词云,作为最近几年比较火的可视化项目之一,逐渐发挥着巨大的作用,使原本生硬的文字赋予了活力,通过词云借助颜色和size可以更直观的看到哪些词条出现频率高,哪些词
词云,作为最近几年比较火的可视化项目之一,逐渐发挥着巨大的作用,使原本生硬的文字赋予了活力,通过词云借助颜色和size可以更直观的看到哪些词条出现频率高,哪些词条出现频率低,从而为原本生硬的文字赋予了活力,使其在可视化领域占有一席之地。
1. 所需资源
传统python自带库已经无法满足我们的数据可视化需求,因此,需要借助其他库,主要有:
第三方库:
jieba :用于分词;
wordcloud : 生成词语;
opencv-python: 生成词云图片;
逐个安装方式
pip install jiebapip install wordcloud
pip install opencv-python
批量安装
pip install jieba wordcloud opencv-python2. 导入三方库
少扯度,不画饼,开门见山,直接看码,先从开头谈起,引入可能需要的三方库:
import requestsimport json
import jieba # pip install jieba
from wordcloud import WordCloud # pip install wordcloud
import cv2 #pip install opencv-python
3. 获取原始数据
通过对微博热搜界面进行抓包,拿到url,post data ,header,对接口进行请求操作,获取response,截取我们所需要的信息字段;
url = "https://m.weibo.cn/api/container/getIndex"querystring = {"containerid": "231583", "page_type": "searchall"}
headers = {
'sec-ch-ua': "\" Not A;Brand\";v=\"99\", \"Chromium\";v=\"100\", \"Google Chrome\";v=\"100\"",
'x-xsrf-token': "99c11b",
'sec-ch-ua-mobile': "?0",
'user-agent': "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36",
'accept': "application/json, text/plain, */*",
'mweibo-pwa': "1",
'x-requested-with': "XMLHttpRequest",
'sec-ch-ua-platform': "\"Windows\"",
'sec-fetch-site': "same-origin",
'sec-fetch-mode': "cors",
'sec-fetch-dest': "empty",
}
response = requests.request("GET", url, headers=headers, params=querystring)
data = json.loads(response.content)
data_list = []
res = data['data']['cards'][0]['group']
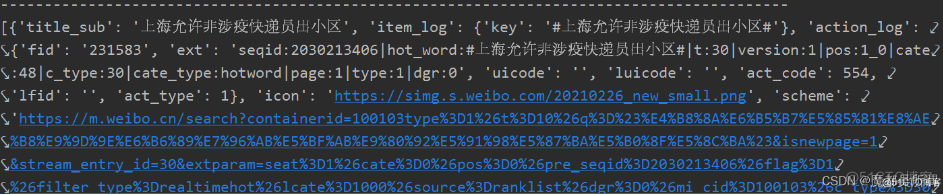
res:就是获取当前的微博热搜接口数据,该数据比较杂,还不是我们的最终数据;
数据展示:
4. 保存至本地
数据保存至本地,有多种形式,比如:数据库,文本,图片等,我们这里简单一点仅仅是保存到txt文档中,操作方便,也很少依赖其他的知识,便于学习;
with open('resou.txt', 'w') as f:for index, i in enumerate(res):
if i['title_sub'] != '微博热搜榜':
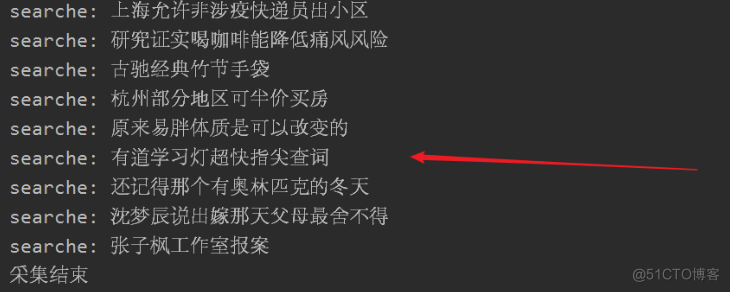
print('searche:',i['title_sub'])
data_list.append(i['title_sub'])
f.write(i['title_sub'] + '\n')
print('采集结束')
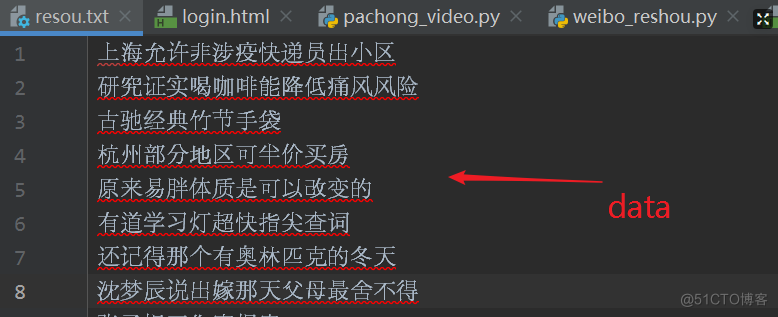
i['title_sub']:就是每个热搜的标题,我们获取到这个数据的同时,将其保存至resou.txt
resou.txt:
5. 准备词汇
生成词云之前,先储备词汇,哪些词汇是我们要在词云中展示的,哪些词汇不要在词云中展示;
停用词:都是不在词云展示的字段,我们需要对其剔除,将所有字段存储成一个字符串;
word_list = jieba.cut(''.join(data_list))
result = ' '.join(word_list)
print(result)
# 设置停用词
stop_words = ['你', '我', '的', '了', '们']
ciyun = ''
# 字体
font = r'C:\\Windows\\fonts\\msyh.ttf'
for i in result:
if i not in stop_words:
ciyun += i
6. 生成词云
生成词云需要先给一个图片,作为参数,来实现词云图形,我这边给的是一个python的logo图标,放在同级目录下pythonlogo.png,其他的都在代码中做了详细的备注,

img = cv2.imread('pythonlogo.png')
# 设置参数,创建WordCloud对象
wc = WordCloud(
scale=4, #scale=4,数值越大,图片分辨率越高,字迹越清晰。
font_path=font, # 中文
background_color='white', # 设置背景颜色为白色
stopwords=stop_words, # 设置禁用词,在生成的词云中不会出现set集合中的词
mask=img
)
# 根据文本数据生成词云
wc.generate(ciyun)
# 保存词云文件
wc.to_file('img.jpg')
7. 词云展示

8. 文件布局
9.全部代码
import requestsimport json
import jieba # pip install jieba
from wordcloud import WordCloud # pip install wordcloud
import cv2 #pip install opencv-python
url = "https://m.weibo.cn/api/container/getIndex"
querystring = {"containerid": "231583", "page_type": "searchall"}
headers = {
'sec-ch-ua': "\" Not A;Brand\";v=\"99\", \"Chromium\";v=\"100\", \"Google Chrome\";v=\"100\"",
'x-xsrf-token': "99c11b",
'sec-ch-ua-mobile': "?0",
'user-agent': "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36",
'accept': "application/json, text/plain, */*",
'mweibo-pwa': "1",
'x-requested-with': "XMLHttpRequest",
'sec-ch-ua-platform': "\"Windows\"",
'sec-fetch-site': "same-origin",
'sec-fetch-mode': "cors",
'sec-fetch-dest': "empty",
}
response = requests.request("GET", url, headers=headers, params=querystring)
data = json.loads(response.content)
data_list = []
res = data['data']['cards'][0]['group']
with open('resou.txt', 'w') as f:
for index, i in enumerate(res):
if i['title_sub'] != '微博热搜榜':
print('searche:',i['title_sub'])
data_list.append(i['title_sub'])
f.write(i['title_sub'] + '\n')
print('采集结束')
# 切割分词
word_list = jieba.cut(''.join(data_list))
result = ' '.join(word_list)
print(result)
# 设置停用词
stop_words = ['你', '我', '的', '了', '们']
ciyun = ''
# 字体
font = r'C:\\Windows\\fonts\\msyh.ttf'
for i in result:
if i not in stop_words:
ciyun += i
# 读取图片
img = cv2.imread('pythonlogo.png')
# 设置参数,创建WordCloud对象
wc = WordCloud(
scale=4, #scale=4,数值越大,图片分辨率越高,字迹越清晰。
font_path=font, # 中文
background_color='white', # 设置背景颜色为白色
stopwords=stop_words, # 设置禁用词,在生成的词云中不会出现set集合中的词
mask=img
)
# 根据文本数据生成词云
wc.generate(ciyun)
# 保存词云文件
wc.to_file('img.jpg')
over~~~