在注册表中分析无线访问热点 以管理员权限开启cmd,输入如下命令来列出每个网络显示出profile Guid对网络的描述、网络名和网关的MAC地址 reg query "HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows N
在注册表中分析无线访问热点
以管理员权限开启cmd,输入如下命令来列出每个网络显示出profile Guid对网络的描述、网络名和网关的MAC地址
reg query "HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\NetworkList\Signatures\Unmanaged" /s 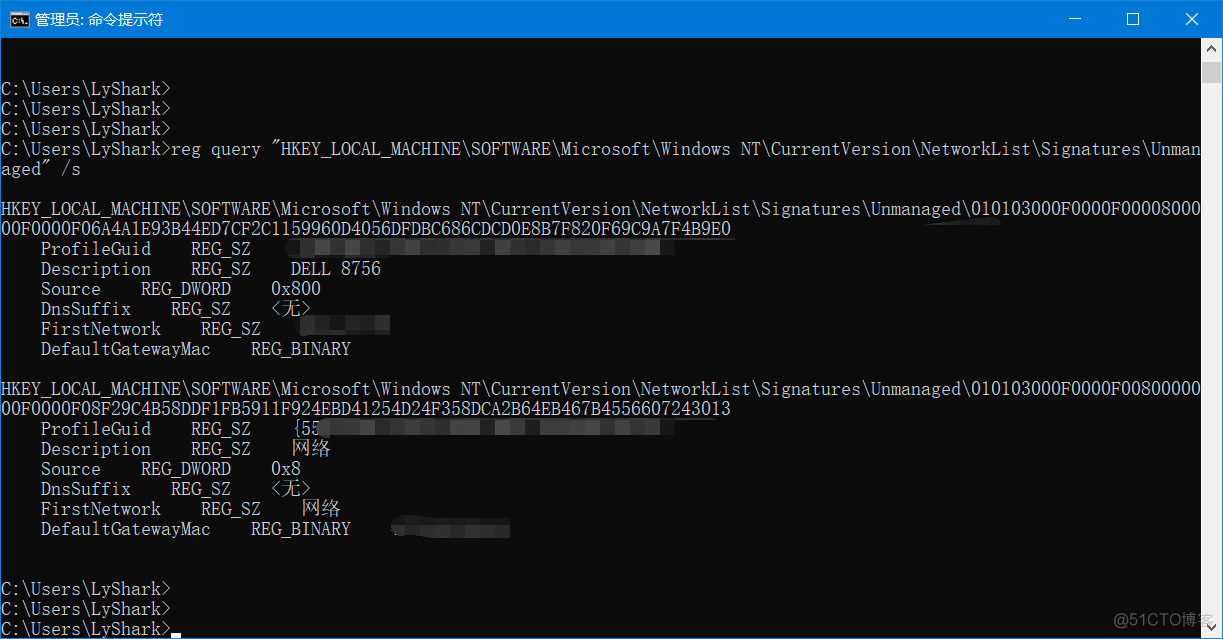
使用WinReg读取Windows注册表中的内容
连上注册表,使用OpenKey()函数打开相关的键,在循环中依次分析该键下存储的所有网络network profile,其中FirstNetwork网络名和DefaultGateway默认网关的Mac地址的键值打印出来。
#coding=utf-8from winreg import *
# 将REG_BINARY值转换成一个实际的Mac地址
def val2addr(val):
addr = ""
for ch in val:
addr += ("%02x " % ord(ch))
addr = addr.strip(" ").replace(" ", ":")[0:17]
return addr
# 打印网络相关信息
def printNets():
net = "/HKEY_LOCAL_MACHINE/SOFTWARE/Microsoft/Windows NT/CurrentVersion/NetworkList/Signatures/Unmanaged"
key = OpenKey(HKEY_LOCAL_MACHINE, net)
for i in range(100):
try:
guid = EnumKey(key, i)
netKey = OpenKey(key, str(guid))
(n, addr, t) = EnumValue(netKey, 5)
(n, name, t) = EnumValue(netKey, 4)
macAddr = val2addr(addr)
netName = name
print('[+] ' + netName + ' ' + macAddr)
CloseKey(netKey)
except:
break
if __name__ == "__main__":
printNets()
使用Mechanize把Mac地址传给Wigle
此处增加了对Wigle网站的访问并将Mac地址传递给Wigle来获取经纬度等物理地址信息。
#!/usr/bin/python#coding=utf-8
from _winreg import *
import mechanize
import urllib
import re
import urlparse
import os
import optparse
# 将REG_BINARY值转换成一个实际的Mac地址
def val2addr(val):
addr = ""
for ch in val:
addr += ("%02x " % ord(ch))
addr = addr.strip(" ").replace(" ", ":")[0:17]
return addr
# 打印网络相关信息
def printNets(username, password):
net = "SOFTWARE\Microsoft\Windows NT\CurrentVersion\NetworkList\Signatures\Unmanaged"
key = OpenKey(HKEY_LOCAL_MACHINE, net)
print "\n[*]Networks You have Joined."
for i in range(100):
try:
guid = EnumKey(key, i)
netKey = OpenKey(key, str(guid))
(n, addr, t) = EnumValue(netKey, 5)
(n, name, t) = EnumValue(netKey, 4)
macAddr = val2addr(addr)
netName = name
print '[+] ' + netName + ' ' + macAddr
wiglePrint(username, password, macAddr)
CloseKey(netKey)
except:
break
# 通过wigle查找Mac地址对应的经纬度
def wiglePrint(username, password, netid):
browser = mechanize.Browser()
browser.open('http://wigle.net')
reqData = urllib.urlencode({'credential_0': username, 'credential_1': password})
browser.open('https://wigle.net/gps/gps/main/login', reqData)
params = {}
params['netid'] = netid
reqParams = urllib.urlencode(params)
respURL = 'http://wigle.net/gps/gps/main/confirmquery/'
resp = browser.open(respURL, reqParams).read()
mapLat = 'N/A'
mapLon = 'N/A'
rLat = re.findall(r'maplat=.*\&', resp)
if rLat:
mapLat = rLat[0].split('&')[0].split('=')[1]
rLon = re.findall(r'maplon=.*\&', resp)
if rLon:
mapLon = rLon[0].split
print '[-] Lat: ' + mapLat + ', Lon: ' + mapLon
def main():
parser = optparse.OptionParser('usage %prog ' + '-u <wigle username> -p <wigle password>')
parser.add_option('-u', dest='username', type='string', help='specify wigle password')
parser.add_option('-p', dest='password', type='string', help='specify wigle username')
(options, args) = parser.parse_args()
username = options.username
password = options.password
if username == None or password == None:
print parser.usage
exit(0)
else:
printNets(username, password)
if __name__ == '__main__':
main()
使用OS模块寻找被删除的文件/文件夹:
Windows系统中的回收站是一个专门用来存放被删除文件的特殊文件夹。子目录中的字符串表示的是用户的SID,对应机器里一个唯一的用户账户。
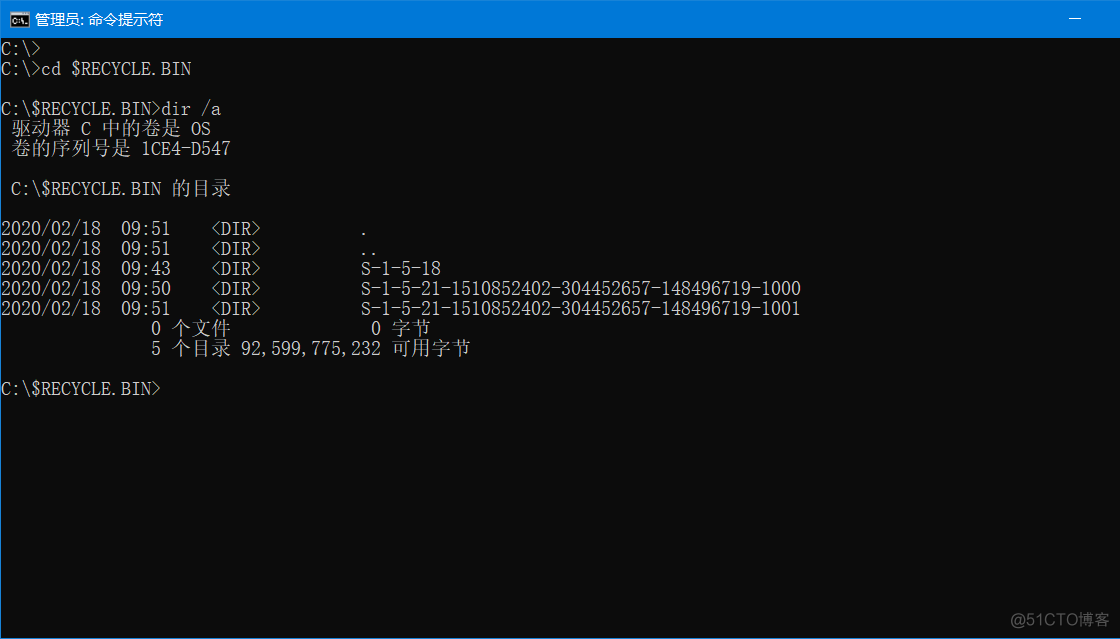
寻找被删除的文件/文件夹的函数:
#!/usr/bin/python#coding=utf-8
import os
# 逐一测试回收站的目录是否存在,并返回第一个找到的回收站目录
def returnDir():
dirs=['C:\\Recycler\\', 'C:\\Recycled\\', 'C:\\$Recycle.Bin\\']
for recycleDir in dirs:
if os.path.isdir(recycleDir):
return recycleDir
return None
用Python把SID和用户名关联起来:
可以使用Windows注册表把SID转换成一个准确的用户名。以管理员权限运行cmd并输入命令:
reg query "HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\ProfileList\S-1-5-21-2595130515-3345905091-1839164762-1000" /s#!/usr/bin/python#coding=utf-8
import os
import optparse
from _winreg import *
# 逐一测试回收站的目录是否存在,并返回第一个找到的回收站目录
def returnDir():
dirs=['C:\\Recycler\\', 'C:\\Recycled\\', 'C:\\$Recycle.Bin\\']
for recycleDir in dirs:
if os.path.isdir(recycleDir):
return recycleDir
return None
# 操作注册表来获取相应目录属主的用户名
def sid2user(sid):
try:
key = OpenKey(HKEY_LOCAL_MACHINE, "SOFTWARE\Microsoft\Windows NT\CurrentVersion\ProfileList" + '\\' + sid)
(value, type) = QueryValueEx(key, 'ProfileImagePath')
user = value.split('\\')[-1]
return user
except:
return sid
def findRecycled(recycleDir):
dirList = os.listdir(recycleDir)
for sid in dirList:
files = os.listdir(recycleDir + sid)
user = sid2user(sid)
print '\n[*] Listing Files For User: ' + str(user)
for file in files:
print '[+] Found File: ' + str(file)
def main():
recycledDir = returnDir()
findRecycled(recycledDir)
if __name__ == '__main__':
main()
使用PyPDF解析PDF文件中的元数据
pyPdf是管理PDF文档的第三方Python库,在Kali中是已经默认安装了的就不需要再去下载安装。
#!/usr/bin/python#coding=utf-8
import pyPdf
import optparse
from pyPdf import PdfFileReader
# 使用getDocumentInfo()函数提取PDF文档所有的元数据
def printMeta(fileName):
pdfFile = PdfFileReader(file(fileName, 'rb'))
docInfo = pdfFile.getDocumentInfo()
print "[*] PDF MeataData For: " + str(fileName)
for meraItem in docInfo:
print "[+] " + meraItem + ": " + docInfo[meraItem]
def main():
parser = optparse.OptionParser("[*]Usage: python pdfread.py -F <PDF file name>")
parser.add_option('-F', dest='fileName', type='string', help='specify PDF file name')
(options, args) = parser.parse_args()
fileName = options.fileName
if fileName == None:
print parser.usage
exit(0)
else:
printMeta(fileName)
if __name__ == '__main__':
main()
用BeautifulSoup下载图片
import urllib2from bs4 import BeautifulSoup as BS
from os.path import basename
from urlparse import urlsplit
# 通过BeautifulSoup查找URL中所有的img标签
def findImages(url):
print '[+] Finding images on ' + url
urlContent = urllib2.urlopen(url).read()
soup = BS(urlContent, 'lxml')
imgTags = soup.findAll('img')
return imgTags
# 通过img标签的src属性的值来获取图片URL下载图片
def downloadImage(imgTag):
try:
print '[+] Dowloading image...'
imgSrc = imgTag['src']
imgContent = urllib2.urlopen(imgSrc).read()
imgFileName = basename(urlsplit(imgSrc)[2])
imgFile = open(imgFileName, 'wb')
imgFile.write(imgContent)
imgFile.close()
return imgFileName
except:
return ' '
用Python的图像处理库读取图片中的Exif元数据
这里查看下载图片的元数据中是否含有Exif标签“GPSInfo”,若存在则输出存在信息。
#!/usr/bin/python#coding=utf-8
import optparse
from PIL import Image
from PIL.ExifTags import TAGS
import urllib2
from bs4 import BeautifulSoup as BS
from os.path import basename
from urlparse import urlsplit
# 通过BeautifulSoup查找URL中所有的img标签
def findImages(url):
print '[+] Finding images on ' + url
urlContent = urllib2.urlopen(url).read()
soup = BS(urlContent, 'lxml')
imgTags = soup.findAll('img')
return imgTags
# 通过img标签的src属性的值来获取图片URL下载图片
def downloadImage(imgTag):
try:
print '[+] Dowloading image...'
imgSrc = imgTag['src']
imgContent = urllib2.urlopen(imgSrc).read()
imgFileName = basename(urlsplit(imgSrc)[2])
imgFile = open(imgFileName, 'wb')
imgFile.write(imgContent)
imgFile.close()
return imgFileName
except:
return ' '
# 获取图像文件的元数据,并寻找是否存在Exif标签“GPSInfo”
def testForExif(imgFileName):
try:
exifData = {}
imgFile = Image.open(imgFileName)
info = imgFile._getexif()
if info:
for (tag, value) in info.items():
decoded = TAGS.get(tag, tag)
exifData[decoded] = value
exifGPS = exifData['GPSInfo']
if exifGPS:
print '[*] ' + imgFileName + ' contains GPS MetaData'
except:
pass
def main():
parser = optparse.OptionParser('[*]Usage: python Exif.py -u <target url>')
parser.add_option('-u', dest='url', type='string', help='specify url address')
(options, args) = parser.parse_args()
url = options.url
if url == None:
print parser.usage
exit(0)
else:
imgTags = findImages(url)
for imgTag in imgTags:
imgFileName = downloadImage(imgTag)
testForExif(imgFileName)
if __name__ == '__main__':
main()
使用Python和SQLite3自动查询Skype的数据库
#!/usr/bin/python#coding=utf-8
import sqlite3
import optparse
import os
# 连接main.db数据库,申请游标,执行SQL语句并返回结果
def printProfile(skypeDB):
conn = sqlite3.connect(skypeDB)
c = conn.cursor()
c.execute("SELECT fullname, skypename, city, country, datetime(profile_timestamp,'unixepoch') FROM Accounts;")
for row in c:
print '[*] -- Found Account --'
print '[+] User : '+str(row[0])
print '[+] Skype Username : '+str(row[1])
print '[+] Location : '+str(row[2])+','+str(row[3])
print '[+] Profile Date : '+str(row[4])
# 获取联系人的相关信息
def printContacts(skypeDB):
conn = sqlite3.connect(skypeDB)
c = conn.cursor()
c.execute("SELECT displayname, skypename, city, country, phone_mobile, birthday FROM Contacts;")
for row in c:
print '\n[*] -- Found Contact --'
print '[+] User : ' + str(row[0])
print '[+] Skype Username : ' + str(row[1])
if str(row[2]) != '' and str(row[2]) != 'None':
print '[+] Location : ' + str(row[2]) + ',' + str(row[3])
if str(row[4]) != 'None':
print '[+] Mobile Number : ' + str(row[4])
if str(row[5]) != 'None':
print '[+] Birthday : ' + str(row[5])
def printCallLog(skypeDB):
conn = sqlite3.connect(skypeDB)
c = conn.cursor()
c.execute("SELECT datetime(begin_timestamp,'unixepoch'), identity FROM calls, conversations WHERE calls.conv_dbid = conversations.id;")
print '\n[*] -- Found Calls --'
for row in c:
print '[+] Time: ' + str(row[0]) + ' | Partner: ' + str(row[1])
def printMessages(skypeDB):
conn = sqlite3.connect(skypeDB)
c = conn.cursor()
c.execute("SELECT datetime(timestamp,'unixepoch'), dialog_partner, author, body_xml FROM Messages;")
print '\n[*] -- Found Messages --'
for row in c:
try:
if 'partlist' not in str(row[3]):
if str(row[1]) != str(row[2]):
msgDirection = 'To ' + str(row[1]) + ': '
else:
msgDirection = 'From ' + str(row[2]) + ' : '
print 'Time: ' + str(row[0]) + ' ' + msgDirection + str(row[3])
except:
pass
def main():
parser = optparse.OptionParser("[*]Usage: python skype.py -p <skype profile path> ")
parser.add_option('-p', dest='pathName', type='string', help='specify skype profile path')
(options, args) = parser.parse_args()
pathName = options.pathName
if pathName == None:
print parser.usage
exit(0)
elif os.path.isdir(pathName) == False:
print '[!] Path Does Not Exist: ' + pathName
exit(0)
else:
skypeDB = os.path.join(pathName, 'main.db')
if os.path.isfile(skypeDB):
printProfile(skypeDB)
printContacts(skypeDB)
printCallLog(skypeDB)
printMessages(skypeDB)
else:
print '[!] Skype Database ' + 'does not exist: ' + skpeDB
if __name__ == '__main__':
main()
用Python解析火狐浏览器的SQLite3数据库
主要关注文件:cookie.sqlite、places.sqlite、downloads.sqlite
#!/usr/bin/python#coding=utf-8
import re
import optparse
import os
import sqlite3
# 解析打印downloads.sqlite文件的内容,输出浏览器下载的相关信息
def printDownloads(downloadDB):
conn = sqlite3.connect(downloadDB)
c = conn.cursor()
c.execute('SELECT name, source, datetime(endTime/1000000, \'unixepoch\') FROM moz_downloads;')
print '\n[*] --- Files Downloaded --- '
for row in c:
print '[+] File: ' + str(row[0]) + ' from source: ' + str(row[1]) + ' at: ' + str(row[2])
# 解析打印cookies.sqlite文件的内容,输出cookie相关信息
def printCookies(cookiesDB):
try:
conn = sqlite3.connect(cookiesDB)
c = conn.cursor()
c.execute('SELECT host, name, value FROM moz_cookies')
print '\n[*] -- Found Cookies --'
for row in c:
host = str(row[0])
name = str(row[1])
value = str(row[2])
print '[+] Host: ' + host + ', Cookie: ' + name + ', Value: ' + value
except Exception, e:
if 'encrypted' in str(e):
print '\n[*] Error reading your cookies database.'
print '[*] Upgrade your Python-Sqlite3 Library'
# 解析打印places.sqlite文件的内容,输出历史记录
def printHistory(placesDB):
try:
conn = sqlite3.connect(placesDB)
c = conn.cursor()
c.execute("select url, datetime(visit_date/1000000, 'unixepoch') from moz_places, moz_historyvisits where visit_count > 0 and moz_places.id==moz_historyvisits.place_id;")
print '\n[*] -- Found History --'
for row in c:
url = str(row[0])
date = str(row[1])
print '[+] ' + date + ' - Visited: ' + url
except Exception, e:
if 'encrypted' in str(e):
print '\n[*] Error reading your places database.'
print '[*] Upgrade your Python-Sqlite3 Library'
exit(0)
# 解析打印places.sqlite文件的内容,输出百度的搜索记录
def printBaidu(placesDB):
conn = sqlite3.connect(placesDB)
c = conn.cursor()
c.execute("select url, datetime(visit_date/1000000, 'unixepoch') from moz_places, moz_historyvisits where visit_count > 0 and moz_places.id==moz_historyvisits.place_id;")
print '\n[*] -- Found Baidu --'
for row in c:
url = str(row[0])
date = str(row[1])
if 'baidu' in url.lower():
r = re.findall(r'wd=.*?\&', url)
if r:
search=r[0].split('&')[0]
search=search.replace('wd=', '').replace('+', ' ')
print '[+] '+date+' - Searched For: ' + search
def main():
parser = optparse.OptionParser("[*]Usage: firefoxParse.py -p <firefox profile path> ")
parser.add_option('-p', dest='pathName', type='string', help='specify skype profile path')
(options, args) = parser.parse_args()
pathName = options.pathName
if pathName == None:
print parser.usage
exit(0)
elif os.path.isdir(pathName) == False:
print '[!] Path Does Not Exist: ' + pathName
exit(0)
else:
downloadDB = os.path.join(pathName, 'downloads.sqlite')
if os.path.isfile(downloadDB):
printDownloads(downloadDB)
else:
print '[!] Downloads Db does not exist: '+downloadDB
cookiesDB = os.path.join(pathName, 'cookies.sqlite')
if os.path.isfile(cookiesDB):
pass
printCookies(cookiesDB)
else:
print '[!] Cookies Db does not exist:' + cookiesDB
placesDB = os.path.join(pathName, 'places.sqlite')
if os.path.isfile(placesDB):
printHistory(placesDB)
printBaidu(placesDB)
else:
print '[!] PlacesDb does not exist: ' + placesDB
if __name__ == '__main__':
main()
用python调查iTunes手机备份
#!/usr/bin/python#coding=utf-8
import os
import sqlite3
import optparse
def isMessageTable(iphoneDB):
try:
conn = sqlite3.connect(iphoneDB)
c = conn.cursor()
c.execute('SELECT tbl_name FROM sqlite_master WHERE type==\"table\";')
for row in c:
if 'message' in str(row):
return True
except:
return False
def printMessage(msgDB):
try:
conn = sqlite3.connect(msgDB)
c = conn.cursor()
c.execute('select datetime(date,\'unixepoch\'), address, text from message WHERE address>0;')
for row in c:
date = str(row[0])
addr = str(row[1])
text = row[2]
print '\n[+] Date: '+date+', Addr: '+addr + ' Message: ' + text
except:
pass
def main():
parser = optparse.OptionParser("[*]Usage: python iphoneParse.py -p <iPhone Backup Directory> ")
parser.add_option('-p', dest='pathName', type='string',help='specify skype profile path')
(options, args) = parser.parse_args()
pathName = options.pathName
if pathName == None:
print parser.usage
exit(0)
else:
dirList = os.listdir(pathName)
for fileName in dirList:
iphoneDB = os.path.join(pathName, fileName)
if isMessageTable(iphoneDB):
try:
print '\n[*] --- Found Messages ---'
printMessage(iphoneDB)
except:
pass
if __name__ == '__main__':
main()
版权声明:本博客文章与代码均为学习时整理的笔记,文章 [均为原创] 作品,转载请 [添加出处] ,您添加出处是我创作的动力!