本次要抓取的目标网站为【整形医生数据】,其中用到的 queue 模块,需要在预备知识篇进行学习。 目标站点数据源分析 目标地址为:https://www.huaroo.net/d/pg_1/,爬取数据区域如下图所示
本次要抓取的目标网站为【整形医生数据】,其中用到的 queue 模块,需要在预备知识篇进行学习。
目标站点数据源分析
目标地址为:https://www.huaroo.net/d/pg_1/,爬取数据区域如下图所示:
 整理目标数据格式为:
整理目标数据格式为:
分页规则如下:
https://www.huaroo.net/d/pg_1/ https://www.huaroo.net/d/pg_2/其中 pg_页码 为页码跳转规则,可以通过代码爬取获取,也可以直接手动输入。
测试过程中发现网页响应速度有点慢,但是没有反爬措施,顾将请求等待时间设置的长一些即可实现。
编码时间
下述编码中使用到了 queue 模块,即队列机制,不过并没有使用生产者与消费者模型,所谓的生产者直接使用一个循环进行了生成。
线程部分开启了 2 个线程,通过判断队列是否为空,在进行后续的数据请求工作。
每次获取数据完毕之后,都使用 q.task_done() 告知任务完成。
格式化数据使用 lxml 模块进行提取。
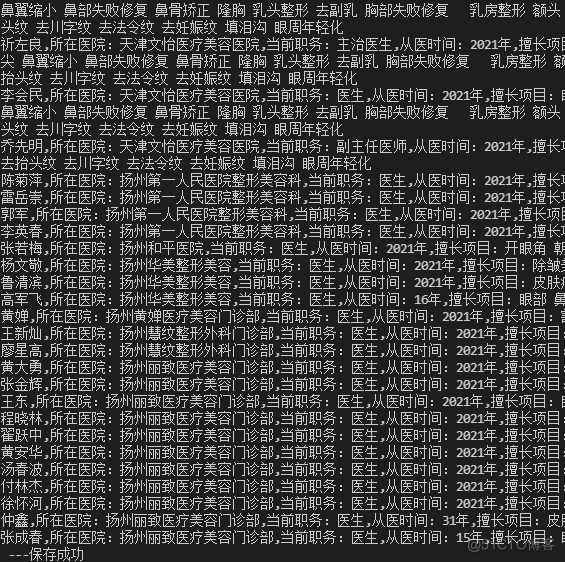
import requests import threading from queue import Queue from lxml import etree import time import random # 初始化一个队列 q = Queue(maxsize=0) # 批量添加数据 for page in range(1, 502): q.put('https://www.huaroo.net/d/pg_{}/'.format(page)) # 获取头文件,其中的 uas 自行设置 def get_headers(): uas = [ "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)", "Mozilla/5.0 (compatible; Baiduspider-render/2.0; +http://www.baidu.com/search/spider.html)" ] ua = random.choice(uas) headers = { "user-agent": ua, "referer": "https://www.baidu.com" } return headers # 格式化数据 def format(text): element = etree.HTML(text) # print(element) article_list = element.xpath('//div[contains(@class,"article_list")]') # print(article_list) wait_save_str = "" # 通过 xpath 提取数据 for article in article_list: title = article.xpath("./a/div/div[@class='article_title']/text()")[0].strip() hospital = article.xpath("./a/div/div[@class='hospital_list_content mt10 oh']/div[1]/text()")[0].strip() duties = article.xpath("./a/div/div[@class='hospital_list_content mt10 oh']/div[2]/text()")[0].strip() practice = article.xpath("./a/div/div[@class='hospital_list_content mt10 oh']/div[3]/text()")[0].strip() project = article.xpath("./a/div/div[@class='hospital_list_content mt10 oh']/div[4]/text()")[0].strip() wait_save_str += f"{title},{hospital},{duties},{practice},{project}\n" save(wait_save_str) # 储存数据 def save(wait_save_str): with open('./医美.csv', 'a+', encoding='utf-8') as f: f.write(wait_save_str) print(wait_save_str, "---保存成功") # 爬虫请求与解析入口 def run(): while q.qsize() > 0: url = q.get() # print(url) q.task_done() res = requests.get(url=url, headers=get_headers(), timeout=10) format(res.text) l = [] for i in range(2): t = threading.Thread(target=run) l.append(t) t.start() for p in l: p.join() print("多线程执行完毕") q.join() print("所有线程运行完毕")代码运行之后,显示如下结果。
收藏时间
==来都来了,不发个评论,点个赞,收个藏吗?==
今天是持续写作的第 <font color=red>208</font> / 365 天。可以<font color=#04a9f4>关注</font>我,<font color=#04a9f4>点赞</font>我、<font color=#04a9f4>评论</font>我、<font color=#04a9f4>收藏</font>我啦。