使⽤kafka-topics.sh脚本时可用的配置:
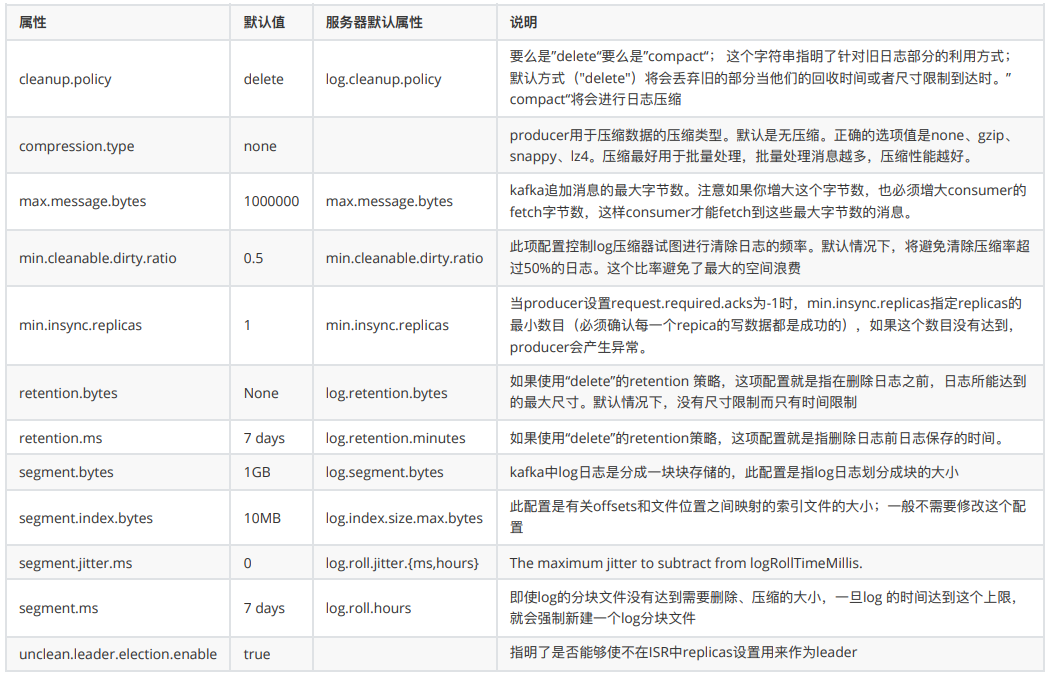
cleanup.policycompression.typedelete.retention.msfile.delete.delay.msflush.messagesflush.msfollower.replication.throttled.replicasindex.interval.bytesleader.replication.throttled.replicasmax.message.bytesmessage.format.versionmessage.timestamp.difference.max.msmessage.timestamp.typemin.cleanable.dirty.ratiomin.compaction.lag.msmin.insync.replicaspreallocateretention.bytesretention.mssegment.bytessegment.index.bytessegment.jitter.mssegment.msunclean.leader.election.enable
--create
创建⼀个新主题
--delete
删除⼀个主题
--delete-config <String: name>
删除现有主题的⼀个主题配置条⽬。这些条⽬就是在--config中给出的配置条⽬。
--alter
更改主题的分区数量,副本分配和/或配置条⽬。
--describe
列出给定主题的细节
--disable-rack-aware
禁⽤副本分配的机架感知。
--force
抑制控制台提示信息
--help
打印帮助信息
--if-exists
如果指定了该选项,则在修改或删除主题的时候,只有主题存在才可以执⾏。
--if-not-exists
在创建主题的时候,如果指定了该选项,则只有主题不存在的时候才可以执⾏命令。
--list
列出所有可⽤的主题。
--partitions <Integer: # of partitions>
要创建或修改主题的分区数。
--replica-assignment <String:broker_id_for_part1_replica1 :broker_id_for_part1_replica2,broker_id_for_part2_replica1 :broker_id_for_part2_replica2 , ...>
当创建或修改主题的时候⼿动指定partition-to-broker的分配关系。
--replication-factor <Integer:replication factor>
要创建的主题分区副本数。1表示只有⼀个副本,也就是Leader副本。
--topic <String: topic>
要创建、修改或描述的主题名称。除了创建,修改和描述在这⾥还可以使⽤正则表达式。
--topics-with-overrides
if set when describing topics, only show topics that haveoverridden configs
--unavailable-partitions
if set when describing topics, only show partitions whoseleader is not available
--under-replicated-partitions
if set when describing topics, only show under replicatedpartitions
--zookeeper <String: urls>
必需的参数:连接zookeeper的字符串,逗号分隔的多个host:port列表。多个URL可以故障转移。
主题中可以使⽤的参数定义(也就是上面--config <String: name=value> 的参数):
kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic tp_demo_02 --partitions 2 --replication-factor 1
kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic tp_demo_03 --partitions 3 --replication-factor 1 --config max.message.bytes=1048576 --config segment.bytes=10485760
kafka-topics.sh --zookeeper localhost:2181/myKafka --list
kafka-topics.sh --zookeeper localhost:2181/myKafka --describe --topic tp_demo_02
kafka-topics.sh --zookeeper localhost:2181/myKafka --topics-with-overrides --describe
kafka-topics.sh --zookeeper localhost:2181/myKafka --create --topic tp_demo_04 --partitions 4 --replication-factor 1
kafka-topics.sh --zookeeper localhost:2181/myKafka --alter --topic tp_demo_04 --config max.message.bytes=1048576
kafka-topics.sh --zookeeper localhost:2181/myKafka --describe --topic tp_demo_04
kafka-topics.sh --zookeeper localhost:2181/myKafka --alter --topic tp_demo_04 --config segment.bytes=10485760
kafka-topics.sh --zookeeper localhost:2181/myKafka --alter --delete-config max.message.bytes --topic tp_demo_04
kafka-topics.sh --zookeeper localhost:2181/myKafka --delete --topic tp_demo_01
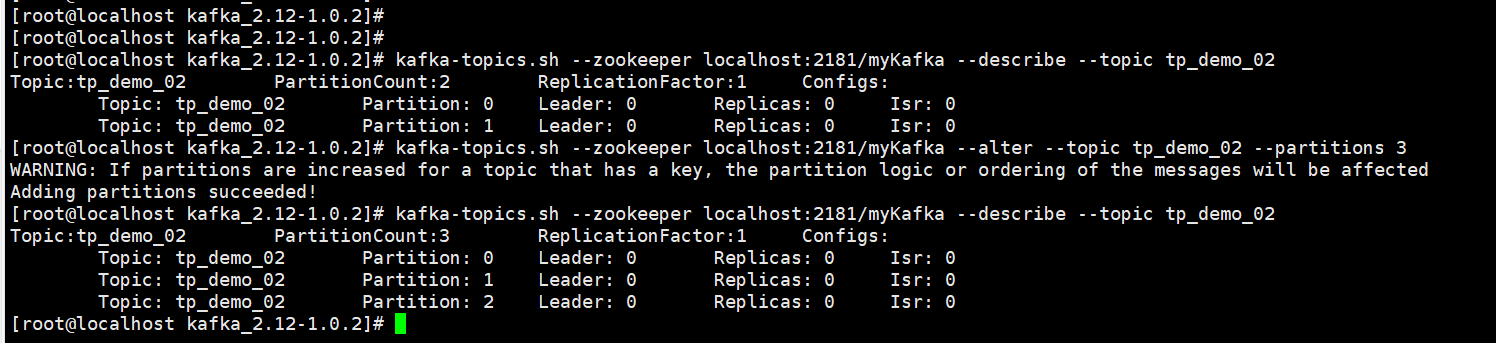
通过命令⾏⼯具操作,主题的分区只能增加,不能减少。否则报错:

通过--alter修改主题的分区数,增加分区。
kafka-topics.sh --zookeeper localhost:2181/myKafka --alter --topic tp_demo_02 --partitions 3
副本分配的三个⽬标:
- 均衡地将副本分散于各个broker上
- 对于某个broker上分配的分区,它的其他副本在其他broker上
- 如果所有的broker都有机架信息,尽量将分区的各个副本分配到不同机架上的broker。
在不考虑机架信息的情况下:
- 第⼀个副本分区通过轮询的⽅式挑选⼀个broker,进⾏分配。该轮询从broker列表的随机位置进⾏轮询。
- 其余副本通过增加偏移进⾏分配。
分配案例:

考虑到机架信息,⾸先为每个机架创建⼀个broker列表。如:三个机架(rack1,rack2,rack3),六个broker(0,1,2,3,4,5)
brokerID -> rack
- 0 -> "rack1", 1 -> "rack3", 2 -> "rack3", 3 -> "rack2", 4 -> "rack2", 5 -> "rack1"
rack1:0,5
rack2:3,4
rack3:1,2
这broker列表为rack1的0,rack2的3,rack3的1,rack1的5,rack2的4,rack3的2
即:0, 3, 1, 5, 4, 2
通过简单的轮询将分区分配给不同机架上的broker:
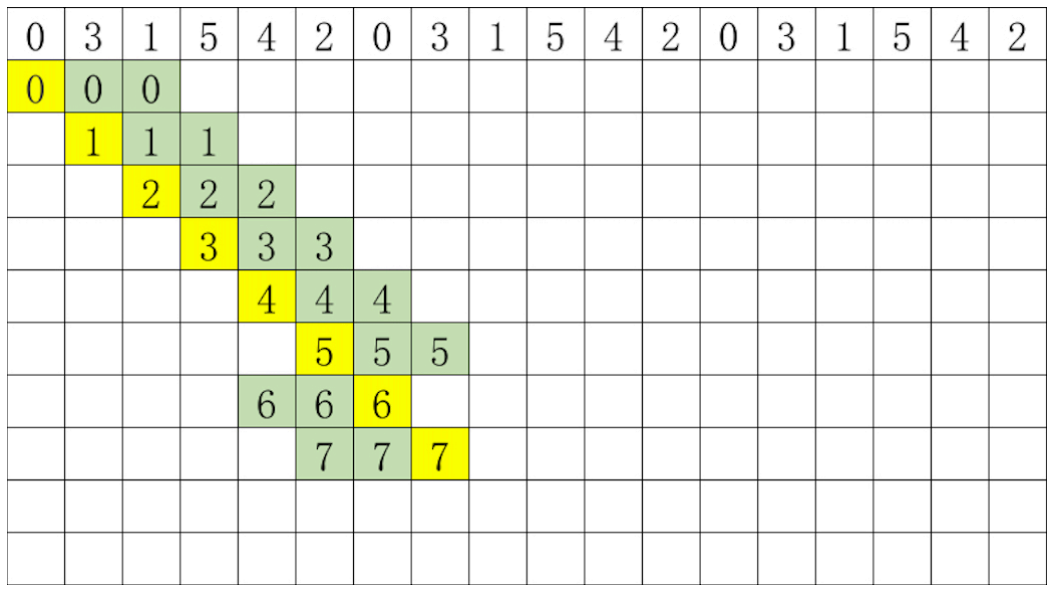
每个分区副本在分配的时候在上⼀个分区第⼀个副本开始分配的位置右移⼀位。
六个broker,六个分区,正好最后⼀个分区的第⼀个副本分配的位置是该broker列表的最后⼀个。
如果有更多的分区需要分配,则算法开始对follower副本进⾏移位分配。
这主要是为了避免每次都得到相同的分配序列。
此时,如果有⼀个分区等待分配(分区6),这按照如下⽅式分配: 6 -> 0,4,2 (⽽不是像分区0那样重复0,3,1)
跟机架相关的副本分配中,永远在机架相关的broker列表中轮询地分配第⼀个副本。其余的副本,倾向于机架上没有副本的broker进⾏副本分配,除⾮每个机架有⼀个副本。然后其他的副本⼜通过轮询的⽅式分配给broker。
结果是,如果副本的个数⼤于等于机架数,保证每个机架最少有⼀个副本。否则每个机架最多保有⼀个副本。
如果副本的个数和机架的个数相同,并且每个机架包含相同个数的broker,可以保证副本在机架和broker之间均匀分布。
四、常用参数配置上面已经介绍过:kafka-topics.sh --config xx=xx --config yy=yy
配置给主题的参数。
说明:
除了使⽤Kafka的bin⽬录下的脚本⼯具来管理Kafka,还可以使⽤管理Kafka的API将某些管理查看的功能集成到系统中。在Kafka0.11.0.0版本之前,可以通过kafka-core包(Kafka的服务端,采⽤Scala编写)中的AdminClient和AdminUtils来实现部分的集群管理操作。Kafka0.11.0.0之后,⼜多了⼀个AdminClient,在kafka-client包下,⼀个抽象类,具体的实现是org.apache.kafka.clients.admin.KafkaAdminClient。
功能与原理介绍
Kafka官⽹:The AdminClient API supports managing and inspecting topics, brokers, acls, and other Kafka objects
KafkaAdminClient包含了⼀下⼏种功能(以Kafka1.0.2版本为准):
-
创建主题
createTopics(final Collection<NewTopic> newTopics, final CreateTopicsOptions options) -
删除主题
deleteTopics(final Collection<String> topicNames, DeleteTopicsOptions options) -
列出所有主题
listTopics(final ListTopicsOptions options) -
查询主题
describeTopics(final Collection<String> topicNames, DescribeTopicsOptions options) -
查询集群信息
describeCluster(DescribeClusterOptions options) -
查询配置信息
describeConfigs(Collection<ConfigResource> configResources, final DescribeConfigsOptions options) -
修改配置信息
alterConfigs(Map<ConfigResource, Config> configs, final AlterConfigsOptions options) -
修改副本的日志记录
alterReplicaLogDirs(Map<TopicPartitionReplica, String> replicaAssignment, final AlterReplicaLogDirsOptions options) -
查询节点的⽇志⽬录信息
describeLogDirs(Collection<Integer> brokers, DescribeLogDirsOptions options) -
查询副本的⽇志⽬录信息
describeReplicaLogDirs(Collection<TopicPartitionReplica> replicas, DescribeReplicaLogDirsOptions options) -
增加分区
createPartitions(Map<String, NewPartitions> newPartitions, final CreatePartitionsOptions options)
其内部原理是使⽤Kafka⾃定义的⼀套⼆进制协议来实现,详细可以参⻅Kafka协议。
KafkaAdminClient⽤到的参数:
客户端会使⽤这⾥列出的所有服务器进⾏集群其他服务器的发现,⽽不管是否指定了哪个服务器⽤作引导。
这个列表仅影响⽤来发现集群所有服务器的初始主机。
字符串形式:host1:port1,host2:port2,...
由于这组服务器仅⽤于建⽴初始链接,然后发现集群中的所有服务器,因此没有必要将集群中的所有地址写在这⾥。
⼀般最好两台,以防其中⼀台宕掉。 high client.id ⽣产者发送请求的时候传递给broker的id字符串。
⽤于在broker的请求⽇志中追踪什么应⽤发送了什么消息。
⼀般该id是跟业务有关的字符串。 medium connections.max.idle.ms 当连接空闲时间达到这个值,就关闭连接。long型数据,默认:300000 medium receive.buffer.bytes TCP接收缓存(SO_RCVBUF),如果设置为-1,则使⽤操作系统默认的值。int类型值,默认65536,可选值:[-1,...] medium request.timeout.ms 客户端等待服务端响应的最⼤时间。如果该时间超时,则客户端要么重新发起请求,要么如果重试耗尽,请求失败。int类型值,默认:120000 medium security.protocol 跟broker通信的协议:PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL.string类型值,默认:PLAINTEXT medium send.buffer.bytes ⽤于TCP发送数据时使⽤的缓冲⼤⼩(SO_SNDBUF),-1表示使⽤OS默认的缓冲区⼤⼩。
int类型值,默认值:131072 medium reconnect.backoff.max.ms 对于每个连续的连接失败,每台主机的退避将成倍增加,直⾄达到此最⼤值。在计算退避增量之后,添加20%的随机抖动以避免连接⻛暴。
long型值,默认1000,可选值:[0,...] low reconnect.backoff.ms 重新连接主机的等待时间。避免了重连的密集循环。该等待时间应⽤于该客户端到broker的所有连接。
long型值,默认:50 low retries The maximum number of times to retry a call before failing it.重试的次数,达到此值,失败。
int类型值,默认5。 low retry.backoff.ms 在发⽣失败的时候如果需要重试,则该配置表示客户端等待多⻓时间再发起重试。
该时间的存在避免了密集循环。
long型值,默认值:100。 low
主要操作步骤:
客户端根据⽅法的调⽤创建相应的协议请求,⽐如创建Topic的createTopics⽅法,其内部就是发送CreateTopicRequest请求。
客户端发送请求⾄Kafka Broker。
Kafka Broker处理相应的请求并回执,⽐如与CreateTopicRequest对应的是CreateTopicResponse。客户端接收相应的回执并进⾏解析处理。
和协议有关的请求和回执的类基本都在org.apache.kafka.common.requests包中,AbstractRequest和AbstractResponse是这些请求和响应类的两个⽗类。
综上,如果要⾃定义实现⼀个功能,只需要三个步骤:
- ⾃定义XXXOptions;
- ⾃定义XXXResult返回值;
- ⾃定义Call,然后挑选合适的XXXRequest和XXXResponse来实现Call类中的3个抽象⽅法。
Kafka 1.0.2,__consumer_offsets主题中保存各个消费组的偏移量。
早期由zookeeper管理消费组的偏移量。
查询⽅法:
通过原⽣ kafka 提供的⼯具脚本进⾏查询。
⼯具脚本的位置与名称为bin/kafka-consumer-groups.sh
⾸先运⾏脚本,查看帮助:
如:--group g1 --group g2。
传值消费组名称和单个主题,仅删除该消费组到指定主题的分区偏移量和所属关系。
如:--group g1 --group g2 --topic t1。
传值⼀个主题名称,仅删除指定主题与所有消费组分区偏移量以及所属关系。
如:--topic t1
注意:消费组的删除仅对基于ZK保存偏移量的消费组有效,并且要⼩⼼使⽤,仅删除不活跃的消费组。 --describe 描述给定消费组的偏移量差距(有多少消息还没有消费)。 --execute 执⾏操作。⽀持的操作:reset-offsets。 --export 导出操作的结果到CSV⽂件。⽀持的操作:reset-offsets。 --from-file<String: path toCSV file> 重置偏移量到CSV⽂件中定义的值。 --group <String:consumer group> ⽬标消费组 --list 列出所有消费组。 --new-consumer 使⽤新的消费者实现。这是默认值。随后的发⾏版中会删除这⼀操作。 --reset-offsets 重置消费组的偏移量。当前⼀次操作只⽀持⼀个消费组,并且该消费组应该是不活跃的。
有三个操作选项
1.(默认)plan:要重置哪个偏移量。
2. execute:执⾏reset-offsets操作。
3. process:配合--export将操作结果导出到CSV格式。
可以使⽤如下选项:
--to-datetime
--by-period
--to-earliest
--to-latest
--shift-by
--from-file
--to-current
必须选择⼀个选项使⽤。
要定义操作的范围,使⽤:
--all-topics
--topic。
必须选择⼀个,除⾮使⽤--from-file选项。 --shift-by<Long: number-of-offsets> 重置偏移量n个。n可以是正值,也可以是负值。 --timeout<Long: timeout(ms)> 对某些操作设置超时时间。
如:对于描述指定消费组信息,指定毫秒值的最⼤等待时间,以获取正常数据(如刚创建的消费组,或者消费组做了⼀些更改操作)。默认时间:5000。 --to-current 重置到当前的偏移量。 --to-datetime<String: datetime> 重置偏移量到指定的时间戳。格式:'YYYY-MM-DDTHH:mm:SS.sss' --to-earliest 重置为最早的偏移量 --to-latest 重置为最新的偏移量 --to-offset<Long: offset> 重置到指定的偏移量。
--topic<String:topic>
指定哪个主题的消费组需要删除,或者指定哪个主题的消费组需要包含到resetoffsets操作中。对于reset-offsets操作,还可以指定分区:topic1:0,1,2。其中0,1,2表示要包含到操作中的分区号。重置偏移量的操作⽀持多个主题⼀起操作。
--zookeeper<String: urls>
必须,它的值,你懂的。--zookeeper localhost:2181/myKafka。
由于kafka 消费者记录group的消费偏移量有两种⽅式 :
- kafka ⾃维护 (新)
- zookpeer 维护 (旧) ,已经逐渐被废弃
所以 ,脚本只查看由broker维护的,由zookeeper维护的可以将--bootstrap-server换成--zookeeper即可。
-
查看有那些 group ID 正在进⾏消费
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list注意:
-
这⾥⾯是没有指定 topic,查看的是所有topic消费者的 group.id 的列表。
-
注意: 重名的 group.id 只会显示⼀次
-
-
**查看指定group.id 的消费者消费情况 **
kafka-consumer-groups.sh --bootstrap-server node1:9092 --describe --group group如果消费者停⽌,查看偏移量信息:

将偏移量设置为最早的:

将偏移量设置为最新的:

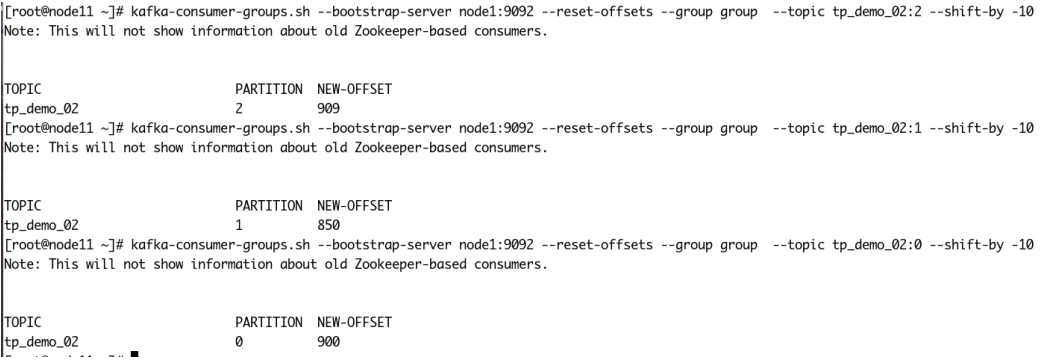
分别将指定主题的指定分区的偏移量向前移动10个消息: