----出自《分布式监控平台Centreon最佳实践》
Proxmox VE(Proxmox Virtual Environment)简称PVE,是一款能与VMware相匹敌的超融合虚拟化平台,其去中心化的特性使整个平台具备更高的可用性,因为没有控制中心,集群中的任意节点故障,都不会导致服务不可用。Proxmox VE 6以后的版本,几乎所有的管控操作,都可以在Web管理界面轻松完成,真是系统管理员的福音啊。
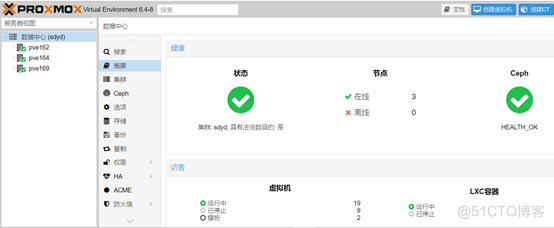
Proxmox VE正常运行主要涉及corosync服务、pveproxy服务、ceph健康状态,只要这三个条件同时满足,我们就可以大致认为Proxmox VE是正常的。
- corosync服务,在系统中有且只有一个进程。
root@pve10:/usr/local/nrpe/libexec#
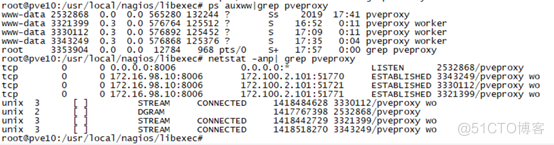
ps auxww|grep corosync root 2108 1.2 0.0 197332 72504 ? SLsl 2018 17614:34 /usr/sbin/corosync -f- pveproxy服务,此服务为Proxmox VE web管理后台。在系统中有多个进程,同时关联tcp监听端口8006。
- ceph健康状态,在命令行执行“ceph health detail” ,以其输出了解其运行是否正常。

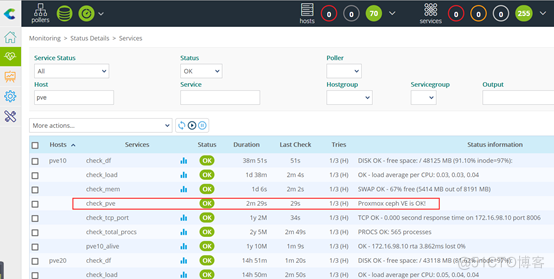
根据上述三个条件,在目录/usr/local/nrpe/libexec下撰写NRPE插件脚本check_pve,其内容如下:
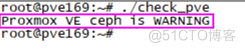
#!/bin/bash #Writed by sery(vx:formyz) in 2021-07-01 source /etc/profile is_corosync=`ps aux| grep corosync|grep -v grep|wc -l` pve_tcp8006=`netstat -anp| grep pveproxy | grep tcp| wc -l` ceph_health=`ceph health detail| grep HEALTH|awk '{print $1}'` if [[ $is_corosync == 1 ]] && [[ $pve_tcp8006 -ge 1 ]] then if [[ $ceph_health = "HEALTH_OK" ]] then echo "Proxmox ceph VE is OK!" exit 0 elif [[ $ceph_health = "HEALTH_WARN" ]] then echo "Proxmox VE ceph is WARNING" exit 1 else echo "Proxmox Ve is CRITICAL" exit 2 fi fi在一个运行正常的Proxmox VE集群是运行插件脚本check_pve,其输出结果如下:

手边正好有一个存在故障的Proxmox VE集群,其它正常而ceph异常。
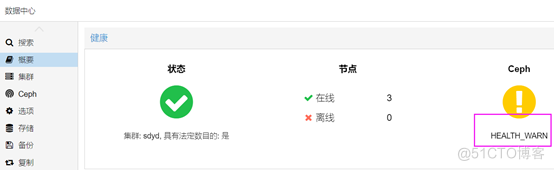
把脚本check_pve复制到该集群的某个系统,运行脚本,其输出如下:
NRPE配置文件nrpe.cfg新增一行文本“command[check_pve]=/usr/local/nrpe/libexec/check_pve”,重启NRPE服务后,从监控服务器Centreon Central用插件check_nrpe进行验证,指令如下:
libexec/check_nrpe -H 172.16.98.10 -c check_pve如果输出结果为“NRPE: Unable to read output”,表明nagios账号权限不足,不能读取ceph服务的相关配置。因此。需要用sudo来给nagios账号进行合理的授权,然后在监控服务器Centreon Central再执行上述指令。

按照前边添加负载均衡监控项的方法,把check_pve在Centreon Central的web管理后台给添加上。
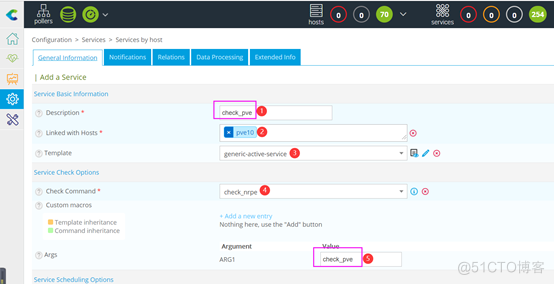
输出Centreon Central Poller,重载Centreon 引擎,Proxmox VE监控项添加成功。