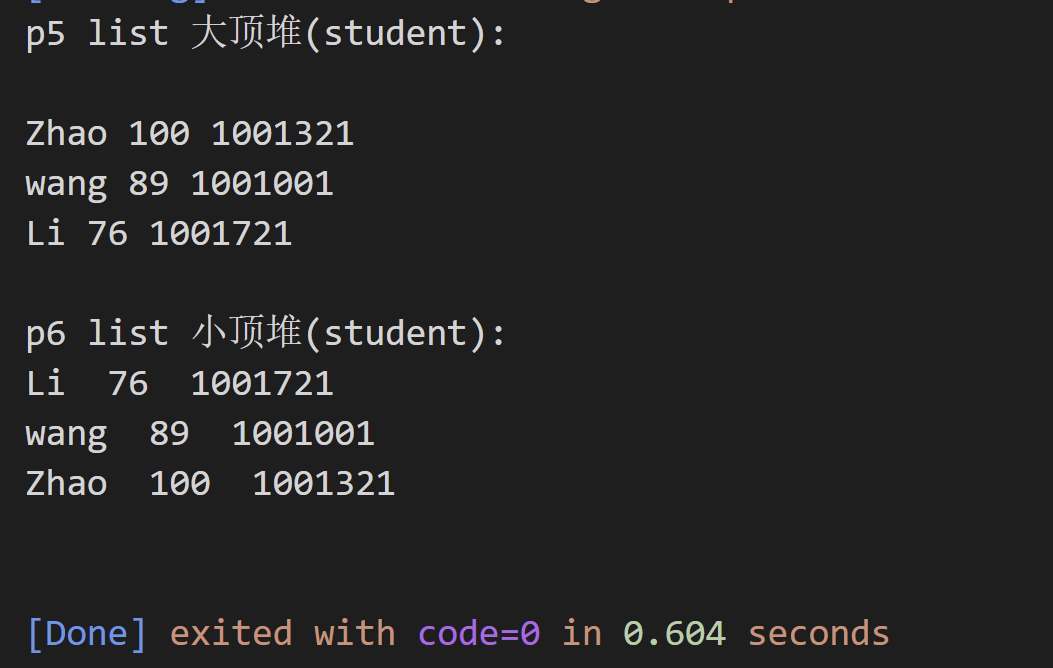
cout << "p5 list 大顶堆(student): " << endl << endl;
while (p5.size())
{
cout << p5.top().name << " " << p5.top().score << " " << p5.top().student_number << endl;;
p5.pop();
}
cout << endl;
// 改为成绩由低到高
priority_queue<student, vector<student>, student_compare_score_greater> p6;
p6.push(s1);
p6.push(s2);
p6.push(s3);
cout << "p6 list 小顶堆(student): " << endl;
while (p6.size())
{
cout << p6.top().name << " " << p6.top().score << " " << p6.top().student_number << endl;;
p6.pop();
}
cout << endl;
}
运行结果:
原型:char* strtok(char *str, const char *delim);
功能:分解字符串为一段字符串
参数:str为要分解的字符串,delim为分割字符串.str必须为一个char型数组,不能定义成指针形式
返回值:从str开头的一个被分割的串,当没有被分割的串则返回NULL
其他:strtok函数线程不安全,可以使用strtok_r替代
对于string str类型的字符串,要先进行转换
string str;
int len = str.size();
char char_ptr[len + 1];
//或者 char* char_ptr = new char[len + 1];
strcpy(char_ptr, str);
strtok使用实例:
点击查看代码
#include<iostream>
#include<cstring>
using namespace std;
int main(){
//char str = "This is a sentence with 7 tokens";
string str = "This is a sentence with 7 tokens";
char *char_ptr = new char[str.size() + 1];
strcpy(char_ptr, str.c_str());
char *tokenPtr;
tokenPtr = strtok(char_ptr, " "); //char_ptr必须是一个char数组,不能定义成指针形式
while (tokenPtr != NULL)
{
cout << tokenPtr << "\n";
tokenPtr = strtok(NULL, " ");
}
//cout << "After strtok, sentence = \n" << tokenPtr << endl;
return 0;
}