作为中间件的杠把子选手,rabbimq在系统架构中承担着承上启下的作用,常问到,你们为何选用rabbimq?则答曰,为了削峰填谷,为了系统解耦合,为了提高系统性能。但这事是绝对的吗?用了这款软件就可以实现这个目的吗?
背景
RabbitMQ 是一个由Erlang 语言开发的AMQP 的开源实现。rabbitMQ是一款基于AMQP协议的消息中间件,它能够在应用之间提供可靠的消息传输。在易用性,扩展性,高可用性上表现优秀。使用消息中间件利于应用之间的解耦,生产者(客户端)无需知道消费者(服务端)的存在。而且两端可以使用不同的语言编写,大大提供了灵活性。
AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
消息的前生
消息是贯穿这个这款中间件服务的脉络,我们不妨通过一条消息来推演窥探整个rabbimq的设计思想,站在前人的肩膀上,看看这款软件的先进设计。

何谓消息
即信息,生产者产生的数据,这些数据记录着生产端产生的业务日志,将会被投递到后端进行处理。
何谓消息队列
消息队列(MQ)全称为Message Queue,是一种应用程序对应用程序的通信方法。说人话就是,在应用之间放一个组件组件,之后应用双方通过这个消息组件进行通信。
本次将通过消息的生命周期的回顾来窥探这款服务的细节
今世
rabbimq的每一次迭代都离不开三个核心概念,生产者producer,消费者comsumer,服务端broker,随着系统的迭代增加了集群的概念,以及后续的容灾机制。
Producer
消息的产生离不开生产者producer,其发送发生很简单,伪代码如下
# 消息发送方法 # messageBody 消息体 # exchangeName 交换器名称 # routingKey 路由键 publishMsg(messageBody,exchangeName,routingKey){ ...... } # 消息发送 publishMsg("This is a warning log","exchange","log.warning");至此,我们一条消息发送成功了,但作为一名开发人员,我们理应知道这条消息去到哪了?到底做了什么操作?后续将会遭遇到了什么?
Broker
在生产者和消费者之间其实包括了很多内容,我们需要把前面的图进行更加深入的展开,我们一层一层拨开mq的心,你会发现,你会流泪
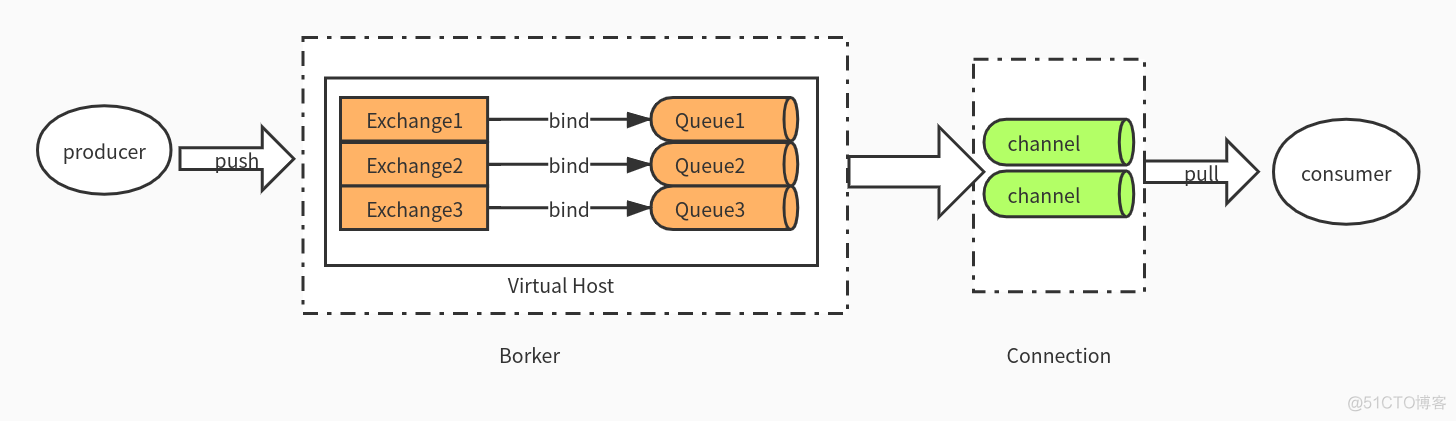
- Broker: 中间件本身。接收和分发消息的应用,这里指的其实就是RabbitMQ Server。
- Virtual host: 虚拟主机。出于多租户和安全因素设计的,把AMQP的基本组件划分到一个虚拟的分组中,类似于namespace。当多个不同的用户使用同一个RabbitMQ server提供的服务时,可以划分出多个vhost,每个用户在自己的vhost创建exchange/queue等,他们之间互不影响,互相独立且隔离。
- Connection: 连接。publisher/consumer和broker之间的TCP连接。断开连接的操作只会在client端进行,Broker不会断开连接,除非出现网络故障或broker服务出现问题。
- Channel: 通道。如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection的开销会比较大且效率也较低。Channel是在connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的channel进行通讯,AMQP method包含了channel id帮助客户端和message broker识别channel,所以channel之间是完全隔离的。Channel作为轻量级的Connection极大减少了操作系统建立TCP connection的开销。
- Exchange: 交换机。根据分发规则,匹配查询表中的routing key,分发消息到queue中去。
- Queue: 消息的队列。消息最终被送到这里等待消费,一个message可以被同时拷贝到多个queue中。
- Binding: 绑定。exchange和queue之间的虚拟连接,binding中可以包含routing key。Binding信息被保存到exchange中的查询表中,用于message的分发依据。
看完了这些概念,我再给大家梳理一遍信息流:当我们的生产者端往Broker(RabbitMQ)中推送消息,Broker会根据其消息的标识送往不同的Virtual host,然后Exchange会根据消息的路由key和交换器类型将消息分发到自己所属的Queue中去。
然后消费者端会通过Connection中的Channel获取刚刚推送的消息,拉取消息进行消费。
工作模型
这里指的是交换机的类型
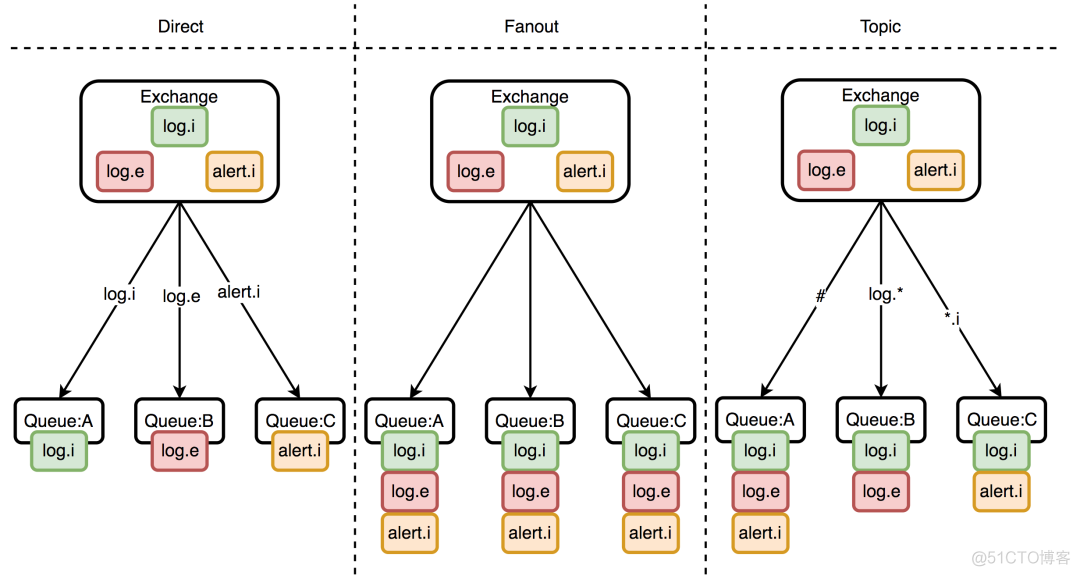
这里有三种交换机类型,也就是有三种路由模式
- Direct:本质上就是单播。在这种模式下的交换机不会将消息发送给所有队列,而是通过队列绑定到交换机上的RoutingKey(路由Key)发送到指定的队列中。
- Fanout:本质上就是广播。生产者生产的一条消息,会被交换机发给所有的队列,所有和队列绑定的消费者均会消费这一条消息。
- Topic:支持自定义匹配规则(即使用通配符),按照规则把所有满足条件的消息路由到指定队列,能够帮助开发者灵活应对各类需求。
consumer
消费者就是消息的处理端,会主动从消息队列中拉取信息,释放消息队列中挤压的资源
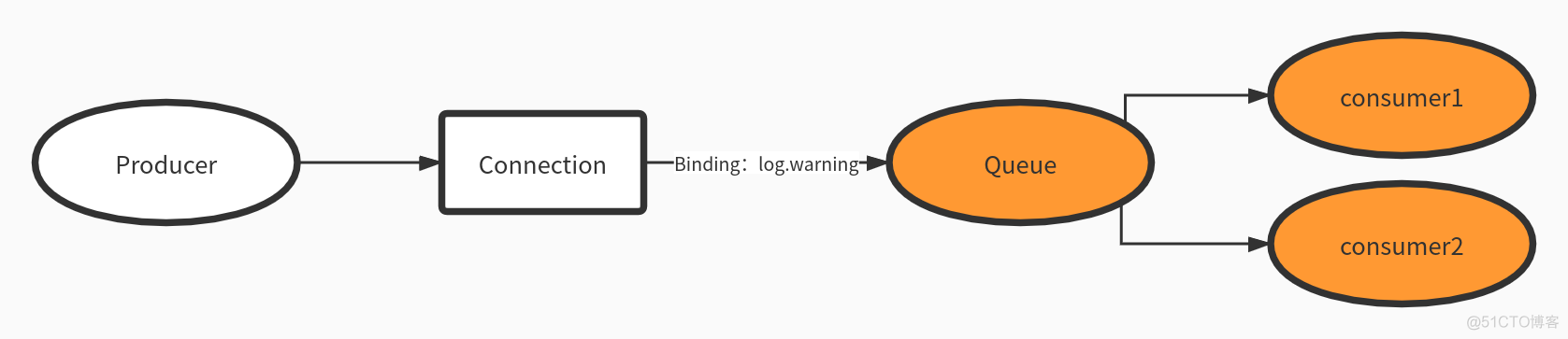
默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取奇数序列的任务,消费者1去队列中获取偶数序列的任务。
对于消息消费而言,消费者直接指定要消费的队列即可,比如指定消费队列A的数据。需要注意的是,在消费者消费完成数据后,返回给rabbimq ACK消息,rabbimq会删掉队列中的该条信息。
现世报
万物抱阳负阴,系统之间突然加了个中间件,提高系统复杂度的同时也增加了很多问题:
- 消息丢失怎么办?
- 消息重复消费怎么办?
- 某些任务需要消息的顺序消息,顺序消费怎么保证?
- 消息队列组件的可用性如何保证?
投递模式
上面前三个问题其实就是对投递模式的灵魂发问,也就是消息推送方知不知道数据已经推送,消息服务端在消息被拉取的时候有没有偏移量记录,消息消费端有没有拉取确认机制。当然了校验机制越复杂对于系统投递性能损耗就越严重,可靠性越强,效率就会相应的打折扣

发后即忘
这个是最简单的模式,也是效率最高的机制,类似于udp,RabbitMQ默认发布消息是不会返回任何结果给生产者的,所以存在发送过程中丢失数据的风险。
AMQP事务
AMQP事务保证RabbitMQ不仅收到了消息,并成功将消息路由到了所有匹配的订阅队列,AMQP事务将使得生产者和RabbitMQ产生同步。虽然事务使得生产者可以确定消息已经到达RabbitMQ中的对应队列,但是却会降低2~10倍的消息吞吐量。
发送方确认
开启发送方确认模式后,消息会有一个唯一的ID,一旦消息被投递给所有匹配的队列后,会回调给发送方应用程序(包含消息的唯一ID),使得生产者知道消息已经安全到达队列了。
如果消息和队列是配置成了持久化,这个确认消息只会在队列将消息写入磁盘后才会返回。如果RabbitMQ内部发生了错误导致这条消息丢失,那么RabbitMQ会发送一条nack消息,当然我理解这个是不能保证的。
这种模式由于不存在事务回滚,同时整体仍然是一个异步过程,所以更加轻量级,对服务器性能的影响很小。
存储
那么问题来了,rabbimq的消息是以什么样的形式存储。默认条件下消息是存储在内存中,不止是消息,Exchange路由等元数据信息实际都在内存中。
具体的元数据信息:队列元数据:队列名称和属性交换器元数据:交换器名称、类型和属性绑定元数据:路由信息
内存的优点是高性能,问题在于故障后无法恢复。都已经2021年,RabbitMQ必然也支持持久化的存储,也就是写磁盘。
持久化存储
实现消息队列持久化的建议同时满足以下三个条件
效果:
- 当一条持久化消息发送到持久化的Exchange上时,RabbitMQ会在消息提交到日志文件后,才发送响应
- 一旦这条消息被消费后,RabbitMQ会将会把日志中该条消息标记为等待垃圾收集,之后会从日志中清除
- 如果出现故障,自动重建Exchange,Bindings和Queue,同时通过重播持久化日志来恢复消息
消息的持久化
消息是否为持久化那还要看消息的持久化设置。也就是说,重启服务之前那个queue里面还没有发出去的消息的话,重启之后那队列里面是不是还存在原来的消息,这个就要取决于发生着在发送消息时对消息的设置了。如果要在重启后保持消息的持久化必须设置消息是持久化的标识。
设置消息的持久化:
channel.basicPublish("exchange.persistent", "persistent", MessageProperties.PERSISTENT_TEXT_PLAIN, "persistent_test_message".getBytes());这里的关键是:MessageProperties.PERSISTENT_TEXT_PLAIN首先看一下basicPublish的方法:
void basicPublish(String exchange, String routingKey, BasicProperties props, byte[] body) throws IOException; void basicPublish(String exchange, String routingKey, boolean mandatory, BasicProperties props, byte[] body) throws IOException; void basicPublish(String exchange, String routingKey, boolean mandatory, boolean immediate, BasicProperties props, byte[] body) throws IOException;- exchange表示交换机的名称
- routingKey表示路由键的名称
- body代表发送的消息体
- mandatory告诉服务器至少将该消息route到一个队列中,否则将消息返还给生产者
- 当设置为true时,如果exchange根据自身类型和消息routeKey无法找到一个符合条件的queue,那么会调用basic.return方法将消息返回给生产者(Basic.Return + Content-Header + Content-Body);
- 当设置为false时,出现上述情形broker会直接将消息扔掉。
- immediate,告诉服务器如果该消息关联的queue上有消费者,则马上将消息投递给它,如果所有queue都没有消费者,直接把消息返还给生产者,不用将消息入队列等待消费者了。
- 当设置为true时,如果exchange在将消息路由到queue(s)时发现对于的queue上么有消费者,那么这条消息不会放入队列中。当与消息routeKey关联的所有queue(一个或者多个)都没有消费者时,该消息会通过basic.return方法返还给生产者。
这里关键的是BasicProperties props这个参数了,这里看下BasicProperties的定义:
public BasicProperties( String contentType,//消息类型如:text/plain String contentEncoding,//编码 Map<String,Object> headers, Integer deliveryMode,//1:nonpersistent 2:persistent Integer priority,//优先级 String correlationId, String replyTo,//反馈队列 String expiration,//expiration到期时间 String messageId, Date timestamp, String type, String userId, String appId, String clusterId)这里的deliveryMode=1代表不持久化,deliveryMode=2代表持久化。
上面的实现代码使用的是MessageProperties.PERSISTENT_TEXT_PLAIN,那么这个又是什么呢?
public static final BasicProperties PERSISTENT_TEXT_PLAIN = new BasicProperties("text/plain", null, null, 2, 0, null, null, null, null, null, null, null null, null);可以看到这其实就是讲deliveryMode设置为2的BasicProperties的对象,为了方便编程而出现的一个东东。换一种实现方式:
AMQP.BasicProperties.Builder builder = new AMQP.BasicProperties.Builder(); builder.deliveryMode(2); AMQP.BasicProperties properties = builder.build(); channel.basicPublish("exchange.persistent", "persistent",properties, "persistent_test_message".getBytes());设置了队列和消息的持久化之后,当broker服务重启的之后,消息依旧存在。单只设置队列持久化,重启之后消息会丢失;单只设置消息的持久化,重启之后队列消失,既而消息也丢失。单单设置消息持久化而不设置队列的持久化显得毫无意义。
Exchange的持久化
不设置Exchange的持久化对消息的可靠性来说没有什么影响,但是同样如果Exchange不设置持久化,那么当broker服务重启之后,Exchange将不复存在,那么既而发送方rabbitmq producer就无法正常发送消息。这里笔者建议,同样设置Exchange的持久化。Exchange的持久化设置也特别简单,方法如下:
Exchange.DeclareOk exchangeDeclare(String exchange, String type, boolean durable) throws IOException; Exchange.DeclareOk exchangeDeclare(String exchange, String type, boolean durable, boolean autoDelete, Map<String, Object> arguments) throws IOException; Exchange.DeclareOk exchangeDeclare(String exchange, String type) throws IOException; Exchange.DeclareOk exchangeDeclare(String exchange, String type, boolean durable, boolean autoDelete, boolean internal, Map<String, Object> arguments) throws IOException; void exchangeDeclareNoWait(String exchange, String type, boolean durable, boolean autoDelete, boolean internal, Map<String, Object> arguments) throws IOException; Exchange.DeclareOk exchangeDeclarePassive(String name) throws IOException;一般只需要:channel.exchangeDeclare(exchangeName, “direct/topic/header/fanout”, true);即在声明的时候讲durable字段设置为true即可。
Queue的持久化
如果将Queue的持久化标识durable设置为true,则代表是一个持久的队列,那么在服务重启之后,也会存在,因为服务会把持久化的Queue存放在硬盘上,当服务重启的时候,会重新什么之前被持久化的Queue。
Queue的持久化是通过durable=true来实现的。一般程序中这么使用:
Connection connection = connectionFactory.newConnection(); Channel channel = connection.createChannel(); channel.queueDeclare("queue.persistent.name", true, false, false, null);关键的是第二个参数设置为true,即durable=true.
Channel类中queueDeclare的完整定义如下:
/** * Declare a queue * @see com.rabbitmq.client.AMQP.Queue.Declare * @see com.rabbitmq.client.AMQP.Queue.DeclareOk * @param queue the name of the queue * @param durable true if we are declaring a durable queue (the queue will survive a server restart) * @param exclusive true if we are declaring an exclusive queue (restricted to this connection) * @param autoDelete true if we are declaring an autodelete queue (server will delete it when no longer in use) * @param arguments other properties (construction arguments) for the queue * @return a declaration-confirm method to indicate the queue was successfully declared * @throws java.io.IOException if an error is encountered */ Queue.DeclareOk queueDeclare(String queue, boolean durable, boolean exclusive, boolean autoDelete, Map<String, Object> arguments) throws IOException;参数说明:
- queue:queue的名称
- exclusive:排他队列,如果一个队列被声明为排他队列,该队列仅对首次申明它的连接可见,并在连接断开时自动删除。这里需要注意三点:
- 排他队列是基于连接可见的,同一连接的不同信道是可以同时访问同一连接创建的排他队列;
- “首次”,如果一个连接已经声明了一个排他队列,其他连接是不允许建立同名的排他队列的,这个与普通队列不同;
- 即使该队列是持久化的,一旦连接关闭或者客户端退出,该排他队列都会被自动删除的,这种队列适用于一个客户端发送读取消息的应用场景。
- autoDelete:自动删除,如果该队列没有任何订阅的消费者的话,该队列会被自动删除。这种队列适用于临时队列。
- queueDeclare相关的有4种方法,分别是:
Queue.DeclareOk queueDeclare() throws IOException;
Queue.DeclareOk queueDeclare(String queue, boolean durable, boolean exclusive, boolean autoDelete,
Map<String, Object> arguments) throws IOException;
void queueDeclareNoWait(String queue, boolean durable, boolean exclusive, boolean autoDelete,
Map<String, Object> arguments) throws IOException;
Queue.DeclareOk queueDeclarePassive(String queue) throws IOException;
其中需要说明的是queueDeclarePassive(String queue)可以用来检测一个queue是否已经存在。如果该队列存在,则会返回true;如果不存在,就会返回异常,但是不会创建新的队列。
进一步思考
将queue,exchange,message等都设置了持久化之后就能保证100%保证数据不丢失了吗?答案是否定的。首先,从consumer端来说,如果这时autoAck=true,那么当consumer接收到相关消息之后,还没来得及处理就crash掉了,那么这样也算数据丢失,这种情况也好处理,只需将autoAck设置为false(方法定义如下),然后在正确处理完消息之后进行手动ack(channel.basicAck).
String basicConsume(String queue, boolean autoAck, Consumer callback) throws IOException;其次,关键的问题是消息在正确存入RabbitMQ之后,还需要有一段时间(这个时间很短,但不可忽视)才能存入磁盘之中,RabbitMQ并不是为每条消息都做fsync的处理,可能仅仅保存到cache中而不是物理磁盘上,在这段时间内RabbitMQ broker发生crash, 消息保存到cache但是还没来得及落盘,那么这些消息将会丢失。
那么这个怎么解决呢?首先可以引入RabbitMQ的mirrored-queue即镜像队列,这个相当于配置了副本,当master在此特殊时间内crash掉,可以自动切换到slave,这样有效的保障了HA, 除非整个集群都挂掉,这样也不能完全的100%保障RabbitMQ不丢消息,但比没有mirrored-queue的要好很多,很多现实生产环境下都是配置了mirrored-queue的,关于镜像队列的,我们后续展开讨论。还有要在producer引入事务机制或者Confirm机制来确保消息已经正确的发送至broker端,有关RabbitMQ的事务机制或者Confirm机制读者们有兴趣的话,请留言,我们再详细展开讨论。
幸亏本章节的主题是讨论RabbitMQ的持久化而不是可靠性,不然就一发不可收拾了。RabbitMQ的可靠性涉及producer端的确认机制、broker端的镜像队列的配置以及consumer端的确认机制,要想确保消息的可靠性越高,那么性能也会随之而降,鱼和熊掌不可兼得,关键在于选择和取舍。
流控
当RabbitMQ出现内存(默认是0.4)或者磁盘资源达到阈值时,会触发流控机制,阻塞Producer的Connection,让生产者不能继续发送消息,直到内存或者磁盘资源得到释放。
信令桶
RabbitMQ基于Erlang/OTP开发,一个消息的生命周期中,会涉及多个进程间的转发,这些Erlang进程之间不共享内存,每个进程都有自己独立的内存空间,如果没有合适的流控机制,可能会导致某个进程占用内存过大,导致OOM。因此,要保证各个进程占用的内容在一个合理的范围,RabbitMQ的流控采用了一种信用证机制(Credit),为每个进程维护了四类键值对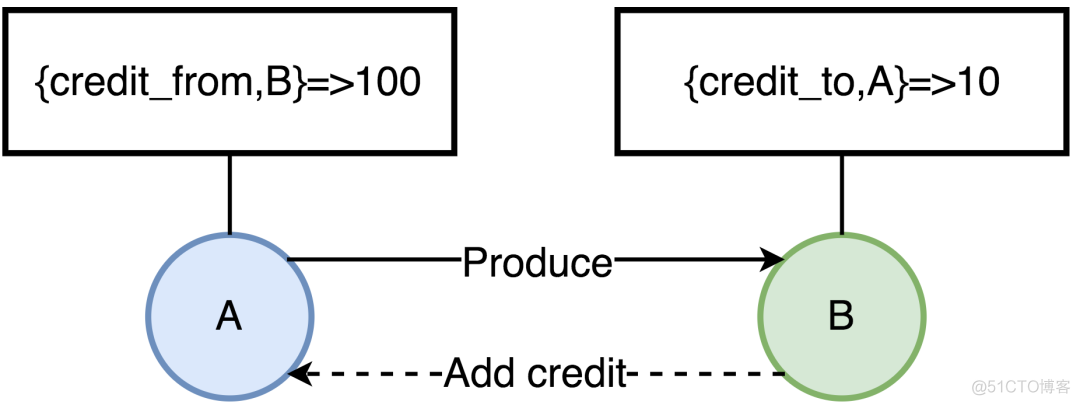
- {credit_from,From},该值表示还能向消息接收进程From发送多少条消息
- {credit_to,To},表示当前进程再接收多少条消息,就要向消息发送进程增加Credit数量
- credit_blocked,表示当前进程被哪些进程block了,比如进程A向B发送消息,那么当A的进程字典中{credit_from,B}的值为0是,那么A的credit_blocked值为[B]
- credit_deferred,消息接收进程向消息发送进程增加Credit的消息列表,当进程被Block时会记录消息信息,Unblock后依次发送这些消息
A进程当前可以发送给B的消息有100条,每发一次,值减1,直到为0,A才会被Block住。B消费消息后,会给A增加新的Credit,这样A才可以持续的发送消息。这里只画了两个进程,多进程串联的情况下,这中影响也就是从底向上传递的
集群设计
rabbimq的集群设计起来,可能是历史原因导致,个人感觉是不够先进,毕竟当年开发的时候,也没有相关的业务需求推动啊
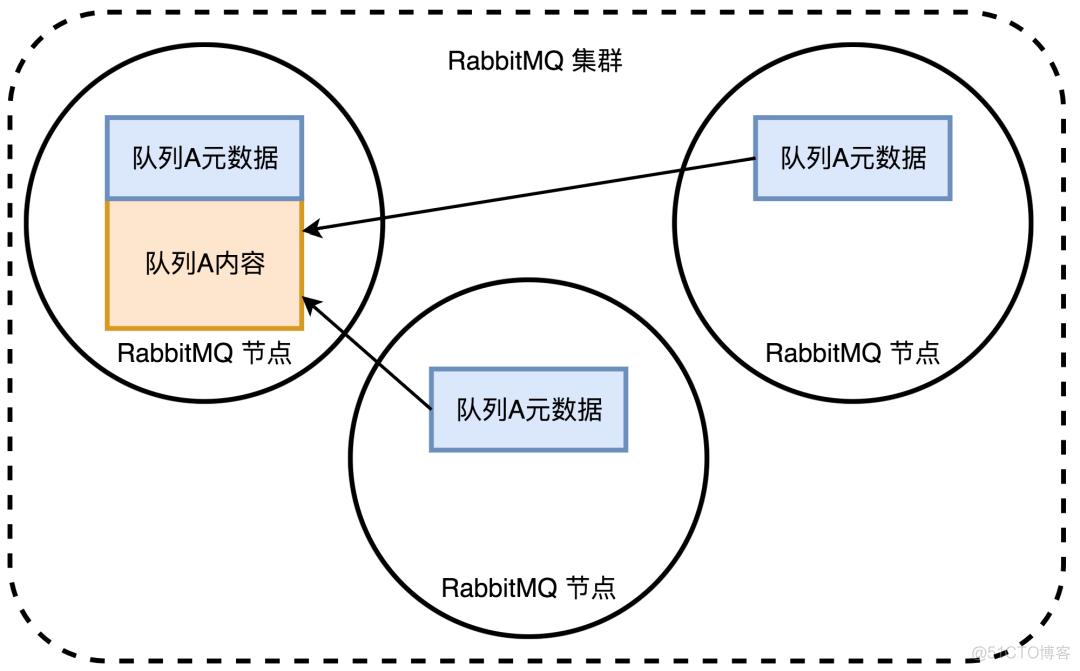
RabbitMQ 会将元数据存储到内存上,如果是磁盘节点,还会存储到磁盘上。
- 元数据
- queue,队列的名称和属性
- exchage,名称,类型和属性
- binding,路由信息
- vhost,为 vhost 内的队列、交换器和绑定提供命名空间和安全属性
队列A的实例实际只在一个RabbitMQ节点上,其它节点实际存储的是指向该队列的指针。虽然RabbitMQ的队列实际只会在一个节点上,但元数据可以存在各个节点上。举个例子来说,当创建一个新的交换器时,RabbitMQ会把该信息同步到所有节点上,这个时候客户端不管连接的那个RabbitMQ节点,都可以访问到这个新的交换器,也就能找到交换器下的队列
为什么RabbitMQ不在各个节点间做复制
在《RabbitMQ实战指南》中朱忠华老师的观点是
- 存储成本考虑-RabbitMQ作为内存队列,复制对存储空间的影响,毕竟内存是昂贵而有限的
- 性能损耗考虑-发布消息需要将消息复制到所有节点,特别是对于持久化队列而言,性能的影响会很大
- 个人观点,答案并不完全成立
- 复制并不一定要复制到所有节点,比如一个队列可以只做两个副本,复制带来的内存成本可以交给使用方来评估,毕竟在内存中没有堆积的情况下,实际上队列是不会占用多大内存的。
- RabbitMQ本身并没有保证消息消费的有序性,所以实际上队列被Partition到各个节点上,这样才能真正达到线性扩容的目的。这个其实是后续对站着学习kafka的时候触发的感觉
- 每次发布消息,都要把它扩散到所有节点上,而且对于磁盘节点来说,每一条消息都会触发磁盘活动,这会导致整个集群内性能负载急剧拉升。
- 如果每个节点都有所有队列的完整内容,那么添加节点不会给你带来额外的存储空间,也会带来木桶效应,举个例子,如果集群内有个节点存储了 3G 队列内容,那么在另外一个只有 1G 存储空间的节点上,就会造成内存空间不足的情况,也就是无法通过集群节点的扩容提高消息积压能力。
镜像队列
镜像队列,本质上就是副本机制
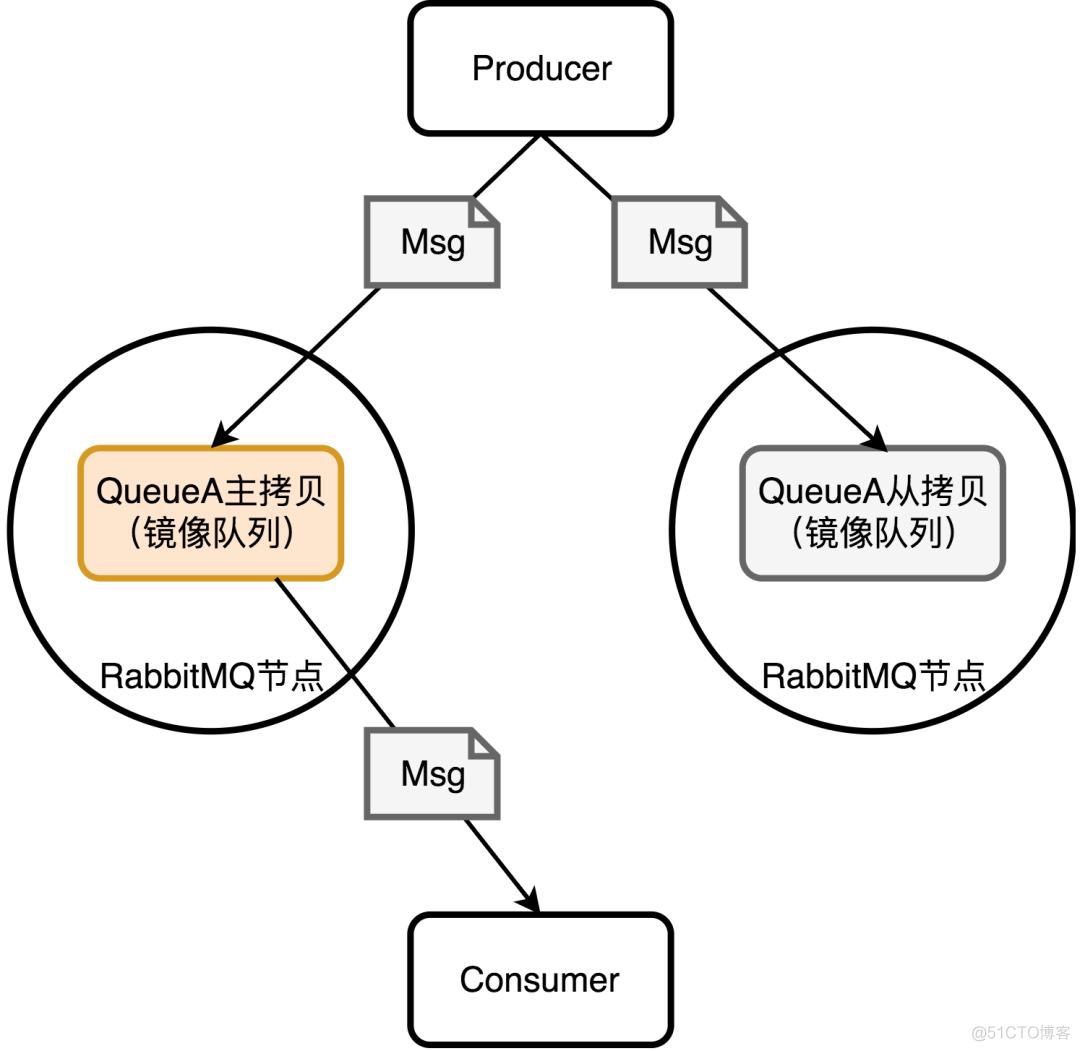
RabbitMQ自己也考虑到了我们之前分析的单节点长时间故障无法恢复的问题,所以RabbitMQ 2.6.0之后它也支持了镜像队列,除了发送消息,所有的操作实际都在主拷贝上,从拷贝实际只是个冷备(默认的情况下所有RabbitMQ节点上都会有镜像队列的拷贝),如果使用消息确认模式,RabbitMQ会在主拷贝和从拷贝都安全的接受到消息时才通知生产者。
从这个结构上来看,如果从拷贝的节点挂了,实际没有任何影响,如果主拷贝挂了,那么会有一个从新选主的过程,这也是镜像队列的优点,除非所有节点都挂了,才会导致消息丢失。重新选主后,RabbitMQ会给消费者一个消费者取消通知(Consumer Cancellation),让消费者重连新的主拷贝。
原理
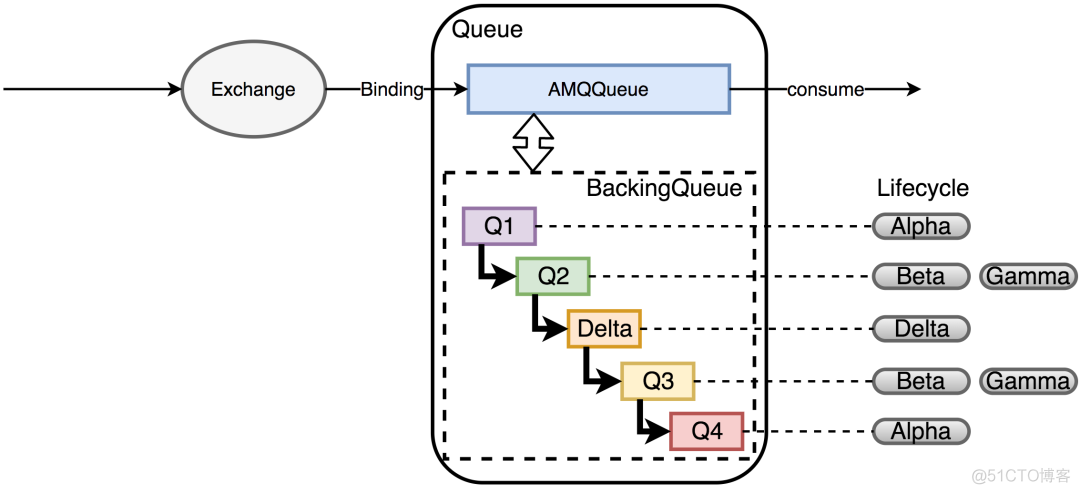
- AMQPQueue,负责AMQP协议相关的消息处理,包括接收消息,投递消息,Confirm消息等
- BackingQueue,提供AMQQueue调用的接口,完成消息的存储和持久化工作,由Q1,Q2,Delta,Q3,Q4五个子队列构成,在Backing中,消息的生命周期有四个状态:
- Alpha,消息的内容和消息索引都在RAM中。(Q1,Q4)
- Beta,消息的内容保存在Disk上,消息索引保存在RAM中。(Q2,Q3)
- Gamma,消息的内容保存在Disk上,消息索引在DISK和RAM上都有。(Q2,Q3)
- Delta,消息内容和索引都在Disk上。(Delta)
这里以持久化消息为例(可以看到非持久化消息的生命周期会简单很多),从Q1到Q4,消息实际经历了一个RAM->DISK->RAM这样的过程,BackingQueue这么设计的目的有点类似于Linux的Swap,当队列负载很高时,通过将部分消息放到磁盘上来节省内存空间,当负载降低时,消息又从磁盘回到内存中,让整个队列有很好的弹性。
结构
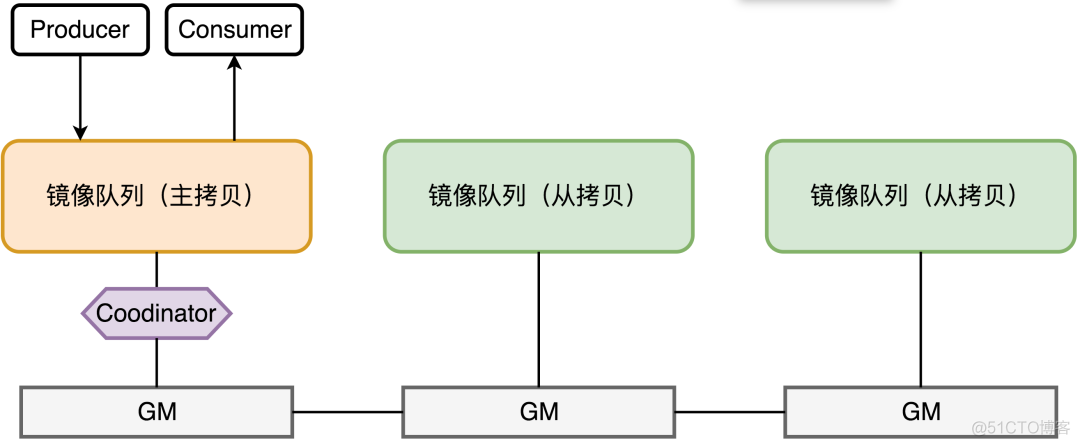 所有对镜像队列主拷贝的操作,都会通过Guarented Multicasting(GM)同步到各个Salve节点,Coodinator负责组播结果的确认。GM是一种可靠的组播通信协议,保证组组内的存活节点都收到消息。
所有对镜像队列主拷贝的操作,都会通过Guarented Multicasting(GM)同步到各个Salve节点,Coodinator负责组播结果的确认。GM是一种可靠的组播通信协议,保证组组内的存活节点都收到消息。
至于说master和slave之间的关系应该是如下图所示
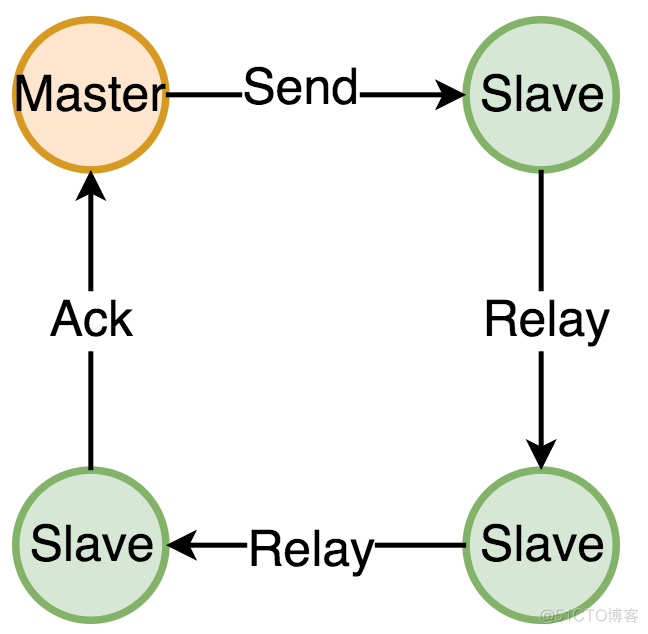
GM的组播并不是由Master节点来负责通知所有Slave的(目的是为了避免Master压力过大,同时避免Master失效导致消息无法最终Ack),RabbitMQ把一个镜像队列的所有节点组成一个链表,由主拷贝发起,由主拷贝最终确认通知到了所有的Slave,而中间由Slave接力的方式进行消息传播。从这个结构来看,消息完成整个镜像队列的同步耗时理论上是不低的,但是由于RabbitMQ消息的消息确认本身是异步的模式,所以整体的吞吐量并不会受到太大影响。
总结
镜像队列(副本)的引入其实就是对Rabbimq的高可用性的补充,从实际结果看,RabbitMQ完成设计目标上并不十分出色,主要原因在于默认的模式下,RabbitMQ的队列实例只存在在一个节点上(虽然后续也支持了镜像队列),既不能保证该节点崩溃的情况下队列还可以继续运行,也不能线性扩展该队列的吞吐量。
尾记
至此我们可以看出rabbimq的一个发展脉络,在古早时代,其推送消息类似udp送过去就送过去了,之后不管了,之后需求倒逼架构改进,要求有可靠性投递引入了确认(ack)机制。随着技术的进步,大规模节点的推广,引入集群的,出现副本,然而集群的并不完美
曾经有位大佬跟我分享过学生时代有个常见的心态:锤子心态即手中有个锤子,看到啥都是钉子,都想锤一下。我们学习了rabbimq,确实是想用起来但不是啥时候都能用,这个要具体问题具体分析