dubbo是一款微服务开发框架,它提供了 RPC通信 与 微服务治理 两大关键能力。作为spring cloud alibaba体系中重要的一部分,随着spring cloud alibaba在国内活跃起来,dubbo也越来越深受各大公司的青睐。本文就来对dubbo的spi机制源码进行剖析,看一看dubbo的spi到底有哪些特性和功能。
一、什么是spi机制?SPI (Service Provider Interface),主要用于扩展的作用。举个例子来说,假如有一个框架有一个接口,他有自己默认的实现类,但是在代码运行的过程中,你不想用他的实现类或者想扩展一下他的实现类的功能,但是此时你又不能修改别人的源码,那么此时该怎么办?这时spi机制就有了用武之地。一般框架的作者在设计这种接口的时候不会直接去new这个接口的实现类,而是在Classpath路径底下将这个接口的实现类按作者约定的格式写在一个配置文件上,然后在运行的过程中通过java提供的api,从所有jar包中读取所有的这个指定文件中的内容,获取到实现类,用这个实现类,这样,如果你想自己替换原有的框架的实现,你就可以按照作者规定的方式配置实现,这样就能使用你自己写的实现类了。
spi机制其实体现了设计思想中的解耦思想,方便开发者对框架功能进行扩展。
二、java的spi机制 -- ServiceLoaderjava中最常见的spi机制应用就是数据库驱动的加载,java其实就是定义了java语言跟数据库交互的接口,但是具体的实现得交给各大数据库厂商来实现,那么java怎么知道你的数据库厂商的实现了?这时就需要spi机制了,java好约了定在 Classpath 路径下的 META-INF/services/ 目录里创建一个以服务接口命名的文件,然后内容是该数据库厂商的实现的接口的全限定名,这样数据库厂商只要按照这个规则去配置,java就能找到。
我以mysql来举例,看一下mysql是怎么实现的。
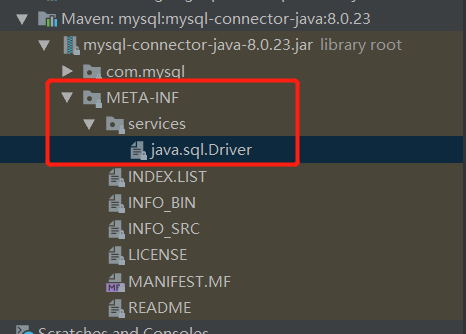
内容
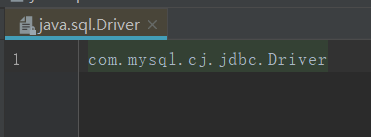
java是通过ServiceLoader类来实现读取配置文件中的实现类的。大家有兴趣可以看一下里面的代码,其实就是读取到每个jar包底下的文件,读取里面的内容。
三、spring中的spi机制 -- SpringFactoriesLoader相信spring大家都不陌生,在spring扩展也是依赖spi机制完成的,只不过spring对于扩展文件约定在Classpath 路径下的 META-INF目录底下,所有的文件名都是叫spring.factories,文件里的内容是一个以一个个键值对的方式存储的,键为类的全限定名,值也为类的全限定名,如果有多个值,可以用逗号分割,有一点得注意的是,键和值本身约定并没有类与类之间的依赖关系(当然也可以有,得看使用场景的约定),也就是说键值可以没有任何关联,键仅仅是一种标识,代表一种场景,最常见的自动装配的注解,@EnableAutoConfiguration,也就是代表自动装配的场景,当你需要你的类被自动装配,就可以以这个注解的权限定名键,你的类为名,这样springboot在进行自动装配的时候,就会拿这个键,找到你写的实现类来完成自动装配。
这里我贴出了自动装配时加载类的源码。
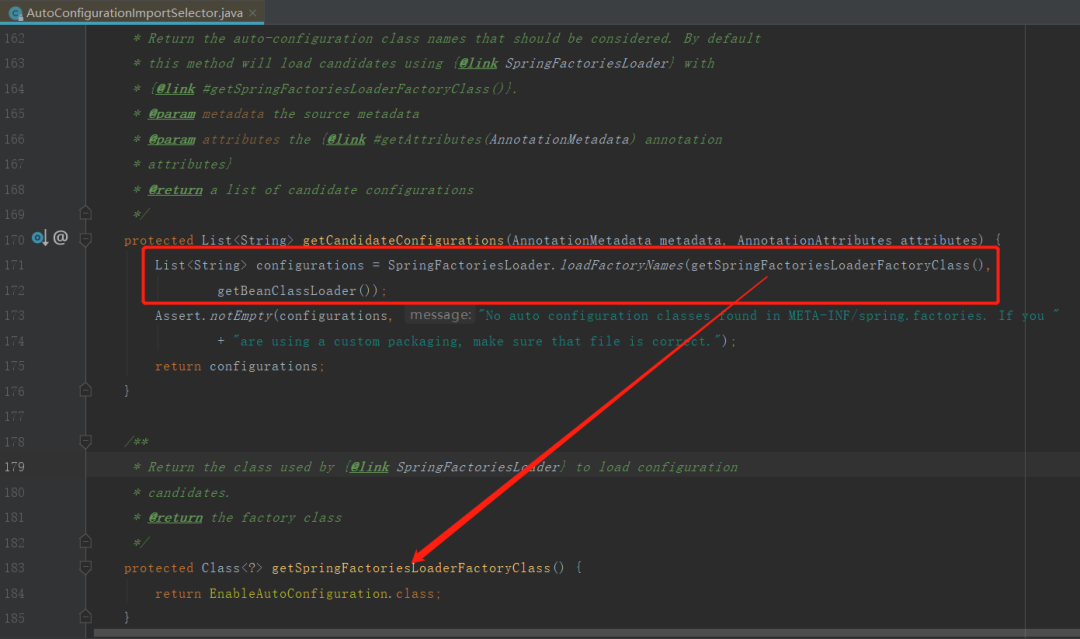
这里其实就是通过@EnableAutoConfiguration的全限定名从spring.factories中加载这个键对应的所有的实现类的名称,这样就能拿到所有需要自动装配的类的全限定名了。
mybatis整合spring的自动装配功能文件

内容
mybatis也是按照spring的规则来配置的。大家有空可以去看MybatisAutoConfiguration这个实现类,里面有mybatis是如何跟spring整合的内容。
SpringFactoriesLoader的应用场景还有很多,大家可以去看一下SpringBoot中的启动引导类SpringApplication,里面多次使用到了这个SpringFactoriesLoader这个类来获取各种实现。
四、dubbo的spi机制 -- ExtensionLoader源码剖析本文是基于dubbo3.0.4版本源码剖析。
讲完了java和spring的中的spi机制,接下来进入本文的主题,dubbo的spi机制到底是什么?它与java自带的有何区别?为什么不用java的spi机制?
ExtensionLoader是dubbo的spi机制所实现的类,通过这个类来加载接口所有实现类,获取实现类的对象。同时每一个接口都会有一个自己的ExtensionLoader。
1)java的spi机制的缺点?从我们分析java的spi机制可以看出,java约定了文件名为接口的名称,内容为实现。不知道大家有没有想过这里面有个很严重的问题,就是虽然我获取到了所有的实现类,但是无法对实现类进行分类,也就是说我无法确定到底该用哪个实现类,并且java的spi机制会一次性给所有的实现类创建对象,如果这个对象你根本不会使用,那么此时就会白白浪费资源,也就是说无法做到按需加载。
所以,dubbo就自己实现了一套spi机制,不仅解决了以上的痛点,同时也加入了更多的特性。
2)dubbo的配置文件约束。dubbo会从四个目录读取文件META-INF/dubbo/internal/ 、META-INF/dubbo/ 、META-INF/services/、META-INF/dubbo/external/,文件名为接口的全限定名,内容为键值对,键为短名称(可以理解为spring中的对象的名称),值为实现类。
3)@SPI 注解的约束dubbo中所有的扩展接口,都需要在接口上加@SPI注解,不然在创建ExtensionLoader的时候,会报错。代码体现在这里
顺便说说ExtensionDirector的作用,在3.0.3以前的版本,是没有这个类的,但是在之后的版本为了实现一些新的特性,就抽象出来了这个类,通过这个类来获取每个接口对应的ExtensionLoader
4)实现类的加载先说各种特性之前,先说一下这些实现类是如何加载的,类的加载是非常重要的一个环节,与后面的spi特性有重要的关系。
类加载默认都是先调用getExtensionClasses这个方法的,当cachedClasses没有的时,才会去加载实现类,然后再把实现类放到cachedClasses中。真正实现加载的是loadExtensionClasses 方法,接下来我们详细看这个方法的源码。
checkDestroyed();
方法没什么东西,其实就是一个检查的作用。
cacheDefaultExtensionName();
缓存默认实现类的短名称。其实很简单,就是从@SPI注解中取出名称,就是默认的实现类的名称,缓存起来,ExtensionLoader有个getDefaultExtension方法,其实就是通过这个短名称对应的实现类的对象。
接下来会遍历LoadingStrategy,根据LoadingStrategy加载指定目录的文件。
我们先来看看LoadingStrategy的实例是怎么加载的。我们进入loadLoadingStrategies方法,
惊讶的发现竟然是使用了java的spi机制加载LoadingStrategy,那我们就去Classpath 路径下的 META-INF/services/路径下找这个LoadingStrategy接口的全限定名的文件,看看有哪些实现。有四个实现,也就是会按照这四个的加载策略来读取实现类。其中有个方法directory,就是指定加载的目录,这也就是我们前面说的那几个dubbo会加载的目录,其实是从这个方法返回的,你可以自己去看看这四个实现类对于这个方法的实现。其实我们也可以实现这个接口,指定我们自己想加载的目录。
这里会循环加载每个目录,我们进去loadDirectory方法。
这个其实就是拿出LoadingStrategy来调用重载的loadDirectory方法。
这里注意会调用两次loadDirectory,下面的那个其实是适配以前老版本的,不用关心。
接下来进去重载的loadDirectory方法。
可以看出,fileName就是LoadingStrategy所指定的目录 + 接口的全限定名,这里就解释了为什么实现类需要写在类全限定名的文件里。其实就是从每个jar底指定的目录类全限定名为名称的文件,得到每个jar底下的文件的URL。然后遍历每个URL,加载类,我们进入loadResource方法来看看具体是怎么加载的。
通过URL打开一个输入流,然后读取文件内容,取出每一行,以 = 进行分割(因为规定的是以键值对存的),键就是短名称,值就是实现类的名称,然后再进入loadClass方法,这个方法很重要,其实是对实现类进行一个分类,后面dubbo的特性实现的前提就是对这些实现类的分类操作。
标红的两处是这个意思
如果你加了@Adaptive注解,那么就将赋值到cachedAdaptiveClass属性上。我们叫这个类为自适应类。什么是自适应,其实说白了这个类本身并没有实际的意义,它是根据你的入参动态来实现找到真正的实现类来完成调用。getAdaptiveExtension其实就是获取到这个自适应实现类对应的对象。
如果你的实现类是有一个该类型为参数的构造方法,那么就将这个实现类放到cachedWrapperClasses中,并且我们称这个类为包装类,什么叫包装,其实跟静态代理有点像,就是将目标对象进行代理,可以增强功能。
这处标红的意思是判断是不是实现类是不是加了@Activate注解,是的话就将短名称和注解放入cachedActivates中,我们称这类实现类为自动激活的类,所谓的自动激活,就是可以根据你的入参,动态选择实现一批符合条件的实现类
saveInExtensionClass就是将这个实现类放入extensionClasses中,该目录下的实现类就加载完成了。
接下来会继续循环,加载不同的目录底下,都会进行分类,并放到extensionClasses中。
当LoadingStrategy循环玩之后,最后将extensionClasses放入cachedClasses中,此时就完成了对于指定目录下实现类的加载和分类。
至此,实现类的加载和分类就完成了。
5)实现类对象构造看实现类对象构造过程之前,先看获取,因为获取不到才构造,也就是java中spi没有的功能,按需加载。
获取实现类对象的方法是getExtension方法,传入的name参数就是短名称,也就是spi文件的键,wrap是是否包装的意思,true的意思就是对你获取的目标对象进行包装(具体什么是包装,如何包装后面会讲),wrap默认是true
接下来我们就着重分析getExtension方法
前面两个if我说一下,
第一个if比较简单,就是简单的参数校验,name参数不能为空
第二个if判断name是不是字符串true,是的话就调用getDefaultExtension,getDefaultExtension这个方法通过名称也能看出来就是获取接口默认的实现,什么是默认实现?默认的实现就是@SPI注解中的名称对应的实现类。
前面两个if之后就是真正获取实现了。在获取之前,先根据你是否包装构建缓存的键值,如果没有包装,就会在短名称后加上 _origin ,这主要是为了区分包不包装,然后进入getOrCreateHolder方法
里面其实就是通过缓存名称从cachedInstances获取一个Holder,获取不到就new一个Holder然后放到cachedInstances中,然后返回。Holder其实本身并没有什么意义,可以理解为一个空壳,里面放的才是真正最终返回的对象。
第一次,不用说Holder肯定没有,那么这个Holder肯定是刚new出来的。
跳出getOrCreateHolder方法,继续往下看。
从Holder中获取实现类,此时肯定是null,接下来就是synchronized,然后又是非空判断。这里其实是典型的单例模式中的双重检查机制,保证并发安全。其实从这里可以看出Holder的作用。这里是为了减少锁冲突的,因为一个实现类对象对应一个Holder对象,这样不同的实现类在创建的时候,由于Holder的不同,synchronized就不是同一个锁对象,这就起到了并发时候减少锁冲突的作用,从这可以看出dubbo设计的时候的细节是很到位的。
第一次都是null,接下来进入createExtension方法,构建对象的过程
先从实现类的缓存中获取到短名称对应的实现类,上面提到,实现类加载之后会放到内部的一个缓存中。
这个if条件判断一般肯定是false的,但是有些情况,就比如第一次构建对象抛出异常,此时第二次来构建这个对象,那么不用说肯定也会有问题,dubbo为了快速知道哪些实现类对象构造的时候会出异常,就在第一次构建对象抛异常的时候缓存了实现类的短名称到unacceptableExceptions中,当第二次来构建的时候,能够快速知道,抛出异常,减少资源的浪费。
接下来就会从extensionInstances中获取实例,这个实例是没有包装的实例,也就是说如果你获取的不带包装的实例,就是这个实例。我们看看这个实例是怎么构建出来的,这里我根据构建的不同阶段进行划分为以下几个步骤。
通过实例化策略InstantiationStrategy进行实例化,默认是通过无参构造器构造的。

调用 ExtensionPostProcessor的postProcessBeforeInitialization方法,ExtensionPostProcessor跟spring中的BeanPostProcessor有点像,就是对目标对象进行扩展的作用。

接下来调用injectExtension方法,这个方法就是依赖注入的实现方法。
依赖注入:说白了就是dubbo会自动调用需要依赖注入的方法,传入相应的参数
哪些方法是需要依赖注入的方法?
dubbo约定 方法名以set开头,方法的参数只有一个,方法上没有加@DisableInject注解 ,方法是public的,符合这类的方法就是需要依赖注入的方法,dubbo在构建对象的时候会自动调用这些方法,传入相应的参数。
接下来进入源码

可以看出,先通过反射获取到所有的方法,然后遍历每个方法,进入两个if判断,这个判断就是判断是不是需要依赖注入的方法,也就是上面说的条件就在这个体现。
假设是需要依赖注入的方法,接下来看看如何获得需要被注入的对象,也就是方法的参数。
首先获取需要set的对象的class类型,就是方法的参数类型
然后通过getSetterProperty方法获取属性名,可以理解为bean的名称,
getSetterProperty就是方法去掉set然后第一个字母小写之后就是属性的名称,举个例子方法叫setUser,那么属性名就叫user,如果叫setUserName,属性名就叫userName,就这么简单。
最后就是根据属性名和参数类型通过 ExtensionInjector 获取需要被注入的对象。
ExtensionInjector 接口讲解
ExtensionInjector就是注入器,通过这个可以获取到被依赖注入的对象,这是个接口,有很多实现,这里是 AdaptiveExtensionInjector 实现类,也是通过spi机制获取的,ExtensionLoader构造的时候获取的。
下面列举了ExtensionInjector有的实现:
AdaptiveExtensionInjector:自适应的,本身没有实际的意义,就是遍历所有其它的ExtensionInjector实现来获取,一旦有一个获取到,就不会再调用下一个ExtensionInjector来获取的
SpiExtensionInjector:顾名思义,就是通过spi机制来获取,获取的是自适应的实现
SpringExtensionInjector:这个是通过spring容器获取实现,所以你通过dubbo的spi机制可以注入spring的bean
ScopeBeanExtensionInjector:通过dubbo内部的组件BeanFactory来获取的,BeanFactory是dubbo内部用来在一定范围的bean的容器,主要是为了对象的重复利用来的。
假设这里获取到了对象,那么接下来就是通过反射调用set方法,进行依赖注入,然后依赖注入就完成了。
第四步:ExtensionAccessorAware接口回调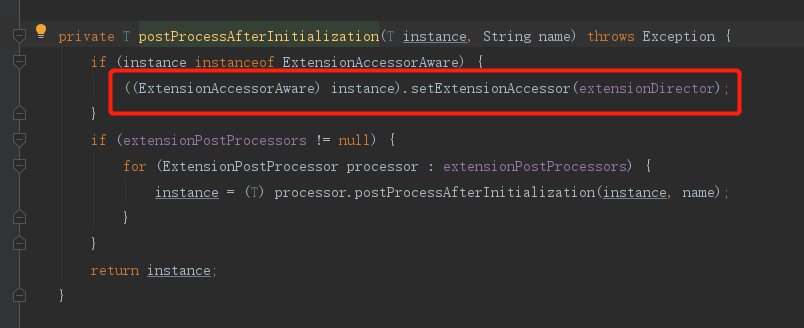
如果你的接口实现了ExtensionAccessorAware接口,那么会注入给你的bean一个 ExtensionDirector ,ExtensionDirector 可以想象成是ExtensionLoader工厂,可以获取每个接口的ExtensionLoader。
第五步: 初始化后ExtensionPostProcessor回调 
调用ExtensionPostProcessor的postProcessAfterInitialization方法对目标对象进行扩展的作用。
第六步:自动包装到这一步实现类本身的对象就算构造好了,接下来就是进行自动包装,如果wrap是true的话。
自动包装:可以说是静态代理模式,就是对你的目标对象进行代理,怎么代理,就是通过包装类,什么是包装类,上文有说过,一个一个构造,慢慢构成一个调用链条,最终才会调用到真正的实现类
我们看看源码的实现
@Wrapper注解是个匹配的作用,就是根据需要属性从包装类中选择一批可以用来包装的类。
构造其实很简单,就是当前instance当做包装类的构造参数通过反射构造,然后进行依赖注入,然后将构造出来的对象复制给instance,instance再进行回调之后再赋值给instance,这样往往复复就形成了一个链条。这里我画个图,让大家看看最后构造出来的对象是什么样。
构造后的对象其实就是这样,你最终使用的对象其实是包装对象,如果你获取对象的时候传的wrap参数是true的话,当前默认情况下是true。最后调用的话就会先调用最外层的包装的方法(包装对象2),然后调用(包装对象1)一直调用,最后会调用到真正的目标对象的方法。
为什么需要包装?
很多人可能不清楚,为什么需要包装,其实很好理解,就是起到动态增强目标对象的作用。可以理解为spring中的aop,但是dubbo因为不像spring那样有完整的ioc和aop的实现,dubbo就通过这种包装的方式来实现动态增强目标对象功能的作用。
第七步:Lifecycle接口回调接下来会调用initExtension方法,这个方法的作用就是判断你的实现类有没有实现Lifecycle接口,如果有的话会调用initialize()方法的实现
至此,一个可用的实现类对象就算完完全全构建完成了,你拿到的对象就是这个对象,然后就会返回这个对象,存到Holder对象中。
最后来张图总结一下实现类构造的过程。
这里我在简单说明一下,
1)包装不是必须的,得看你要获取的对象是什么,如果不要包装,就会回调原始对象的Lifecycle接口,不过dubbo内部的框架基本上获取的都是带包装的对象,而非原始的对象;
2)包装时暴露出去的是包装类的对象,在调用的时候,最先调用的也是包装类的对象,然后一层一层的调用,最终调用到实现类对象。
6)自适应机制自适应:自适应扩展类的含义是说,基于参数,在运行时动态选择到具体的目标类,然后执行。在 Dubbo 中,很多拓展都是通过 SPI 机制进行加载的,比如 Protocol、Cluster、LoadBalance 等。有时,有些拓展并不想在框架启动阶段被加载,而是希望在拓展方法被调用时,根据运行时参数进行加载。这听起来有些矛盾。拓展未被加载,那么拓展方法就无法被调用(静态方法除外)。拓展方法未被调用,拓展就无法被加载。对于这个矛盾的问题,Dubbo 通过自适应拓展机制很好的解决了。自适应拓展机制的实现逻辑比较复杂,首先 Dubbo 会为拓展接口生成具有代理功能的代码。然后通过 javassist 或 jdk 编译这段代码,得到 Class 类。最后再通过反射创建代理类,整个过程比较复杂。
自适应对象获取的方法,就是getAdaptiveExtension方法。构建自适应对象的方法就是createAdaptiveExtension方法的实现。
源码很简单,就是得到自适应的实现类,然后就是普通反射构造,然后经过初始化前,依赖注入,初始化之后,Lifecycle接口回调操作,构造出对象。
自适应的类有两种来源,一种是自己在实现类上加@Adaptive注解,指定自适应实现类,上面提到的AdaptiveExtensionInjector就是指定的自适应实现类,类上加了@Adaptive注解,如果不指定,dubbo框架会按照一定的规则来动态生成一个自适应的类,构造过程在createAdaptiveExtensionClass方法实现,最终会调用AdaptiveClassCodeGenerator生成代码
7)自动激活
所谓的自动激活,就是根据你的入参,动态的选择一批实现类返回给你。至于怎么找到,就是通过注解@Activate来实现的。dubbo内部自动激活的主要用在Filter中,Filter是个接口,有很多实现。不论是在provider端还是consumer端,在调用之前,都会经过一个由Filter实现构成的链,这条链的不同实现就是根据入参的不同来区分是每个Filter的实现属于provider的还是consumer端的。
@Activate它有三个重要属性,group 表示修饰在哪个端,是 provider 还是 consumer,value 表示在 URL参数中出现才会被激活,order 表示实现类的顺序。
总结
本文先介绍了什么是spi机制,然后分析了java的spi机制和spring的spi机制,最后我们进入本文的主题,dubbo的spi机制,我们从源码的角度剖析了dubbo spi机制的功能,包扩了在构建对象时的实现类的加载、ioc和自动包装的机制、自适应对象机制、自动激活机制。整体而言,dubbo的spi机制不是很难,所以大家看了两篇文章之后如果自己再过一遍源码的话那么收获会更大。dubbo的spi机制其实非常重要,如果不理解dubbo的spi机制的特性的话,在阅读dubbo源码的时候,很难读懂,因为你可能都不知道,你拿到的对象到底是什么样的,这样就很难理解一些功能的实现。
往期热门文章推荐
-
Redis分布式锁实现Redisson 15问
-
有关循环依赖和三级缓存的这些问题,你都会么?(面试常问)
-
万字+28张图带你探秘小而美的规则引擎框架LiteFlow
-
7000字+24张图带你彻底弄懂线程池
-
【SpringCloud原理】OpenFeign原来是这么基于Ribbon来实现负载均衡的
-
【SpringCloud原理】Ribbon核心组件以及运行原理源码剖析
-
【SpringCloud原理】OpenFeign之FeignClient动态代理生成原理
扫码或者搜索关注公众号 三友的java日记 ,及时干货不错过,公众号致力于通过画图加上通俗易懂的语言讲解技术,让技术更加容易学习。
