 不同的优化算法采用不同的方法对目标函数进行优化,以寻找最优预测模型。其中最重要的两个特性就是收敛速率和复杂度。优化算法最初都是确定性的,不过近年来随着机器学习中数据规模的不断增大,优化问题复杂度不断增高,原来越多的优化算法发展出了随机版本和并行化版本。依据算法在优化过程中所利用的是一阶导数信息还是二阶导数信息,还可把优化算法分为一阶方法和二阶方法。
1 优化问题定义
不同的优化算法采用不同的方法对目标函数进行优化,以寻找最优预测模型。其中最重要的两个特性就是收敛速率和复杂度。优化算法最初都是确定性的,不过近年来随着机器学习中数据规模的不断增大,优化问题复杂度不断增高,原来越多的优化算法发展出了随机版本和并行化版本。依据算法在优化过程中所利用的是一阶导数信息还是二阶导数信息,还可把优化算法分为一阶方法和二阶方法。
1 优化问题定义
我们考虑以下有监督机器学习问题。假设输入数据\(D=\{(x_i, y_i)\}_{i=1}^n\)依据输入空间\(\mathcal{X} \times \mathcal{Y}\)的真实分布\(p(x, y)\)独立同分布地随机生成。我们想根据输入数据学得参数为\(w\)的模型\(h(\space \cdot\space; w)\),该模型能够根据输入\(x\)给出接近真实输出\(y\)的预测结果\(h(x; w)\)。我们下面将参数\(w\)对应的模型简称为模型\(w\),模型预测好坏用损失函数\(\mathcal{l}(w; x, y)\)衡量。则正则化经验风险最小化(R-ERM)问题的目标函数可以表述如下:
\[\hat{l}_n(w) = \frac{1}{n}\sum_{i=1}^n\mathcal{l}(w; x_i, y_i) + \lambda R(w) \]其中\(R(\space \cdot\space)\)为模型\(w\)的正则项。
由于在优化算法的运行过程中,训练数据已经生成并且保持固定,为了方便讨论且在不影响严格性的条件下,我们将上述目标函数关于训练数据的符号进行简化如下:
\[f(w) = \frac{1}{n}\sum_{i=1}^nf_i(w) \]其中\(f_i(w)=\mathcal{l}(w, x_i, y_i) + \lambda R(w)\)是模型\(w\)在第\(i\)个训练样本\((x_i, y_i)\)上的正则损失函数。
不同的优化算法采用不同的方法对上述目标函数进行优化,以寻找最优预测模型。看似殊途同归,但实践中的性能和效果可能有很大差别,其中最重要的两个特性就是收敛速率和复杂度。
假设优化算法所产生的模型参数迭代序列为\(\{w^t\}\),其中\(w^t\)为第\(t\)步迭代中输出的模型参数,R-ERM问题的最优模型为\(w^* = \text{arg min}_w f(w)\)。一个有效的优化算法会使序列\(\{w_t\}\)收敛于\(w^*\)。我们用\(w^t\)与\(w^*\)在参数空间中的距离来衡量其接近程度,即
\[\mathbb{E}\lVert w^t - w^*\rVert^2\leqslant \epsilon(t) \]若用正则化经验风险的差值来衡量,则为
\[\mathbb{E} [f(w^t) - f(w^*)]\leqslant \epsilon(t) \]来衡量。
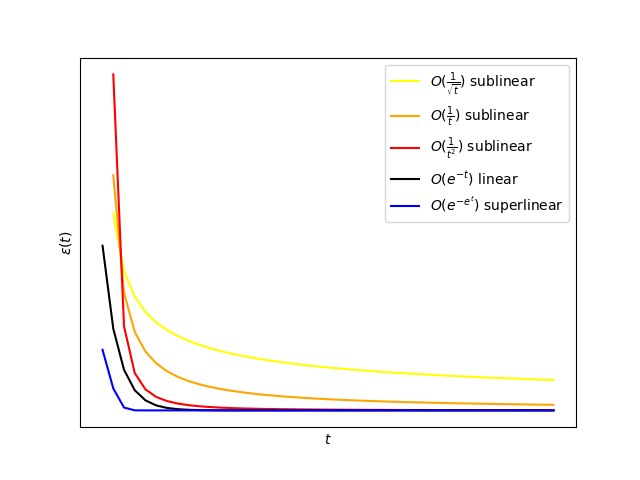
\(\epsilon(t)\)可视为关于\(t\)的函数,收敛的算法都满足随着\(t\rightarrow \infty\),有\(\epsilon(t)\rightarrow 0\),不过其渐进收敛速率各有不同。通常用\(\text{log}\space \epsilon(t)\)的衰减速率来定义优化算法的渐进收敛速率。
-
如果\(\log \epsilon(t)\)与\(-t\)同阶,则称该算法具有线性(linear)收敛率。
例: \(\mathcal{O}(\text{e}^{-t})\)
-
如果\(\log \epsilon(t)\)比\(-t\)衰减速度慢,则称该算法具有次线性(sublinear)收敛率。
例: \(\mathcal{O}(\frac{1}{\sqrt{t}})、\mathcal{O}(\frac{1}{t})、\mathcal{O}(\frac{1}{t^2})\)
-
如果\(\log \epsilon(t)\)比\(-t\)衰减速度快,则称该算法具有超线性(superlinear)收敛率(进一步地,如果\(\log \log \epsilon(t)\)与\(-t\)同阶,则该算法有二阶收敛速率)。
例:\(\mathcal{O}(\text{e}^{-\text{e}^t})\)
收敛速率各阶数对比可参照下图:
 3 复杂度
3 复杂度
优化算法的复杂度需要考虑单位计算复杂度与迭代次数复杂度。单位计算复杂度是优化算法进行单次迭代计算需要的浮点运算次数,如给定\(n\)个\(d\)维样本,采用梯度下降法来求解模型的单位计算复杂度为\(\mathcal{O}(nd)\),随机梯度下降法则是\(\mathcal{O}(d)\)。迭代次数复杂度则是指计算出给定精度\(\epsilon\)的解所需要的迭代次数。比如若我们的迭代算法第\(T\)步输出的模型\(w_t\)与最优模型\(w^*\)满足关系
\[f(w_t) - f(w^*) \leqslant \frac{c}{\sqrt{t}} \],若要计算算法达到精度\(f(w^t) - f(w^*) \leqslant \epsilon\)所需的迭代次数,只需令\(\frac{c}{\sqrt{t}}\leqslant \epsilon\)得到\(t \geqslant \frac{c^2}{\epsilon^2}\),因此该优化算法对应的迭代次数复杂度为\(\mathcal{O}(\frac{1}{\varepsilon^2})\)。注意,渐进收敛速率更多的是考虑了迭代次数充分大的情形,而迭代次数复杂度则给出了算法迭代有限步之后产生的解与最优解之间的定量关系,因此近年来受到人们广泛关注。
我们可以根据单位计算复杂度和迭代次数复杂度来得到总计算复杂度,如梯度下降法单位计算复杂度为\(\mathcal{O}(nd)\),在光滑强凸条件下的迭代次数复杂度为\(\mathcal{O}\left(\log(\frac{1}{\varepsilon})\right)\),则总计算复杂度为\(\mathcal{O}\left(nd\log{(\frac{1}{\varepsilon})}\right)\)。随机梯度下降法单位计算复杂度为\(\mathcal{O}(d)\),在光滑强凸条件下的迭代次数复杂度为\(\mathcal{O}(\frac{1}{\varepsilon})\),则总计算复杂度为\(\mathcal{O}(\frac{d}{\varepsilon})\)。
4 假设条件目前大多数优化算法的收敛性质都需要依赖目标函数具有某些良好的数学属性,如凸性和光滑性。近年来由于深度学习的成功人们也开始关注非凸优化问题。我们这里先讨论凸优化的假设。
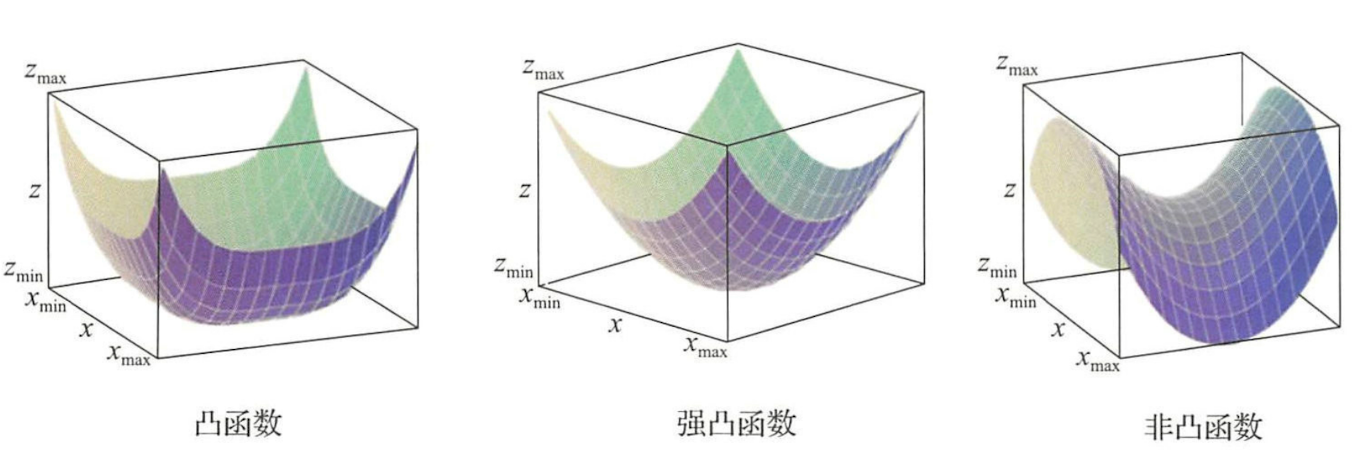
凸函数 考虑实值函数\(f:\mathbb{R}^d\rightarrow \mathbb{R}\),如果对任意自变量\(w, v \in \mathbb{R}^d\)都有下列不等式成立:
\[f(w) - f(v) \geqslant \nabla f(v)^T(w-v) \]则称函数\(f\)是凸的(可以直观理解为自变量任何取值处的切线都在函数曲面下方)。
凸性会给优化带来很大方便。原因是凸函数任何一个局部极小点都是全局最优解。对于凸函数还可以进一步区分凸性的强度,强凸性质的定义如下:
强凸函数 考虑实值函数\(f:\mathbb{R}^d\rightarrow \mathbb{R}\)和\(\mathbb{R}^d\)上范数\(\lVert \space \cdot \space \rVert\),如果对任意自变量\(w, v \in \mathbb{R}^d\)都有下列不等式成立:
\[f(w) - f(v) \geqslant \nabla f(v)^T(w-v) + \frac{\alpha}{2} \lVert w - v \rVert^2 \]则称函数\(f\)关于范数\(\lVert \space \cdot \space \rVert\)是\(\alpha\)-强凸的。
可以验证当函数\(f\)是\(\alpha\)强凸的当前仅当\(f - \frac{\alpha}{2} \lVert \space\cdot \space \rVert^2\)是凸的。
下图中给出了凸函数、强凸函数和非凸函数的直观形象:
光滑性刻画了函数变化的缓急程度。直观上,如果自变量的微小变化只会引起函数值的微小变化,我们说这个函数是光滑的。对于可导和不可导函数,这个直观性质有不同的数学定义。
对于不可导函数,通常用Lipschitz性质来描述光滑性。
Lipschitz连续 考虑实值函数\(f:\mathbb{R}^d\rightarrow \mathbb{R}\)和\(\mathbb{R}^d\)上范数\(\lVert \space \cdot \space \rVert\),如果存在常数\(L>0\),对任意自变量\(w, v \in \mathbb{R}^d\)都有下列不等式成立:
\[|f(w) - f(v)| \leqslant L \lVert w - v \rVert \]则称函数\(f\)关于范数\(\lVert \space \cdot \space \rVert\)是\(L\)-Lipschitz连续的。
对于可导函数,光滑性质依赖函数的导数,定义如下:
光滑函数 考虑实值函数\(f:\mathbb{R}^d\rightarrow \mathbb{R}\)和\(\mathbb{R}^d\)上范数\(\lVert \space \cdot \space \rVert\),如果存在常数\(\beta>0\),对任意自变量\(w, v \in \mathbb{R}^d\)都有下列不等式成立:
\[f(w) -f(v) \leqslant \nabla f(v)^T(w-v) + \frac{\beta}{2} \lVert w - v \rVert^2 \]则称函数\(f\)关于范数\(\lVert \space \cdot \space \rVert\)是\(\beta\)-光滑的。
下图是Lipshitz连续函数和光滑函数的直观形象:
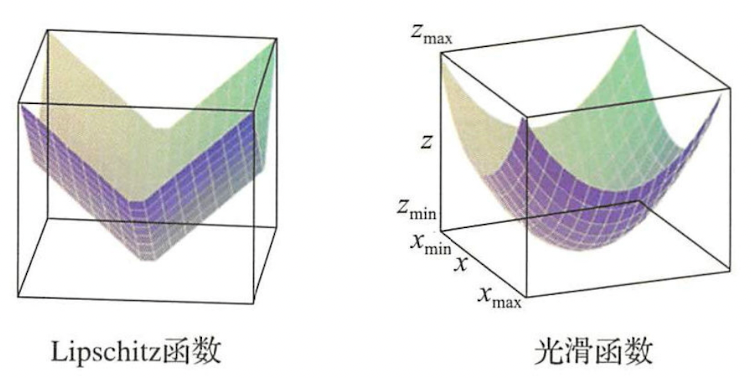
可以验证,凸函数\(f\)是\(\beta\)-光滑的充分必要条件是其导数\(\nabla f\)是\(\beta\)-Lipschitz连续的。所以,\(\beta\)-光滑函数的光滑性质比Lipschitz连续的函数的光滑性质更好。
5 算法分类和发展历史数值优化算法的发展历史如下图所示:
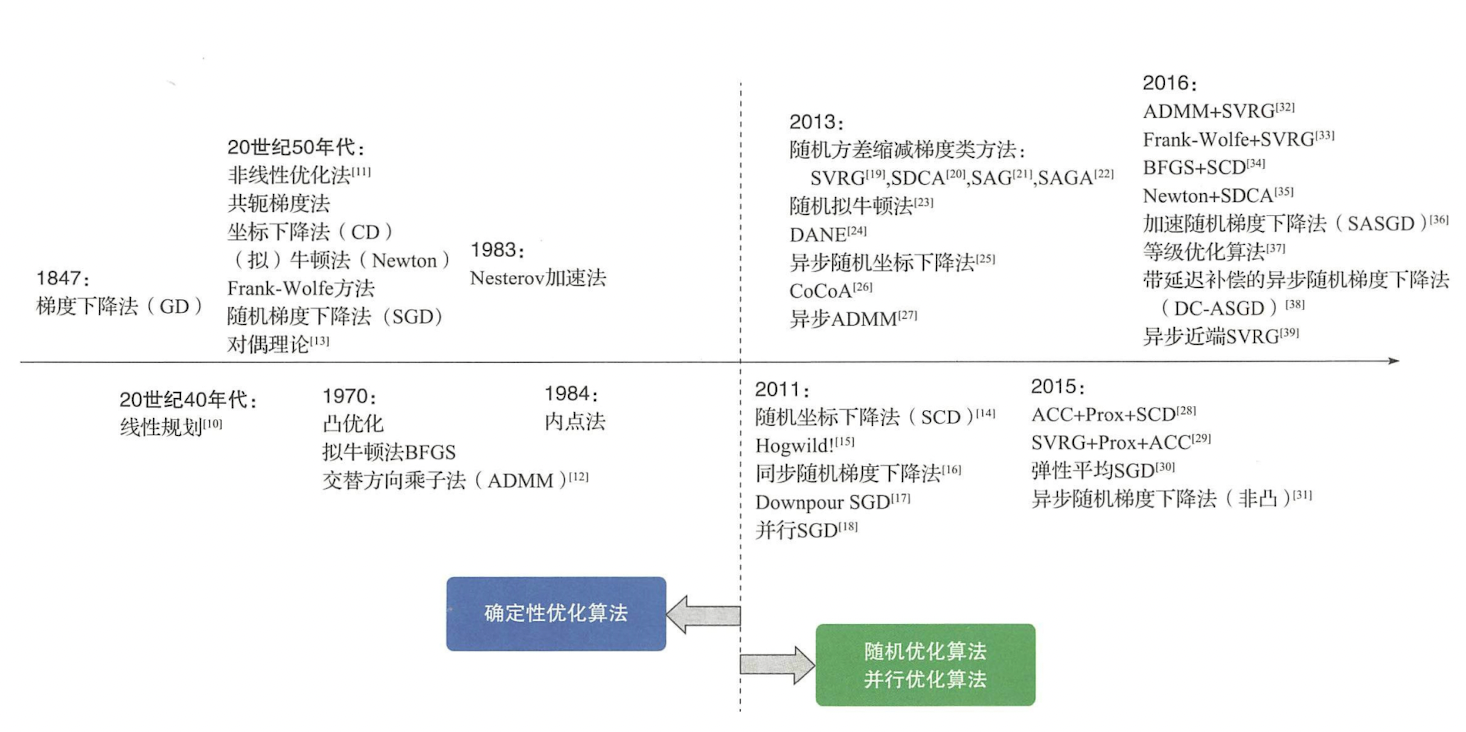
可以看到,优化算法最初都是确定性的,也就是说只要初始值给定,这些算法的优化结果就是确定性的。不过近年来随着机器学习中数据规模的不断增大,优化问题复杂度不断增高,原来越多的优化算法发展出了随机版本和并行化版本。
为了更好地对众多算法进行分析,我们对其进行了如下分类:
- 依据是否对数据或变量进行随机采样,把优化算法分为确定性算法和随机算法。
- 依据算法在优化过程中所利用的是一阶导数信息还是二阶导数信息,把优化算法分为一阶方法和二阶方法。
- 依据优化算法是在原问题空间还是在对偶空间进行优化,把优化算法分为原始方法和对偶方法。
以上分类可以用下图加以总结:
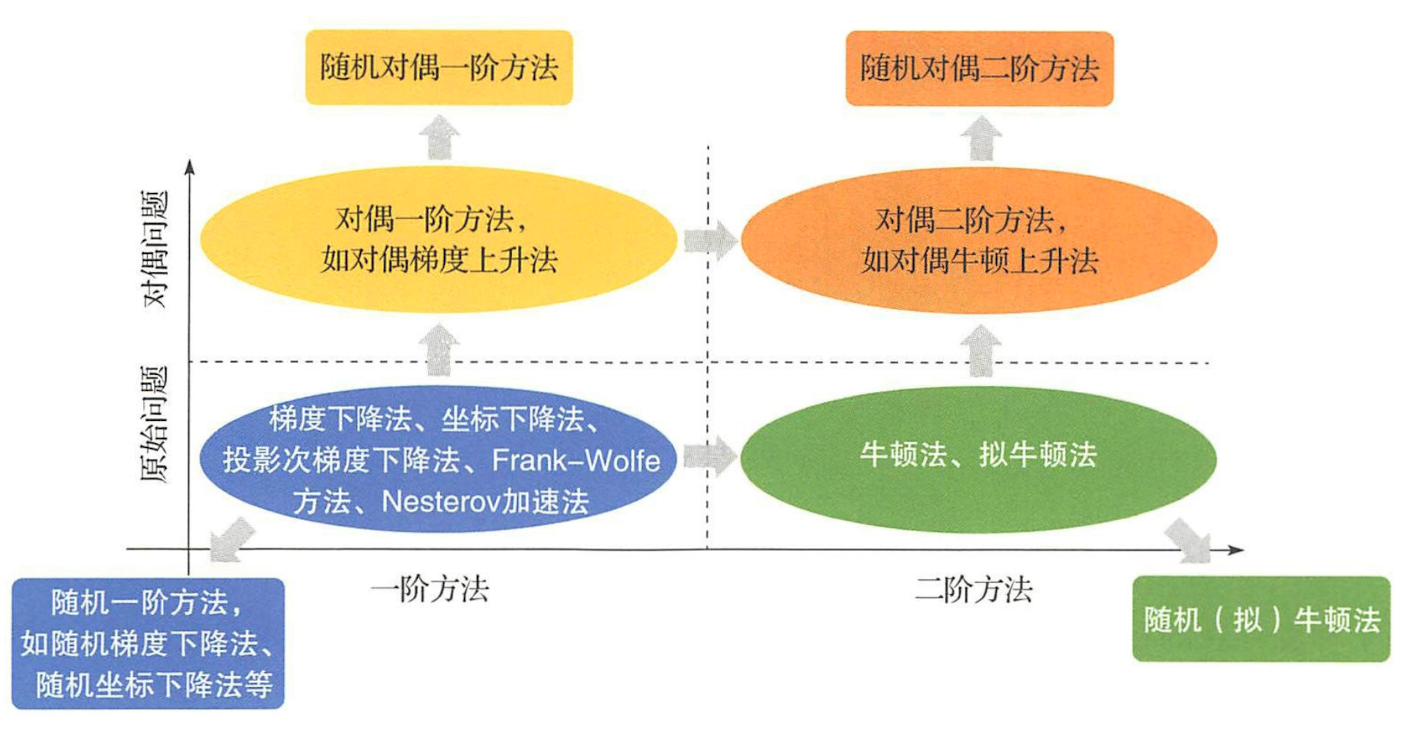
我们下面的博客将依次讨论一阶和二阶确定性算法、单机随机优化算法和并行优化算法,大家可以继续关注。
参考- [1] 刘浩洋,户将等. 最优化:建模、算法与理论[M]. 高教出版社, 2020.
- [2] 刘铁岩,陈薇等. 分布式机器学习:算法、理论与实践[M]. 机械工业出版社, 2018.
- [3] Stanford CME 323: Distributed Algorithms and Optimization (Lecture 7)