当年龟叔想把上面列出来的这些都干掉。在 “All Things Pythonic: The fate of reduce() in Python 3000”这篇文章中,他给出了自己要移除lambda、map、filter和reduce的原因。当然,这事儿最后没成功。只有reduce被挪到functools模块中去了。
lambda
lambda是匿名函数,也就是没有名字的函数。lambda的语法非常简单:
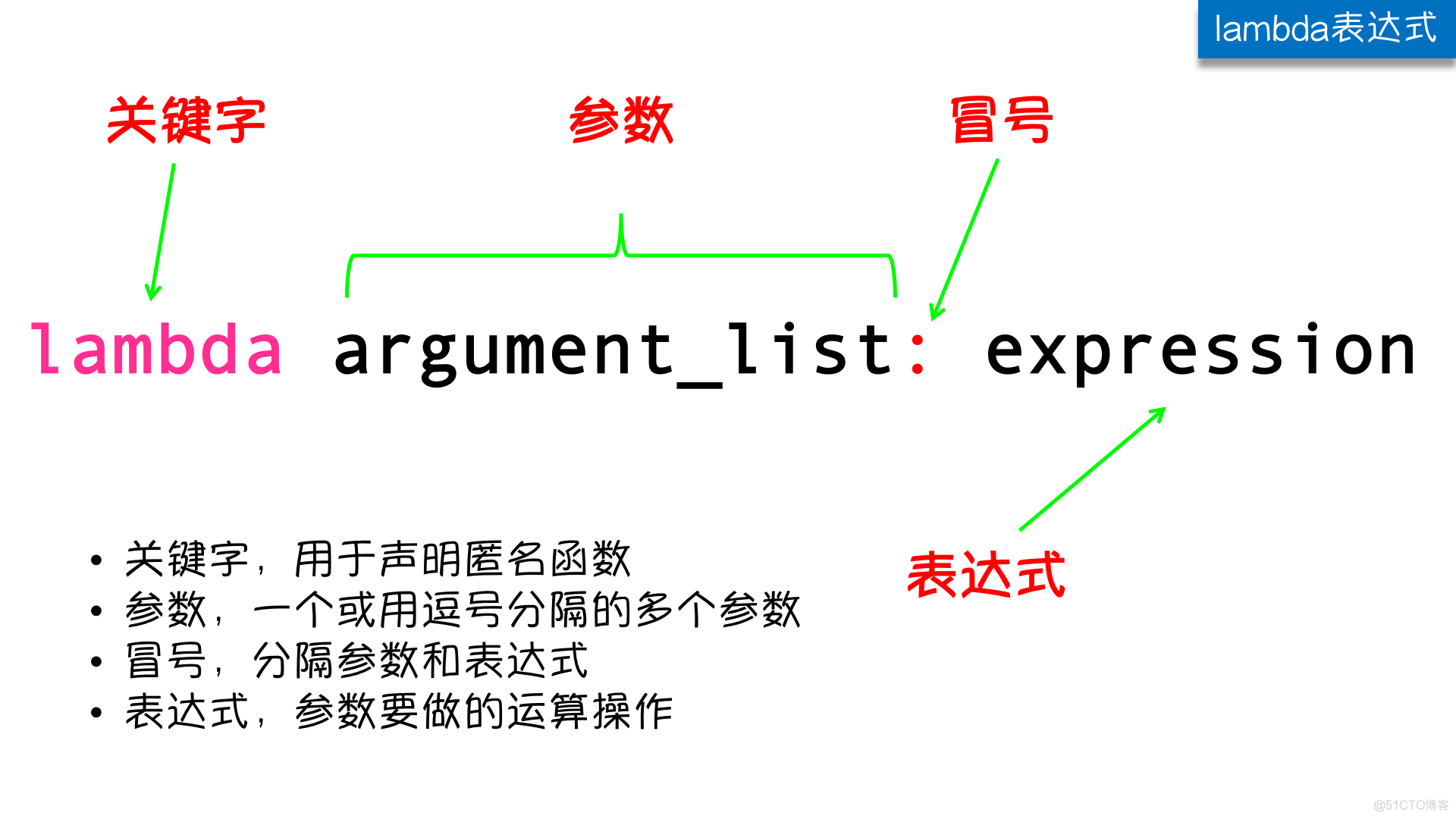
下面是一个lambda表达式的简单例子:
注意:我们可以把lambda表达式赋值给一个变量,然后通过这个变量来使用它。
>>> my_sum = lambda x, y: x+y>>> my_sum(1, 2)
3
下图是定义lambda表达式和定义一个普通函数的对比:
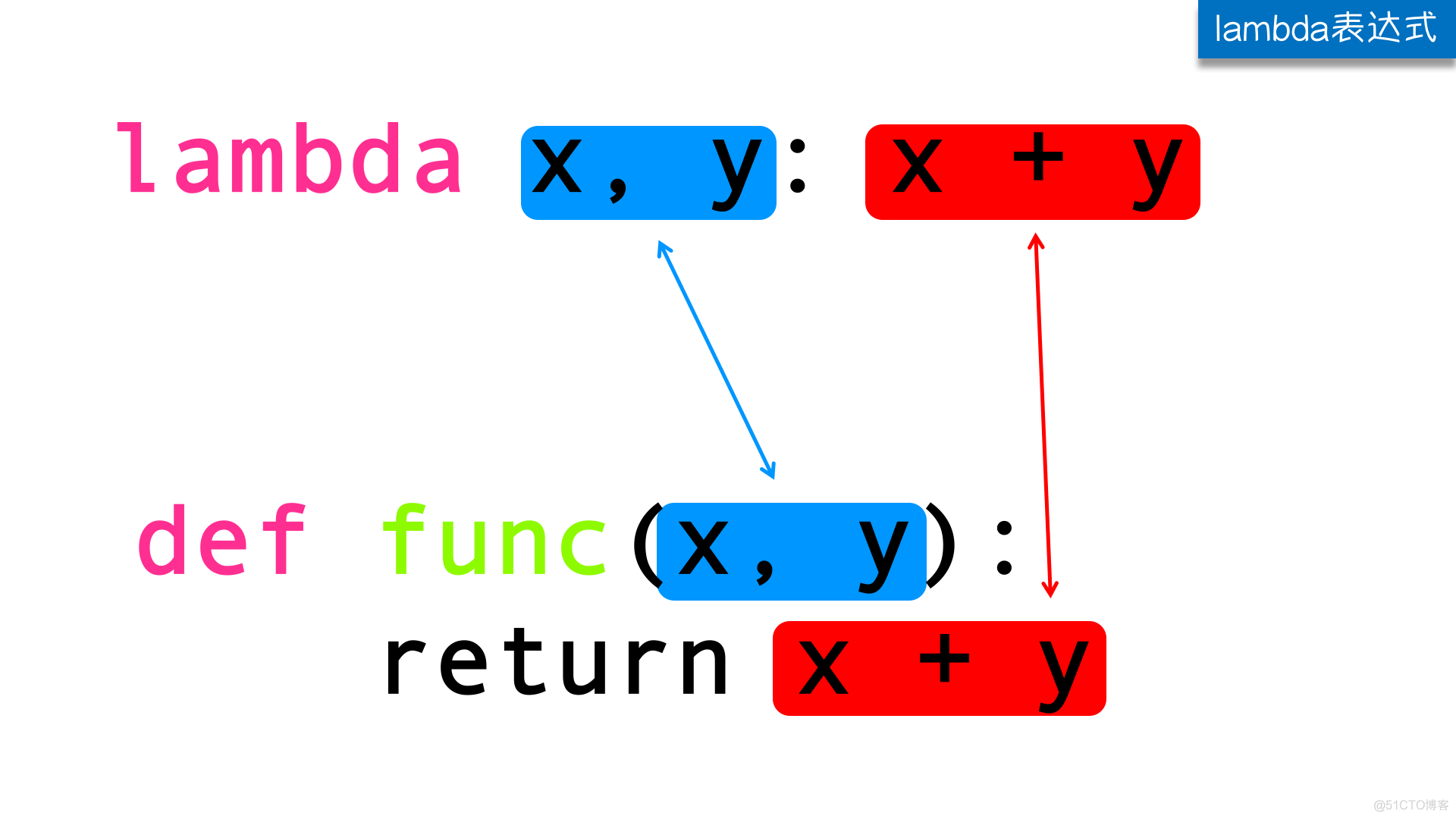
注意:
使用lambda表达式并不能提高代码的运行效率,它只能让你的代码看起来简洁一些。
map
map()接收两个参数func(函数)和seq(序列,例如list)。如下图:
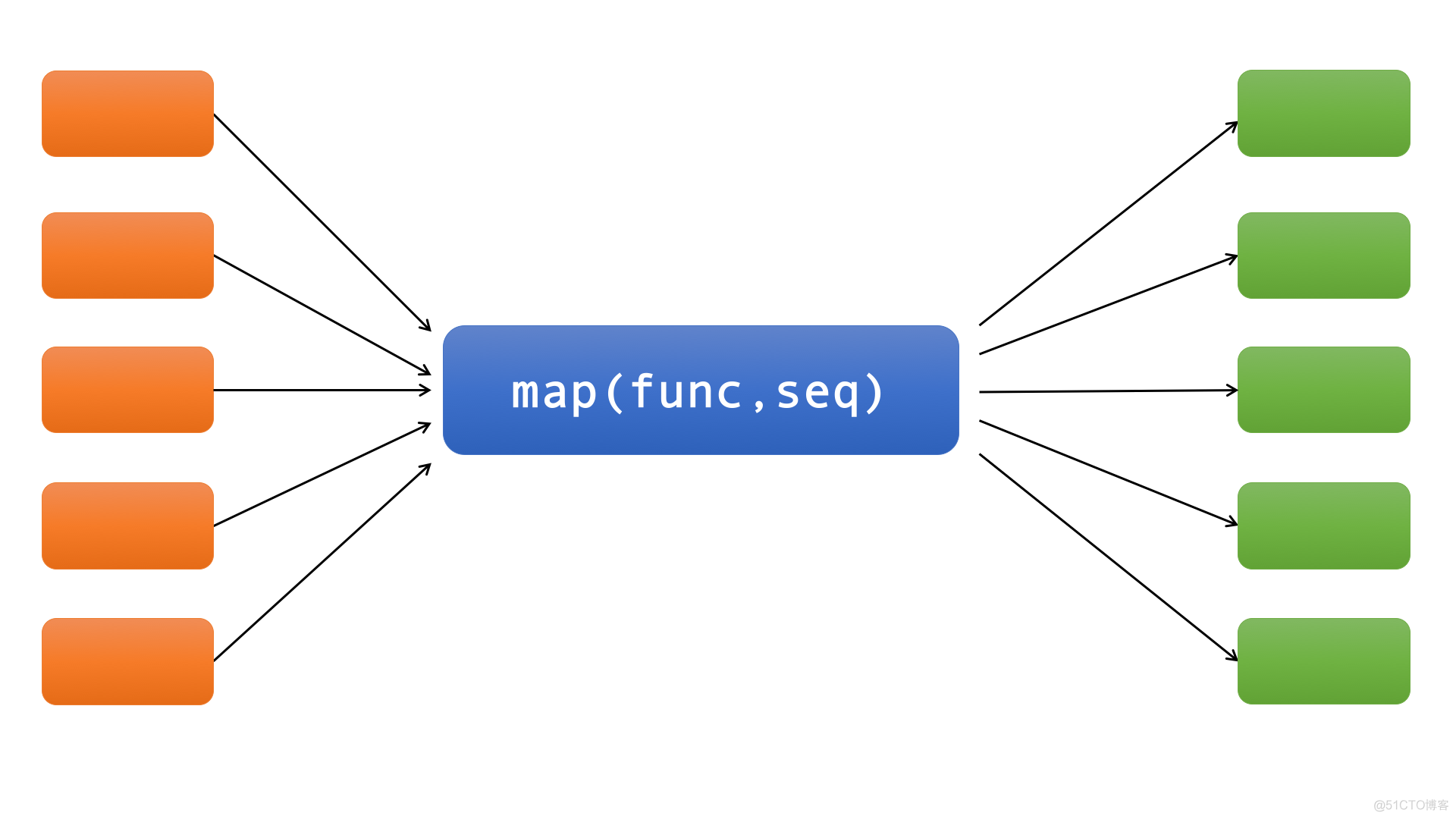
map()将函数func应用于序列seq中的所有元素。在Python3之前,map()返回一个列表,列表中的每个元素都是将列表或元组“seq”中的相应元素传入函数func返回的结果。Python 3中map()返回一个迭代器。
因为map()需要一个函数作为参数,所以可以搭配lambda表达式很方便的实现各种需求:
- 例子1–将一个列表里面 的每个数字都加100:
>>> list(map(lambda x:x+100, l))
[111, 122, 133, 144, 155]
- 例子2–
使用map就相当于使用了一个for循环,我们完全可以自己定义一个my_map函数:
def my_map(func, seq):result = []
for i in seq:
result.append(func(i))
return result
测试一下我们自己的my_map函数:
>>> def my_map(func, seq):... result = []
... for i in seq:
... result.append(func(i))
... return result
...
>>> l = [11, 22, 33, 44, 55]
>>> list(my_map(lambda x:x+100, l))
[111, 122, 133, 144, 155]
我们自定义的my_map函数的效果和内置的map函数一样。
当然在Python3中,map函数返回的是一个迭代器,所以我们也需要让我们的my_map函数返回一个迭代器:
def my_map(func, seq):for i in seq:
yield func(i)
测试一下:
>>> def my_map(func, seq):... for i in seq:
... yield func(i)
...
>>> l = [11, 22, 33, 44, 55]
>>> list(my_map(lambda x:x+100, l))
[111, 122, 133, 144, 155]
与我们自己定义的my_map函数相比,由于map是内置的因此它始终可用,并且始终以相同的方式工作。它也具有一些性能优势,通常会比手动编写的for循环更快。当然内置的map还有一些高级用法:
例如,可以给map函数传入多个序列参数,它将并行的序列作为不同参数传入函数:
拿pow(arg1, arg2)函数举例,
>>> pow(2, 10)1024
>>> pow(3, 11)
177147
>>> pow(4, 12)
16777216
>>> list(map(pow, [2, 3, 4], [10, 11, 12]))
[1024, 177147, 16777216]
pow(arg1, arg2)函数接收两个参数arg1和arg2,map(pow, [2, 3, 4], [10, 11, 12])就会并行从[2, 3, 4]和[10, 11, 12]中取出元素,传入到pow中。
还有一个例子:
>>> from operator import add>>> x = [1, 2, 3]
>>> y = [4, 5, 6]
>>> list(map(add, x, y))
[5, 7, 9]
调用map函数类似于列表推导式,但是列表推导式是对每个元素做表达式运算,而map对每个元素都会应用一次函数调用。也只有在map中使用内置函数时,才可能比列表推导式速度更快。
filter
filter函数和map函数一样也是接收两个参数func(函数)和seq(序列,如list),如下图:
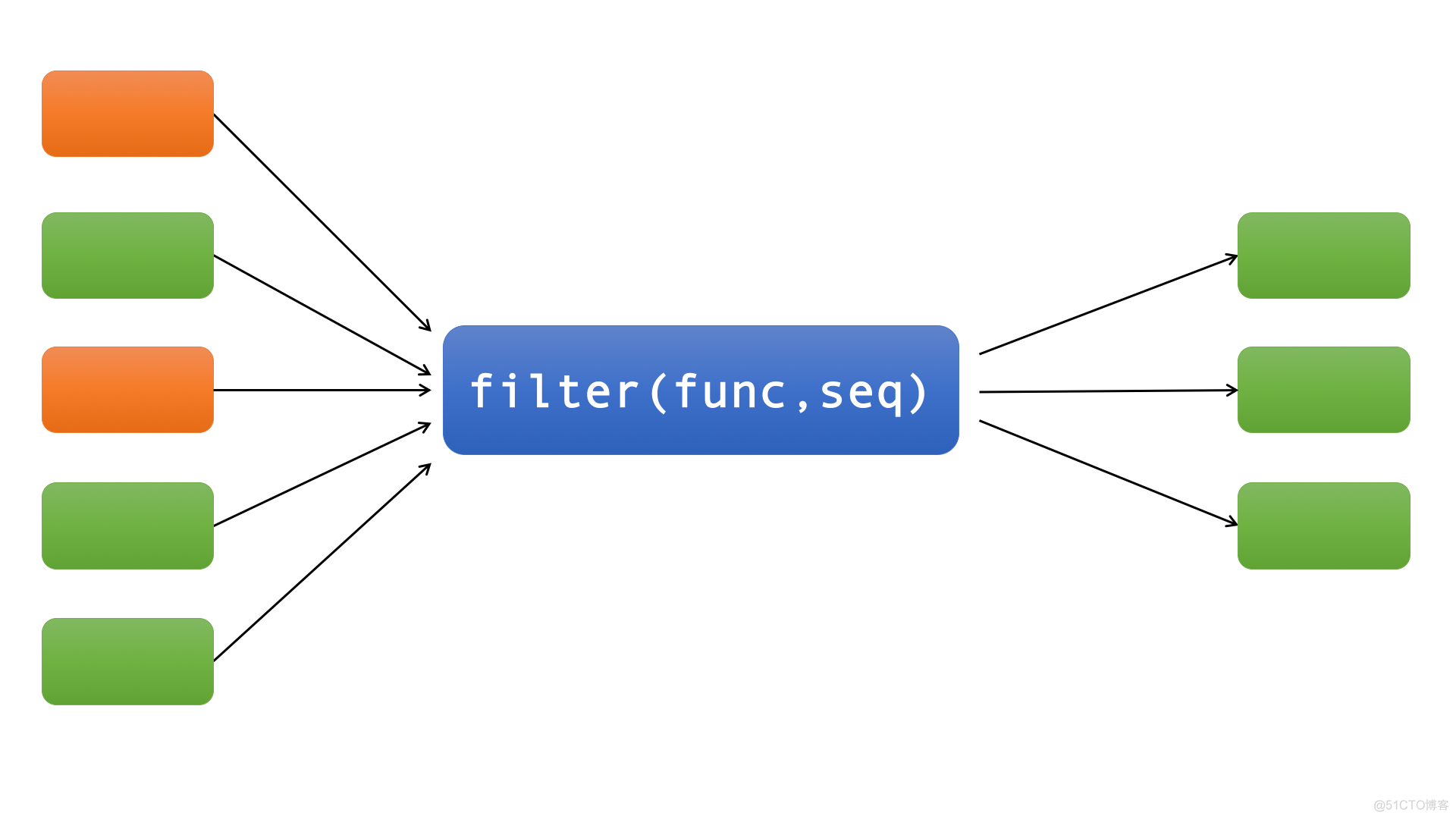
filter函数类似实现了一个过滤功能,它过滤序列中的所有元素,返回那些传入func后返回True的元素。也就是说filter函数的第一个参数func必须返回一个布尔值,即True或者False。
下面这个例子,是使用filter从一个列表中过滤出大于33的数:
>>> l = [30, 11, 77, 8, 25, 65, 4]>>> list(filter(lambda x: x>33, l))
[77, 65]
利用filter()还可以用来判断两个列表的交集:
>>> x = [1, 2, 3, 5, 6]>>> y = [2, 3, 4, 6, 7]
>>> list(filter(lambda a: a in y, x))
[2, 3, 6]
reduce
注意:Python3中reduce移到了functools模块中,你可以用过from functools import reduce来使用它。
reduce同样是接收两个参数:func(函数)和seq(序列,如list),如下图:
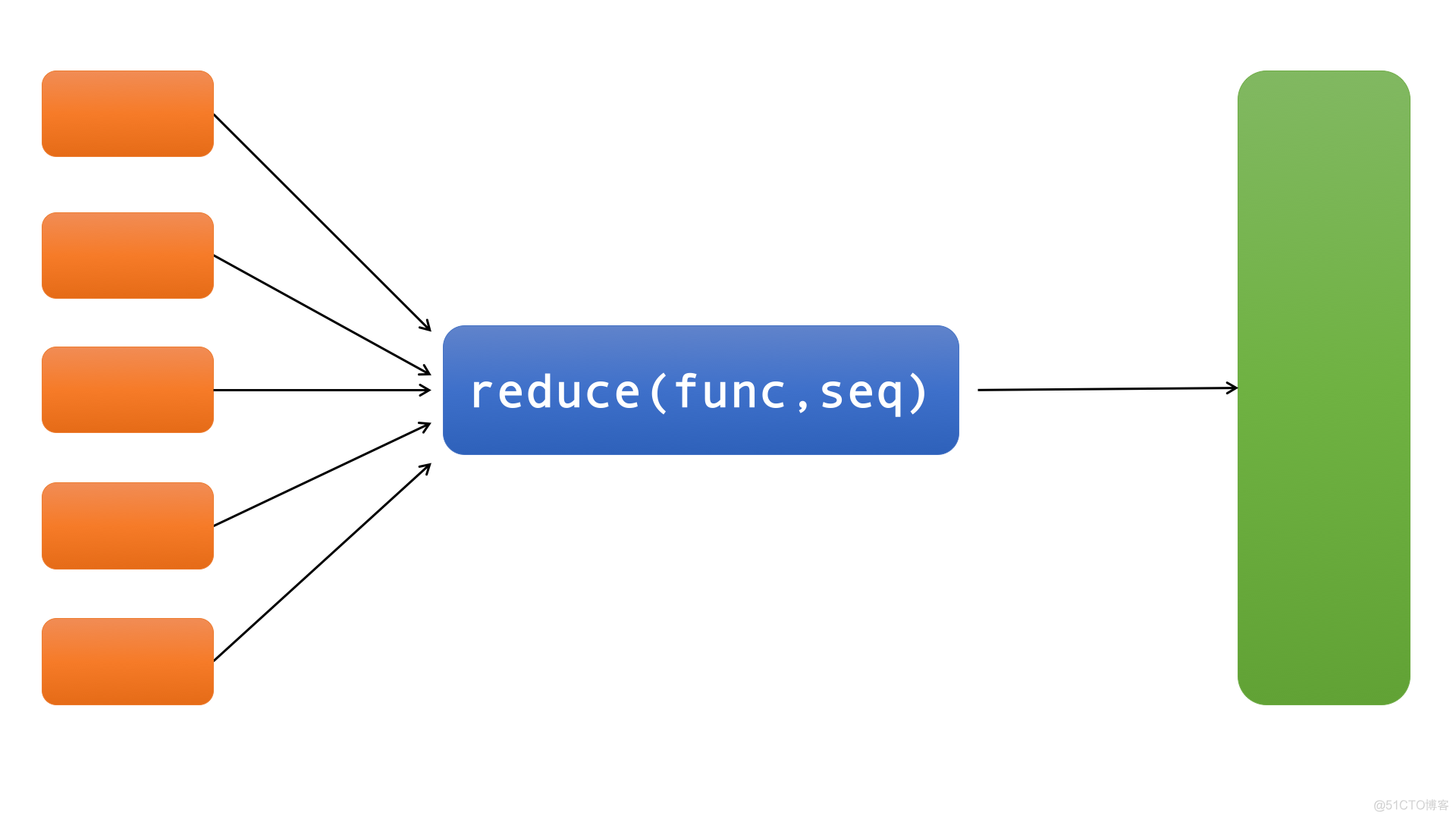
reduce最后返回的不是一个迭代器,它返回一个值。
reduce首先将序列中的前两个元素,传入func中,再将得到的结果和第三个元素一起传入func,…,这样一直计算到最后,得到一个值,把它作为reduce的结果返回。
原理类似于下图:

看一下运行结果:
>>> from functools import reduce>>> reduce(lambda x,y:x+y, [1, 2, 3, 4])
10
再来练习一下,使用reduce求1~100的和:
>>> from functools import reduce>>> reduce(lambda x,y:x+y, range(1, 101))
5050
三元运算
三元运算(三目运算)在Python中也叫条件表达式。三元运算的语法非常简单,主要是基于True/False的判断。如下图:

使用它就可以用简单的一行快速判断,而不再需要使用复杂的多行if语句。 大多数时候情况下使用三元运算能够让你的代码更清晰。
三元运算配合lambda表达式和reduce,求列表里面值最大的元素:
>>> from functools import reduce>>> l = [30, 11, 77, 8, 25, 65, 4]
>>> reduce(lambda x,y: x if x > y else y, l)
77
再来一个,三元运算配合lambda表达式和map的例子:
将一个列表里面的奇数加100:
>>> l = [30, 11, 77, 8, 25, 65, 4]>>> list(map(lambda x: x+100 if x%2 else x, l))
[30, 111, 177, 8, 125, 165, 4]
zip
zip函数接收一个或多个可迭代对象作为参数,最后返回一个迭代器:
>>> x = ["a", "b", "c"]>>> y = [1, 2, 3]
>>> a = list(zip(x, y)) # 合包
>>> a
[('a', 1), ('b', 2), ('c', 3)]
>>> b =list(zip(*a)) # 解包
>>> b
[('a', 'b', 'c'), (1, 2, 3)]
zip(x, y) 会生成一个可返回元组 (m, n) 的迭代器,其中m来自x,n来自y。 一旦其中某个序列迭代结束,迭代就宣告结束。 因此迭代长度跟参数中最短的那个序列长度一致。
>>> x = [1, 3, 5, 7, 9]>>> y = [2, 4, 6, 8]
>>> for m, n in zip(x, y):
... print(m, n)
...
1 2
3 4
5 6
7 8
如果上面不是你想要的效果,那么你还可以使用 itertools.zip_longest() 函数来代替这个例子中的zip。
>>> from itertools import zip_longest>>> x = [1, 3, 5, 7, 9]
>>> y = [2, 4, 6, 8]
>>> for m, n in zip_longest(x, y):
... print(m, n)
...
1 2
3 4
5 6
7 8
9 None
zip其他常见应用:
>>> keys = ["name", "age", "salary"]>>> values = ["Andy", 18, 50]
>>> d = dict(zip(keys, values))
>>> d
{'name': 'Andy', 'age': 18, 'salary': 50}