1. k8s简介与本文目的
1.1. 概述
k8s 本身涉及到大量的技术知识,包括操作系统、网络、存储、调度、分布式等方面的知识。在本文中,不会着重讲解 Kubernetes的详细知识。而是尝试去了解Kubernetes的最基本的概念,并基于官方的kubeadmin 工具搭建一个简单的Kubernetes集群。
k8s是Kubernetes的简称,来自Google,是用于自动部署、扩展和管理“容器化应用程序”的开源系统。简单地说就是:k8s 是一套服务器集群管理组件,k8s现在普遍用于管理集群节点上的容器。在学习k8s之前,我们应该具备一定的docker容器基础。
下面这张图展示了一个Kubernetes的一个典型的架构图
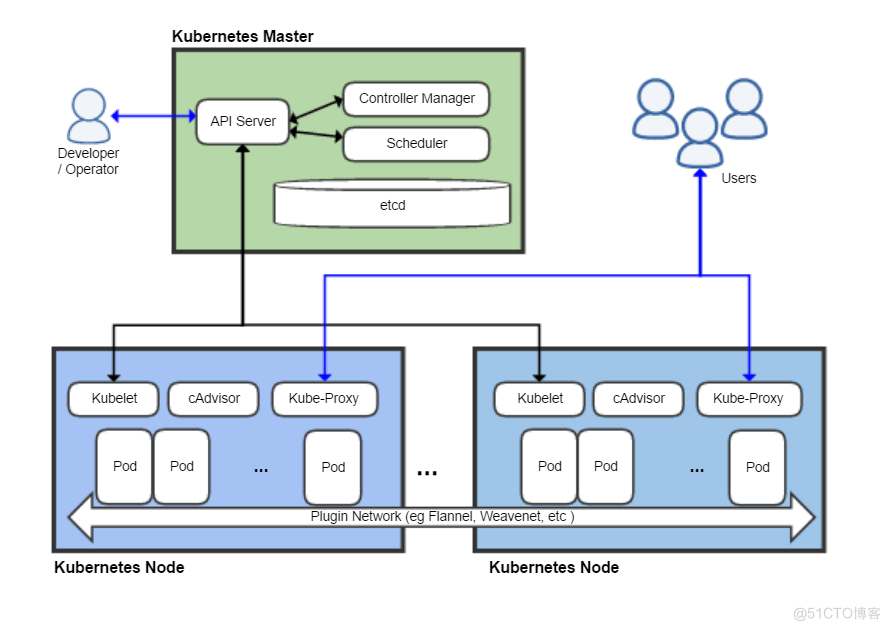
1.2. k8s的功能
- 自我修复
- 弹性伸缩:实时根据服务器并发情况,实现自动增加或缩减容器数量
- 自动部署
- 回滚
- 服务发现和负载均衡
- 机密和配置共享管理
1.3. k8s的相关组件
主控制节点(master node): master节点需要安装以下组件:
- apiserver: 用于接收客户端操作k8s的指令
- schduler: 从多个woker节点组件中选举一个来启动服务
- controller manger: 向worker节点的kubelet组件发送指令
工作节点(worker node): 工作节点,worker节点需要安装以下组件:
- kubenet:向docker发送指令管理docker容器
- kubeproxy:管理docker容器的网络
1.4. k8s的核心概念
-
Controllers:控制器,控制pod,启动、停止、删除
- ReplicaSet
- Deployment
- StatefulSet
- DaemonSet
- Job
-
Cronjob
- service:服务
将一组pod关联起立,提供一个统一的入口,即使pod地址发生改变,这个统一入口也不会变化,可以保证用户访问不受影响
-
label:标签一组pod是一个统一的标签,service是通过标签和一组pod进行关联的
- namespace:名称空间
用来隔离pod的运行环境【默认情况下,pod是可以互相访问】,使用场景,为不同的公司提供隔离的pod运行环境,为开发环境、测试环境、生产环境分别准备不同的名称空间,进行隔离
1.5. 目标
在学习使用kubernetes来管理你的容器应用之前,应当拥有一个Kubernetes集群环境。那么第一步就是自己搭建一个集群环境,本着这个目的,在下文中我们一起探讨怎样搭建一个虚拟机的Kubernetes集群。
本次我们将部署一个主节点(master1)和两个工作节点(worker1、worker2)的集群。为了节省电脑资源,master1、worker1、worker2每个节点分配2个cpu、2G内存、10G硬盘。这也是保证Kubernetes正常运行的的最低配置,但这些配置完全足够我们用以学习。接下来我们将在root用户下,进行相关的操作。
2. 准备环境
2.1. 创建Ubuntu Server 20.04虚拟机
分别创建2核cpu、10G硬盘、2G内存,名为master1、worker1、worker2三台虚拟机
2.1.1. 使用multipass创建
multipass launch -c 2 -d 10G -m 2G -n master1 20.04 multipass launch -c 2 -d 10G -m 2G -n worker1 20.04 multipass launch -c 2 -d 10G -m 2G -n worker2 20.04使用multipass list查询创建的虚拟机列表,如下
pan@pandeMacBook-Pro ~ % multipass list Name State IPv4 Image master1 Running 192.168.64.8 Ubuntu 18.04 LTS worker1 Running 192.168.64.11 Ubuntu 18.04 LTS worker2 Running 192.168.64.12 Ubuntu 18.04 LTS通过以下指令进入虚拟机中
# 进入master1主机 multipass shell master12.1.2. 使用vagrant创建
定义Vagrantfile,如下内容
Vagrant.configure("2") do |config| config.vm.box = "ubuntu/focal64" config.disksize.size = '10GB' # master1 config.vm.define "master1" do |master1| master1.vm.network "public_network", ip: "192.168.33.10" master1.vm.hostname = "master1" # 将宿主机../data目录挂载到虚拟机/vagrant_dev目录 master1.vm.synced_folder "../data", "/vagrant_data" # 指定核心数和内存 config.vm.provider "virtualbox" do |v| v.memory = 2048 v.cpus = 2 end end # worker1 config.vm.define "worker1" do |worker1| worker1.vm.network "public_network", ip: "192.168.33.11" worker1.vm.hostname = "worker1" # 将宿主机../data目录挂载到虚拟机/vagrant_pro目录 worker1.vm.synced_folder "../data", "/vagrant_data" # 指定核心数和内存 config.vm.provider "virtualbox" do |v| v.memory = 2048 v.cpus = 2 end end # worker2 config.vm.define "worker2" do |worker2| worker2.vm.network "public_network", ip: "192.168.33.12" worker2.vm.hostname = "worker2" # 将宿主机../data目录挂载到虚拟机/vagrant_pro目录 worker2.vm.synced_folder "../data", "/vagrant_data" # 指定核心数和内存 config.vm.provider "virtualbox" do |v| v.memory = 2048 v.cpus = 2 end end end如果你的vagrant 虚拟机不能正常运行,需要安装以下两个
vagrant plugin install vagrant-vbguest vagrant-disksize使用vagrant status命令查看当前虚拟机的状态,可以看到如下内容
pan@pan-PC ~/Work/vagrant/kubernetes$ vagrant status Current machine states: master1 running (virtualbox) worker1 running (virtualbox) worker2 running (virtualbox) This environment represents multiple VMs. The VMs are all listed above with their current state. For more information about a specific VM, run `vagrant status NAME`.通过以下指令进入虚拟机中
# 进入master1主机 vagrant ssh master12.2. 修改root用户
为了方便使用root用户,我们对每一台虚拟机进行账号登录的修改操作
# 修改root账号的密ma,这里我都改为123456 sudo passwd root # 修改之后,直接使用su命令切换 root用户 su2.3. 关闭防火墙和iptables
根据官方文档,防火墙和iptables可能会影响到k8s集群,所以我们需要将每一台主机的防火墙关闭掉
# 关闭防火墙 ufw disable # 关闭iptables iptables -P INPUT ACCEPT iptables -P FORWARD ACCEPT iptables -P OUTPUT ACCEPT iptables -F3. 安装docker与kubeadm
因为k8s的很多官方组建服务器在国外,所以下面的很多安装步骤,使用阿里云镜像进行。
3.1. 安装与配置docker
安装docker
# 安装GPG证书 curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add - # 写入软件源信息 add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" # 更新软件库 apt-get -y update # 查询docker版本 apt-cache madison docker-ce # 安装程序 # 18.04 上执行 apt-get -y install docker-ce=5:19.03.15~3-0~ubuntu-bionic # 20.04 上执行 apt-get -y install docker-ce=5:19.03.15~3-0~ubuntu-focal # 固定版本 apt-mark hold docker-ce设置docker阿里云加速镜像仓库
mkdir -p /etc/docker tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://g6ogy192.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"] } EOF systemctl daemon-reload systemctl restart docker3.2. 安装kubeadm, kubelet, kubectl
# 下载 gpg 密钥 curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add - # 添加 k8s 镜像源 cat <<EOF > /etc/apt/sources.list.d/kubernetes.list deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main EOF # 更新软件库 apt-get update # 安装程序 apt-get install -y kubelet=1.18.0-00 kubeadm=1.18.0-00 kubectl=1.18.0-00 # 固定版本 apt-mark hold kubelet kubeadm kubectl3.3. 集群服务镜像准备
使用kubeadm config images list命令查看当前集群所需要的镜像,镜像版本会根据kubeadm版本而定,返回如下内容
k8s.gcr.io/kube-apiserver:v1.18.20 k8s.gcr.io/kube-controller-manager:v1.18.20 k8s.gcr.io/kube-scheduler:v1.18.20 k8s.gcr.io/kube-proxy:v1.18.20 k8s.gcr.io/pause:3.2 k8s.gcr.io/etcd:3.4.3-0 k8s.gcr.io/coredns:1.6.7我们使用docker拉取镜像,但是由于国内正常访问不到k8s.cgr.io,可以替换阿里加速镜像地址:registry.aliyuncs.com/google_containers,执行如下命令
docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.18.20 docker pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.18.20 docker pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.18.20 docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.18.20 docker pull registry.aliyuncs.com/google_containers/pause:3.2 docker pull registry.aliyuncs.com/google_containers/etcd:3.4.3-0 docker pull registry.aliyuncs.com/google_containers/coredns:1.6.7接下来给镜像重命名,使其和原kubeadm需要的镜像名称一致
docker tag registry.aliyuncs.com/google_containers/kube-apiserver:v1.18.20 k8s.gcr.io/kube-apiserver:v1.18.20 docker tag registry.aliyuncs.com/google_containers/kube-controller-manager:v1.18.20 k8s.gcr.io/kube-controller-manager:v1.18.20 docker tag registry.aliyuncs.com/google_containers/kube-scheduler:v1.18.20 k8s.gcr.io/kube-scheduler:v1.18.20 docker tag registry.aliyuncs.com/google_containers/kube-proxy:v1.18.20 k8s.gcr.io/kube-proxy:v1.18.20 docker tag registry.aliyuncs.com/google_containers/pause:3.2 k8s.gcr.io/pause:3.2 docker tag registry.aliyuncs.com/google_containers/etcd:3.4.3-0 k8s.gcr.io/etcd:3.4.3-0 docker tag registry.aliyuncs.com/google_containers/coredns:1.6.7 k8s.gcr.io/coredns:1.6.7再删除掉从阿里云下载的镜像
docker rmi registry.aliyuncs.com/google_containers/kube-apiserver:v1.18.20 docker rmi registry.aliyuncs.com/google_containers/kube-controller-manager:v1.18.20 docker rmi registry.aliyuncs.com/google_containers/kube-scheduler:v1.18.20 docker rmi registry.aliyuncs.com/google_containers/kube-proxy:v1.18.20 docker rmi registry.aliyuncs.com/google_containers/pause:3.2 docker rmi registry.aliyuncs.com/google_containers/etcd:3.4.3-0 docker rmi registry.aliyuncs.com/google_containers/coredns:1.6.74. k8s集群的初始化
4.1. 初始化master节点
在master节点上执行初始化命令
kubeadm init --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16 --ignore-preflight-errors=Swap参数说明
- --service-cidr:k8s中scv网络的网络段
- --pod-network-cidr:k8s中pod使用的网络段
- --ignore-preflight-errors:忽略swap报错
初始化结果如下
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.64.8:6443 --token mzolyd.fgbta1hw9s9yml55 \ --discovery-token-ca-cert-hash sha256:21ffa3a184bb6ed36306b483723c37169753f9913e645dc4f88bb12afcebc9dd4.2. 让Linux用户能操作集群
根据初始化结果提示,为了让master1上的Linux用户正常操作集群,我们输入exit按回车切换回普通用户后执行以下命令
$ mkdir -p $HOME/.kube $ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config $ sudo chown $(id -u):$(id -g) $HOME/.kube/config4.3. 配置集群网络
根据初始化结果提示,我们需要安装网络插件。本次我们使用flannel作为集群的网络插件,将flannel配置文件从互联网保存到master1,文件地址为:https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml,在master1上将文件命名为kube-flannel.yml,后执行以下命令
kubectl apply -f kube-flannel.yml如看到如下信息,即网络插件安装成功
podsecuritypolicy.policy/psp.flannel.unprivileged created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds created4.4. 初始化集群工作节点
同时,初始化集群管理节点master1之后,我们需要将工作节点worker1和wroker2加入到集群中。将工作节点的初始化命令拷贝到worker1和worker2,使集群的工作节点(worker1、worker2)和工作节点(master1)关联起来,如下命令
kubeadm join 192.168.64.8:6443 --token mzolyd.fgbta1hw9s9yml55 \ --discovery-token-ca-cert-hash sha256:21ffa3a184bb6ed36306b483723c37169753f9913e645dc4f88bb12afcebc9dd在工作节点执行初始化命令之后,我们在管理节点使用kubectl get pods --all-namespaces查看结果,如下结果
root@master1:/home/ubuntu# kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-66bff467f8-pw9br 1/1 Running 0 13m kube-system coredns-66bff467f8-wsj45 1/1 Running 0 13m kube-system etcd-master1 1/1 Running 0 14m kube-system kube-apiserver-master1 1/1 Running 0 14m kube-system kube-controller-manager-master1 1/1 Running 0 14m kube-system kube-flannel-ds-c4jnh 1/1 Running 0 3m39s kube-system kube-flannel-ds-rg58c 1/1 Running 0 3m14s kube-system kube-flannel-ds-sw85v 1/1 Running 0 3m15s kube-system kube-proxy-ddk88 1/1 Running 0 3m15s kube-system kube-proxy-dt825 1/1 Running 0 13m kube-system kube-proxy-jgm4h 1/1 Running 0 3m14s kube-system kube-scheduler-master1 1/1 Running 0 14m需要注意的是,如果你的列表中显示的所有pod并不是处于Running状态,你需要等待一段时间。而且,你在安装集群的过程中,最好处于一个优质的网络环境。