学习笔记
前言:此案例中,要求抓取某电影网站内【最新电影栏目】里的电影名称,以及该电影的下载链接,并将这些数据存储在数据库中。
案例(某电影网站数据抓取)
首先,确定要爬取的某电影网站的URL地址
https://www.ygdy8.net/html/gndy/dyzz/index.html
查看网页是否为静态网页(与静态相对的是动态网页)
怎么查看是否为静态网页?我们可以ctrl+f搜索一下想要爬取的数据,如果查询到数据了,就暂时判定是静态的。但如果没有查询到我们想要的数据,且看到一堆堆的css和js文件,则这个网页可能是动态网页。
打开网页源代码,ctrl+f搜索关键字【攀登者】:
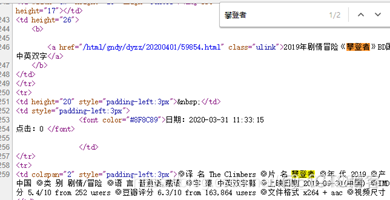
嗯,查询到了数据,该网页应该是静态的。
爬取目标
电影名称(在一级页面中),以及点开电影详情链接后,该电影的下载地址(在二级页面中)。
一级页面中需要爬取的电影名称:

二级页面中需要爬取的下载地址:

这里所谓的二级页面,是相对于一级页面而言的。也就是从一级页面中链接出来的页面。这样说,可能不够形象。举个例子,比如打开淘宝,淘宝首页就是一级页面,点击首页中的一个分类【零食】,所弹出来的网页,就是二级页面。
查找URL规律
同样我们进行翻页操作,检查一下不同页面的URL:
第2页:https://www.ygdy8.net/html/gndy/dyzz/list_23_2.html
第3页:https://www.ygdy8.net/html/gndy/dyzz/list_23_3.html
由此我们可以判断第k页的URL地址为:https://www.ygdy8.net/html/gndy/dyzz/list_23_k.html
我们再右键点击【检查】,查看《攀登者》电影的名称以及详情超链接部分的HTML结构:
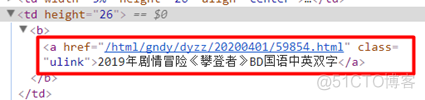
我们可以观察HTML页面结构,通过正则表达式,得到含有下载链接的二级页面。
在含有下载链接的二级页面中,同样先查看网页源代码,判断网页是否为静态。
打开网页源代码,ctrl+f搜索关键字【磁力】:
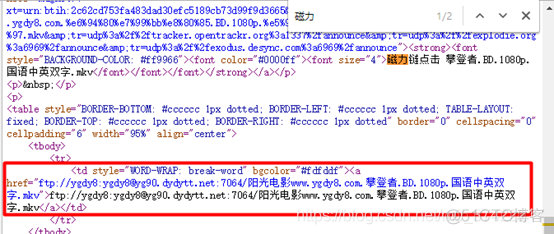
查询到了数据,二级网页也是静态的。
我们观察HTML页面结构,同样可以通过正则表达式得到电影下载链接。
正则表达式
打开一级页面的审查元素,我们发现每个电影名称和其详情链接均在一个<table>标签中:
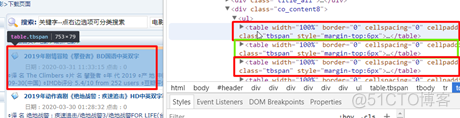
打开电影《攀登者》的<table>标签,仔细观察其结构和参数值:
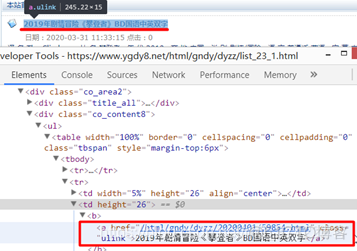
为了避免每个<table>标签内的结构不一致,我们在检查一下电影《绝地战警:疾速追击》的结构和参数值:
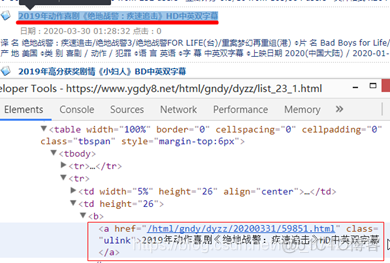
不错,两部电影的HTML结构和参数很一致,由此可以推断,我们要爬取的电影名称和其详情链接的HTLM结构基本一致。
注意,此时我们提取到的电影详情链接/html/gndy/dyzz/20200401/59854.html貌似没有加上域名,所以,在我们之后敲代码时,要在详情链接前加上域名https://www.ygdy8.net
这时,我们可以将其中一个电影<table>标签内的页面源代码copy下来,仔细观察规律,并在编辑器中编写正则表达式。
编写一级页面的正则表达式:
<table width="100%".*?<td height="26".*?<a href="(.*?)".*?>.*?(《.*?)</a>现在,为了提取电影下载链接,我们打开二级页面的页面源代码:
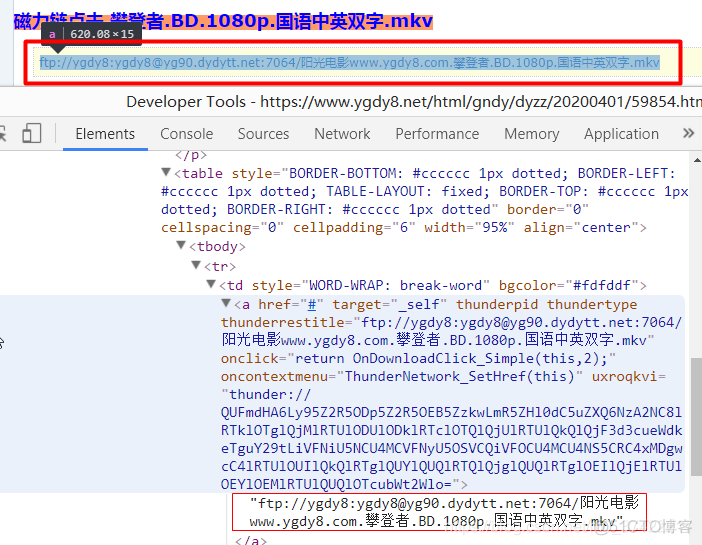
编写二级页面的正则表达式:
<td style="WORD-WRAP:.*?>.*?>(.*?)</a>我们先在mysql中先创建一个新的数据表filmheaven,方便之后要把爬取的数据存进去:

python代码:
import pymysqlfrom urllib import request, parse
import time
import re
import random
#导入自定义模块,里面放着包含各种User-Agent字符串的列表
from my_user_agent_list import user_agent
class FilmHeaven:
def __init__(self):
self.url = 'https://www.ygdy8.net/html/gndy/dyzz/list_23_{}.html'
self.user_agent = user_agent
self.page = 1
self.db = pymysql.connect(host = '127.0.0.1',
port = 3306,
user = 'root',
password = '19970928',
database = 'datacup',
charset = 'utf8')
self.cur = self.db.cursor()
#获取html页面
def get_page(self, url):
headers = {'User-Agent': random.choice(self.user_agent)}
#print(headers['User-Agent'])
req = request.Request(url, headers = headers)
res = request.urlopen(req)
html = res.read().decode('gbk', 'ignore')
return html
#解析提取数据(将1级和2级页面中所有数据一次性拿到)
def parse_page(self, html):
regex01 = '<table width="100%".*?<td height="26".*?<a href="(.*?)".*?>.*?(《.*?)</a>'
#先解析一级页面
pattern = re.compile(regex01, re.S)
#film_list = [('电影详情链接', '名称')]
film_list = pattern.findall(html)
data_list = []
for link, name in film_list:
film_name = name.strip()
film_link = 'https://www.ygdy8.net'+ link.strip()
download_link = self.parse_two_page(film_link)
data_list.append((film_name, download_link))
print('电影名称:', film_name)
#print('下载链接:', download_link)
sql = 'insert into filmheaven(name, download_link) \
values(%s, %s);'
try:
self.cur.executemany(sql, data_list)
self.db.commit()
except Exception as e:
self.db.rollback()
print('错误信息:', e)
def parse_two_page(self, url):
regex02 = '<td style="WORD-WRAP:.*?>.*?>(.*?)</a>'
html = self.get_page(url)
pattern = re.compile(regex02, re.S)
download_link = pattern.findall(html)[0]
return download_link
#通过电影链接后,获取二级页面的html,再获取下载链接
def main(self):
for page in range(1, 3):
url = self.url.format(page)
one_html = self.get_page(url)
self.parse_page(one_html)
print('第%d页爬取完成' % self.page)
self.page += 1
time.sleep(random.randint(1, 3))
self.cur.close()
self.db.close()
if __name__ == '__main__':
#获取开始的时间戳
start = time.time()
spider = FilmHeaven()
spider.main()
#获取结束的时间戳
end = time.time()
print('执行时间:%.2f' % (end-start))
备注:如果在decode()解码时遇到编码错误,就把utf-8/gbk/gb2312/gb18030都试一遍,如果都不行!!!注意!这时,就在decode()中加一个参数: ‘ignore’,直接忽略这个编码错误,也就是当做没有看见某些无法识别的字符,继续向后面执行。
控制台输出(由于输出较多,所以我截取了部分输出放在这里):
电影名称: 《攀登者》BD国语中英双字电影名称: 《绝地战警:疾速追击》HD中英双字幕
...
电影名称: 《星球大战9:天行者崛起》BD中英双字幕
电影名称: 《变身特工》BD国英双语双字
第1页爬取完成
电影名称: 《白头山》BD韩语中字
电影名称: 《南山的部长们》BD韩语中字
电影名称: 《哪吒之魔童降世》BD国语中英双字
...
电影名称: 《原钻》BD中英双字幕
第2页爬取完成
执行时间:109.34
查看mysql中filmheaven数据表的情况:
select * from filmheaven;mysql输出:
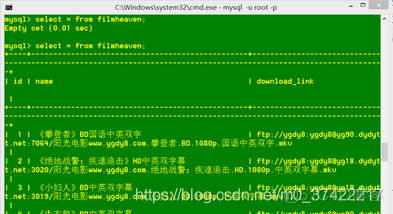
不错50条数据都被导入了。
我们再查询name字段中包含【日语中字】的记录:
select * from filmheaven where name like "%日语中字%";mysql输出:
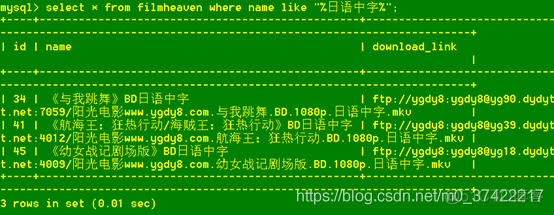
Perfect!