这是一篇介绍监控系统Prometheus(普罗米修斯)的文章。希望通过这篇由浅入深的文章,能让你轻松的学会Prometheus监控系统。下一篇:Prometheus(普罗米修斯)监控系统(二)
一、监控系统
(一)、监控系统构成的4个功能组件:
1、指标数据采集2、置标数据存储3、置标数据趋势分析及可视化4、告警
(二)、监控体系(自底向上)
1、系统层监控
1)系统监控:cpu、load、memory、swap、diskio、processes、kernelParameters ...2)网络监控:网络设备、工作负载、网络延迟、丢包率 ...##
2、中间件及基础设施类系统监控
1)消息中间件:kafka、rocketMQ、Rabbitmq等2)web服务容器:nginx、tomcat、apache等3)数据库及缓存系统:mysql、Psql、mogodb、ES、redis等。4)数据库连接池:ShardingSpere等5)存储系统:ceph等
3、应用层监控
用于检测应用程序代码的状态和性能
4、业务层监控
业务接口:登录数、注册、搜索量等
(三)、三个监控方法论
1、黄金指标
源于google的SRE一书。(适用于应用及服务监控)1)延迟服务请求所需要的时长,例如http请求的平均时长2)流量衡量服务的容量需求,例如每秒处理的http请求数量或者其他事务数量。3)错误请求失败的情况,例如网站返回错误代码。4)饱和度衡量资源的使用情况,用于展示服务器或应用程序资源,例如cpu、内存、IO、网络的使用量
2、Netflix的USE方法
主要用于分析系统性能问题 (适用于主机、服务器指标监控)1)使用率,关注系统资源的使用情况,包括不限于cpu、内存、io、网络等,100%使用率通常是系统性能瓶颈的标志。2)饱和度3)错误
3、red方法
基于黄金指标,结合kubernetes容器实践,适合云原生应用和微服务架构应用。red方法主要关注以下3种关键指标:1)rate :每秒接收到的请求数2)errors:每秒失败的请求数3)duration:每个请求所花费的时间
二、Prometheus快速入门
概念
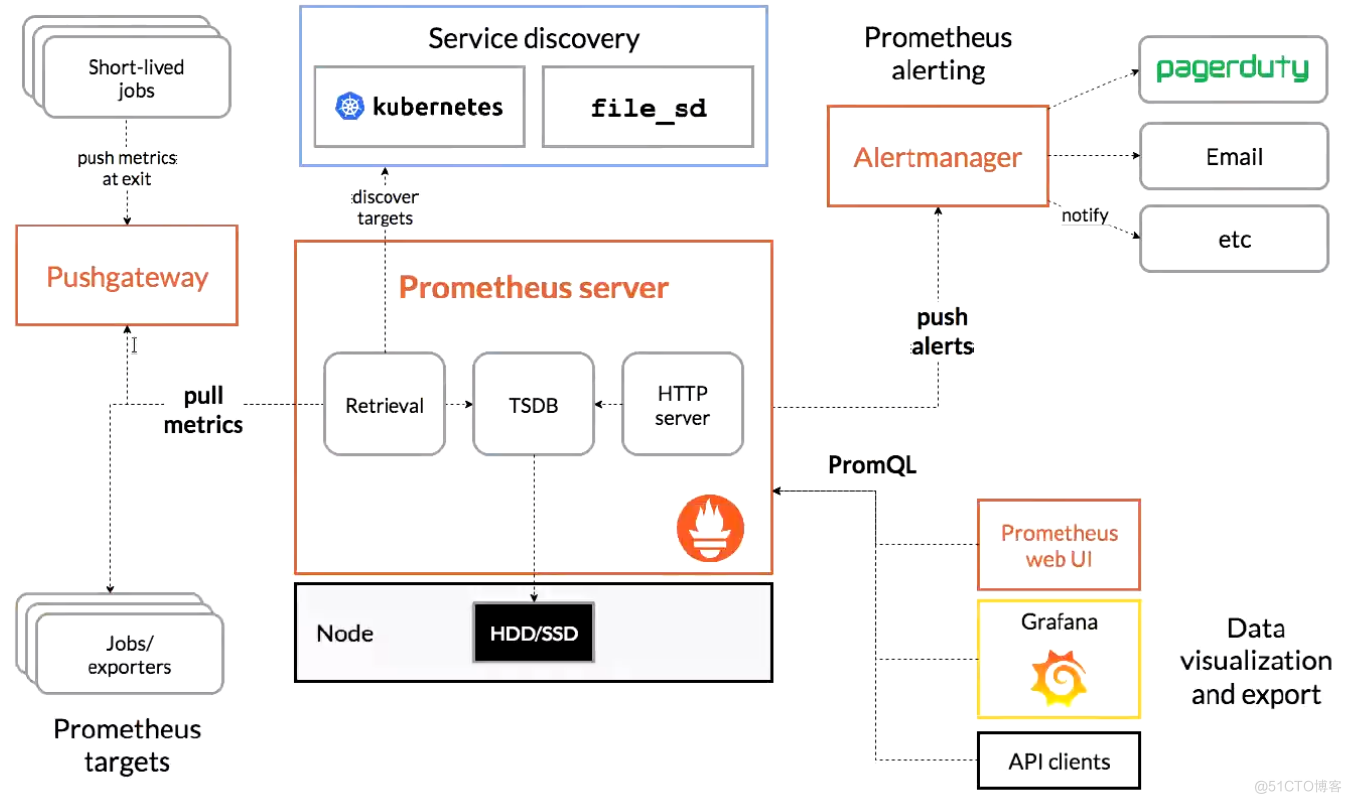
- 首先,Prometheus是一款时序(time serier)数据库,但它的功能却并不止于TSDB,而是一款设计用于进行目标(Target)监控的关键组件;集合生态系统内的其他组件,例如pushGateway、Altermanager和Grafana等,可构成一个完整的IT监控系统。
- 时序数据,是在一段时间内通过重复测量而获得的观察值的集合;将这些观测值绘制于图形之上,有一个数据轴和时间轴。我们服务器的指标数据、应用程序的性能检测数据、网络数据等也都是时序数据。基于http/https,从配置文件中指定的网络端点(客户端)上周期性获取指标数据。
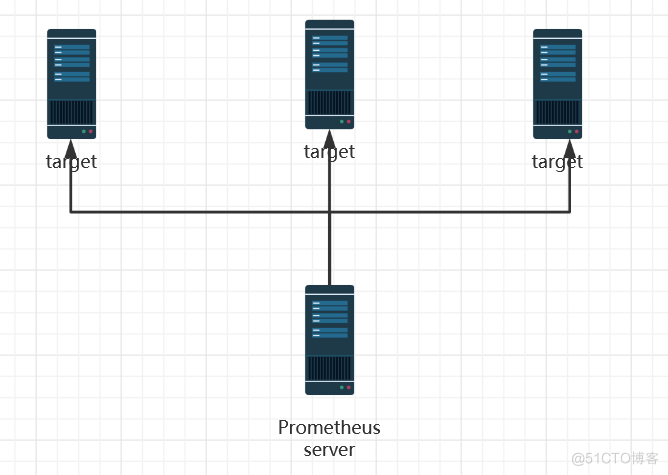
- 工作模型是基于pull/push中的pull(拉取)。
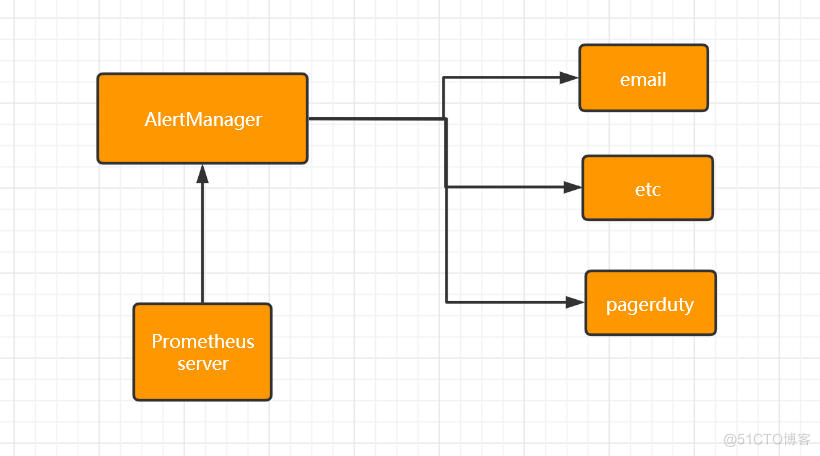
Prometheus支持通过三种类型的途径从目标上抓取(scrape)指标数据;管理告警,主要是负责实现报警功能。在 Prometheus Server 中支持基于 PromQL 创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由 AlertManager 进行管理。
在 AlertManager 中我们可以与邮件,Slack 等等内置的通知方式进行集成,也可以通过 Webhook 自定义告警处理方式。AlertManager 即 Prometheus 体系中的告警处理中心。1. exporters主要用来采集数据,并通过 HTTP 服务的形式暴露给 Prometheus Server,Prometheus Server 通过访问该 Exporter 提供的接口,即可获取到需要采集的监控数据。常见的Exporter有很多,例如node_exporter、mysqld_exporter、haproxy_exporter 等,支持如 HAProxy、StatsD、Graphite、Redis 此类的服务监控;
pull and push
- Prometheus同其他时序数据库相比有一个非常典型的特性:它是主动从各TARGET(客户端)上拉取(pull)数据,而非等待监控端的推送(push)
- pull的优势在于,集中控制有利于配置集在Prometheus server上完成,包括指标和采集的速率。
- Prometheus的目标是收集在TARGET上预先完成聚合的聚合性数据,而非事件性驱动的存储系统。
Prometheus 的生态组件
-
Prometheus ServerPrometheus组件中的核心部分,收集和存储时间序列数据,提供PromQL查询语言的支持。内置的 Express Browser UI,通过这个 UI 可以直接通过 PromQL 实现数据的查询以及可视化。
-
Exporters将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可以获取到需要采集的监控数据
-
PushGateway主要是实现接收由 Client push 过来的指标数据,在指定的时间间隔,由主程序来抓取。由于 Prometheus 数据采集基于 Pull 模型进行设计,因此在网络环境的配置上必须要让 Prometheus Server 能够直接与 Exporter 进行通信。当这种网络需求无法直接满足时,就可以利用 PushGateway 来进行中转。可以通过 PushGateway 将内部网络的监控数据主动 Push 到 Gateway 当中。而 Prometheus Server 则可以采用同样 Pull 的方式从 PushGateway 中获取到监控数据。
- Alertmanager管理告警,主要是负责实现报警功能。在 Prometheus Server 中支持基于 PromQL 创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由 AlertManager 进行管理。在 AlertManager 中我们可以与邮件,Slack 等等内置的通知方式进行集成,也可以通过 Webhook 自定义告警处理方式。AlertManager 即 Prometheus 体系中的告警处理中心。
Prometheus 数据模型 (*重点,必须理解掌握)
Prometheus 仅用于以“键值”(key)形式储存时序式的聚合数,不支持存储文本信息;
- 其中的“键”称为指标,它通常意味着cpu速率、内存使用率、负载等;
- 同一指标可能会适配到多个目标,比如cpu使用率这个指标,我们需要对100台服务器设备进行使用。所以它使用“标签”(labels)作为元数据,从而为指标添加更多的信息描述;
- 这些标签可以作为过滤器进行指标过滤及运算。光看上面的文字描述很难理解,具体的看如下数据展示描述,理解更为简单:
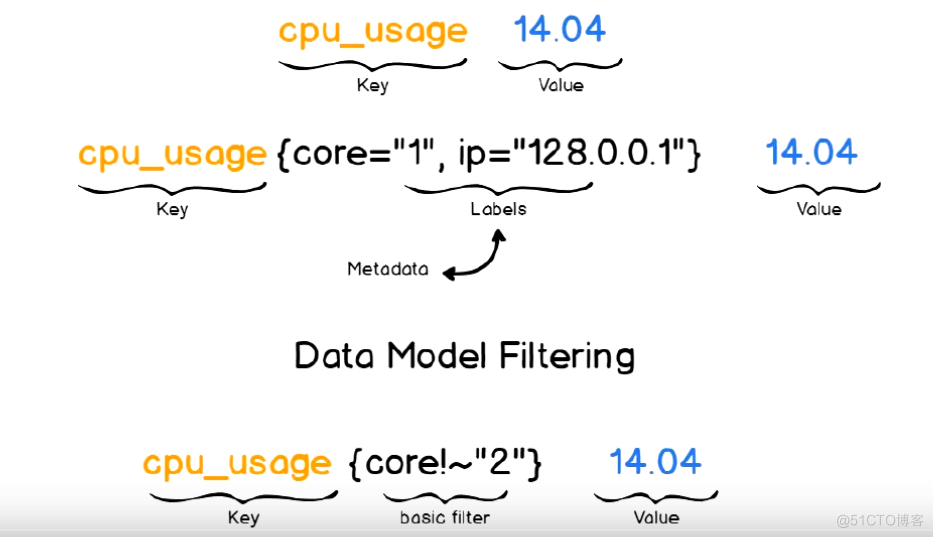 如上图中,cpu_usage{core="1",ip="128.0.0.1"} 14.04 cpu_usage为指标名称,{core="1",ip="128.0.0.1"}为标签(标签内的条件可以多个,用逗号分隔),14.04 为 表达式返回的值
如上图中,cpu_usage{core="1",ip="128.0.0.1"} 14.04 cpu_usage为指标名称,{core="1",ip="128.0.0.1"}为标签(标签内的条件可以多个,用逗号分隔),14.04 为 表达式返回的值
指标类型 (metric type)
Prometheus 使用4种方法来描述监视的指标
- Counter 计数器,用于保存计数型数据,如网站访问量等。
- Gauge 仪表盘,用于存储有着起伏特征的指标数据,如空间空闲大小等。
- Histogram直方图,在一段时间范围内对数据进行采样,并将其计入可配置的存储中,后续可通过制定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图。
- Summary摘要,Histogram的扩展类型,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间计算
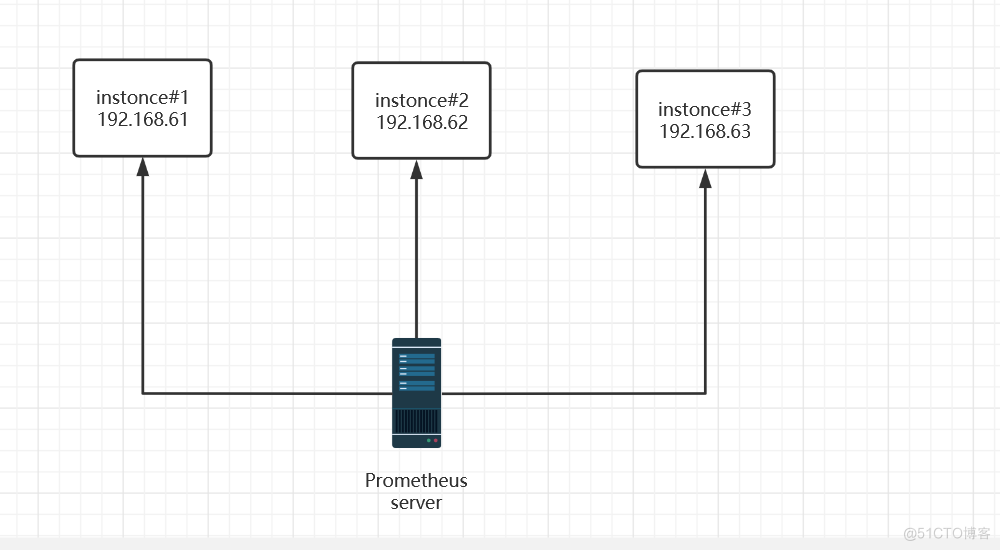
作业(job)和实例(Instance)
-
Instance实例可以简单的理解为就是一个target,网络客户端,实际上在多核心的服务器上,一个instance就代表一个cpu核心;
node_cpu_seconds_total{cpu="0",instance="192.168.0.61:9100",job="prometheus",mode="idle"} 12880841.65 node_cpu_seconds_total{cpu="1",instance="192.168.0.61:9100",job="prometheus",mode="idle"} 12808726.3 node_cpu_seconds_total{cpu="2",instance="192.168.0.61:9100",job="prometheus",mode="idle"} 12857636.16 node_cpu_seconds_total{cpu="3",instance="192.168.0.61:9100",job="prometheus",mode="idle"} 12781748.83 - job通常,具有类似功能的Instance的集合称为一个job。例如一个nginx集群中所有的nginx进程。
 ::: hljs-center
::: hljs-center
cpu_usage{job="1",instance="192.168.0.61"} 15.8cpu_usage{job="1",instance="192.168.0.61"} 12.9cpu_usage{job="1",instance="192.168.0.61"} 16.5
:::
PromQL
- 内置的数据查询语言,支持用户进行实时的数据查询及聚合操作
- PromQL支持处理两种向量,并内置提供了一组用于数据处理的函数 即使向量:最近一次的时间戳上跟踪的数据指标时间范围向量:指定范围时间内的所有时间戳上的数指标
Alerts
- 抓取到异常值后,Prometheus 支持通过报警(alert)机制向用户发送反馈,以便用户能够及时采取应对措施。
- Prometheus server 仅负责生成报警指示,具体的报警行为由另一个独立的应用程序AlertManager负责。报警指示由Prometheus server 基于用户提供的“报警规则”周期性计算生成;AlertManager接收到Prometheus server发来的报警指示后,基于用户定义的报警路由(route)向接收人(receivers)发送报警信息;
三、实战演练部署Prometheus
实战环境
- prometheus server服务器 192.168.0.63
- 被监控的客户端 192.168.0.61
下载二进制源码包
官方下载地址。https://prometheus.io/download/注意选择对应的操作系统和芯片架构类型需要下载的是:
- prometheus 服务端server服务器上部署 wget https://github.com/prometheus/prometheus/releases/download/v2.28.1/prometheus-2.28.1.linux-amd64.tar.gz
- node_exporter 客户端服务器上部署
https://github.com/prometheus/node_exporter/releases/download/v1.2.0/node_exporter-1.2.0.linux-amd64.tar.gz
部署
- 分别解压prometheus、node_exporter的压缩包。
tar -zxvf prometheus-2.28.1.linux-amd64.tar.gz
tar -zxvf node_exporter-1.2.0.linux-amd64.tar.gz
客户端node_exporter安装配置192.168.0.61(62):
cp -R node_exporter-1.2.0.linux-amd64 /usr/local/node_exporter cd /usr/local/node_exporter touch /usr/lib/systemd/system/node_exporter.service vim /usr/lib/systemd/system/node_exporter.service在node_exporter.service中加入如下代码:
[Unit] Description=node_exporter After=network.target [Service] Type=simple User=root ExecStart=/usr/local/node_exporter/node_exporter Restart=on-failure [Install] WantedBy=multi-user.target启动 node_exporter 服务并设置开机启动
systemctl daemon-reload systemctl enable node_exporter.service systemctl start node_exporter.service systemctl status node_exporter.service注意:检测端口9100是否监听,监听则客户端node_exporter启动成功,node_exporter启动成功后, 你就可以通过如下api看到你的监控数据了http://192.168.0.61:9100/metrics
服务器端192.168.0.63部署:
由于Prometheus是go语言写的,所以不需要编译,安装的过程非常简单,仅需要解压然后运行。
cp -R prometheus-2.28.1.linux-amd64 /usr/local/prometheuscd cd /usr/local/prometheuscd vim prometheus.yml 在最后面增加如下配置 #测试,增加新job,命名为nodes,这里需要特别注意,一定要严格注意间距和格式,建议参考范例所示的格式,我在第一次部署的时候,曾因为少了一个空格导致启动失败。 - job_name: 'nodes' static_configs: - targets: ['192.168.0.61:9100','192.168.0.62:9100']访问192.168.0.63:9090/classic/targets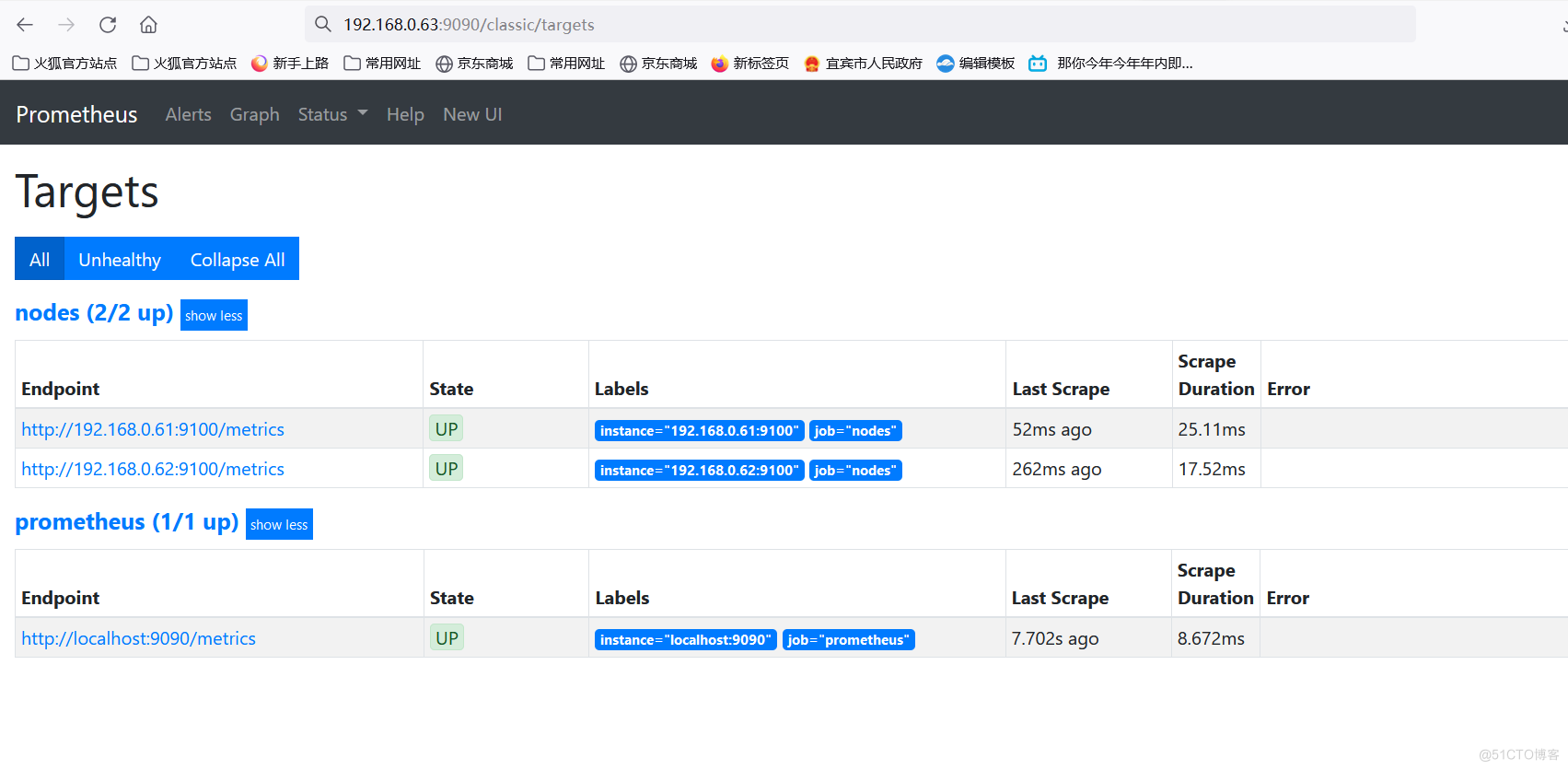
- 设置prometheus系统服务,并配置开机启动touch /usr/lib/systemd/system/prometheus.servicevim /usr/lib/systemd/system/prometheus.service将如下配置写入prometheus.servie [Unit] Description=Prometheus Documentation=https://prometheus.io/ After=network.target
[Service]Type=simpleUser=root
--storage.tsdb.path是可选项,默认数据目录在运行目录的./dada目录中
ExecStart=/usr/local/prometheus/prometheus --conf由于Prometheus是go语言写的,所以不需要编译,安装的过程非常简单,仅需要解压然后运行。ig.file=/usr/local/prometheus/prometheus.yml --web.enable-lifecycle --storage.tsdb.path=/usr/local/prometheus/data --storage.tsdb.retention=60dRestart=on-failure
[Install]WantedBy=multi-user.target
- Prometheus启动参数说明 --config.file -- 指明prometheus的配置文件路径 --web.enable-lifecycle -- 指明prometheus配置更改后可以进行热加载 --storage.tsdb.path -- 指明监控数据存储路径 --storage.tsdb.retention --指明数据保留时间 - 设置开机启动 ```bash systemctl daemon-reload systemctl enable prometheus.service systemctl status prometheus.service systemctl start prometheus.service注意: prometheus在2.0之后默认的热加载配置没有开启, 配置修改后, 需要重启prometheus server才能生效, 这对于生产环境的监控是不可容忍的, 所以我们需要开启prometheus server的配置热加载功能.
在启动prometheus时加上参数 web.enable-lifecycle , 可以启用配置的热加载, 配置修改后, 热加载配置:
curl -X POST http://localhost:9090/-/reload数据展示Grafana安装配置
- 下载地址: https://grafana.com/grafana/download wget https://dl.grafana.com/oss/release/grafana-8.0.6-1.x86_64.rpm yum install grafana-8.0.6-1.x86_64.rpm systemctl start grafana-server systemctl status grafana-server
-
默认端口为3000,输入http://192.168.0.63:3000/访问granafa首次登录账户名和密码admin/admin,可以修改

-
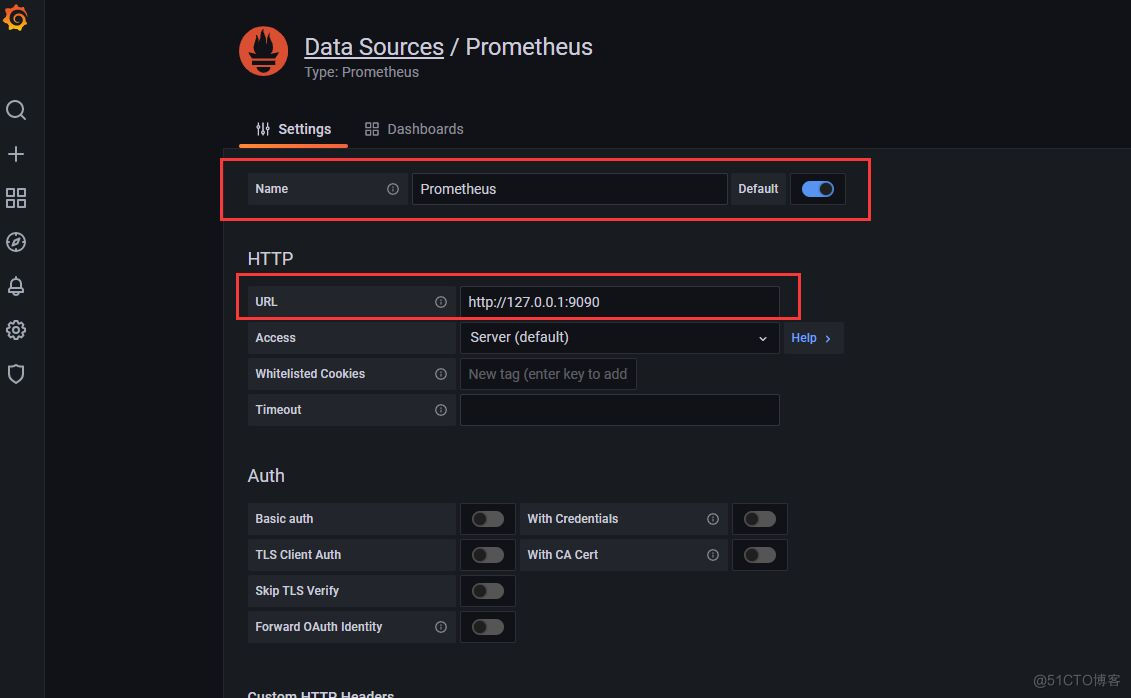
配置数据源Data sources->Add data source -> Prometheus,输入prometheus数据源的信息,主要是输入name和url
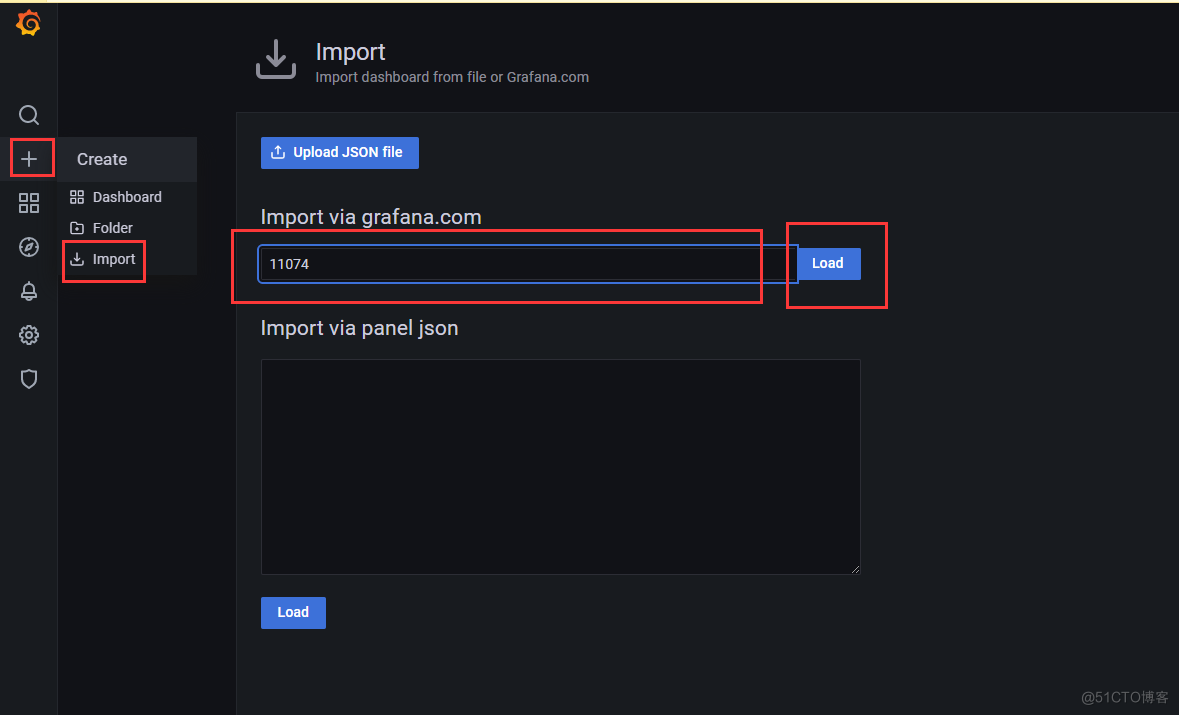
- Grafana图形显示Linux硬件信息Grafana官方提供模板地址:https://grafana.com/grafana/dashboards本次要导入的模板:https://grafana.com/grafana/dashboards/11074
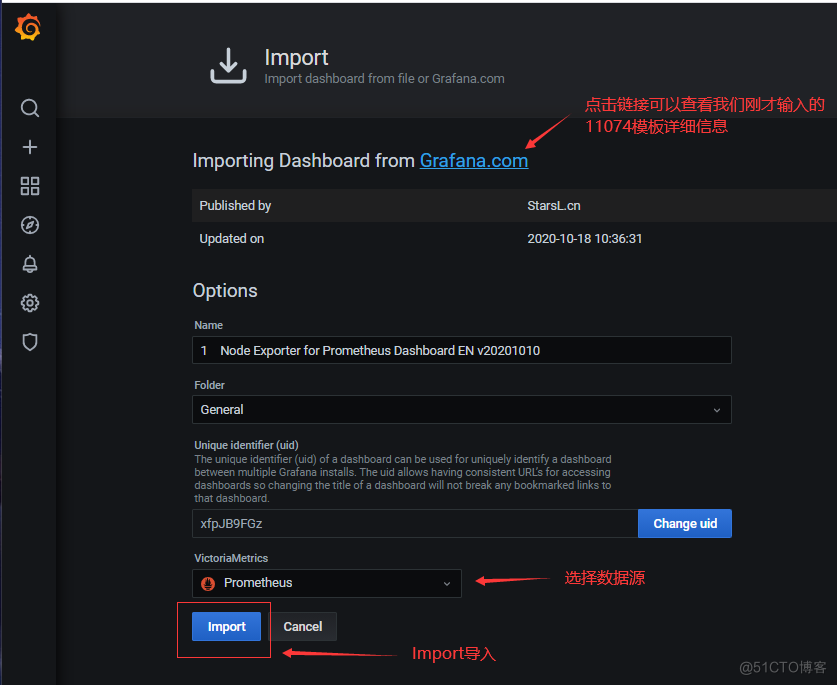
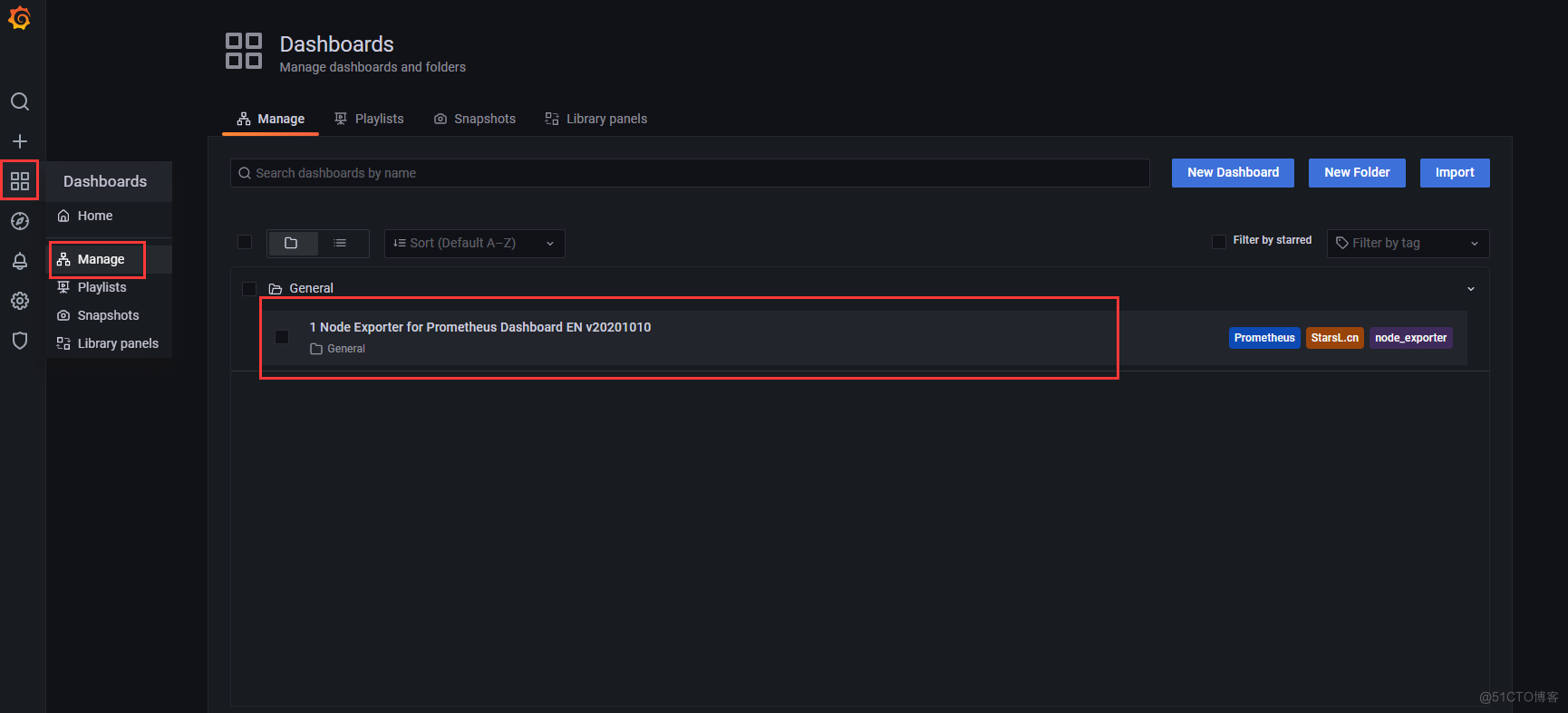
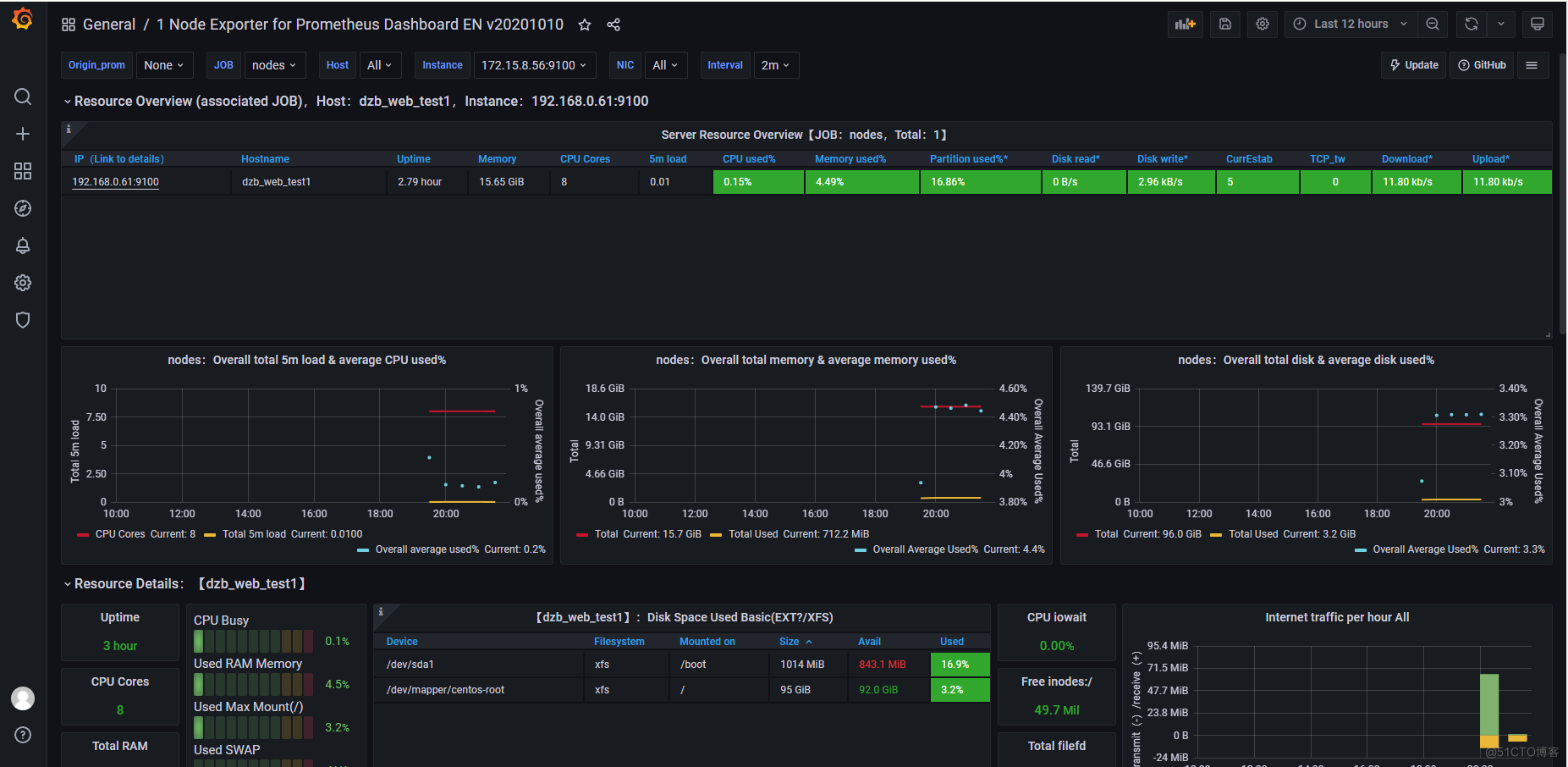
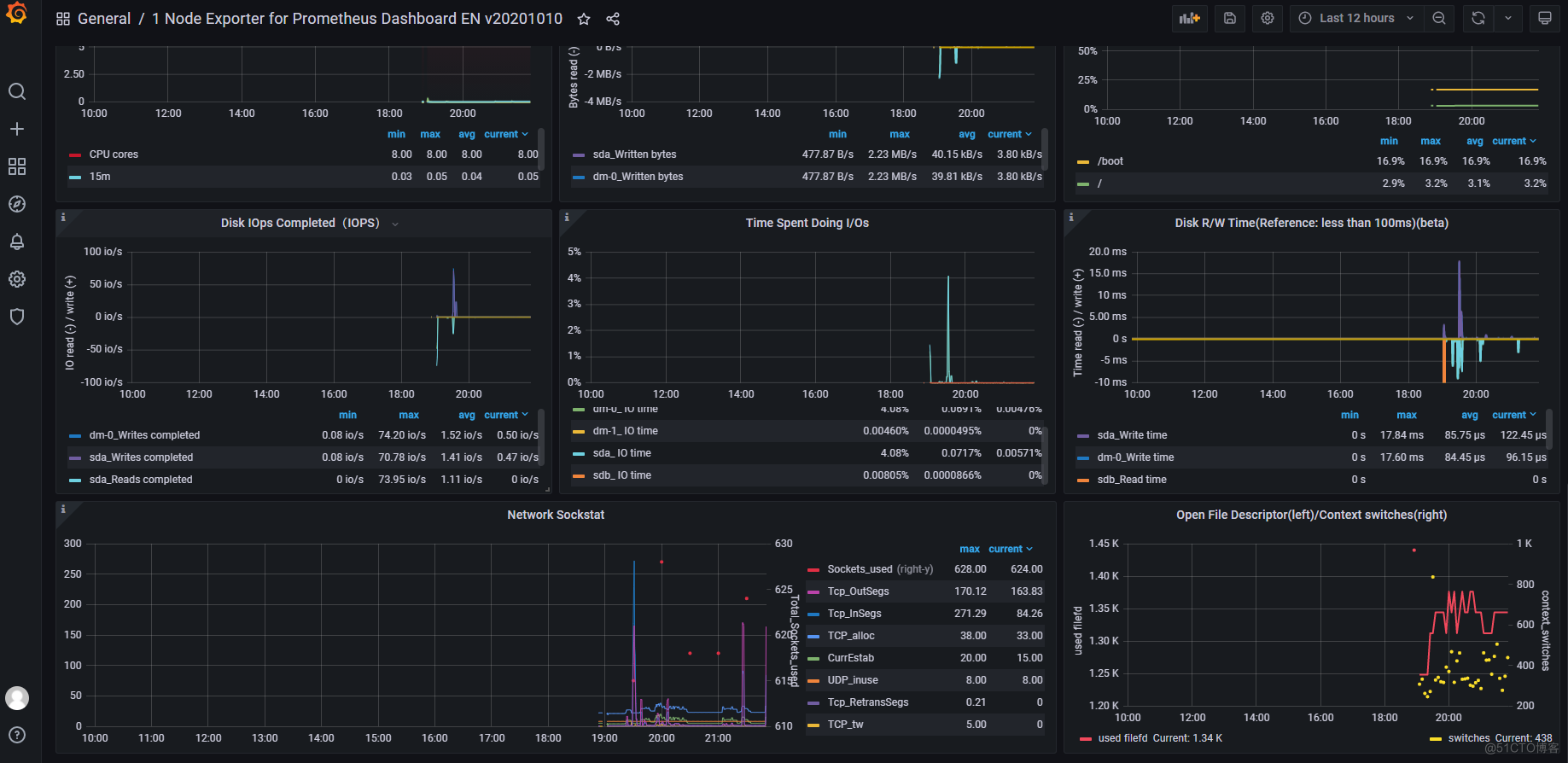
四、关键指标讲解
cpu饱和度
跟踪cpu的平均负载就能获取到相关主机的cpu饱和度,实际上它是将主机上的cpu核心数考虑在内的一段时间内的平均运行队列长度
- 平均负载少于cpu的核心数是正常状况,而长时间内超过cpu核心数则表示cpu已然饱和;
- node_load1 > on(instance) 2 * count
内存使用率
- node_exporter 暴露了多个以node_memory为前缀的指标,我们重点关注如下几个 node_memory_MemTotal_bytes node_memory_MemFree_bytes node_memory_Buffers_bytes node_memory_Cached_bytes
- 计算使用率可用空间:
node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes
已用空间:
node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)使用率 = 已用空间除以总空间
时间序列
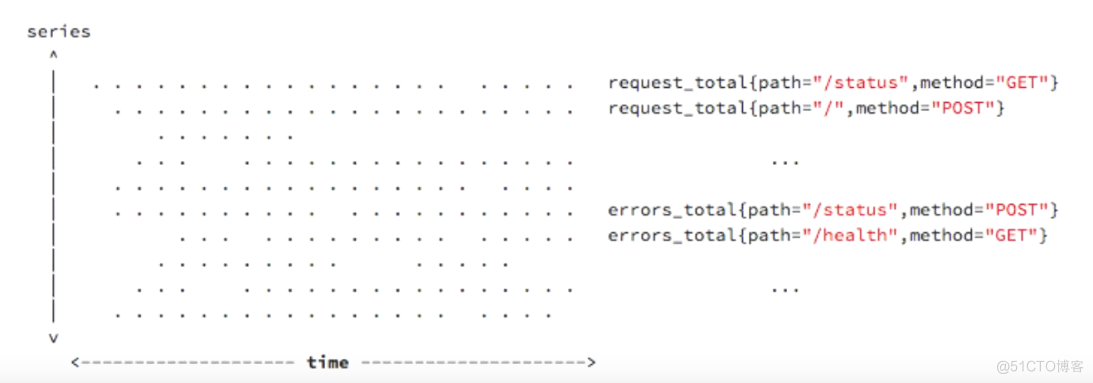
时间序列 数据
- 按照时间顺序记录系统、设备状态变化的数据,每个数据称为一个样本
- 数据采集以特定的时间周期进行,因而,随着时间,将这些样本记录下来。可以生成离散的样本数据序列;
- 该序列也称为向量(vector);而将多个序列放在同一个坐标系内,以时间为横轴,以序列为纵轴,形成一个由数据点组成的矩阵
五、PromQL基础
promQL介绍
promQL是prometheus server 内置数据查询语言
- promQL使用表达式(expression)来表述查询需求
- 根据其使用的指标和标签,以及时间范围,表达式的查询请求可灵活地覆盖在一个或多个时间序列的一定范围内的样本之上。
promQL的数据类型
表达式支持4种数据类型
- 即时向量特定或全部的时间序列集合上,具有相同时间戳的一组样本值
- 范围向量特定或全部的时间序列集合上,在指定的同一时间范围内的所有样本值
- 标量一个浮点型的数据值
- 字符串支持使用单引号、双引号或反引号进行引用,但反引号中不会对转义字符进行转义
时间序列选择器(time series selectors)
promQL的查询操作需要针对有限个时间序列上的样本数据进行
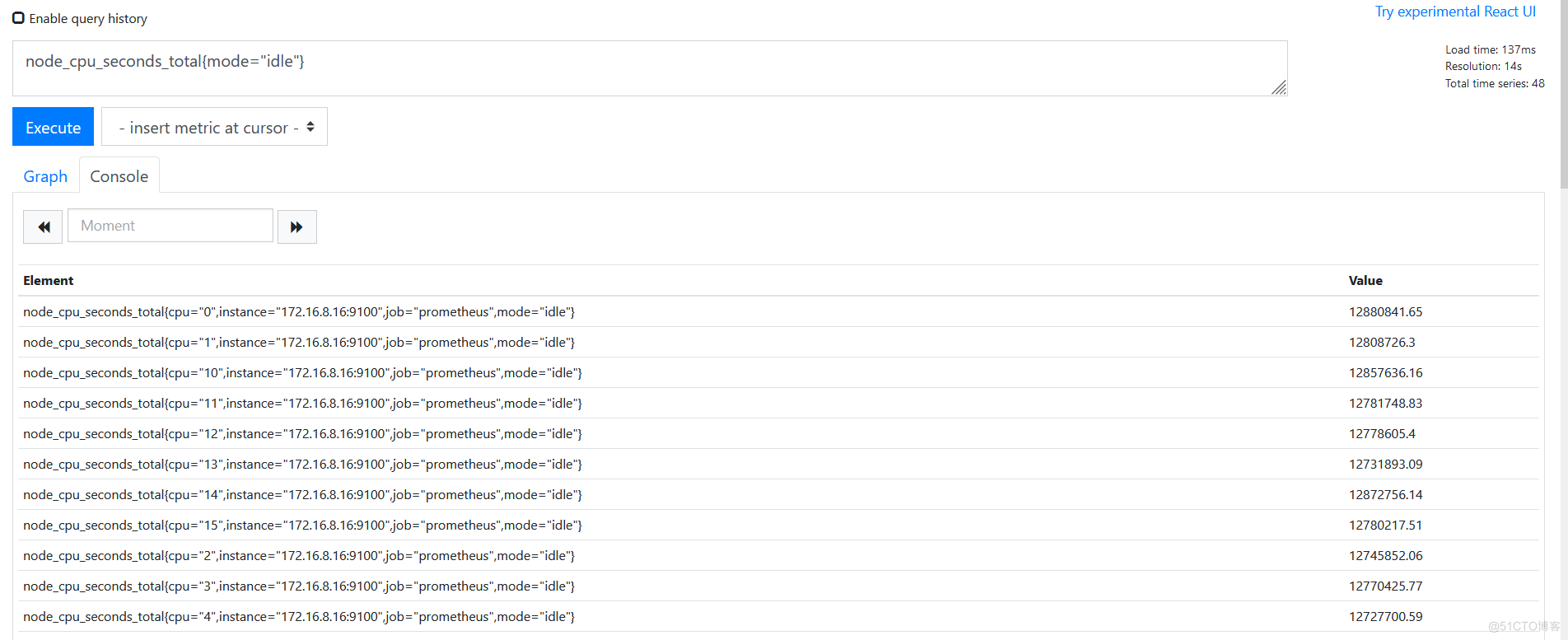
- 即时向量选择器返回时间序列上给定时间戳上的样本
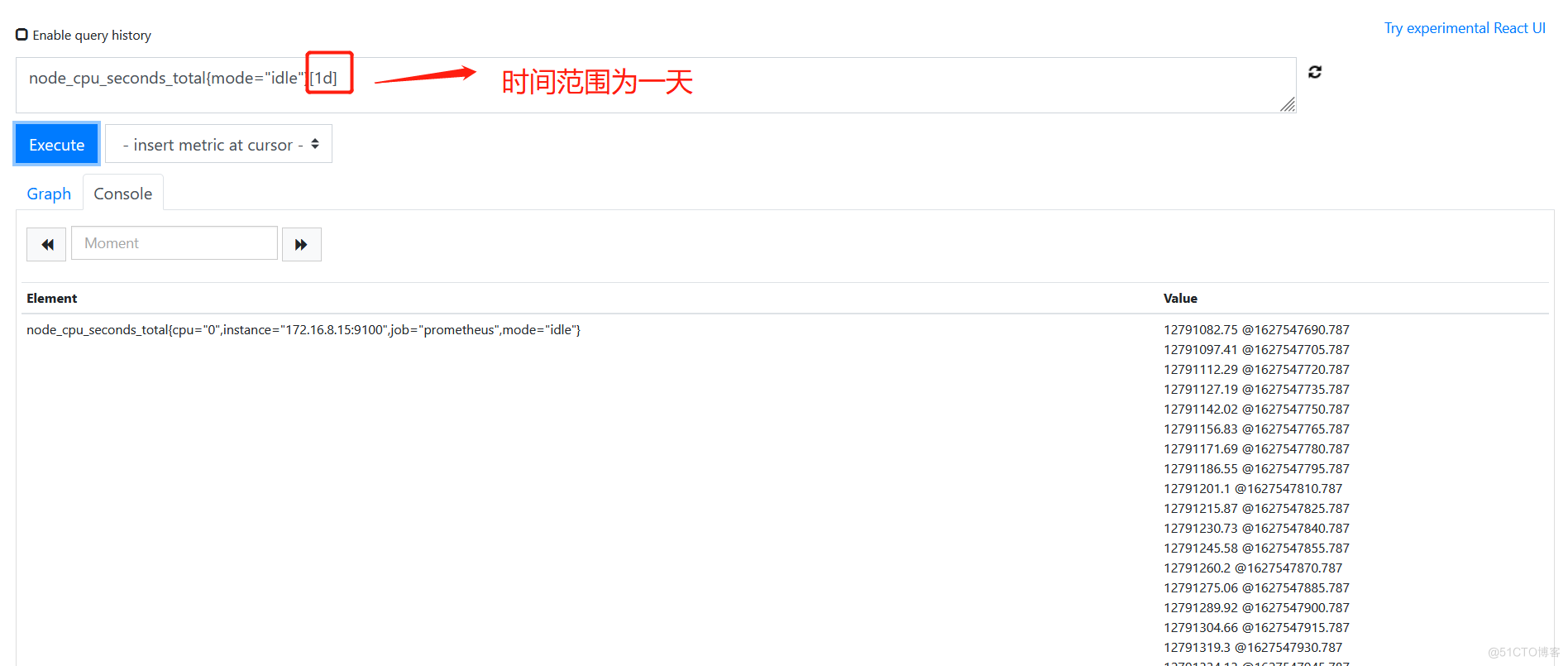
- 范围向量选择器返回时间序列上给定时间范围上的样本
向量表达式使用要点
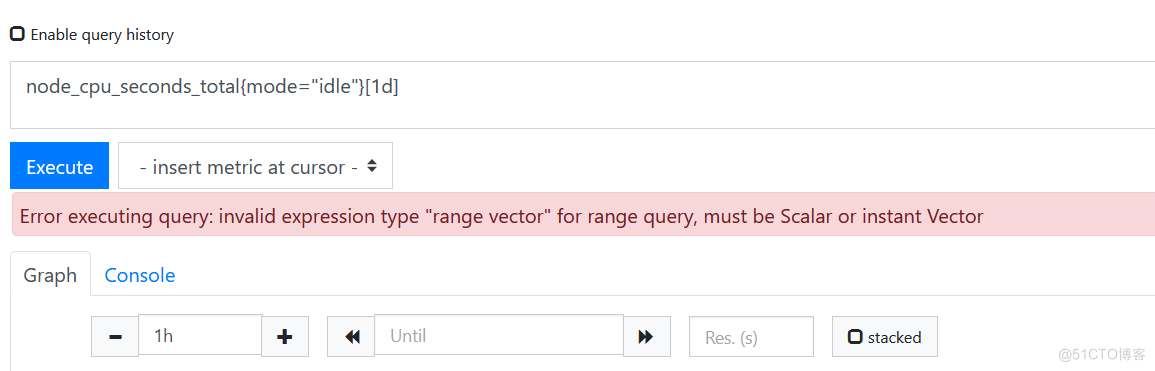
- 表达式的返回值类型是即时向量、范围向量、标量、字符4种数据类型中的一种,但是有些使用场景要求表达式返回值必须满足特定的条件,例如:需要把返回值绘制成图形的时候,就必须为即时向量。范围向量表达式返回值不能直接应用图表显示,范围向量选择总是结合速率类的函数rate一同使用。以下是直接用于图表会报错以及结合速率类rate使用就可以:
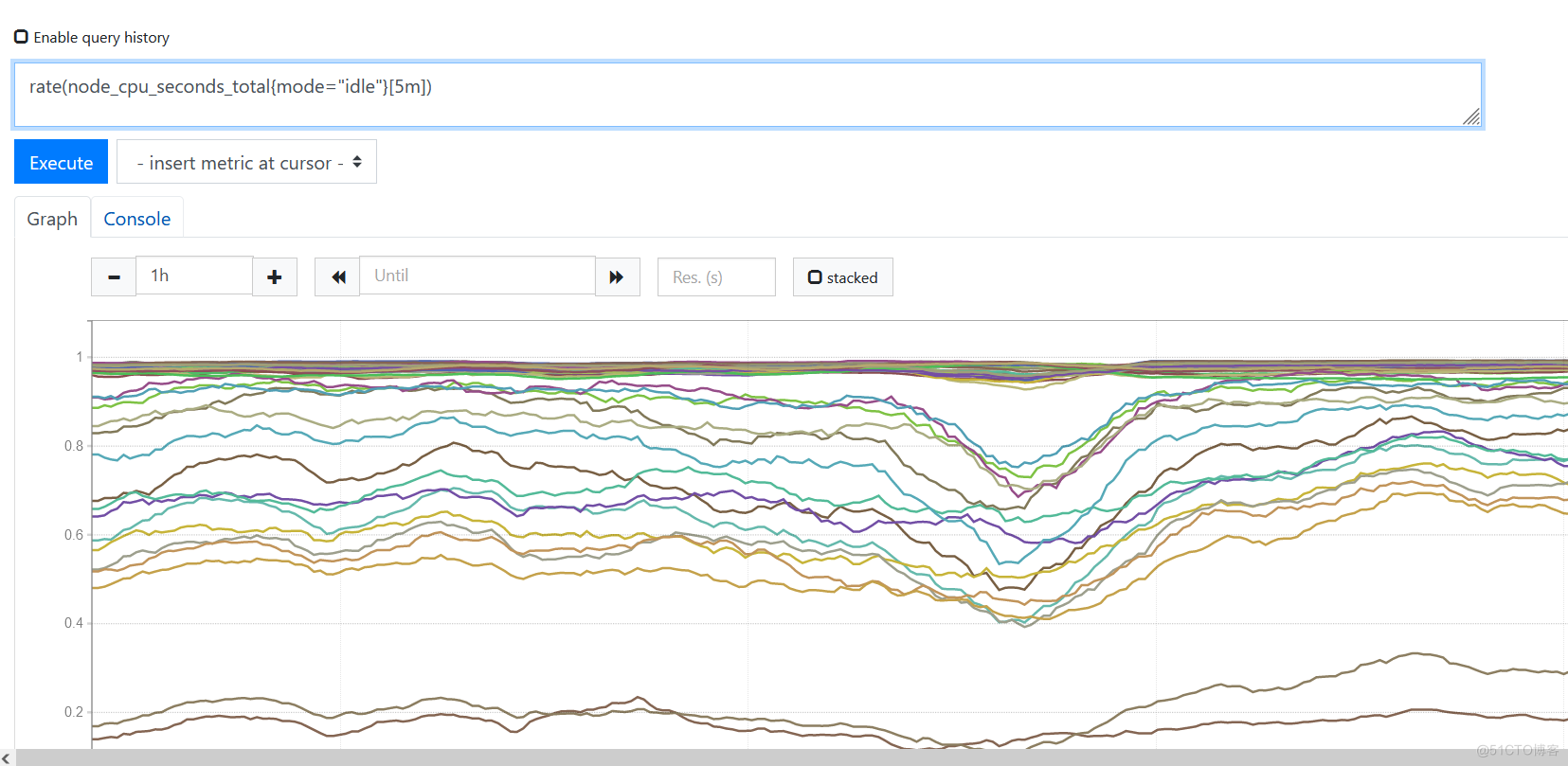
即时向量选择器
即时向量选择器由两部分组成
- 指标名称用于限定特定指标下的时间序列,负责过滤指标;
- 匹配器(Matcher)标签选择器,用于过滤时间序列上的标签;定义在{}中,可选;既定义即时向量选择器时,以上两部分至少给出一个,于是,这存在以下三种组合;
- 仅给定指标名称例如:http_requests_total
- 仅给定匹配器例如:{job=".*",method="get"}
- 指标名称和匹配器组合例如:http_requests_total{method="get"}
匹配器(Matcher)
匹配器用于定义标签过滤条件,目前支持如下4种匹配操作:
- = :选择正好相等的字符串标签
- != :选择不相等的字符串标签
- =~ :选择匹配正则表达式的标签(或子标签)
- !~ :选择不匹配正则表达式的标签(或子标签)注意事项:
- 匹配到空标签值的匹配器时,所有未定义该标签的时间序列同样符合条件;例如:http_requests_total{env=“”},则该指标名称上的所有未使用该标签env的时间序列也符合条件,比如:http_requests_total{method="get"}
- 正则表达式执行完全锚定机制,它需要匹配指定的标签的整个值
- 向量选择器至少要包含一个指标名称,或者至少有一个不会匹配到空字符串的匹配器;例如: {job=""}为非法的选择器
- 使用“name”作为标签名称,还能够对指标名称进行过滤;
- 例如:{name=~"httprequests.*"}能够匹配所有以“httprequests”为前缀的所有指标;
总结
这篇文章介绍了Prometheus入门配置以及基础的知识。后面的篇章再来介绍Prometheus更深入的一些的监控功能。