写在前面:
LightGBM 用了很久了,但是一直没有对其进行总结,本文从 LightGBM 的使用、原理及参数调优三个方面进行简要梳理。
目录
- 开箱即用
- quickstart
- sklearn 接口
- 增量学习
- 原理
- 回顾Xgboost
- LightGBM
- 直方图算法
- Leaf-wise 生长
- 类别型特征支持
- 并行支持
- 不均衡数据处理
- 参数调优
- 参数说明
- 核心参数
- 超参
- 调优
- 自动调参
- 特征重要性
- 参数说明
- references
使用 LightGBM 官方接口,核心步骤
- 定义参数
- 构造数据
- train
- predict
# 1.定义参数
config = json.load(open("configs/lightgbm_config.json", 'r'))
# 2. 构造数据
index = int(len(features)*0.9)
train_fts, train_lbls = features[:index], labels[:index]
val_fts, val_lbls = features[index:], labels[index:]
train_data = lgb.Dataset(train_fts, label=train_lbls)
val_data = lgb.Dataset(val_fts, label=val_lbls)
# 3. train
bst = lgb.train(params=config, train_set=train_data, valid_sets=[val_data])
# 4. predict
lgb.predict(val_data)
# lightgbm_config.json
{
"objective":"binary",
"task":"train",
"boosting":"gbdt",
"num_iterations":500,
"learning_rate":0.1,
"max_depth":-1,
"num_leaves":64,
"tree_learner":"serial",
"num_threads":0,
"device_type":"cpu",
"seed":0,
"min_data_in_leaf":100,
"min_sum_hessian_in_leaf":0.001,
"bagging_fraction":0.9,
"bagging_freq":1,
"bagging_seed":0,
"feature_fraction":0.9,
"feature_fraction_bynode":0.9,
"feature_fraction_seed":0,
"early_stopping_rounds":10,
"first_metric_only":true,
"max_delta_step":0,
"lambda_l1":0,
"lambda_l2":1,
"verbosity":2,
"is_unbalance":true,
"sigmoid":1,
"boost_from_average":true,
"metric":[
"binary_logloss",
"auc",
"binary_error"
]
}
import lightgbm as lgb
# 1. config
"""
objective parameter:
‘regression’ for LGBMRegressor
‘binary’ or ‘multiclass’ for LGBMClassifier
‘lambdarank’ for LGBMRanker.
"""
lgb_clf = lgb.LGBMModel(
objective = 'binary',
metric = 'binary_logloss,auc',
learning_rate = 0.1,
bagging_fraction = 0.8,
feature_fraction = 0.9,
bagging_freq = 5,
n_estimators = 300,
max_depth = 4,
is_unbalance = True
)
# 2. fit
# 3. predict
在处理大规模数据时,数据无法一次性载入内存,使用增量训练。
主要通过两个参数实现:
- init_model
- keep_training_booster
详细方法见 增量学习/训练
原理
在LightGBM,Xgboost一直是kaggle的屠榜神器之一,但是,一切都在进步~
回顾Xgboost-
贪心算法生成树,时间复杂度\(O(ndKlogn)\),\(d\) 个特征,每个特征排序需要\(O(nlogn)\),树深度为\(K\)
- pre-sorting 对特征进行预排序并且需要保存排序后的索引值(为了后续快速的计算分裂点),因此内存需要训练数据的两倍。
- 在遍历每一个分割点的时候,都需要进行分裂增益的计算,
-
Level-wise 生长,并行计算每一层的分裂节点
- 提高了训练速度
- 但同时也因为节点增益过小增加了很多不必要的分裂,增加了计算量
- 基于 Histogram 的决策树算法
- 带深度限制的 Leaf-wise 的叶子生长策略
- 直方图做差加速
- 直接支持类别特征(Categorical Feature)
- Cache命中率优化
- 基于直方图的稀疏特征优化
- 多线程优化
- 将连续的浮点特征离散成
个离散值,并构造宽度为
- 遍历训练数据,统计每个离散值在直方图中的累计统计量。
- 在进行特征选择时,只需要根据直方图的离散值,遍历寻找最优的分割点。
内存优化:
- int32存下标,float32存数据 -> 8位存储
- 内存消耗可以降低为原来的
时间优化:
- \(O(nd)\)变为\(O(kd)\)
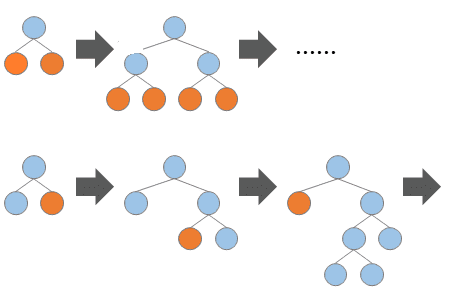
Leaf-wise(按叶子生长)生长策略
- 每次从当前所有叶子中找到分裂增益最大(一般也是数据量最大)的一个叶子
- 然后分裂,如此循环。
- 同 Level-wise 相比,在分裂次数相同的情况下,Leaf-wise 可以降低更多的误差,得到更好的精度。Leaf-wise 的缺点是可能会长出比较深的决策树,产生过拟合。因此 LightGBM 在 Leaf-wise 之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
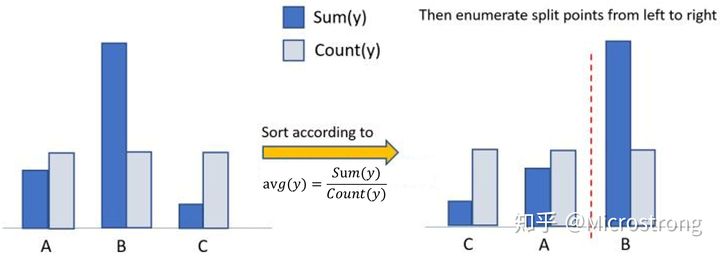
xgboost使用one-hot编码,LightGBM 采用了 Many vs Many 的切分方式,实现过程如下【7】:
-
将类别的取值当做bin,有多少个取值就是多少个bin(去除样本极少的bin)
-
统计该特征中的各取值上的样本数,按照从样本数从大到小排序,去除样本占比小于1%的类别值
-
对于剩余的特征值(可以理解为一个特征值对应一个桶),统计各个特征值对应的样本的一阶梯度之和,二阶梯度之和,根据正则化系数,算得各个桶的统计量: 一阶梯度之和 / (二阶梯度之和 + 正则化系数);
-
根据该统计量对各个桶进行从大到小排序;在排序好的桶上,进行最佳切点查找
- 特征并行:在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
- 数据并行:让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优分割点。
- 二分类
is_unbalance=True,表示 正样本的权重/负样本的权重 等于负样本的样本数/正样本的样本数- 或设置
scale_pos_weight,代表的是正类的权重,可以设置为 number of negative samples / number of positive samples
- 多分类
class weight
- 自定义 facal loss【9】
-
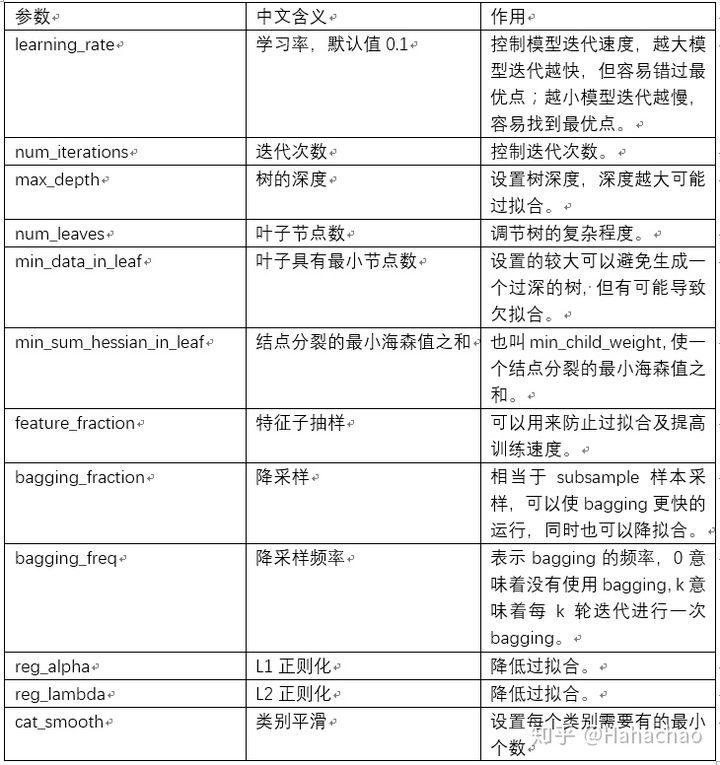
boosting / boost / boosting_type
用于指定弱学习器的类型,默认值为 ‘gbdt’,表示使用基于树的模型进行计算。还可以选择为 ‘gblinear’ 表示使用线性模型作为弱学习器。
‘gbdt’,使用梯度提升树 ‘rf’,使用随机森林 ‘dart’,不太了解,官方解释为 Dropouts meet Multiple Additive Regression Trees ‘goss’,使用单边梯度抽样算法,速度很快,但是可能欠拟合。 -
objective / application
“regression”,使用L2正则项的回归模型(默认值)。 “regression_l1”,使用L1正则项的回归模型。 “mape”,平均绝对百分比误差。 “binary”,二分类。 “multiclass”,多分类。 -
num_class
多分类问题的类别个数 -
增量训练
keep_training_booster=True # 增量训练
调优思路与方向
- 树结构参数
- max_depth :3-8
- num_leaves:最大值是
2^(max_depth) - min_data_in_leaf
- 训练速度参数
- learning_rate 和 n_estimators,结合early_stopping使用
- max_bin:变量分箱的数量,默认255。调大则准确,但容易过拟合;调小可以加速
- 防止过拟合
- lambda_l1 和 lambda_l2:
L1和L2正则化,对应XGBoost的reg_lambda和reg_alpha - min_gain_to_split:如果你设置的深度很深,但又无法向下分裂,
LGBM就会提示warning,无法找到可以分裂的了,说明数据质量已经达到了极限了。参数含义和XGBoost的gamma是一样。比较保守的搜索范围是(0, 20),它可以用作大型参数网格中的额外正则化 - bagging_fraction:训练每棵树的训练样本百分比
- feature_fraction:训练每棵树时要采样的特征百分比
- lambda_l1 和 lambda_l2:
使用Optuna,定义优化目标函数:
- 定义训练参数字典
- 创建模型,训练
- 定义指标
import optuna # pip install optuna
from sklearn.metrics import log_loss
from sklearn.model_selection import StratifiedKFold
from optuna.integration import LightGBMPruningCallback
def objective(trial, X, y):
param_grid = {
"n_estimators": trial.suggest_categorical("n_estimators", [10000]),
"learning_rate": trial.suggest_float("learning_rate", 0.01, 0.3),
"num_leaves": trial.suggest_int("num_leaves", 20, 3000, step=20),
"max_depth": trial.suggest_int("max_depth", 3, 12),
"min_data_in_leaf": trial.suggest_int("min_data_in_leaf", 200, 10000, step=100),
"max_bin": trial.suggest_int("max_bin", 200, 300),
"lambda_l1": trial.suggest_int("lambda_l1", 0, 100, step=5),
"lambda_l2": trial.suggest_int("lambda_l2", 0, 100, step=5),
"min_gain_to_split": trial.suggest_float("min_gain_to_split", 0, 15),
"bagging_fraction": trial.suggest_float(
"bagging_fraction", 0.2, 0.95, step=0.1
),
"bagging_freq": trial.suggest_categorical("bagging_freq", [1]),
"feature_fraction": trial.suggest_float(
"feature_fraction", 0.2, 0.95, step=0.1
),
}
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=1121218)
cv_scores = np.empty(5)
for idx, (train_idx, test_idx) in enumerate(cv.split(X, y)):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
model = lgbm.LGBMClassifier(objective="binary", **param_grid)
model.fit(
X_train,
y_train,
eval_set=[(X_test, y_test)],
eval_metric="binary_logloss",
early_stopping_rounds=100,
callbacks=[
LightGBMPruningCallback(trial, "binary_logloss")
],
)
preds = model.predict_proba(X_test)
preds = model.predict_proba(X_test)
# 优化指标logloss最小
cv_scores[idx] = log_loss(y_test, preds)
return np.mean(cv_scores)
调优
study = optuna.create_study(direction="minimize", study_name="LGBM Classifier")
func = lambda trial: objective(trial, X, y)
study.optimize(func, n_trials=20)
搜索完成后,调用best_value和bast_params属性,调参就出来了。
print(f"\tBest value (rmse): {study.best_value:.5f}")
print(f"\tBest params:")
for key, value in study.best_params.items():
print(f"\t\t{key}: {value}")
-----------------------------------------------------
Best value (binary_logloss): 0.35738
Best params:
device: gpu
lambda_l1: 7.71800699380605e-05
lambda_l2: 4.17890272377219e-06
bagging_fraction: 0.7000000000000001
feature_fraction: 0.4
bagging_freq: 5
max_depth: 5
num_leaves: 1007
min_data_in_leaf: 45
min_split_gain: 15.703519227860273
learning_rate: 0.010784015325759629
n_estimators: 10000
得到这个参数组合后,我们就可以拿去跑模型了,看结果再手动微调,这样就可以省很多时间了。
特征重要性lgb_clf.feature_importances_
【1】详解LightGBM两大利器:基于梯度的单边采样(GOSS)和互斥特征捆绑(EFB)https://zhuanlan.zhihu.com/p/366234433
【2】LightGBM的参数详解以及如何调优. https://cloud.tencent.com/developer/article/1696852
【3】LightGBM 中文文档. https://lightgbm.cn/
【4】决策树(下)——XGBoost、LightGBM(非常详细)https://zhuanlan.zhihu.com/p/87885678
【5】http://www.showmeai.tech/article-detail/195
【6】https://zhuanlan.zhihu.com/p/99069186
【7】lightgbm离散类别型特征为什么按照每一个类别里对应样本的一阶梯度求和/二阶梯度求和排序? - 一直学习一直爽的回答 - 知乎 https://www.zhihu.com/question/386888889/answer/1195897410
【8】LightGBM+OPTUNA超参数自动调优教程
【9】LightGBM with the Focal Loss for imbalanced datasets