这是一篇介绍监控系统Prometheus(普罗米修斯)的文章系列。之前的文章在这里查看:Prometheus(普罗米修斯)监控系统(一)
一、PromQL进阶
(一)、范围向量选择器:
概览
同即时向量选择器唯一不同的在于,需要在表达式后紧跟一个方括号[]来表达需要在时间序列上返回的样本所处的时间范围;
时间范围
以当前时间为基准时间点,指向过去一个特定的时间长度,例如:[5m]是指过去5分钟之内;
时间格式
一个整数后跟一个时间单位,例如:[5m]中的“m”即是时间单位;
- 可用的时间单位有ms(毫秒)、s(秒)、m(分钟)、h(小时)、d(天)、w(周)和y(年);
- 必须使用整数时间,且能够将多个不同级别的单位进行串联组合,以时间单位由大到小为顺序,例如1h30m,但不能使用1.5h;
注意
范围向量选择器返回的是一定范围时间内的数据样本,虽然不同时间序列的数据抓取时间点相同,但是他们时间戳并不会严格对齐(Prometheus为了降低server在抓取众多指标时候的压力)
- 多个target上的数据抓取需要分散在抓取点前后一定的时间范围内,以均衡Prometheus server的负载;
- 因而,Prometheus 在趋势上的准确,但并非绝对精准。
偏移量修改器
默认情况下,选择器都以当前时间为基准时间点,而偏移量修改器能够修改该基准;
- 使用方法是在选择器表达式之后使用“offset” 关键案字指定:http_requests_total offset 5m :表示获取以http_requests_total为指标名称的所有时间序列在过去5分钟之内的样本http_requests_total [5m] offset 1d :表示获取距当前时间1天之前的5分钟之内的所有样本;
(二)、指标类型:
PromQL的指标类型
PromQL有四个指标类型,他们主要由Prometheus 的客户端库使用
- Counter :计数器,单调递增,除非重置
- Gauge :仪表盘,可增可减的数据
- Histogram :直方图,将时间范围内的数据划分成不同的时间段,并各自评估其样本个数及样本值之和,因而可计算出分位数,可用于分析因异常值而引起的平均值过大的问题。比如我们看指标load一天内的平均值很低,就以为load很低,这其实是一个误区,平均值并不能分析出具体一个时刻发生的特殊事件,所以通过分位数就可以很清晰的找到在特殊时刻发生特殊情况。
- Summary :类似Histogram ,但客户端会直接计算并上报分位数;

Prometheus server 并不使用类型信息,而是将所有数据展平为时间序列;
Counter
表示收集的数据是按照某个趋势(增加/减少)一直变化的,我们往往用它记录服务请求总量,错误总数等。例如 Prometheus server 中 http_requests_total, 表示 Prometheus 处理的 http 请求总数,我们可以使用data, 很容易得到任意区间数据的增量。通常,Counter 的总数并没有直接作用,而是需要借助于rate、topk、increase和irate等函数来生成样本数据的变化状况(增长率);
- rate(http_requests_total[2h]),获取2小时内,该指标下各时间序列上的http总请求数的增长速率;
- topk(3,http_requests_total[2h]),获取该指标下http请求总数排名前三的时间序列;
- irate(http_requests_total[2h]),高灵敏度函数,用于计算指标的瞬时速率;适用于短期时间范围内的变化速率分析;
Gauge
表示搜集的数据是一个瞬时的,与时间没有关系,可以任意变高变低,往往可以用来记录内存使用率、磁盘使用率等。Gauge用存储其值可增可减的指标样本数据,常用于进行求和,取平均值,最小值,最大值等聚合运算;也经常结合predict_linear和delta函数使用
- predict_linear(v,range-vector,t,scalar)函数可以预测时间序列v在t秒后的值,它通过线性回归的方式来预测样本数据的变化趋势;
- delta(v,range-vector)函数计算范围向量中每个时间序列元素的第一个值与最后一个值之差,从而展示不同时间点上的样本值的差异;例如:delta(cpu_temp_celsius{host="www.lwj.com"}[2h]),返回该服务器上的cpu温度与2小时之前的差异。
Histogram
Histogram 由 <basename>_bucket{le="<upper inclusive bound>"}(样本统计区间), <basename>_bucket{le="+Inf"}(最大区间包含所有样本),<basename>_sum(所有样本观测值的总和),<basename>_count(总的观察次数,本身是一个Counter类型的指标) 组成,主要用于表示一段时间范围内对数据进行采样,(通常是请求持续时间或响应大小),并能够对其指定区间以及总数进行统计,通常我们用它计算分位数的直方图。
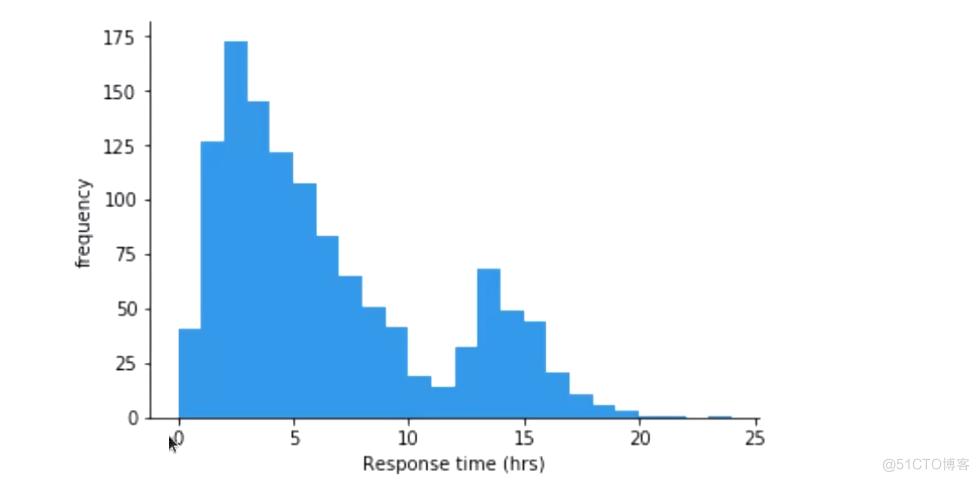
- 由横轴表示指标的数据取值区间,用纵轴表示样本统计的频率,从而能够以二维图的形式展现数值的分布情况
- 为了展示Histogram ,首先需要将数值的范围进行分段,而后统计每个间隔中有多少值;
-
Histogram 的作用用于排查非常明显举个例子,今天我们的线上应用发生了一次故障,我们通过分析nginx日志的所有请求时间/所有请求数,就会得出一个平均的请求时间,假设这个平均请求时间为2秒,那是不是就认为,我们的应用响应性能非常棒?不会有任何问题?这个时候,我们如果通过Histogram 的立方图,把响应时间按段来分开成4段1、小-于0.05s2、大于0.05s小于2s3、大于2s小于10s4、大于10s小于30s通过观察发现,大部分的响应在前两段,但是最后一段2s小于10s这一段,出现了一些链接。那其实就说明,在那个时间节点,服务确实是出现过慢请求,那意味着确实是出现过问题。所以通过平均数来判断是有很大的迷惑性,我们应该使用分位数来了解真正的数据分布状态。
- Summary Summary 和 Histogram 类似,由<basename>{quantile="<φ>"},<basename>_sum,<basename>_count组成,主要用于表示一段时间内数据采样结果,(通常是请求持续时间或响应大小),它直接存储了 quantile 数据,而不是根据统计区间计算出来的。区别在于: a. 都包含 <basename>_sum,<basename>_count。b. Histogram 需要通过 <basename>_bucket 计算 quantile, 而 Summary 直接存储了 quantile 的值。
PromQL 内置函数
内置函数
二、服务发现
配置客户端有两种方式,一是静态配置,二是服务发现。静态配置适合需要监控的客户端不多并且变动不大的情况,服务发现适合客户端较多,并且变动较达,如docker实例,经常变更等情况。
(一)、基于文件的服务发现
基于文件的服务发现优于静态配置的服务发现方式,是最简单和通用的实现方式;主 配置文件:
scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: file_sd_configs: #基于文件的服务发现 - files: - targets/prometheus-*.yaml #加载发现targets目录下所有prometheus-开头的配置文件 refresh_interval: 2m #每隔2分钟重载配置文件 # All nodes - job_name: 'nodes' file_sd_configs: - files: - targets/nodes-*.yaml refresh_interval: 2mtouch targetscd targetsvim nodes-linux.yaml
- targets: - 192.168.0.62:9100 - 192.168.0.63:9100 - 192.168.0.64:9100 labels: app: node-exporter job: nodevim prometheus-servers.yaml
- targets: - 192.168.0.61:9100 labels: app: prometheus job: prometheus重启prometheus后,可以根据配置文件nodes-linux.yaml里面的配置,2分钟跟新一次,增加或减少target节点。
(二)、基于dns 的服务发现
基于dns的服务发现针对一组dns域名进行定期查询,以发现待监控的目标
- 查询时使用的dns服务器由 /etc/resolv.conf文件指定;
- 该发现机制依赖于A AAAA 和SRV资源记录,且仅支持该类方法,尚不支持RFC6763中的高级dns发现方法;
- 基于DNS的服务发现,需要搭建一台配置好的DNS服务器将prometheus-server所在主机的dns设置为部署好的dns,dns配置好解析记录如下: [root@node1 prometheus]# nslookup > set type=srv > _prometheus._tcp.cmxu.com Server: 192.168.42.128 Address: 192.168.42.128#53
_prometheus._tcp.cmxu.com service = 10 10 9100 node1.cmxu.com._prometheus._tcp.cmxu.com service = 10 10 9100 master.cmxu.com.
set type=anode1.cmxu.comServer: 192.168.42.128Address: 192.168.42.128#53
Name: node1.cmxu.comAddress: 192.168.42.133
quitServer: 192.168.42.128Address: 192.168.42.128#53
配置主文件: ```bash scrape_configs: - job_name: 'node_exporter_dns' #基于SRV记录发现,不手动指定,默认就是基于SRV dns_sd_configs: - names: ['_prometheus._tcp.cmxu.com']- job_name: 'docker_CADvisor_dns' #基于A记录发现dns_sd_configs:
- names: ['node1.cmxu.com']type: Aport: 8181 
(三)、通过Consul发现
Consul是一款基于go开发的开源工具,主要面向分布式、服务化的系统提供服务注册、服务发现和配置管理的功能;提供服务注册、发现、监控检查、key/Value存储、多数据中心和分布式一致性保证等功能;
安装Consul
wget https://releases.hashicorp.com/consul/1.6.1/consul_1.6.1_linux_amd64.zip mkdir consul cd consul unzip consul_1.6.1_linux_amd64.zip启动consul
#使用dev模式测试,开发环境使用server模式 ./consul agent -dev -ui -data-dir=/root/consul/data/ -config-dir=/root/consul/ -client=0.0.0.0-server 表示是server模式 -dev 表示开发模式-data-dir 目录-client 客户端ip-ui 非必须 webui的路径 用web来管理consul-config-dir 配置文件目录
启动成功后访问:ip+8500
https://blog.csdn.net/aixiaoyang168/article/details/103022342
这个时候,consul还没有注册服务,所以,没有其他节点。
注册服务节点
vim prometheus-servers.json #配置文件需要在之前consul启动时候制定的配置路径中 { "services": [ { "id": "prometheus-server-node01", "name": "prom-server-node01", "address": "192.168.0.56", "port": 9090, "tags": ["prometheus"], "checks": [{ "http": "http://192.168.0.56:9090/metrics", "interval": "5s" }] } ] } ./consul reload #重载consul增加了prometheus-server的节点: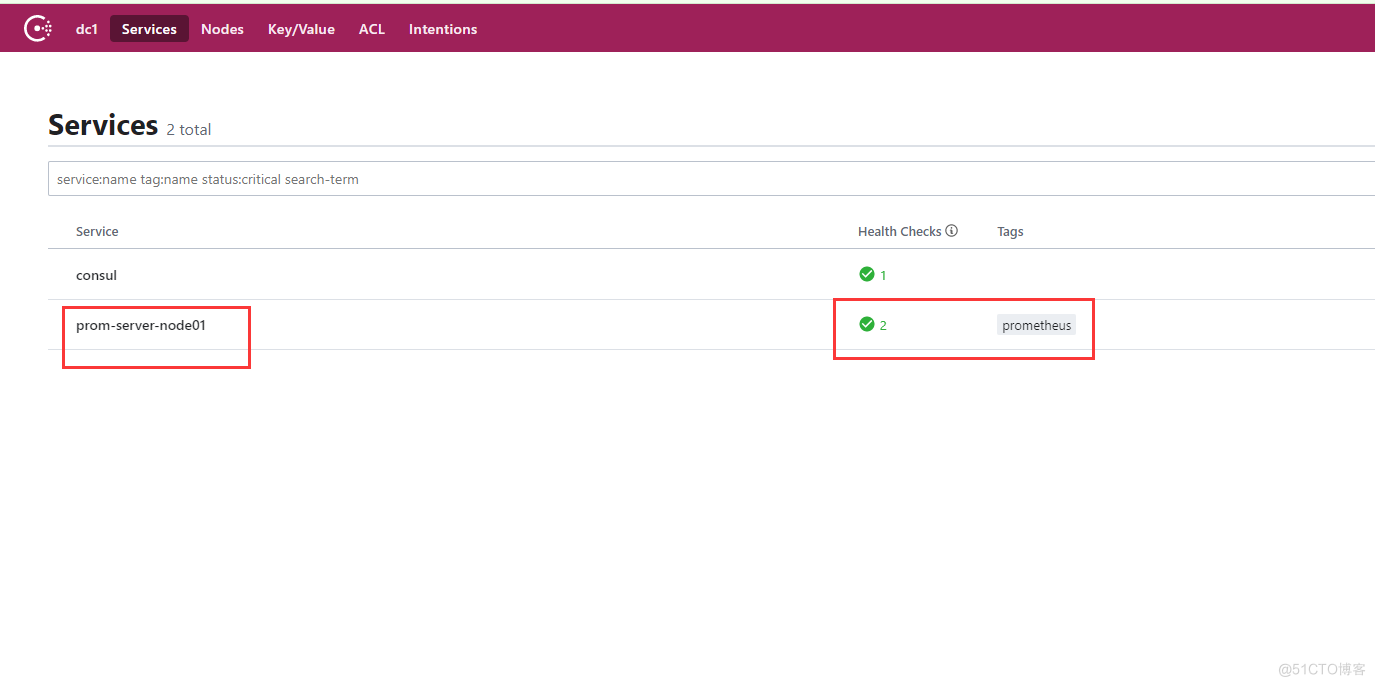 再用同样的配置格式,把node节点配置进去
再用同样的配置格式,把node节点配置进去
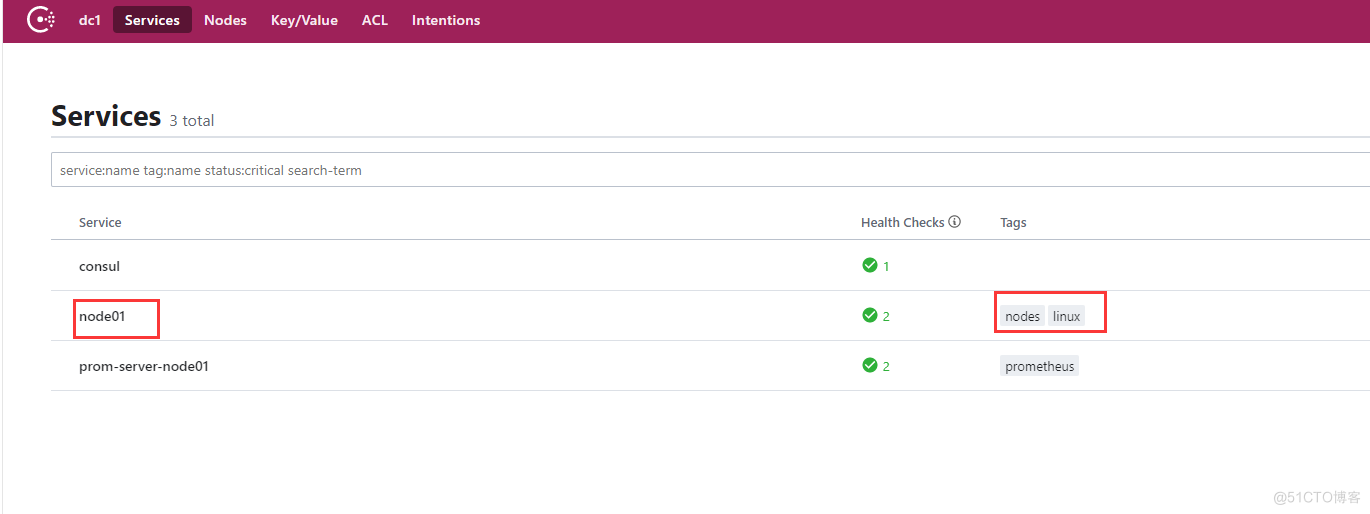
修改prometheus配置为通过concul发现服务
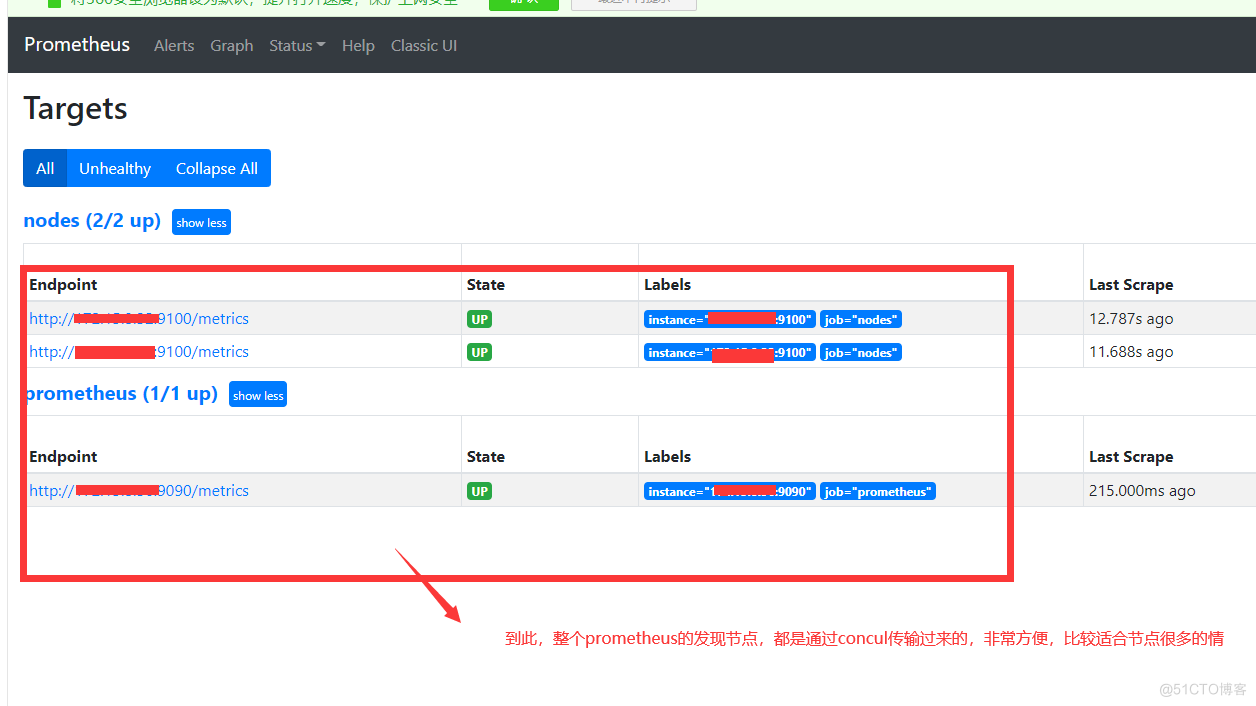
vim prometheus.yml scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. consul_sd_configs: #关键配置,设置通过consul服务发现 - server: "192.168.0.56:8500" tags: - "prometheus" #这里的标签值要对应之前concul的配置 refresh_interval: 2m # All nodes - job_name: 'nodes' consul_sd_configs: #关键配置,设置通过consul服务发现 - server: "192.168.0.56:8500" tags: - "nodes" #这里的标签值要对应之前concul的配置 refresh_interval: 2m这里我们只是说明prometheus是如何通过concul发现服务的原理,真是情况不会这样设置。如果这样设置。和之前的静态文件设置就没本质区别了,那有何必多了concul这一中间环节?生产环境,更多是使用脚本或者各类自动化运维工具,通过api来把节点注册到concul。
curl -X PUT -d '{"id": "node-exporter","name": "node02","address": "192.168.0.62","port": 9100,"tags": ["nodes", "linux"],"checks": [{"http": "http://192.168.0.62:9100/metrics", "interval": "5s"}]}' http://192.168.0.56:8500/v1/agent/service/register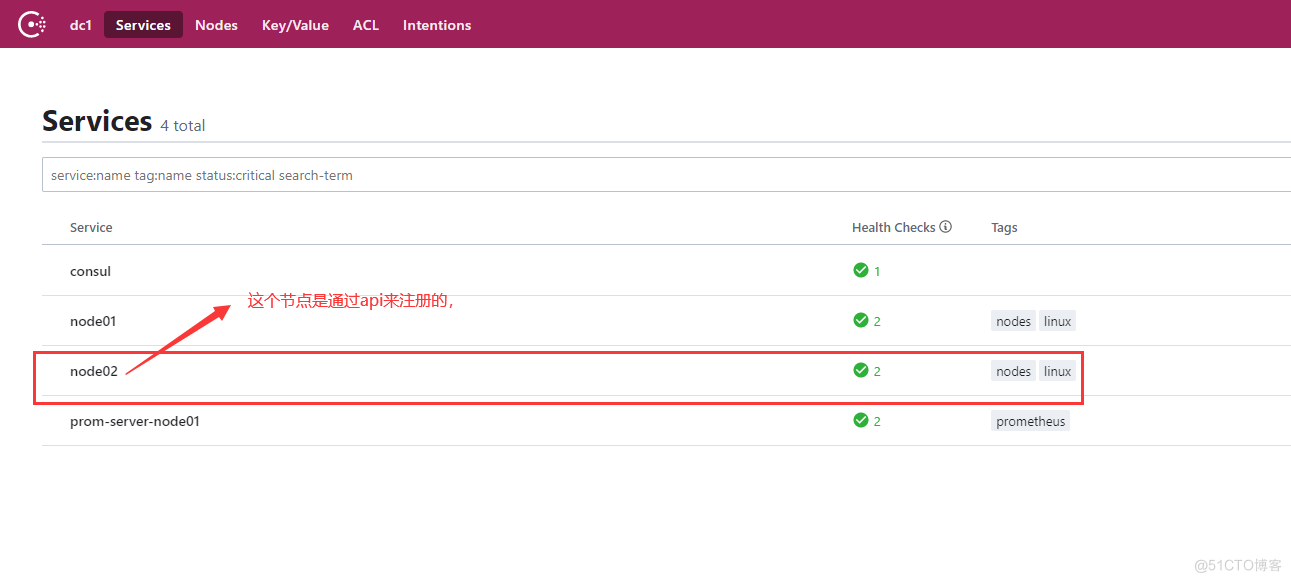
如果需要取消节点,可以使用consu命令来取消,下面取消之前通过api注册的node02节点:
./consul services deregister -id="node-exporter"最方便批量管理的还是使用api接口进行删除服务节点:
#node-exporter为服务实例ID PUT http://192.168.0.56:8500/v1/agent/service/deregister/node-exporter最后还是需要把concul设置为开机启动
vim /usr/lib/systemd/system/consul.service
[Unit] Description=consul-service After=network.target [Service] Type=forking user=root ExecStart=/root/consul/consul.start.sh ExecReload=/bin/kill -SIGHUP $MAINPID ExecStop=/bin/kill -SIGINT $MAINPID [Install] WantedBy=multi-user.target graphical.targetvim /root/consul/consul.start.sh
chmod u+x /root/consul/consul.start.sh #!/bin/bash nohup /root/consul/consul agent -server -bootstrap-expect 1 -bind=127.0.0.1 -ui -data-dir=/root/consul/data/ -log-file=/root/consul/log/consul_log-$(date +%Y-%m-%d--%H-%M) -config-dir=/root/consul/ -client=0.0.0.0重新加载配置systemctl daemon-reload设置开机自启动systemctl enable consul.serviceConsul 启动systemctl start consulConsul 停止systemctl stop consul上面创建开机自启动脚本实践的时候大家可能会发现 通过systemctl start /consul 无法启动问题,这时候可以通过status 来查询状态,命令如下systemctl status consul
总结
Prometheus serverd的数据抓取基于pull模型,所以它必须实现知道各target的位置,才能从相应的exporter中抓取数据。对于小型系统环境,通过使用静态配置文件方式指定target是最简单的配置方式;每个targets用一个网络ip+port进行标识;对于中大型的系统环境或具有较强动态性的云计算环境来说,静态配置显示难以适应;使用动态发现的方式如consul利用api+自动化脚本执行注册和删除节点更为适合;