本章是系列文章的第七章,终于来到了鼎鼎大名的SSA,SSA是编译器领域最伟大的发明之一,也是影响最广的发明。
7.1 控制流图回顾本文中的所有内容来自学习DCC888的学习笔记或者自己理解的整理,如需转载请注明出处。周荣华@燧原科技
对下面的c代码保存成7.1.cc:
1 int max(int a, int b) { 2 int ans = a; 3 if (b > a) { 4 ans = b; 5 } 6 return ans; 7 }
直接用clang生成bc → dot → svg,最终svg的结果如下:
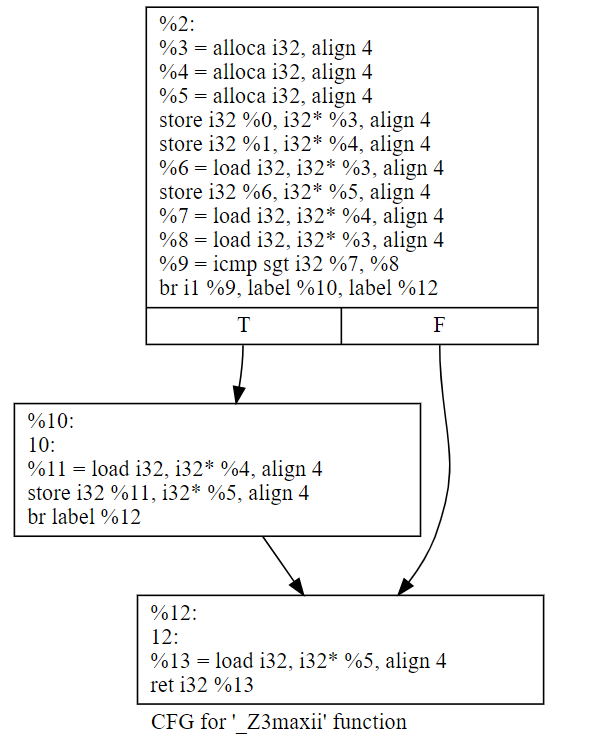
如果经过一轮opt的优化“opt -mem2reg 7.1.ll -o 7.1.1.bc”之后的结果,就变成了这样(注意,需要删除ll里面的optnone属性,否则opt不会生效):
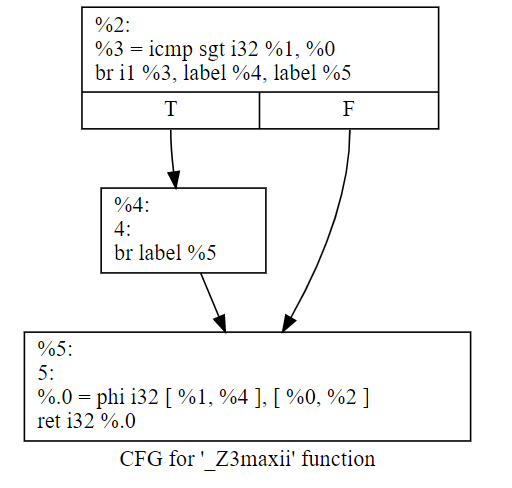
除了我们本来准备跑的mem2reg的pass外,优化前后最后一个BB里是不是还多了一个phi函数?
7.1.1 静态单赋值范式(SSA Form)
静态单赋值,字面意思是对静态的变量只有一次赋值点。这是现在所有编译器都广泛使用的属性,也是编译器历史上最具有突破性意义的属性,简化了各种分析和优化的过程。
1991年SSA的奠基论文被引用打到2800+次,这还是截止2019年的数据,这个引用次数每年还在增加。
几乎每本讲编译器的书都会说到SSA。google学术上用SSA能搜到5000+个结果。
每年来自全世界的编译器专家,都会在SSA研讨会上庆祝一次SSA的诞生。
和静态单赋值对应的是动态单赋值,也就是程序执行过程中,每个变量只能赋值一次。和动态单赋值不同,静态单赋值,只要求每个变量的赋值程序点只能有一个,这个程序点可以出现在循环内部(这意味着动态执行过程中这个程序点会多次执行)。
7.2 从SSA来到SSA去 7.2.1 将线性代码转换成SSA Form如果一个程序没有任何分叉,则称这个程序是线性代码。
例如下面的代码:
1 double baskhara(double a, double b, double c) { 2 double delta = b * b - 4 * a * c; 3 double sqrDelta = sqrt(delta); 4 double root = (b + sqrDelta) / 2 * a; 5 return root; 6 }
其实它本身就是符合SSA定义的(每个变量只定义一次),但一般经过opt转换之后的代码是这样:
1 define double @baskhara(double %a, double %b, double %c) { 2 %1 = fmul double %b, %b 3 %2 = fmul double 4.000000e+00, %a 4 %3 = fmul double %2, %c 5 %4 = fsub double %1, %3 6 %5 = call double @sqrt(double %4) 7 %6 = fadd double %b, %5 8 %7 = fdiv double %6, 2.000000e+00 9 %8 = fmul double %7, %a 10 ret double %8 11 }
线性代码转换成SSA范式的的算法比较直接:
1 for each variable a: 2 Count[a] = 0 3 Stack[a] = [0] 4 rename_basic_block(B) = 5 for each instruction S in block B: 6 for each use of a variable x in S: 7 i = top(Stack[x]) 8 replace the use of x with xi 9 for each variable a that S defines 10 count[a] = Count[a] + 1 11 i = Count[a] 12 push i onto Stack[a] 13 replace definition of a with ai
例如,下面的c代码:
1 a = x + y; 2 b = a - 1; 3 a = y + b; 4 b = 4 * x; 5 a = a + b;
经过SSA转换之后会变成这样:
1 a1 = x0 + y0; 2 b1 = a1 - 1; 3 a2 = y0 + b1; 4 b2 = 4 * x0; 5 a3 = a2 + b2;
7.2.2 Phi函数
前面说了线性代码的SSA转换过程,那非线性代码应该怎么处理呢?
例如下面的控制流图,SSA转换之后L5处使用的b是哪一个b?:
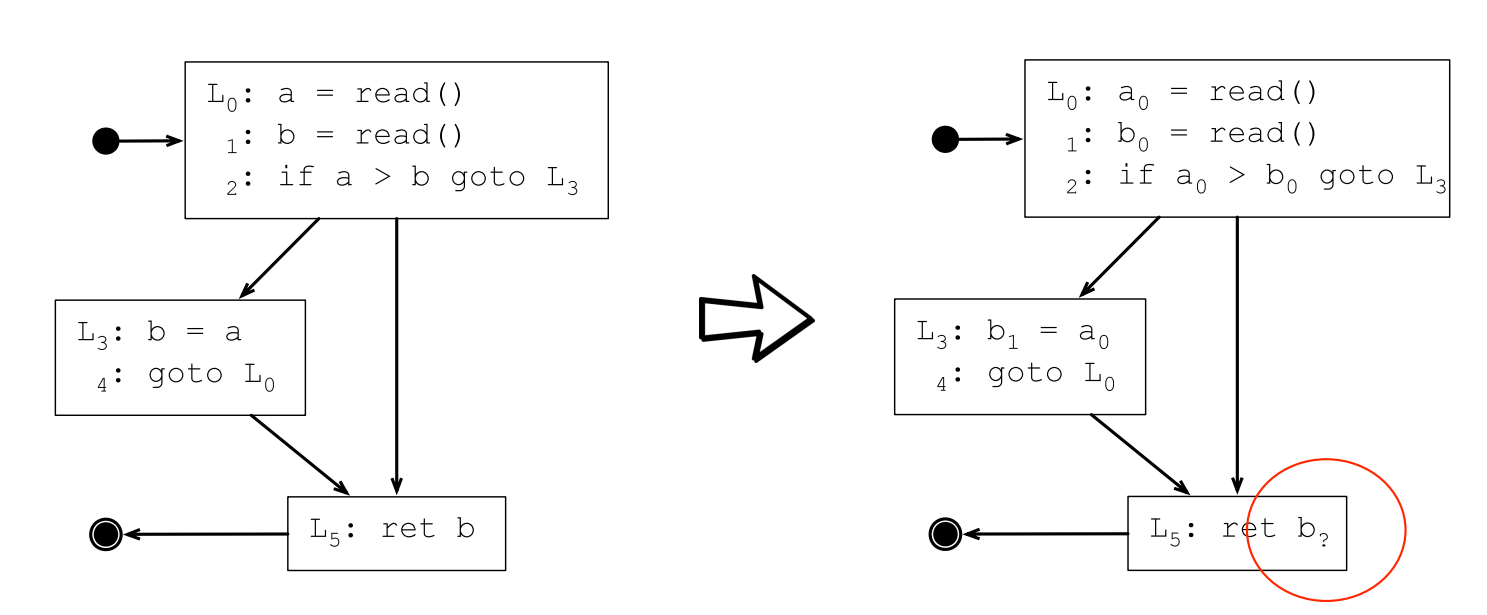
答案是要看情况,如果控制流图上从L4执行到L5,则L5处的b应该是b1;如果是从L2执行到L5,则L5处的b应该是b0。
为了处理这种情况,需要引入phi函数(φ),φ函数会根据路径做选择,根据进入φ函数的路径选择不同的定义。
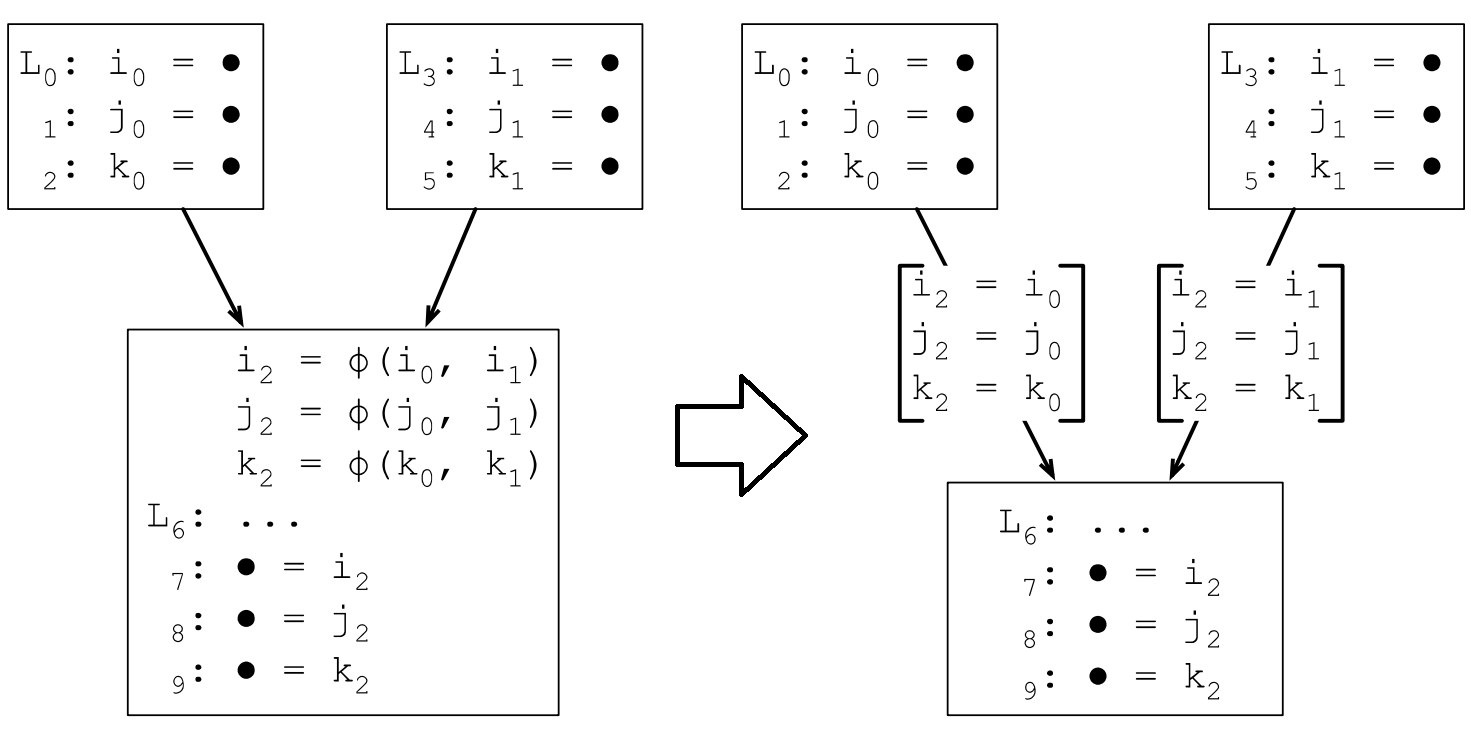
插入φ函数之后的SSA转换结果如下:
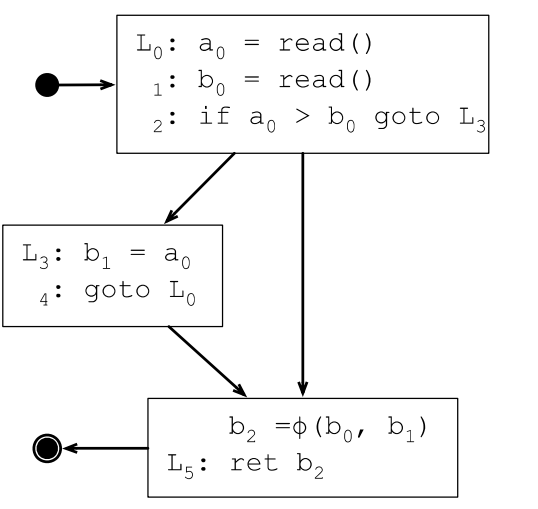
φ函数会插入到每个基本块的最开始地方,对N个变量生成N个φ函数,φ函数的参数个数取决于执行到该基本块的直接前驱有几个。
7.2.3 临界边
如果一条边的起始点BB有多个直接后继BB,终止点的BB有多个前驱BB,则称为该边为临界边。
7.2.4 临界边分裂在临界边上插入一个空的BB(这个BB只有一个简单的goto语句),来解决临界边的上的φ函数自动注入问题。
7.2.5 φ函数的插入策略- 存在一个基本块x包含b的定义
- 存在一个非x的基本块y包含b的定义
- 存在至少一条路径Pxz从x到z
- 存在至少一条路径Pyz从y到z
- Pyz和Pxz除了z节点外,没有其他公共节点
- z不会同时出现在Pxz和Pyz路径中间,但可以出现在其中一条路径的中间
在一个有根的有向图中,d支配n的意思是所有从根节点到n的路径都通过d。
在严格SSA范式(严格的意思是所有变量都是在使用前初始化)程序中,每个变量的定义都支配它的使用:
在基本块n中,如果x是φ函数的第i个参数,则x的定义支配n的第3个前驱。
在一个使用x的不存在φ函数的基本块n中,x的定义支配基本块n。
7.2.7 支配前沿(The Dominance Frontier)一个节点x严格支配节点w,当且仅当x支配w,并且x≠w。
节点x的支配前沿是所有具有下面属性的节点w的集合:x支配w的前驱,但不严格支配w。
支配前沿策略:如果节点x函数变量a的定义,那么x的支配前沿中的任意节点z都需要一个a的φ函数。
支配前沿迭代:因为φ函数本身会产生一个定义,所以需要循环执行支配前沿策略,直到没有节点需要额外增加φ函数。
定理:迭代支配前沿策略和迭代路径覆盖策略生成同样的φ函数集合。
7.2.8 支配前沿的计算
DF[n] = DFlocal[n] ∪ { DFup[c] | c ∈ children[n] }
Where:
DFlocal[n]: 不被n严格支配(SSA的1989年版本要求的是严格支配,但1991年版本优化成直接支配,前一篇在ACM会议上,后一篇在ACM期刊上,Cytron果然是混职级的高手![]() )的n的后继节点
)的n的后继节点
DFup[c]: c的支配前沿集合中不被n严格支配的节点
children[n]: 支配树中n的子结点集合
转换成算法之后的伪代码如下:
1 computeDF[n]: 2 S = {} 3 for each node y in succ[n] 4 if idom(y) ≠ n 5 S = S ∪ {y} 6 for each child c of n in the dom-tree 7 computeDF[c] 8 for each w ∈ DF[c] 9 if n does not dom w, or n = w 10 S = S ∪ {w} 11 DF[n] = S
7.2.9 插入φ函数
插入的算法描述如下:
1 place-phi-functions: 2 for each node n: 3 for each variable a ∈ Aorig[n]: 4 defsites[a] = defsites[a] ∪ [n] 5 for each variable a: 6 W = defsites[a] 7 while W ≠ empty list 8 remove some node n from W 9 for each y in DF[n]: 10 if a ∉ Aphi[y] 11 insert-phi(y, a) 12 Aphi[y] = Aphi[y] ∪ {a} 13 if a ∉ Aorig[y] 14 W = W ∪ {y} 15 16 insert-phi(y, a): 17 insert the statement a = ϕ(a, a, …, a) 18 at the top of block y, where the 19 phi-function has as many arguments 20 as y has predecessors 21 Where: 22 Aorig[n]: the set of variables defined at node "n" 23 Aphi[y]: the set of variables that have phi-functions at node "y"
7.2.10 变量重命名
1 rename(n): 2 rename-basic-block(n) 3 for each successor Y of n, where n is the j-th predecessor of Y: 4 for each phi-function f in Y, where the operand of f is ‘a’ 5 i = top(Stack[a]) 6 replace j-th operand with ai 7 for each child X of n: 8 rename(X) 9 for each instruction S ∈ n: 10 for each variable v that S defines: 11 pop Stack[v]
rename-basic-block的定义参照之前的,这里只是增加了一些场景。7.3 跑一下整个流程 7.3.1 伪代码
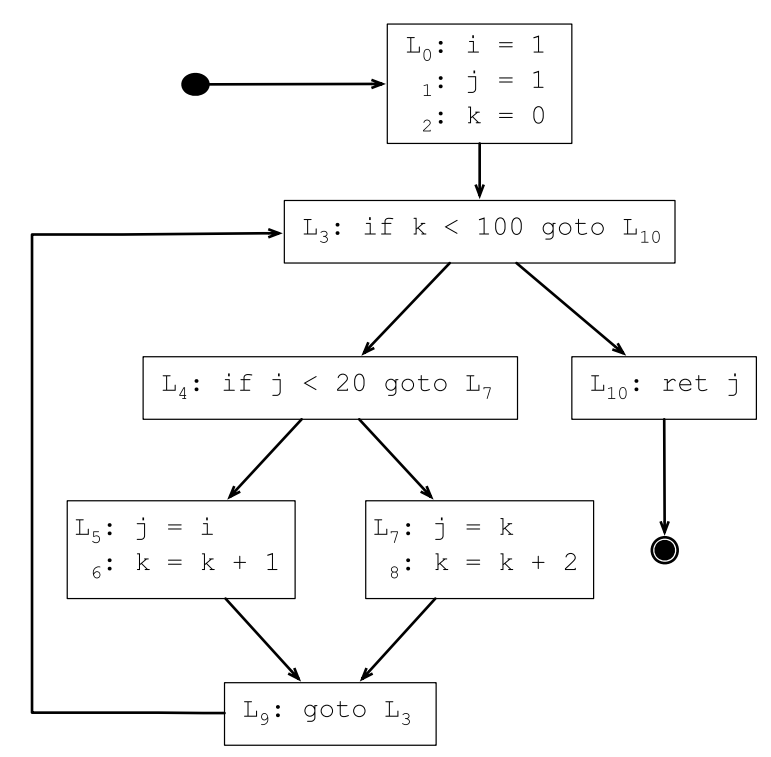
1 i = 1 2 j = 1 3 k = 0 4 while k < 100 5 if j < 20 6 j = i 7 k = k + 1 8 else 9 j = k 10 k = k + 2 11 return j
7.3.2 生成控制流图
7.3.3 根据控制流图生成支配树

7.3.4 计算支配前沿
一般从支配树的叶子节点开始计算,第一轮计算所有叶子节点:
DF(7) = {9}, DF(9) = {3}, DF(5) = {9}, DF(10) = {}
第二轮去掉支配树的所有叶子节点,计算第二轮叶子节点的支配前沿:
DF(4) = {3}
第三轮删掉叶子节点,并计算当前叶子节点的支配前沿:
DF(3) = {3}
第四轮删掉叶子节点,并计算当前叶子节点的支配前沿:
DF(0) = {}
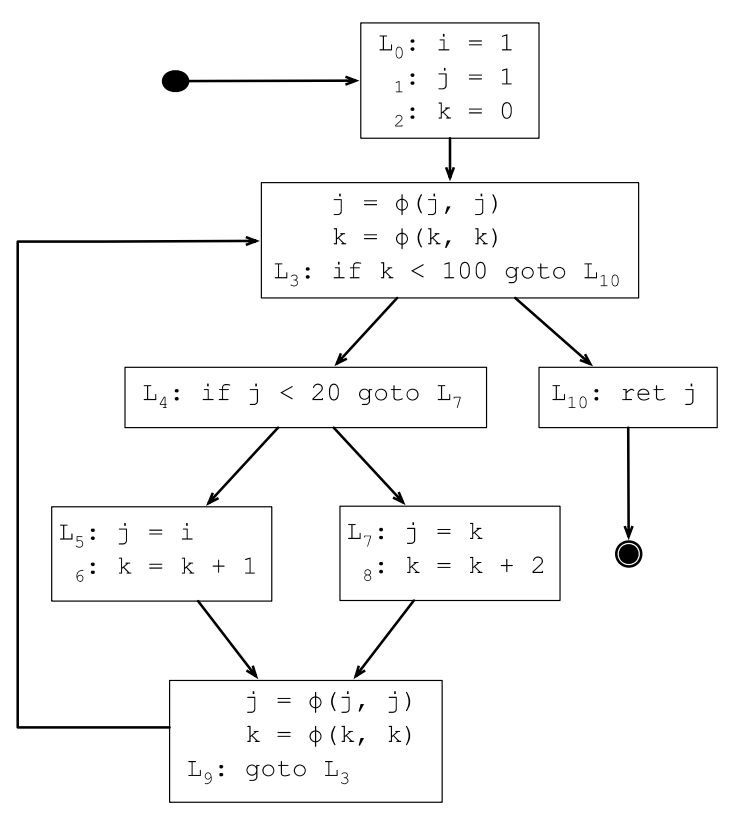
7.3.5 插入φ函数上一节求出来的DF集合其实只有2个元素,所以只需要在L3和L9的基本块开始处插入φ函数,存在多种定义的变量只有j和k,所以下面在L3和L9插入j和k的φ函数:
7.3.6 φ函数的参数个数
是否存在只有一个前驱的φ函数?如果只有一个前驱,那说明变量只有一个定义,自然就不需要φ函数。
是否存在参数多余2个的φ函数?如果前驱个数大于2,自然就会出现参数多余2的φ函数。
7.3.7 变量重命名 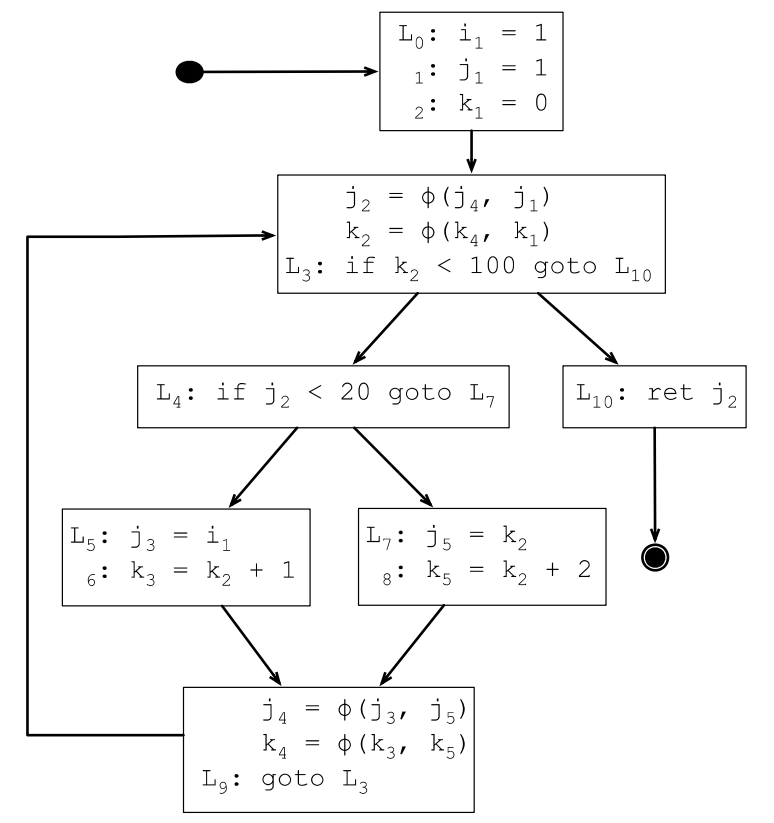
7.3.8 优化SSA范式
上面生成的SSA范式,从SSA的定义上看虽然已经是最简的了,但可能存在一些用不上的变量定义,砍掉这些冗余的定义是生命周期检查的工作,经过生命周期检查,仅在变量i还处在生命周期范围内的程序点才需要插入i的φ函数。
下面L1处的i的定义后面没机会使用了,所以L1处的φ函数插入是不必要的:
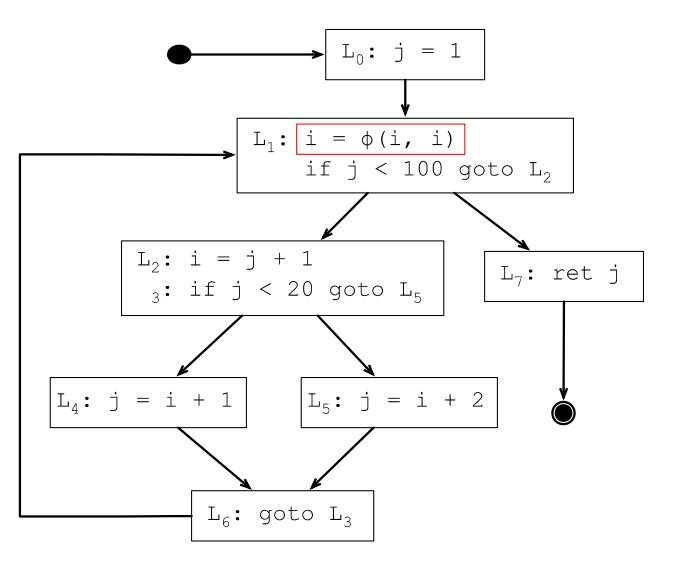
7.4 使用SSA简化分析
SSA范式可以用来简化各种基于数据流的分析。SSA范式之前,数据流分析的某个变量的定义是一个集合,SSA范式转换之后这些变量都变成了唯一定义;而且由于每个变量只有一次定义,相当于说每个变量都可以转换成常量(循环内定义的变量除外,每次循环迭代,变量都会被重新定义)。
7.4.1 简化冗余代码删除如果一个变量定义了,没有使用,并且该定义的语句也没有其他副作用,可以将该变量定义的语句删除。(SSA之前变量是否被使用的含义就要复杂多了,因为会有多个版本的变量定义)
给每个SSA转换之后的每个变量保存一个计数器,初始化为0。遍历一遍代码,每次使用就将计数器加一,遍历完如果某个变量的使用计数器为0,则可以删除变量的定义语句。
7.4.2 简化常量传播因为每个变量的定义都只有一个定义,所以在变量定义时就能判断变量是常量,还是真的变量。如果变量的定义依赖某个外部输入,则它不是常量。如果变量的定义依赖的是一个常量,或者依赖的变量是一个常量,则常量可以一直传播下去,所有类似的变量都能转换成常量。直到明确所有变量都是依赖某个外部输入。
如果碰到φ函数怎么办?因为φ函数会给变量的赋值增加多种可能性,所以变量的定义变成了一个集合,只有当集合中所有定义都是常量的情况下,才能将该变量转换成常量。
下面是llvm的常量传播的实现:

7.4.3 SSA范式转换之后的生命周期分析
新的生命周期分析算法如下:
1 For each statement S in the program: 2 IN[S] = OUT[S] = {} 3 For each variable v in the program: 4 For each statement S that uses v: 5 live(S, v) 6 live(S, v): 7 IN[S] = IN[S] ∪ {v} 8 For each P in pred(S): 9 OUT[P] = OUT[P] ∪ {v} 10 if P does not define v 11 live(P, v)
7.5 SSA简史
- “An Efficient Method of Computing Static Single Assignment Form, ” appeared in the conference Record of the 16th ACM Symposium on principles of Programming Languages (Jan. 1989). https://c9x.me/compile/bib/ssa.pdf
- Efficiently Computing Static Single Assignment Form and the Control Dependence Graph, ACM Transact~ons on Programmmg Languages and Systems, VO1 13, NO 4, October, le91, Pages 451.490. Efficiently computing static single assignment form and the control dependence graph (utexas.edu)
- Lengauer, T. and Tarjan, R. "A Fast Algorithm for Finding Dominators in a Flowgraph", TOPLAS, 1:1 (1979) pp 121-141
- Briggs, P. and Cooper, K. and Harvey, J. and Simpson, L. "Practical Improvements to the Construction and Destruction of Static Single Assignment Form", SP&E (28:8), (1998) pp 859-881