Apache SkyWalking的UI界面主要分为以下几个区域:
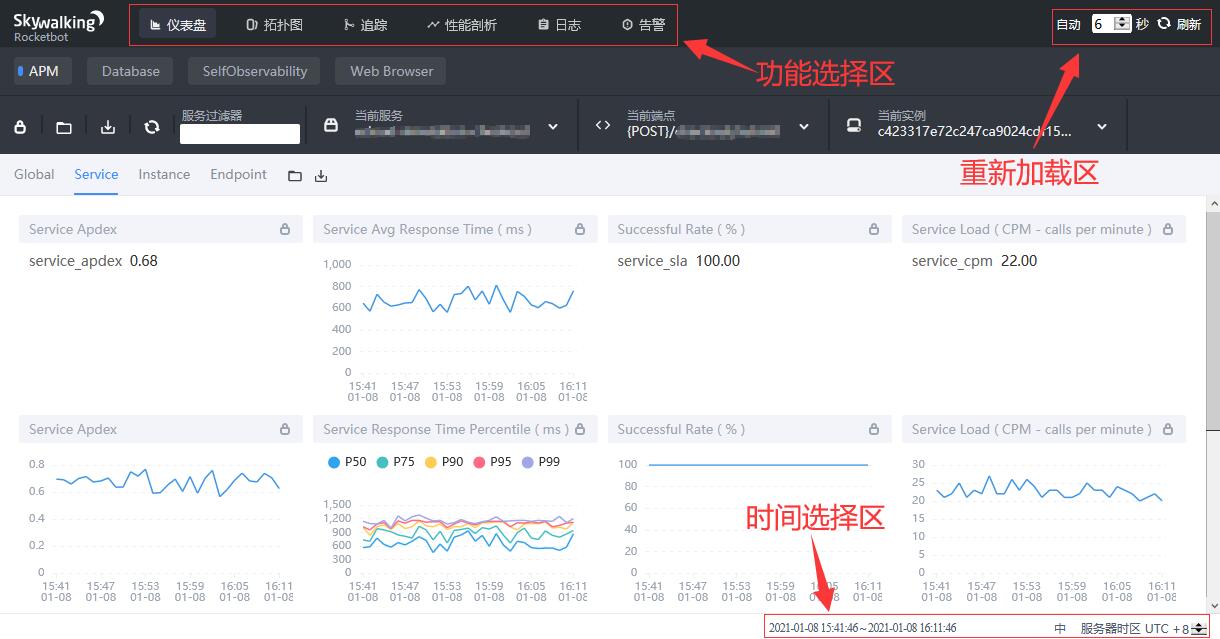
- 功能选择区:这里列出了主要的UI功能,包括仪表盘、拓扑图、追踪、性能刨析、告警等功能
- 重新加载区:控制重新加载机制,包括定期重新加载或手动重新加载。
- 时间选择器:控制时区和时间范围。这里有一个中文/英文切换按钮,默认,UI使用浏览器语言设置。
下面逐一介绍功能选择区的各个功能。
文章持续更新,微信搜索「万猫学社」第一时间阅读,关注后回复「电子书」,免费获取12本Java必读技术书籍。
仪表盘仪表盘又分为以下几个功能:

- APM:以全局(Global)、服务(Service)、服务实例(Instance)、端点(Endpoint)的维度展示各项指标。
- Database:展示数据库的各项指标。
- SelfObservability:展示OAP服务端的各项指标。
- Web Browser:以服务和页面的维度展示Web浏览器端的各项指标。
APM - 全局(Global)相关概念解释:
- 服务(Service):表示对请求提供相同行为的一组工作负载,比如:一个的 Web API系统。
- 服务实例(Instance):上述的一组工作负载中的每一个工作负载称为一个实例,比如:一个的 Web API 系统集群中的一个实例。
- 端点(Endpoint):对于特定服务所接收的请求路径,如 HTTP 的 URI 路径和 gRPC 服务的类名 + 方法签名。
全局(Global)展示的是所有服务的各项指标,包括:
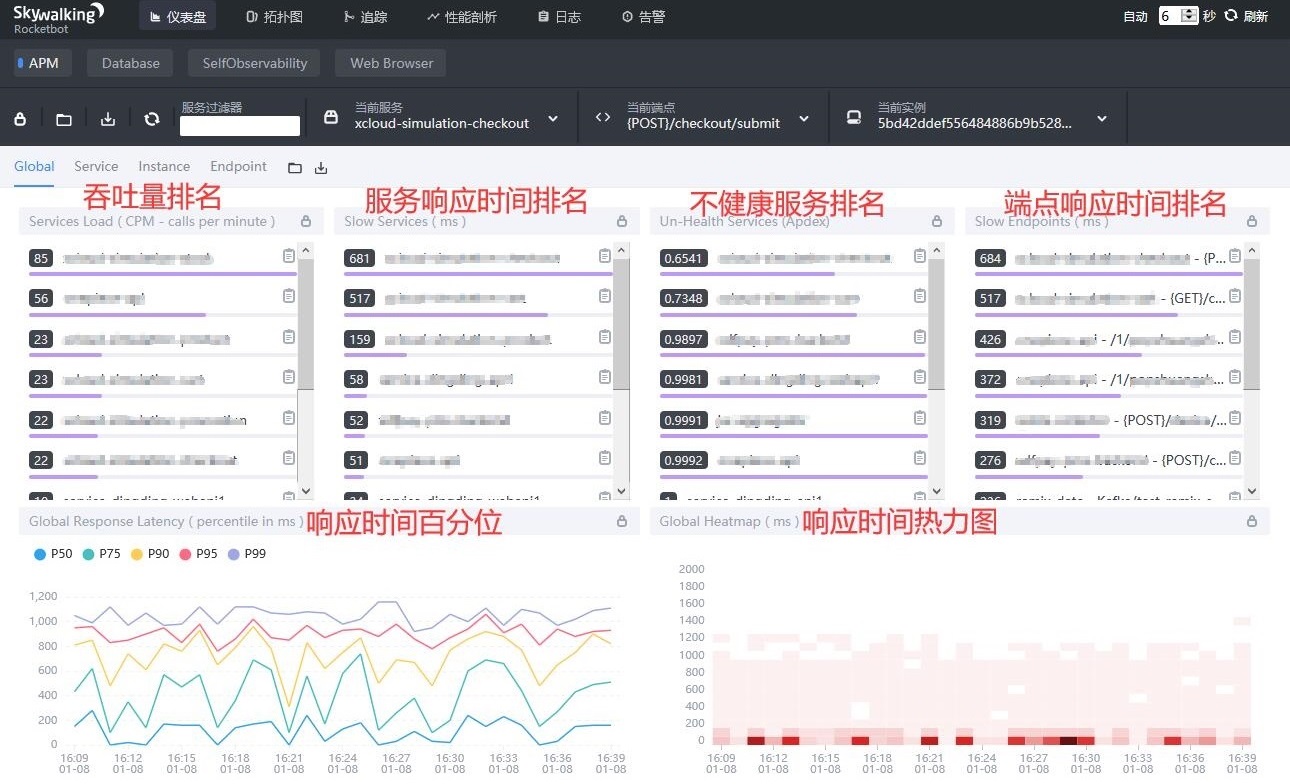
- 吞吐量排名,单位为CPM(calls per minute,每分钟的调用次数)。
- 服务响应时间排名,单位为毫秒。
- 不健康服务排名,单位为Apdex(Application Performance Index,应用性能指数)。
- 端点响应时间排名,单位为毫秒。
- 响应时间百分位,包括
p99,p95,p90,p75,p50,单位为毫秒。 - 响应时间热力图,单位为毫秒。
APM - 服务(Service)相关概念解释:
- Apdex:Application Performance Index,应用性能指数, Apdex = (满意样本数 + 可容忍样本数 * 0.5) / 样本总数,满意样本为响应时间小等于
Apdex阈值,可容忍样本为响应时间大于Apdex阈值并小等于4倍的Apdex阈值。目前Apdex阈值为0.5秒。
服务(Service)是以服务的维度展示各项指标,包括:
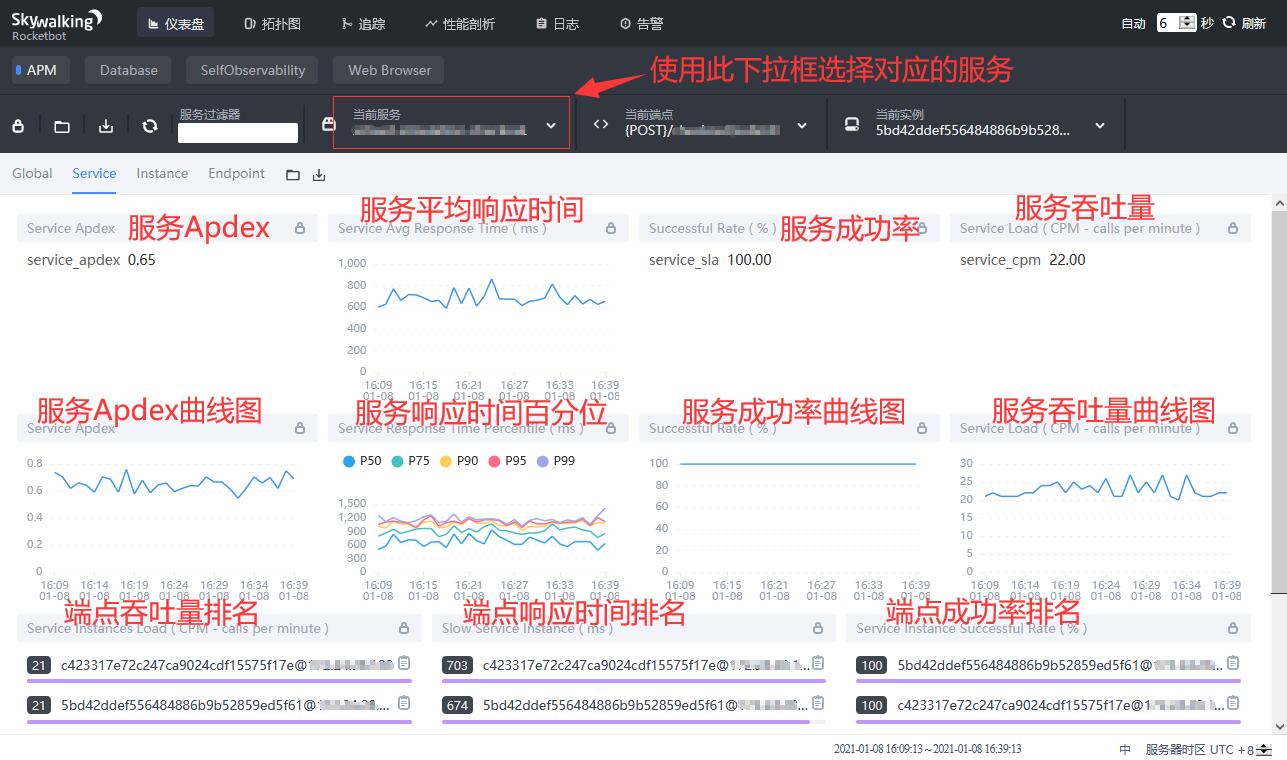
- 服务Apdex(Application Performance Index,应用性能指数)。
- 服务平均响应时间,单位为毫秒。
- 服务成功率。
- 服务吞吐量,单位为CPM(calls per minute,每分钟的调用次数)。
- 服务Apdex曲线图。
- 服务百分位,包括
p99,p95,p90,p75,p50,单位为毫秒。 - 服务成功率曲线图。
- 服务吞吐量曲线图,单位为CPM(calls per minute,每分钟的调用次数)。
- 端点吞吐量排名,单位为CPM(calls per minute,每分钟的调用次数)。
- 端点响应时间排名,单位为毫秒。
- 端点成功率排名。
服务实例(Instance)是以实例的维度展示各项指标,包括:
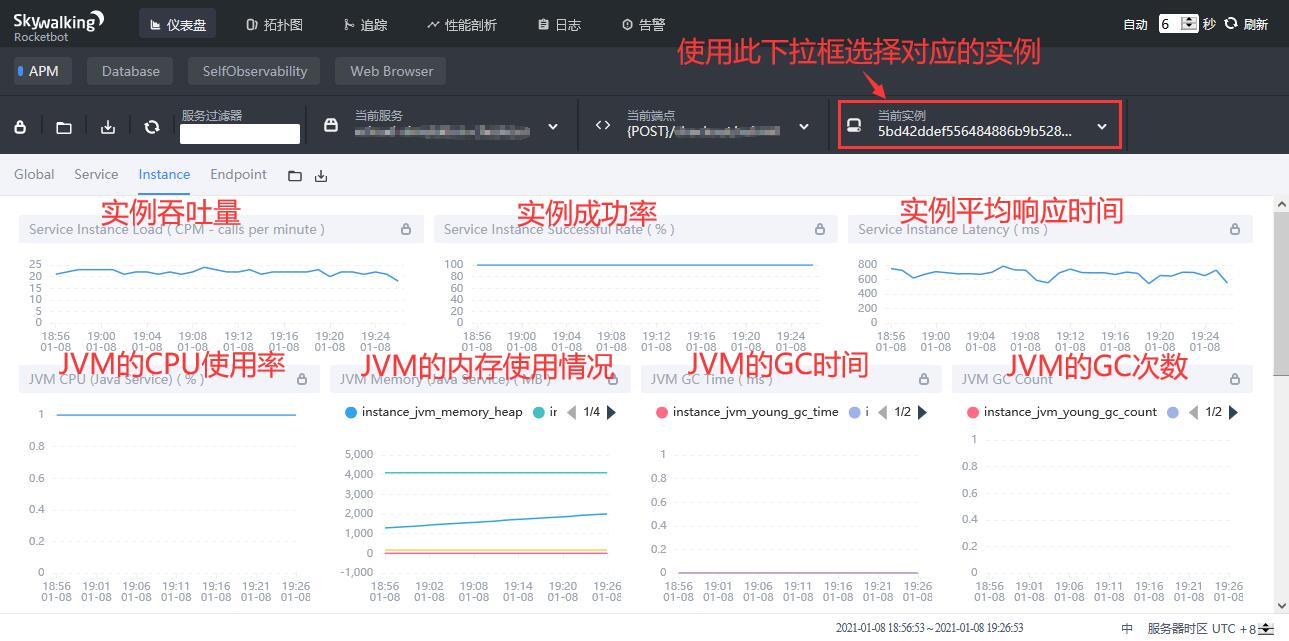
- 实例吞吐量,单位为CPM(calls per minute,每分钟的调用次数)。
- 实例成功率。
- 实例平均响应时间,单位为毫秒。
- JVM的CPU使用百分比。
- JVM的内存使用情况。
- JVM的GC时间。
- JVM的GC次数。
端点(Endpoint)是以端点的维度展示各项指标,包括:
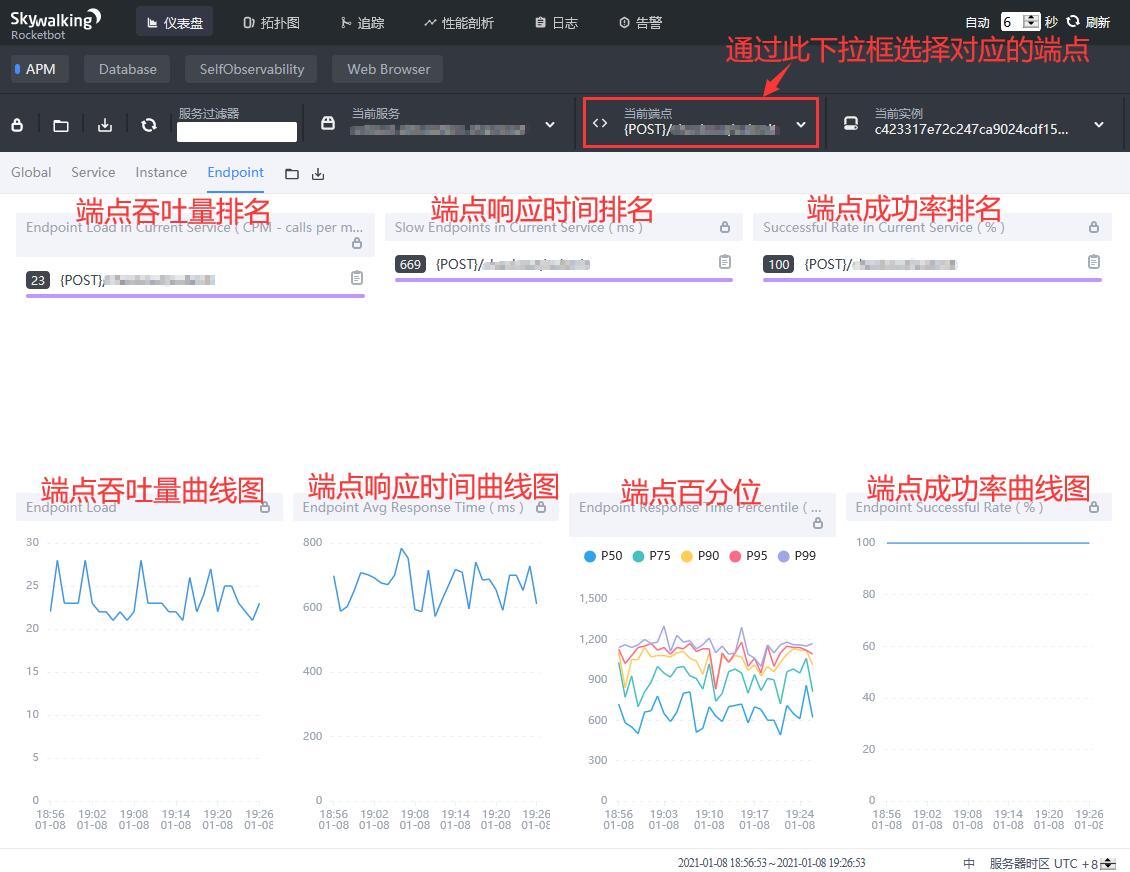
- 端点吞吐量排名,单位为CPM(calls per minute,每分钟的调用次数)。
- 端点平均响应时间排名,单位为毫秒。
- 端点成功率排名。
- 端点吞吐量曲线图,单位为CPM(calls per minute,每分钟的调用次数)。
- 端点平均响应时间曲线图,单位为毫秒。
- 端点百分位,包括
p99,p95,p90,p75,p50,单位为毫秒。 - 端点成功率曲线图。
文章持续更新,微信搜索「万猫学社」第一时间阅读,关注后回复「电子书」,免费获取12本Java必读技术书籍。
Database展示数据库(Database)相关的各项指标,包括:
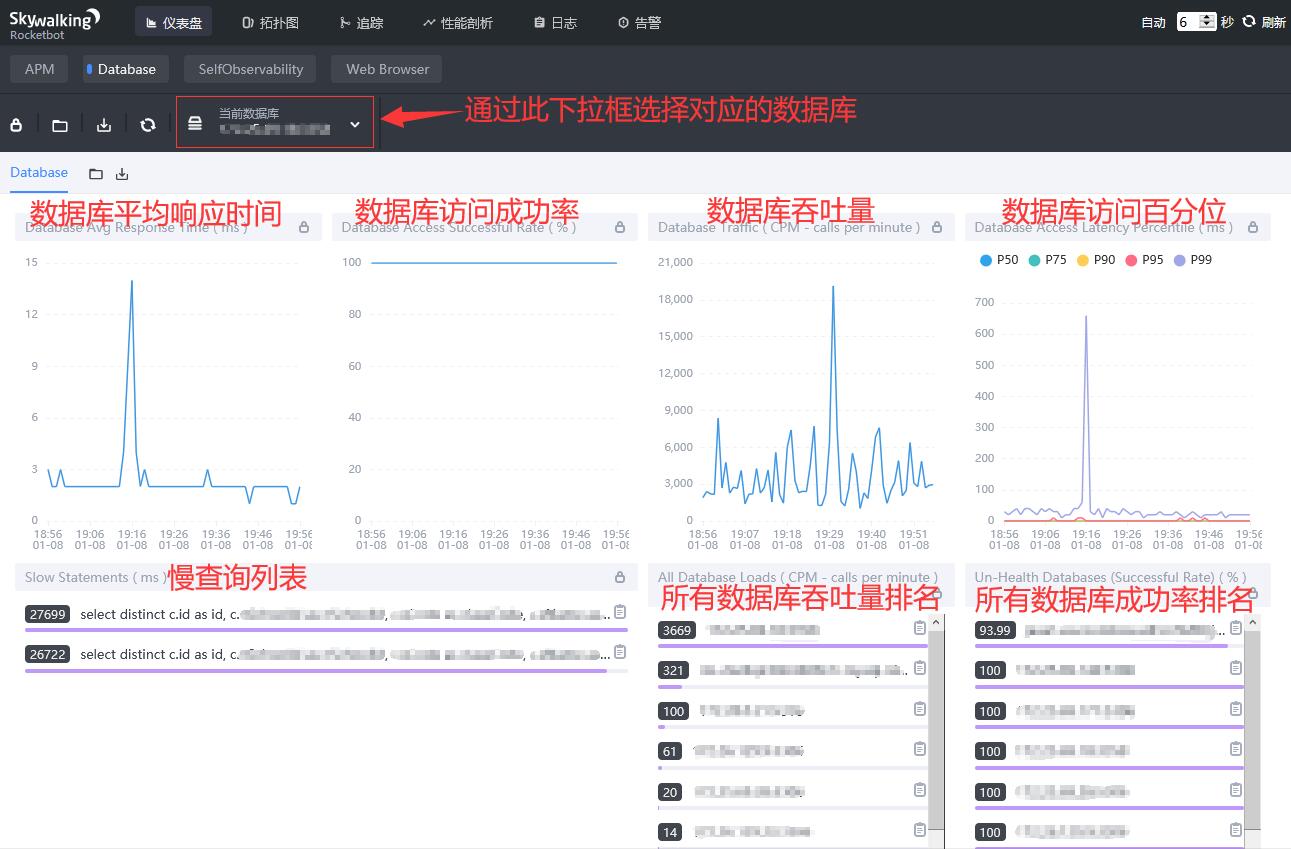
- 数据库平均响应时间,单位为毫秒。
- 数据库访问成功率。
- 数据库吞吐量,单位为CPM(calls per minute,每分钟的调用次数)。
- 数据库访问百分位,包括
p99,p95,p90,p75,p50,单位为毫秒。 - 慢查询列表,单位为毫秒。
- 所有数据库吞吐量排名,单位为CPM(calls per minute,每分钟的调用次数)。
- 所有数据库成功率排名。
拓扑图可以显示服务之间的拓扑关系,如下图:
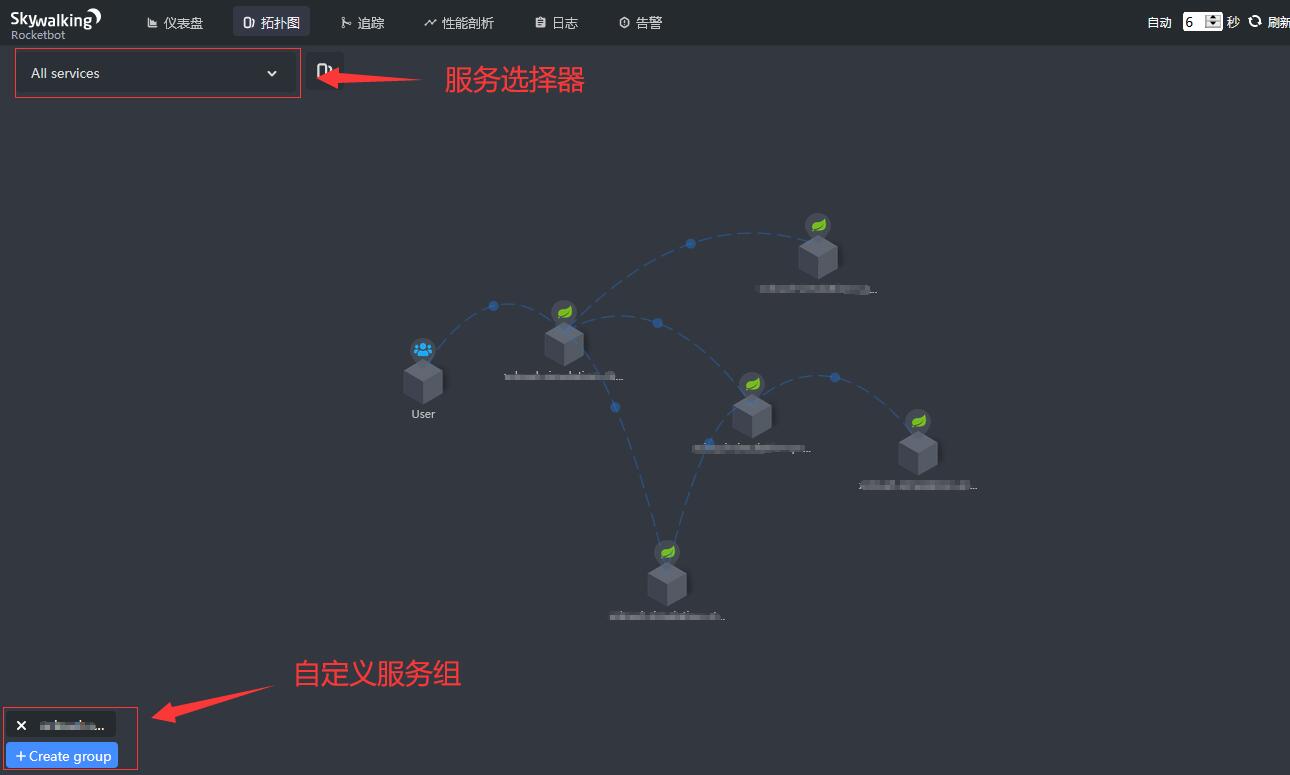
- 服务选择器,可以选择某个服务,显示其直接关系,包括上游和下游。
- 自定义组,可以创建自定义的任意一组服务,用于显示其一组服务的拓扑图。
点击某些服务的图标,可查看该服务的类型、Apdex、成功率、响应时间、吞吐量、百分位等信息,如下图:
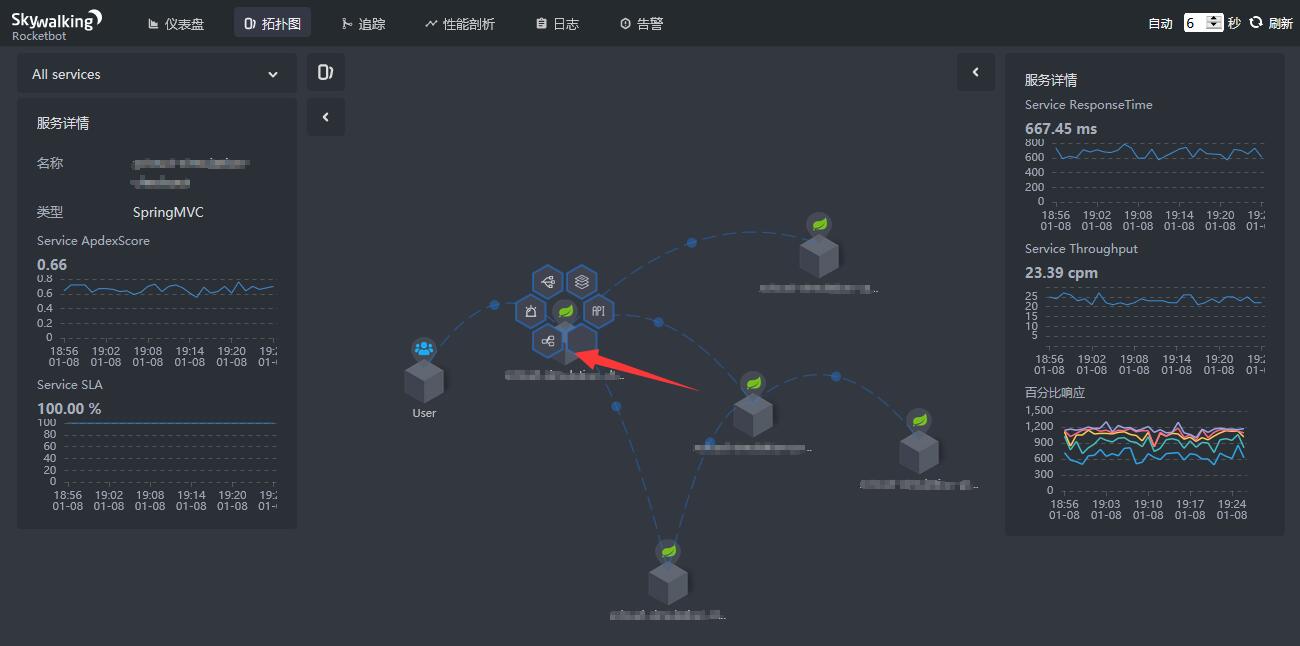
点击服务之间的连线,可查看两个服务之间的响应时间、吞吐量、成功率、百分位等信息,如下图:

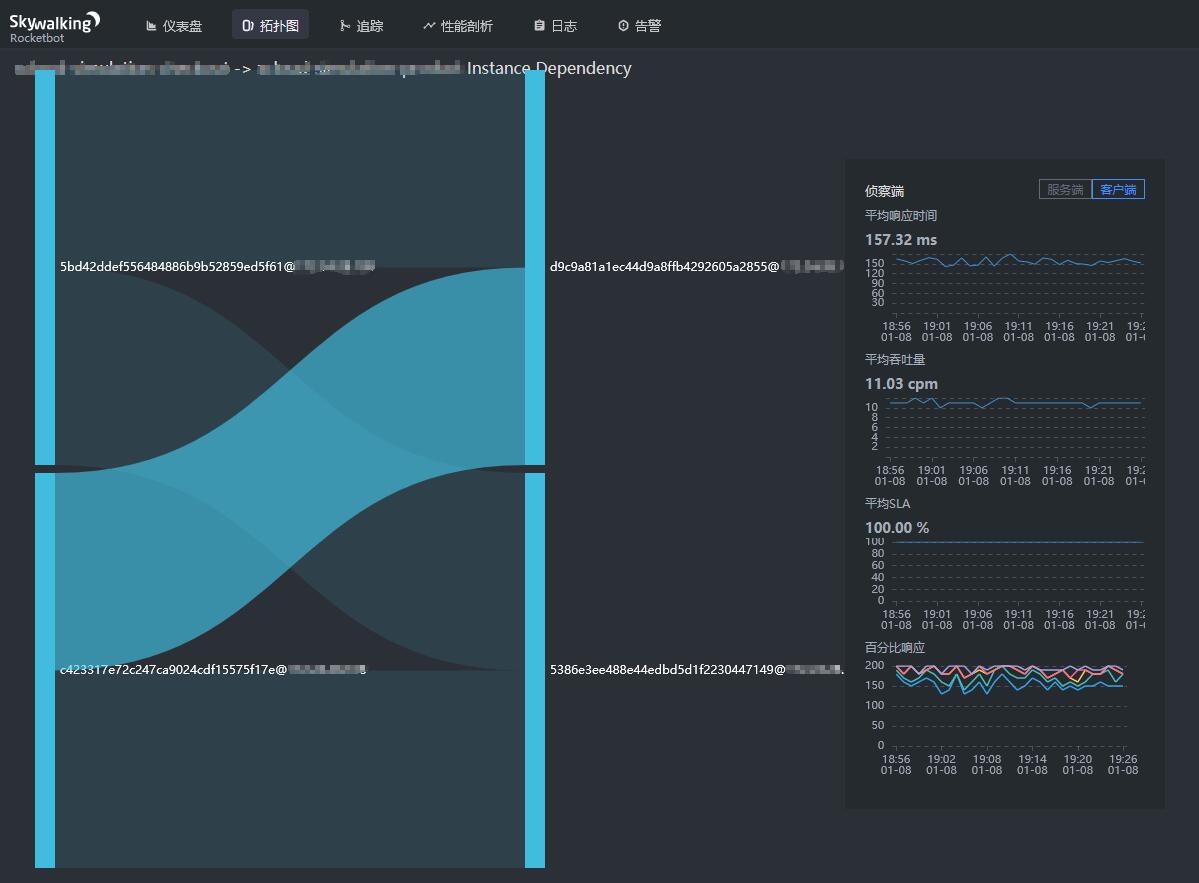
点击上图中的展示实例依赖按钮,可查看各个实例之间的响应时间、吞吐量、成功率、百分位等信息,如下图:
追踪页面可以查询到某个分布式链路的整体情况,如下图:
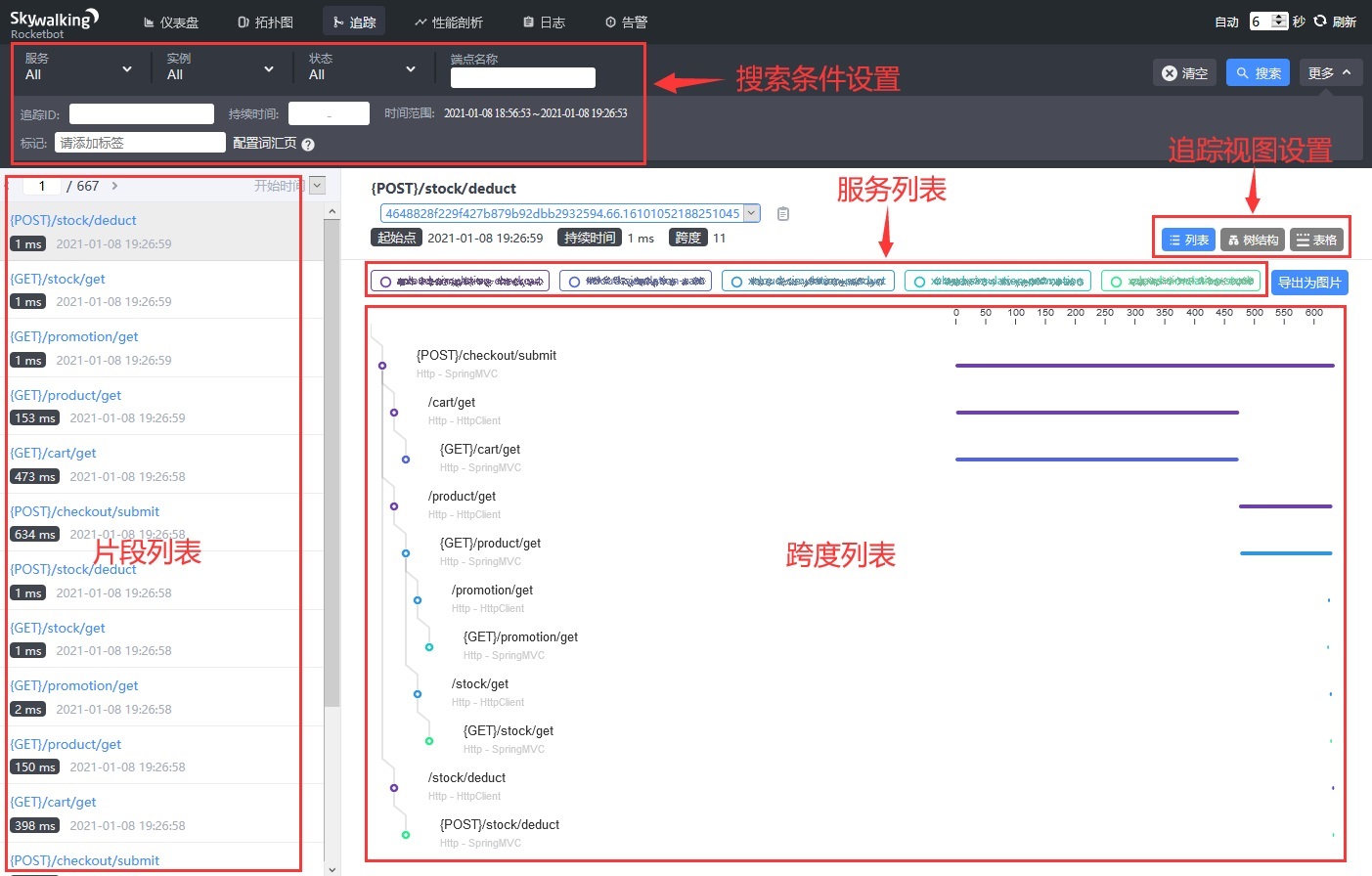
- 搜索条件设置,支持按服务、实例、端点名称、追踪ID、时间范围等条件进行查询。
- 片段(Segment)列表,点击某个片段(Segment),在右侧展示与片段(Segment)相关的整个追踪(Trace)。
- 服务列表,是这个追踪(Trace)涉及的所有服务,每个服务用不同的颜色展示。
- 跨度(Span)列表,是这个追踪(Trace)涉及的所有跨度(Span),还可以看到每个跨度(Span)耗时和层级关系。点击某个跨度(Span),可以看到它的等服务名称、端点名称信息。
- 追踪(Trace)视图设置,提供3种视图展示追踪(Trace):列表、树结构、表格。
相关概念解释:
- 追踪(Trace):一个追踪(Trace)表示一个事务或者流程在分布式系统中的执行过程,是一条完整的分布式调用链。
- 跨度(Span):一个跨度(Span)表示系统中具有开始时间和执行时长的逻辑运行单元。跨度(Span)之间通过嵌套或者顺序排列建立逻辑因果关系,最终形成一个追踪(Trace)。
- 片段(Segment):一个片段(Segment)表示同一端点内的一组跨度(Span)的集合。
常见的错误可能是由代码异常或网络故障引起的,通过追踪(Trace)视图提供的跨度(Span)细节,可以快速找到错误发生在哪个环节。
性能刨析性能剖析是利用方法栈快照,并对方法执行情况进行分析和汇总,对代码执行速度进行估算。
性能剖析激活时,会对指定线程周期性的进行线程栈快照,并将所有的快照进行汇总分析,如果两个连续的快照含有同样的方法栈,则说明此栈中的方法大概率在这个时间间隔内都处于执行状态。从而,通过这种连续快照的时间间隔累加成为估算的方法执行时间。
文章持续更新,微信搜索「万猫学社」第一时间阅读,关注后回复「电子书」,免费获取12本Java必读技术书籍。
创建任务想要进行性能刨析,我们必须创建一个任务,如下图:
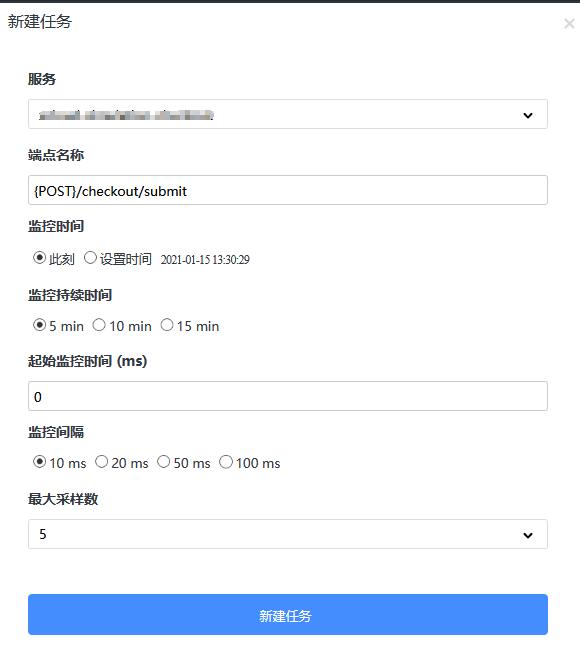
- 选择指定的服务。
- 输入端点名称,这里的端点名称通常是第一个片段(Segment)的操作名,在追踪页面的追踪(Trace)视图里可以找到。
- 选择监控时间,可以从现在开始,也可以从未来的任何时间开始。
- 选择监视持续时间,可以设置监视的时间窗口,以查找到合适的请求进行性能刨析。
- 监控间隔,提供了一个过滤器机制,如果给定端点响应的请求很快,它就不会性能刨析,可以确保性能刨析的数据是预期的数据。
- 最大采样数,表示探针收集的最大数据集,它有助于减少内存和网络负载。
即使性能刨析对目标系统的性能影响非常有限,但它仍然是一个额外的负载,以上设置可以使性能影响可控。另外,在任何时刻,每个服务只能执行一个性能刨析任务。
分析结果等待性能刨析的任务完成后,对应的片段(Segment)就会在右侧展示出来。点击某个片段(Segment),可以更详细地看到各个片段(Segment)的耗时,如下图:
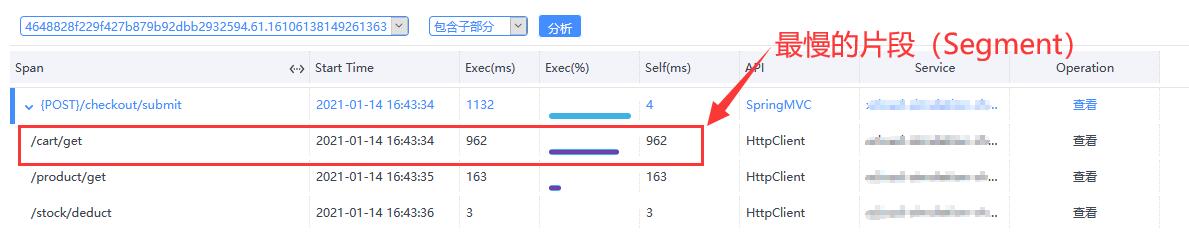
从上图可以看到最慢的片段(Segment)。点击分析按钮,可以看到基于方法栈的分析结果,包括对应的类名、方法名、代码行数、耗时等信息,最慢的方法栈被高亮显示,如下图:
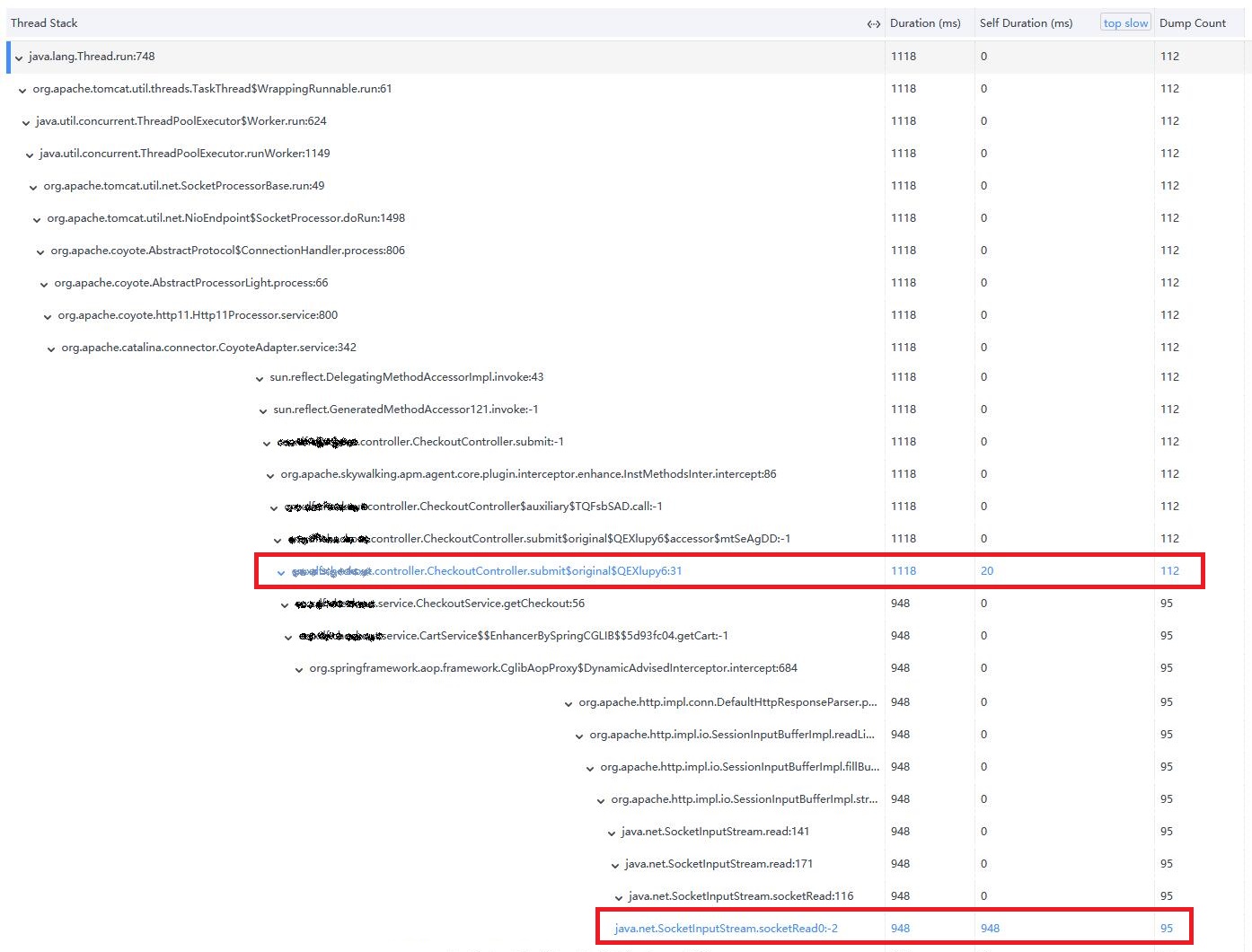
- 精确的问题定位,直接找到代码方法和代码行;
- 无需反复的增删埋点,大大减少了人力开发成本;
- 不用承担过多埋点对目标系统和监控系统的压力和性能风险;
- 按需使用,平时对系统无消耗,使用时的消耗稳定可控。
在告警页面可以查看所有触发的告警,如下图:
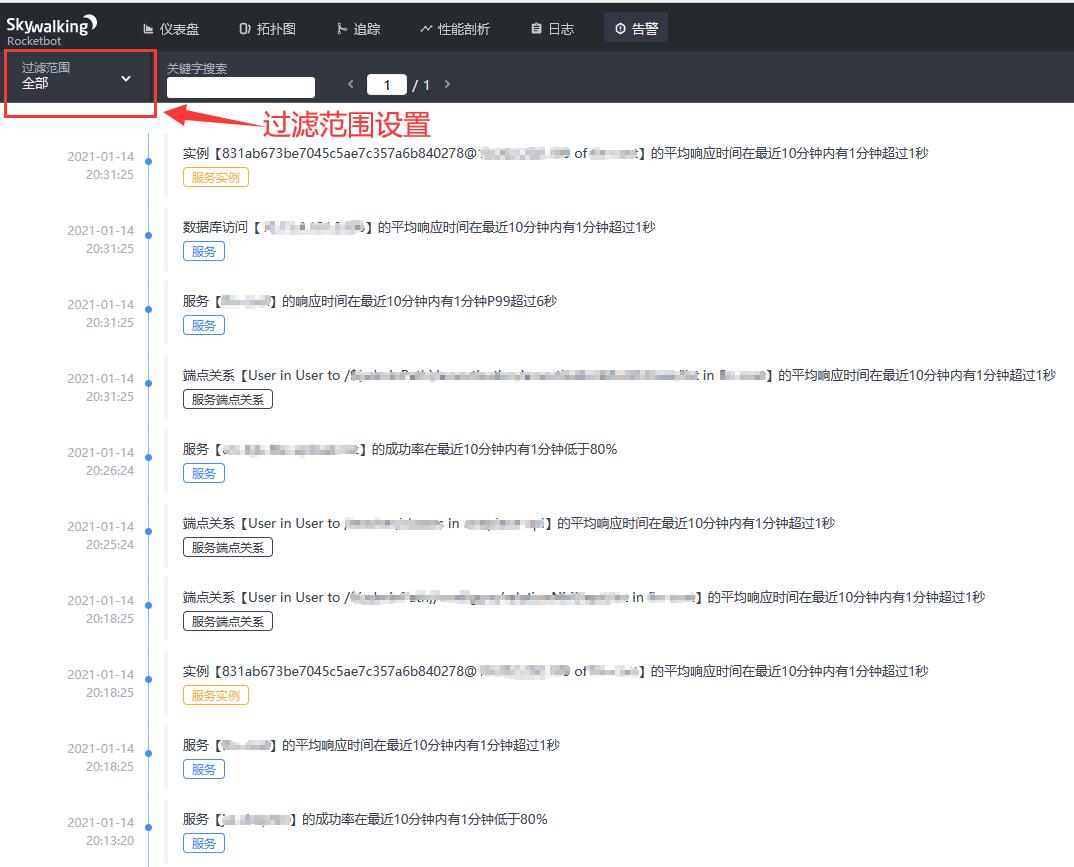
过滤范围的设置包括:服务、服务实例、端点、服务关系、服务实例关系、端点关系等。
微信公众号:万猫学社
微信扫描二维码
关注后回复「电子书」
获取12本Java必读技术书籍
