ClickHouse是什么数据库?ClickHouse速度有多快?应用场景是怎么样的?ClickHouse是关系型数据库吗?ClickHouse目前是很火爆的一款面向OLAP的数据,可以提供秒级的大数据查询。
Google于2003~2006年相继发表了三篇论文“Google File System”“Google MapReduce”和“Google Bigtable”,将大数据的处理技术带进了大众视野。2006年开源项目Hadoop的出现,标志着大数据技术普及的开始,大数据技术真正开始走向普罗大众。长期以来受限于数据库处理能力的大数据技术,开始了波澜壮阔的技术革新浪潮席卷而来。Hadoop最初指代的是分布式文件系统HDFS和MapReduce计算框架,但是它一路高歌猛进,在此基础之上像搭积木一般快速发展成为一个庞大的生态,包括Yarn、Hive、HBase、Spark等数十种之多组件相继开源。Hadoop全家桶很快成为了主流。传统关系型数据库所构建的数据仓库,被以Hive为代表的大数据技术所取代,数据查询分析的查询计算引擎Spark、Impala、Kylin等都出来了。Hadoop成为大数据的代名词。
Hadoop虽然带来了诸多便利性,随着时代的发展,但是也带来了一些新的问题。
- Hadoop生态化的两面性:臃肿和复杂。Hadoop生态下的每种组件都自成一体、相互独立,强强组合的技术组件有些时候显得过于笨重了。
- 随着现代化终端系统对实效性的要求越来越高,Hadoop在海量数据和高时效性的双重压力下,速度有点更不上了。
当然这是hadoop生态的确定,但是目前最普及的方案还是hadoop莫属,但是hadoop生态在大数据量的查询和组件的笨重确实存在,在日常的数据开发中,数据分析,BI等都需要查询数据,目前的hadoop查询引擎提供的查询速度,相对于ClickHouse,会慢很多。
所以,这款非Hadoop生态、简单、自成一体的技术组件ClickHouse横空出世。
ClickHouse背后的研发团队是一家俄罗斯本土的互联网企业Yandex公司,2011年在纳斯达克上市,它是现今世界上最大的俄语搜索引擎,占据了本国47%以上的搜索市场,Google是它的直接竞争对手。 ClickHouse的前身是一款在线流量分析的产品Yandex.Metrica,类似Google Analytics,随着Yandex.Metrica业务的发展,其底层架构历经四个阶段,最终形成了大家现在所看到的ClickHouse。
ClickHouse的定义及其优缺点ClickHouse是一款高性能、MPP架构、列式存储、具有完备DBMS功能的OLAP数据库。
ClickHouse可以在存储数据超过20万亿行的情况下,做到了90%的查询能够在1秒内返回。它基本能够满足各种数据分析类的场景,并且随着数据体量的增大,它与Spark、Impala、Kylin对比,优势也会变得越为明显。
ClickHouse适用于商业智能领域(BI),也能够被广泛应用于广告流量、Web、App流量、电信、金融、电子商务、信息安全、网络游戏、物联网等众多其他领域。应该说它适合的场景,就是OLAP。
ClickHouse不是万能的。它对于OLTP事务性操作的场景支持有限,它有以下几点不足。
- 不支持事务。
- 不擅长根据主键按行粒度进行查询(虽然支持),故不应该把ClickHouse当作Key-Value数据库使用。
- 不擅长按行删除数据(虽然支持)。
这些弱点并不能视为ClickHouse的缺点,事实上其他同类高性能的OLAP数据库同样也不擅长上述的这些方面。因为对于一款OLAP数据库而言,上述这些能力并不是重点,只能说这是为了极致查询性能所做的权衡。
ClickHouse为何这么快的原因前面我们说了ClickHouse以在存储数据超过20万亿行的情况下,在1秒内返回查询,那它是怎么做到的?主要有下面的原因。
-
列式存储与数据压缩
列式存储和数据压缩,对于一款高性能数据库来说是必不可少的。如果你想让查询变得更快,那么最简单且有效的方法是减少数据扫描范围和数据传输时的大小,列式存储和数据压缩就可以做到这两点。 -
向量化执行
能升级硬件解决的问题,千万别优化程序。能用钱解决的问题,那都不是问题。
向量化执行,可以简单地看作一项消除程序中循环的优化,是基于底层硬件实现的优化。这里用一个形象的例子比喻。小胡经营了一家果汁店,虽然店里的鲜榨苹果汁深受大家喜爱,但客户总是抱怨制作果汁的速度太慢。小胡的店里只有一台榨汁机,每次他都会从篮子里拿出一个苹果,放到榨汁机内等待出汁。如果有8个客户,每个客户都点了一杯苹果汁,那么小胡需要重复循环8次上述的榨汁流程,才能榨出8杯苹果汁。如果制作一杯果汁需要5分钟,那么全部制作完毕则需要40分钟。为了提升果汁的制作速度,小胡想出了一个办法。他将榨汁机的数量从1台增加到了8台,这么一来,他就可以从篮子里一次性拿出8个苹果,分别放入8台榨汁机同时榨汁。此时,小胡只需要5分钟就能够制作出8杯苹果汁。为了制作n杯果汁,非向量化执行的方式是用1台榨汁机重复循环制作n次,而向量化执行的方式是用n台榨汁机只执行1次。
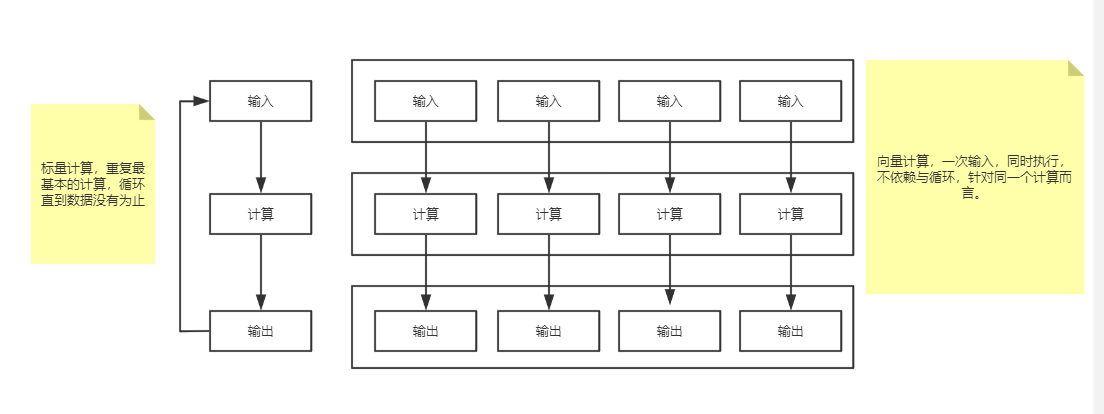
上图中,右侧为vectorization(向量化计算),左侧为经典的标量计算。将多次for循环计算变成一次计算完全仰仗于CPU的SIMD指令集,SIMD指令可以在一条cpu指令上处理2、4、8或者更多份的数据。在Intel处理器上,这个称之为SSE以及后来的AVX;在ARM处理器上,这个称之为NEON。
因此简单来说,向量化计算就是将一个loop——处理一个array的时候每次处理1个数据共处理N次,转化为vectorization——处理一个array的时候每次同时处理8个数据共处理N/4次,假如cpu指令上可以处理更多份的数据,设为M,那就是N/M次。
为了实现向量化执行,需要利用CPU的SIMD指令。SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据。现代计算机系统概念中,它是通过数据并行以提高性能的一种实现方式,它的原理是在CPU寄存器层面实现数据的并行操作。ClickHouse目前利用SSE4.2指令集实现向量化执行。
-
多样化的表引擎
与MySQL类似,ClickHouse也将存储部分进行了抽象,把存储引擎作为一层独立的接口。目前ClickHouse共拥有合并树、内存、文件、接口和其他6大类20多种表引擎。每一种表引擎都有着各自的特点,用户可以根据实际业务场景的要求,选择合适的表引擎使用。 -
多线程与分布式
多线程处理就是通过线程级并行的方式实现了性能的提升,ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。这种设计下,可以使得ClickHouse单条Query就能利用整机所有CPU,极致的并行处理能力,极大的降低了查询延时。
而分布式数据属于基于分而治之的基本思想,实现的优化,如果一台服务器性能吃紧,那么就利用多台服务的资源协同处理。这个前提是需要在数据层面实现数据的分布式,因为计算移动比数据移动更加划算,在各服务器之间,通过网络传输数据的成本是高昂的,所以预先将数据分布到各台服务器,将数据的计算查询直接下推到数据所在的服务器。
ClickHouse相关资料分享如果还想了解更多关于ClickHouse,可以看看这个文档,也可以看看ClickHouse官方网站的文档
ClickHouse经典中文文档分享
文章参考:ClickHouse(01)什么是ClickHouse,ClickHouse适用于什么场景
【转自:外国服务器 http://www.558idc.com/shsgf.html转载请说明出处】