 学习MySQL锁的一些概念和简单的实践,每章节至少读两遍,才能明白一些东西,整理下方便以后查询。
全局锁、表锁和行锁
学习MySQL锁的一些概念和简单的实践,每章节至少读两遍,才能明白一些东西,整理下方便以后查询。
全局锁、表锁和行锁
全局锁MySQL45讲基础篇:根据加锁的范围,MySQL里面的锁大致分为全局锁、表锁、行锁三类
实现:对整个数据库实例进行加锁,使用FTWRL.
Flush table with read lock
效果:整个库处于只读状态,DML和DDL以及更新事务的提交语句都会被阻塞。
全局锁使用场景:做全库逻辑备份(binlog)--也就是把整库每个表都 select 出来存成文本
做全库逻辑备份:
- 加全局锁:整个库处于阻塞状态,无法更新,这对线上是不可能采用的
- 不加全局锁:当我在备份的时候,由数据更新,造成,备份库和本地库不匹配,没有意义
准确点说:
不加锁的话,备份系统备份的得到的库不是一个逻辑时间点,这个视图是逻辑不一致的
由此,可以引出前面所说的事务隔离中的可重复读(视图中的数据前后一致):
一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是 一致的。当然在可重复读隔离级别下,未提交变更对其他事务也是不可见的。
MySQL多版本并发控制(MVCC):同一条记录在系统中可以存在多个版本,不同时刻启动的事务会有不同的read-view(值)。
具体的实现是:
官方自带的逻辑备份工具是 mysqldump。当 mysqldump 使用参数–single-transaction(所有的表使用事务引擎的库(InnoDB )) 的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。而由于 MVCC 的支持,这个过程中数据是可以正常更新的。
FTWRL与set global readonly=true对比:
- FTWRL:适用于不支持事务的引擎;并且使用后如果客户端发生异常连接断开,那么MySQL会自动释放全局锁。
为了使全库已读,也不推荐:set global readonly=true
- 一是,在有些系统中,readonly 的值会被用来做其他逻辑,比如用来判断一个库是主库还是备库。因此,修改 global 变量的方式影响面更大,我不建议你使用。
- 二是,将整个库设置为 readonly 之后,如果客户端发生异常,则数据库就会一直保持 readonly 状态,这样会导致整个库长时间处于不可写状态,风险较高
表锁语法:lock tables ...read/write
释放锁:unlock tables 或者在客户端断开的时候自动释放
缺点:除了限制别的线程的读写外,也限定了本线程接下来的操作对象
线程A:
lock tables t1 read, t2 write;
如果在某个线程 A 中执行 lock tables t1 read, t2 write; 这个语句,则其他线程写 t1、读写 t2 的语句都会被阻塞。同时,线程 A 在执行 unlock tables 之前,也只能执行读 t1、读写 t2 的操作。连写 t1 都不允许,自然也不能访问其他表。
尽量不要使用全局表锁,对于有innodb引擎的数据库来说,推荐使用:single-transaction
MDL(metadata lock): 不显示使用,在访问一个表的时候会被自动加上。
server层的锁;
规则:读读共享,读写互斥,写写互斥;
问题:表加字段,导致整个库挂掉
给一个表加字段,或者修改字段,或者加索引,需要扫描全表的数据
对表进行增删改查(隐式提交)的时候都会自动加上MDL;
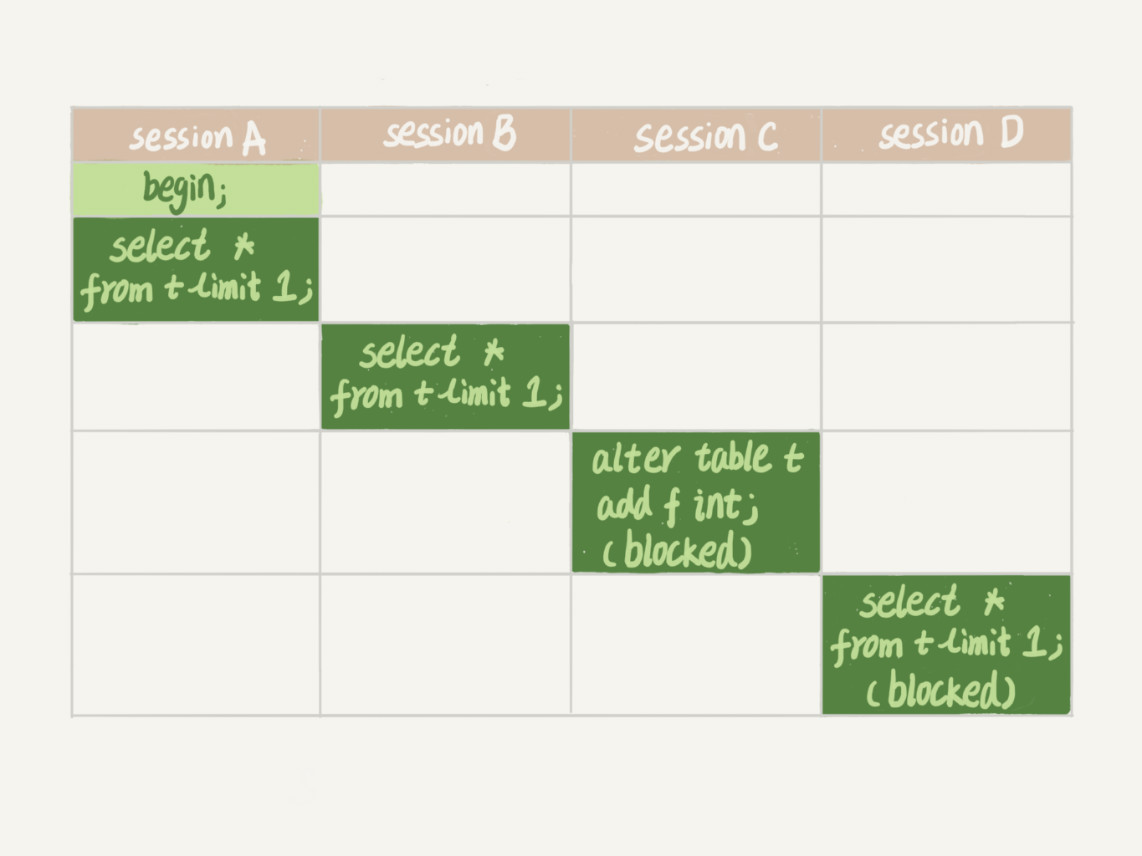
显示使用事务:begin---commit;
- sessionA 加读锁--未释放
- sessionB 加读锁,读读不互斥,可以使用
- sessionC 修改表(加字段--写锁),前面读锁未释放,所以等待
- 后续对于t表的操作都会阻塞
如果某个表上的查询语句频繁,而且客户端有重试机制,也就是说超时后会再起一个新 session 再请求的话,这个库的线程很快就会爆满;
实践:


事务提交以后:
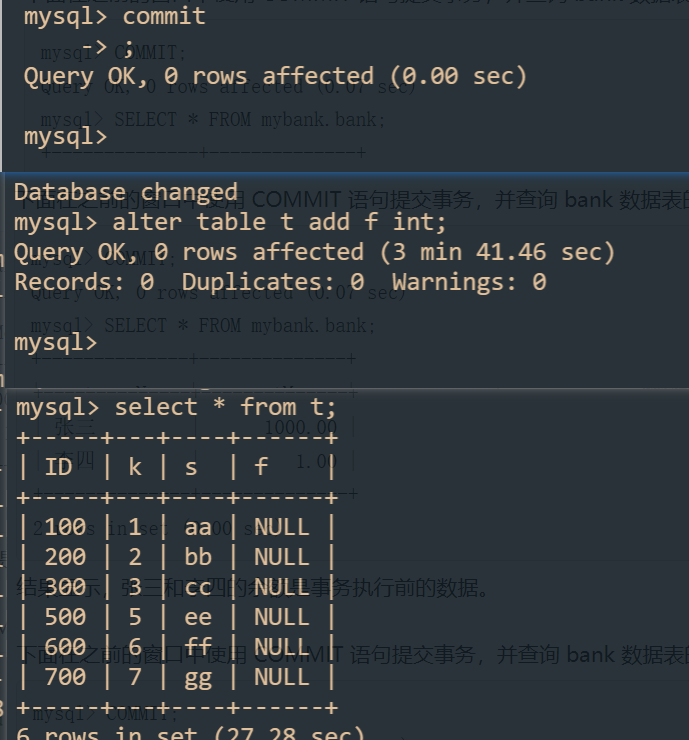
由上引出如何安全给表加字段:
明确产生的原因:解决长事务,事务不提交,就会一直占着 MDL 锁;
如果表的实时性不是很重要,可以考虑暂停DDL的变更或者kill长事务;
表(热点表--请求频繁)的实时性很高的话(数据都是热点数据):
在 alter table 语句里面设定等待时间,如果在这个指定的等待时间里面能够拿到 MDL 写锁最好,拿不到也不要阻塞后面的业务语句,先放弃。之后开发人员或者 DBA 再通过重试命令重复这个过程.
ALTER TABLE tbl_name NOWAIT add column ...
ALTER TABLE tbl_name WAIT N add column ...
行锁每次锁定的是一行数据,行级锁定不是MySQL自己实现锁定的方式,是由存储引擎实现的(InnoDB)自己实现的。
两段锁:在 InnoDB 事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议
通过给索引上的索引项加锁来实现的,也就意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁。这一点在实际应用中特别需要注意,不然的话可能导致大量的锁冲突,从而影响引发并发性能
--共享锁就是允许多个线程同时获取一个锁,一个锁可以同时被多个线程拥有
select ... lock in share mode;
--排它锁,也称作独占锁,一个锁在某一时刻只能被一个线程占有,其它线程必须等待锁被释放之后才可能获取到锁。
select ... for update
如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放。
减少冲突造成的阻塞时间过长。
死锁和死锁检测:当并发系统中不同线程出现循环资源依赖,涉及的线程都在等待别的线程释放资源时,就会导致这几个线程都进入无限等待的状态,称为死锁
解决策略:
- 直接进入等待,直到超时,超时时间参数:innodb_lock_wait_timeout(默认值50s)
- 发起死锁检测,发现死锁后,主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。将参数 innodb_deadlock_detect 设置为 on,表示开启这个逻辑
对于innodb_lock_wait_timeout的默认值来说,时间太长,如果设置一个很小的值,会造成误伤。
推荐使用:主动死锁检测
检测对系统来说还是有额外的负担;这里有一个边界情况:所有事务都要更新同一行的场景
怎么解决由这种热点行更新导致的性能问题呢?假设有 1000 个并发线程要同时更新同一行,那么死锁检测操作就是 100 万这个量级的。虽然最终检测的结果是没有死锁,但是这期间要消耗大量的 CPU 资源。因此,你就会看到 CPU 利用率很高,但是每秒却执行不了几个事务
问题的症结在于,死锁检测要耗费大量的 CPU 资源。
-
临时关闭死锁检测,但并不可靠
-
控制并发度:控制同一行最大线程操作数
问题:如果你要删除一个表里面的前 10000 行数据,有以下三种方法可以做到:
- 第一种,直接执行 delete from T limit 10000;(X)
- 第二种,在一个连接中循环执行 20 次 delete from T limit 500;(
√) - 第三种,在 20 个连接中同时执行 delete from T limit 500。(X)
你会选择哪一种方法呢?为什么呢?
- 长事务,占用的时间比较长,造成等待时间较长,应该避免;
- 将一个长事务,分为20个短事务,每次事务占用锁的时间相对较短;
- 造成锁冲突,当第一个连接中的事务没有提交,那么会阻塞剩余线程。
部分图片引入来源:MySQL实战45讲