点赞再看,养成习惯,微信搜索【牧小农】关注我获取更多资讯,风里雨里,小农等你,很高兴能够成为你的朋友。
什么是Kubernetes?
Kubernetes 是Google开源的分布式容器管理平台,是为了更方便的在服务器中管理我们的容器化应用。
Kubernetes 简称 K8S,为什么会有这个称号?因为K和S是 Kubernetes 首字母和尾字母,而K和S中间有八个字母,所以简称 K8S,加上 Kubernetes比较绕口,所以一般使用简称 K8S。
Kubernetes 即是一款容器编排工具,也是一个全新的基于容器技术的分布式架构方案,在基于Docker的基础上,可以提供从 创建应用>应用部署>提供服务>动态伸缩>应用更新一系列服务,提高了容器集群管理的便捷性。
K8S产生的原因
大家可以先看一下,下面一张图,里面有我们的mysql,redis,tomcat,nginx等配置信息,如果我们想要安装里面的数据,我们需要一个一个手动安装,好像也可以,反正也就一个,虽然麻烦了一点,但也不耽误。

但是随着技术的发展和业务的需要,单台服务器已经不能满足我们日常的需要了,越来越多的公司,更多需要的是集群环境和多容器部署,那么如果还是一个一个去部署,运维恐怕要疯掉了,一天啥也不干就去部署机器了,有时候,可能因为某一个环节出错,要重新,那真的是吐血。。。。。,如下图所示:
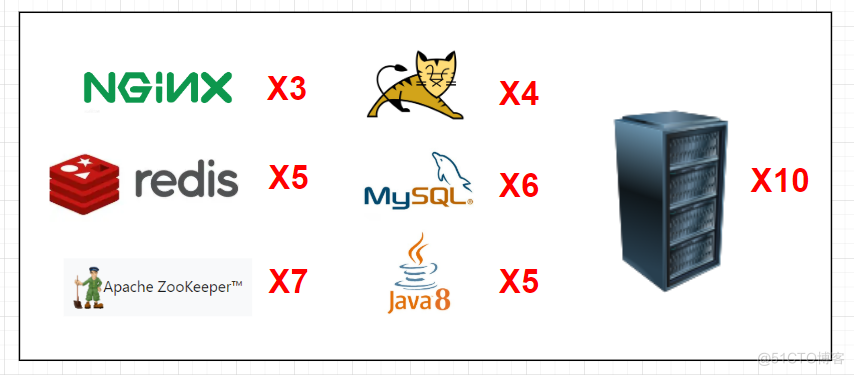
如果我想要部署,以下几台机器:
3台 - Nginx5台 - Redis7台 - ZooKeeper4台 - Tomcat6台 - MySql5台 - JDK10台 - 服务器
如果要一个一个去部署,人都要傻掉了,这什么时候是个头,如果是某里巴的两万台机器,是不是要当场提交辞职信,所以 K8S 就是帮助我们来做这些事情的,方便我们对容器的管理和应用的自动化部署,减少重复劳动,并且能够自动化部署应用和故障自愈。
并且如果 K8S 对于微服务有很好的支持,并且一个微服务的副本可以跟着系统的负荷变化进行调整,K8S 内在的服务弹性扩容机制也能够很好的应对突发流量。
容器编排工具对比
Docker-Compose
Docker-Compose 是用来管理容器的,类似用户容器管家,我们有N多台容器或者应用需要启动的时候,如果手动去操作,是非常耗费时间的,如果有了 Docker-Compose 只需要一个配置文件就可以帮我们搞定,但是 Docker-Compose 只能管理当前主机上的 Docker,不能去管理其他服务器上的服务。意思就是单机环境。
Docker Swarm

Docker Swarm 是由Docker 公司研发的一款用来管理集群上的Docker容器工具,弥补了 Docker-Compose 单节点的缺陷,Docker Swarm 可以帮助我们启动容器,监控容器的状态,如果容器服务挂掉会重新启动一个新的容器,保证正常的对外提供服务,也支持服务之间的负载均衡。而且这些东西 Docker-Compose是不支持的,
Kubernetes

Kubernetes 它本身的角色定位是和Docker Swarm 是一样的,也就是说他们负责的工作在容器领域来说是相同的部分,当然也要一些不一样的特点,Kubernetes 是google自己的产品,经过大量的实践和宿主机的实验,非常的成熟,所以 Kubernetes 正在成为容器编排领域的领导者,其 可配置性、可靠性和社区的广大支持,从而超越了 Docker Swarm,作为google的开源项目,它和整个google的云平台协调工作。
K8S的职责
K8S的基本概念
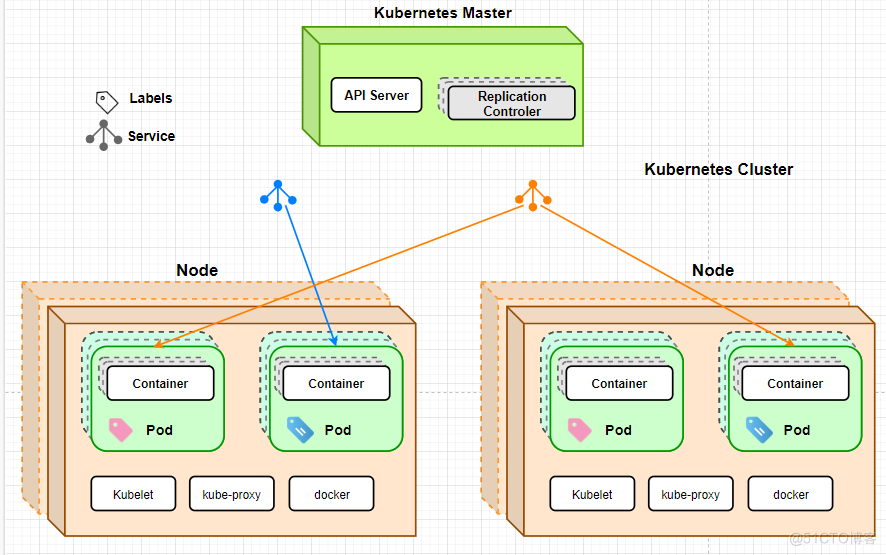
在下图中,是K8S的一个集群,在这个集群中包含三台宿主机,这里的每一个方块都是我们的物理虚拟机,通过这三个物理机,我们形成了一个完整的集群,从角色划分,可以分为两种
-
一种是 Kubernetes Master主服务器,它是整个集群的管理者,它可以对整个集群的节点进行管理,通过主服务器向这些节点,发送创建容器、自动部署、自动发布等功能,并且所有来自外部的数据都会由 Kubernetes Master进行接收并进行分配。
- 还有一种就是 node节点 节点可以是一台独立的物理机也可以是一个虚拟机,在每个节点中都有一个非常重要的 K8S 独有的概念,就是我们的Pod,Pod是K8S最重要也是最基础的概念
Pod
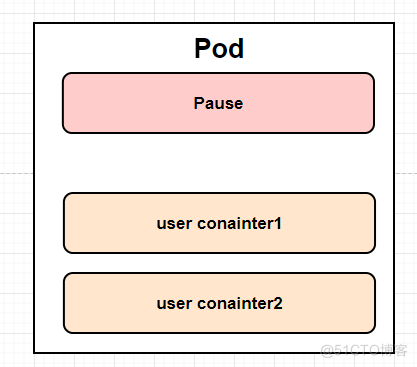
- Pod是 Kubernetes 控制的最小单元,一个Pod就是一个进程。
- 一个Pod可以被一个容器化的环境看做应用层的“逻辑宿主机”,可以理解为容器的容器,可以包含多个“Container”;
- 一个Pod的多个容器应用通常是紧密耦合的,Pod在Node上创建、启动或销毁;
- 每个Pod里面运行着一个特殊的被称为Pause的容器,其他的容器被称为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷;
- Pod的内部容器网络是互通的,每个Pod都有独立的虚拟IP。
- Pod都是部署完整的应用或模块,同一个Pod容器之间只需要通过localhsot就能互相通信。
- Pod的生命周期是通过 Replication Controller 来管理的,通过模板进行定义,然后分配到一个Node上运行,在Pod锁包含容器运行结束后,Pod结束。
打一个比较形象的比喻,我们可以把Pod理解成一个豆荚,容器就是里面的豆子,是一个共生体。
Pod里面到底装的是什么?
-
在一些小公司里面,一个Pod就是一个完整的应用,里面安装着各种容器,一个Pod里面可能包含(Redis、Mysql、Tomcat等等),当把这一个Pod部署以后就相当于部署了一个完整的应用,多个Pod部署完以后就形成了一个集群,这是Pod的第一种应用方式
- 还有一种使用方式就是在Pod里面只服务一种容器,比如在一个Pod里面我只部署Tomcat
具体怎么部署Pod里面的容器,是按照我们项目的特性和资源的分配进行合理选择的。
pause容器:
Pause容器 全称infrastucture container(又叫infra)基础容器,作为init pod存在,其他pod都会从pause 容器中fork出来,这个容器对于Pod来说是必备的一个Pod中的应用容器共享同一个资源:
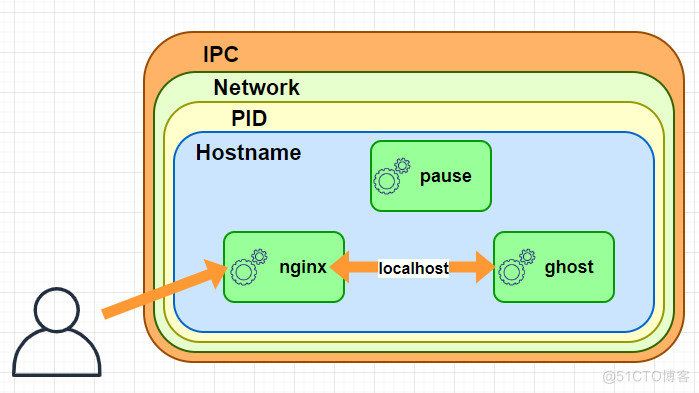
在上图中如果没有pause容器,我们的Nginx和Ghost,Pod内的容器想要彼此通信的话,都需要使用自己的IP地址和端口,才可以彼此进行访问,如果有pause容器,对于整个Pod来说,我们可以看做一个整体,也就是我们的Nginx和Ghost直接使用localhost就可以进行访问了,他们唯一不同的就只是端口,这里面可能看着觉得比较简单,但其实是使用了很多网络底层的东西才实现的,感兴趣的小伙伴可以自行了解一下。
Service(服务)
在 Kubernetes 中,每个Pod都会被分配一个单独的IP地址,但是Pod和Pod之间,是无法直接进行交互的,如果想要进行网络通信,必须要通过另外一个组件才能交流,也就是我们的 Service
Service 是服务的意思,在K8S中Service主要工作就是将多个不同主机上的Pod,通过Service进行连通,让Pod和Pod之间可以正常的通信
我们可以把Service看做一个域名,而相同服务的Pod集群就是不同的ip地址,Service 是通过 Label Selector 来进行定义的。
- Service 拥有一个指定的名字,类似于域名这种,并且它还拥有一个虚拟的IP地址和端口号,只能内网进行访问,如果Service想要进行外wang访问或提供外网服务,需要指定公共的IP和NodePort或者外部的负载均衡器。
使用NodePort提供外部访问,只需要在每个Node上打开一个主机的真实端口,这样就可以通过Node的客户端访问到内部的Service。
Label(标签)
Label 一般以 kv的方式附件在各种对象上,Label 是一个说明性的标签,它有着很重要的作用,我们在部署容器的时候,在哪些Pod进行操作,都需要根据Label进行查找和筛选,我们可以理解Label是每一个Pod的别名,只有取了名称,作为K8S的Master主节点才能找到对应的Pod进行操作。
Replication Controller(复制控制器)
存在Master主节点上,这个兄弟的作用主要是对Pod的数量进行监控,比如我们在下面的节点中我们需要三个相同属性的Pod,但是目前只有两个,当Replication Controller看到只有两个的时候,就会自动帮助我们按照我们制定的规则创建一个额外的副本,放到我们的节点中。
Replication Controller还可以对Pod进行实时监控,当我们某一个Pod它失去了响应,这个Pod就会被剔除,如果我们需要,Replication Controller会自动创建一个新的
K8S的总体架构
- Kubernetes将集群中的机器划分为一个Master节点和一群工作节点(Node)
- Master节点上运行着集群管理相关的一组进程etcd、API Server、Controller Manager、Scheduler,后三个组件构成了Kubernetes的总控中心,这些进程实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控和纠错等管理功能,并且全都是自动完成。
- Node上运行kubelet、kube-proxy、docker三个组件,是真正支持K8S的技术方案。负责对本节点上的Pod的生命周期进行管理,以及实现服务代理的功能。
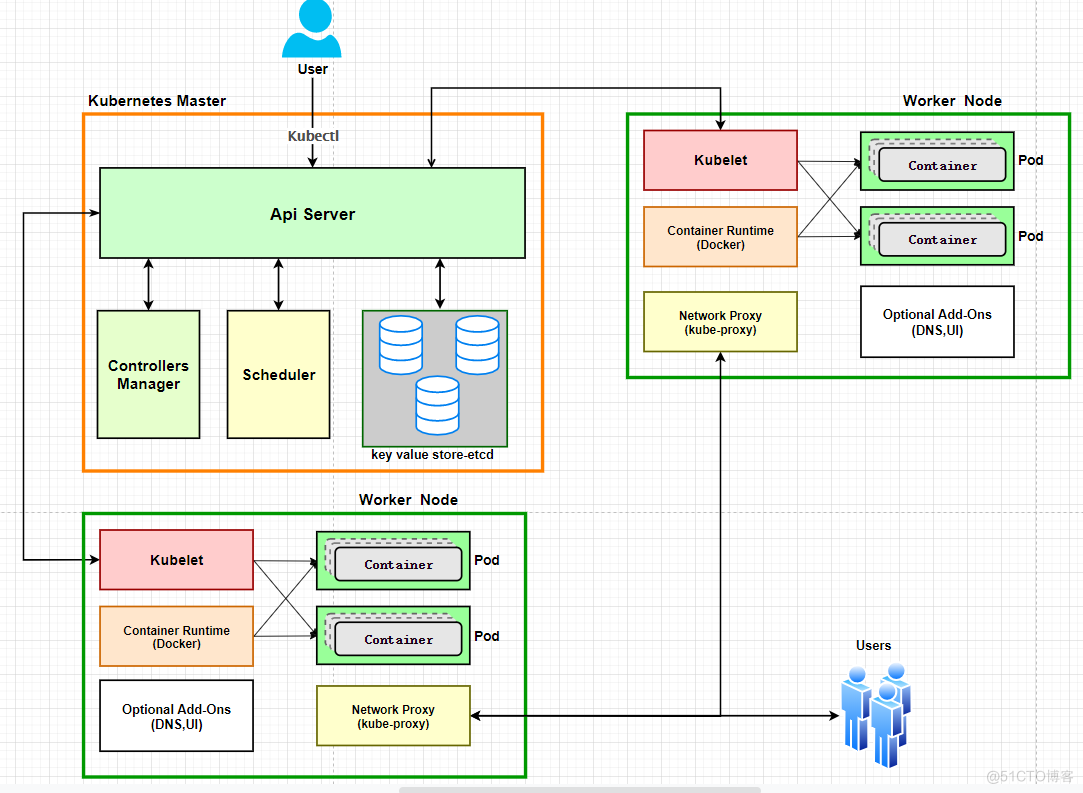
用户通过 Kubectl提交一个创建 Replication Controller请求,这个请求通过 API Server 写入 etcd 中,这个时候Controller Manager通过 API Server的监听到了创建的命名,经过它认真仔细的分析以后,发现当前集群里面居然还没有对应的Pod实例,赶紧根据Replication Controller模板定义造一个Pod对象,再通 过Api Server 写到我们 etcd 里面
到下面,如果被Scheduler发现了,好家伙不告诉我???,无业游民,这家伙一看就不是一个好人啊,它就会立即运行一个复杂的调度流程,为这个新的Pod选一个可以落户的Node,总算有个身份了,真是让人操心,然后通过 API Server 将这个结果也写到etcd中,随后,我们的 Node上运行的小管家Kubelet进程通过 API Server 检测到这个 新生的小宝宝——“Pod”,就会按照它,就会按照这个小宝宝的特性,启动这个Pod并任劳任怨的负责它的下半生,直到Pod的生命结束。
然后我们通过Kubectl提交一个新的映射到这个Pod的Service的创建请求,Controller Manager会通过Label标签查询到相关联的Pod实例,生成Service的Endpoints的信息,并通过 API Server 写入到etcd中,接下来,所有Node上运行的Proxy进程通过 Api Server 查询并监听Service对象与其对应的Endpoints信息,建立一个软件方式的负载均衡器来实现Service访问到后端Pod的流量转发功能。
kube-proxy: 是一个代理,充当这多主机通信的代理人,前面我们讲过Service实现了跨主机、跨容器之间的网络通信,在技术上就是通过kube-proxy来实现的,service是在逻辑上对Pod进行了分组,底层是通过kube-proxy进行通信的
kubelet: 用于执行K8S的命令,也是K8S的核心命令,用于执行K8S的相关指令,负责当前Node节点上的Pod的创建、修改、监控、删除等生命周期管理,同时Kubelet定时“上报”本Node的状态信息到API Server里
etcd: 用于持久化存储集群中所有的资源对象,API Server提供了操作 etcd的封装接口API,这些API基本上都是对资源对象的操作和监听资源变化的接口
API Server : 提供资源对象的操作入口,其他组件都需要通过它提供操作的API来操作资源数据,通过对相关的资源数据“全量查询”+ “变化监听”,可以实时的完成相关的业务功能。
Scheduler : 调度器,负责Pod在集群节点中的调度分配。
Controller Manager: 集群内部管理控制中心,主要是实现 Kubernetes集群的故障检测和恢复的自动化工作。比如Pod的复制和移除,Endpoints对象的创建和更新,Node的发现、管理和状态监控等等都是由 Controller Manager完成。
总结
到这里K8S的基本情况我们就讲解完毕了,有喜欢的小伙伴记得 点赞关注,相比如Docker来说K8S有着更成熟的功能,经过google大量实践的产物,是一个比较成熟和完善的系统。
关于K8S大家有什么想要了解或者疑问的地方欢迎大家留言告诉我。
我是牧小农,一个卑微的打工人,如果觉得文中的内容对你有帮助,记得一键三连,你们的三连是小农最大的动力。
—— 怕什么真理无穷,进一步 有进一步的欢喜,大家加油~