什么是shared libraries Warning: 本文不是面对初学者的,如果你看不懂pipeline,那我也没办法.如果许多概念不明白的话,可以点下面的官方文档多看看. 简单的翻译一下 官方文档 的原话: 在多个
什么是shared libraries
Warning: 本文不是面对初学者的,如果你看不懂pipeline,那我也没办法.如果许多概念不明白的话,可以点下面的官方文档多看看.
简单的翻译一下 官方文档 的原话: 在多个流水线之间共享步骤以此来减少代码的冗余.
那么这到底是什么意思呢? 我们知道当我们使用声明式的流水线的时候,必须要在项目的代码仓库中放一个 Jenkinsfile 文件, 当我们项目越来越多的时候, Jenkinsfile也会越来越多,然后构建的过程也大同小异,这时候你就会发现一些问题:
- 每个Jenkinsfile几乎都长一个样,代码冗余.
- 项目太多,每个Jenkinsfile都要跟着仓库走,不好管理
- Jenkinsfile是在仓库里的,也就意味着开发人员可以更改,改错了无法进行构建了
- 仓库多分支时,每个分支对应的发布环境不一样,Jenkinsfile也不一样,开发合并分支时Jenkinfile会冲突
共享库的最原始的用法就是解决代码冗余的问题的,那么我们来看一个比较官方的用法
文中的所有内容均在: https://github.com/jinyunboss/jenkins-libraries
stage("配置共享库")
# 基本的结构就是这样的
.
├── src
│ └── com
│ └── lotbrick
│ └── jenkins
└── vars
- 在vars目录下新建个execShell.groovy文件
// vars/execShell.groovy
def call(params) {
// 让我们来执行个echo命令
sh "echo ${params}"
}
- 将代码传到git,然后去jenkins配置全局共享库
至于为什么是配置全局共享库,请看这里: https://www.jenkins.io/doc/book/pipeline/shared-libraries/#global-shared-libraries
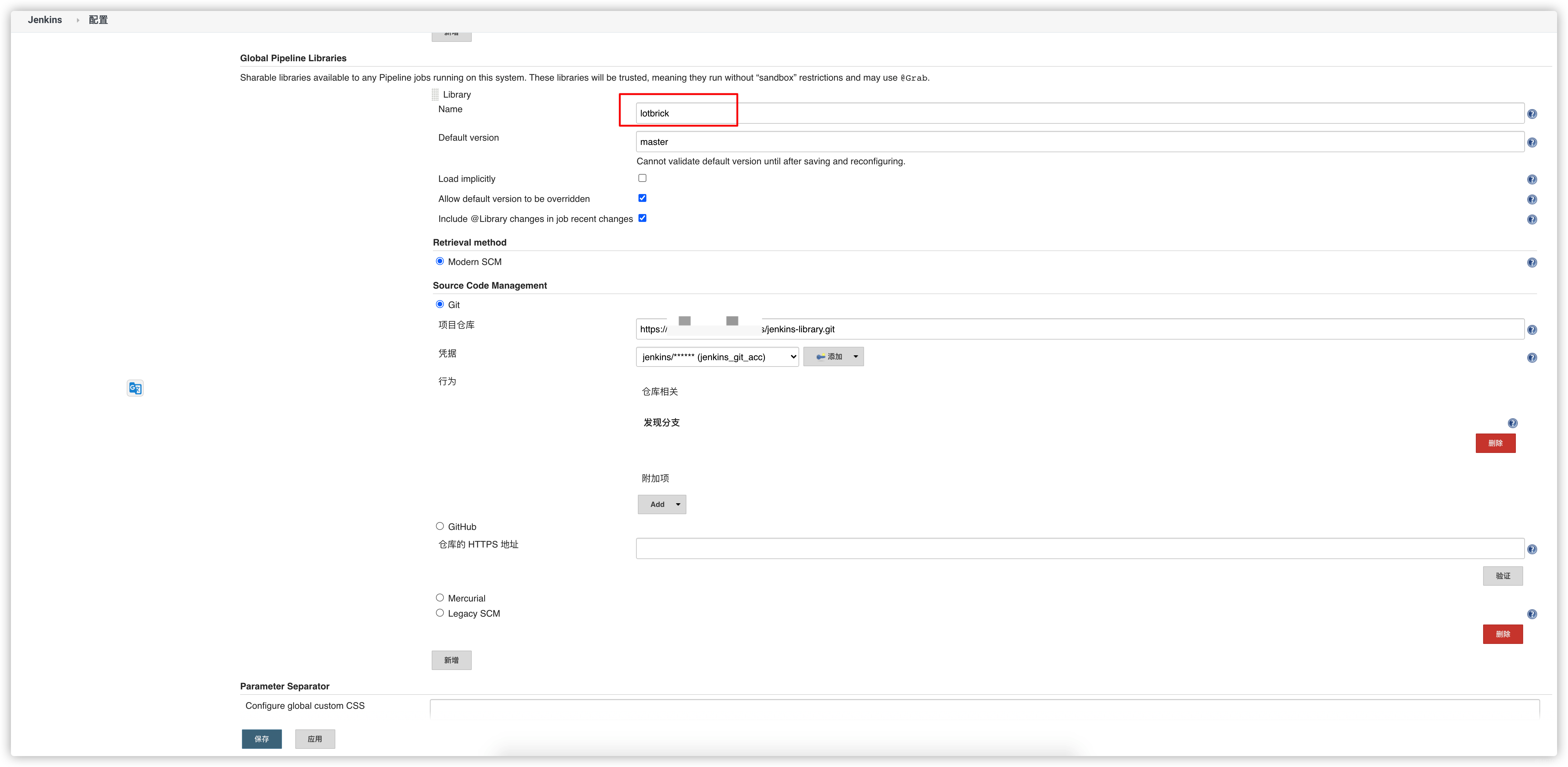
在 Jenkins > 系统配置 > Global Pipeline Libraries中添加一个共享库,名为 lotbrick
stage(“第一个例子”)
@Library('lotbrick') _
pipeline {
agent any
stages {
stage("第一步") {
steps {
script {
execShell("我是一个执行sh命令的例子")
}
}
}
}
}

好像看起来这个例子并没有怎么简化Jenkinsfile呀,没事,来再看一个
stage(“第二个例子,来个input”)
- 在vars目录下新建个inputMsg.groovy文件
// vars/inputMsg.groovy
def call(params){
try {
input(
id: "${params.id}", message: "${params.msg}"
)
} catch(err) {
// 获取执行Input的用户
env.user = err.getCauses()[0].getUser().toString()
userInput = false
env.QATEST_TEST = false
echo "Aborted by: [${user}]"
// 抛出异常确保流程终止
throw err
}
}
@Library('lotbrick') _
pipeline {
agent any
stages {
stage("第一步") {
steps {
script {
execShell("我是一个执行sh命令的例子")
}
}
}
stage("第一步") {
steps {
script {
inputMsg([id:"input1",msg:"我是一个input步骤"])
}
}
}
}
}
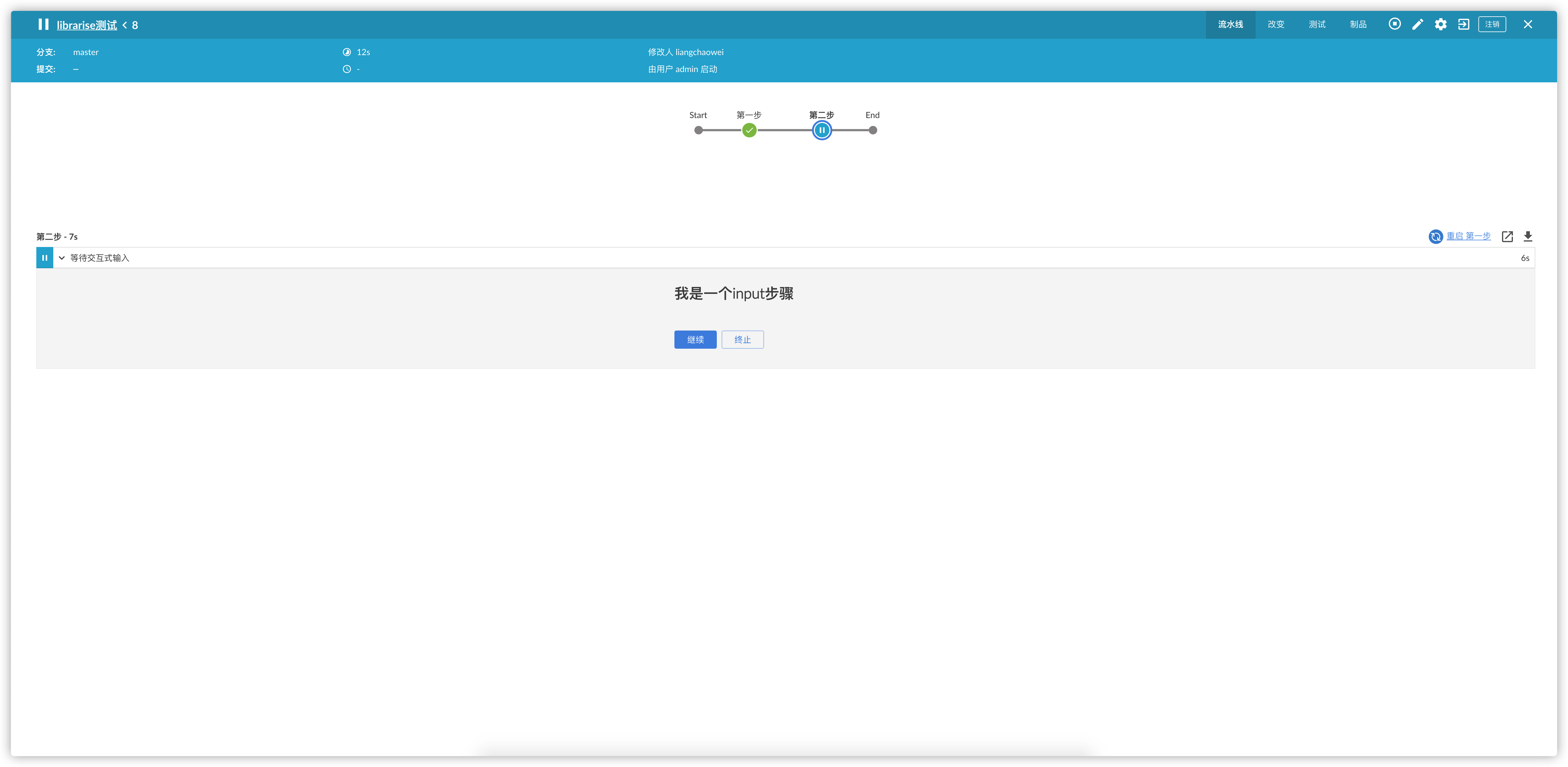
这回我们得到了一个input的步骤,虽然看起来也没简化多少,但是,咱这只是一个input,如果是比较长的执行ansible的步骤呢?我们来看一下调用ansible playbook需要的代码
ansiColor('xterm') {
ansiblePlaybook(
playbook: 'lotbrick.yml',
inventory: 'production',
disableHostKeyChecking: true,
//inventoryContent: 'master',
credentialsId: 'lotbrick-test1-46a8-91cd-185a08255a53',
colorized: true,
)
}
执行一个playbook就需要这些代码,如果执行十个呢?量变就会引起质变,其他的就要靠自己去发掘了.
stage("来个正经的脚本式pipeline")
刚才我们简单的了解了一下共享库是怎么简化Jenkinsfile的,那么咱们来点正经的.官方给的例子基本都是脚本式的流水线,那咱们也来一个正点的脚本式的流水线
- 在vars目录下新建个build.groovy文件,然后在build中写pipeline
// vars/build.groovy
def call(params) {
node {
stage("拉一个代码") {
git url: "${params.git_url}"
}
stage("执行一个命令"){
execShell("${params.cmd}")
}
stage("打印现在的时间"){
sh "date"
}
stage("input步骤"){
inputMsg([id:"input1",msg:"我是一个input步骤"])
}
}
}
@Library('lotbrick') _
build([
git_url:"https://github.com/jinyunboss/docker-compose.git",
cmd:"ls -al"
])
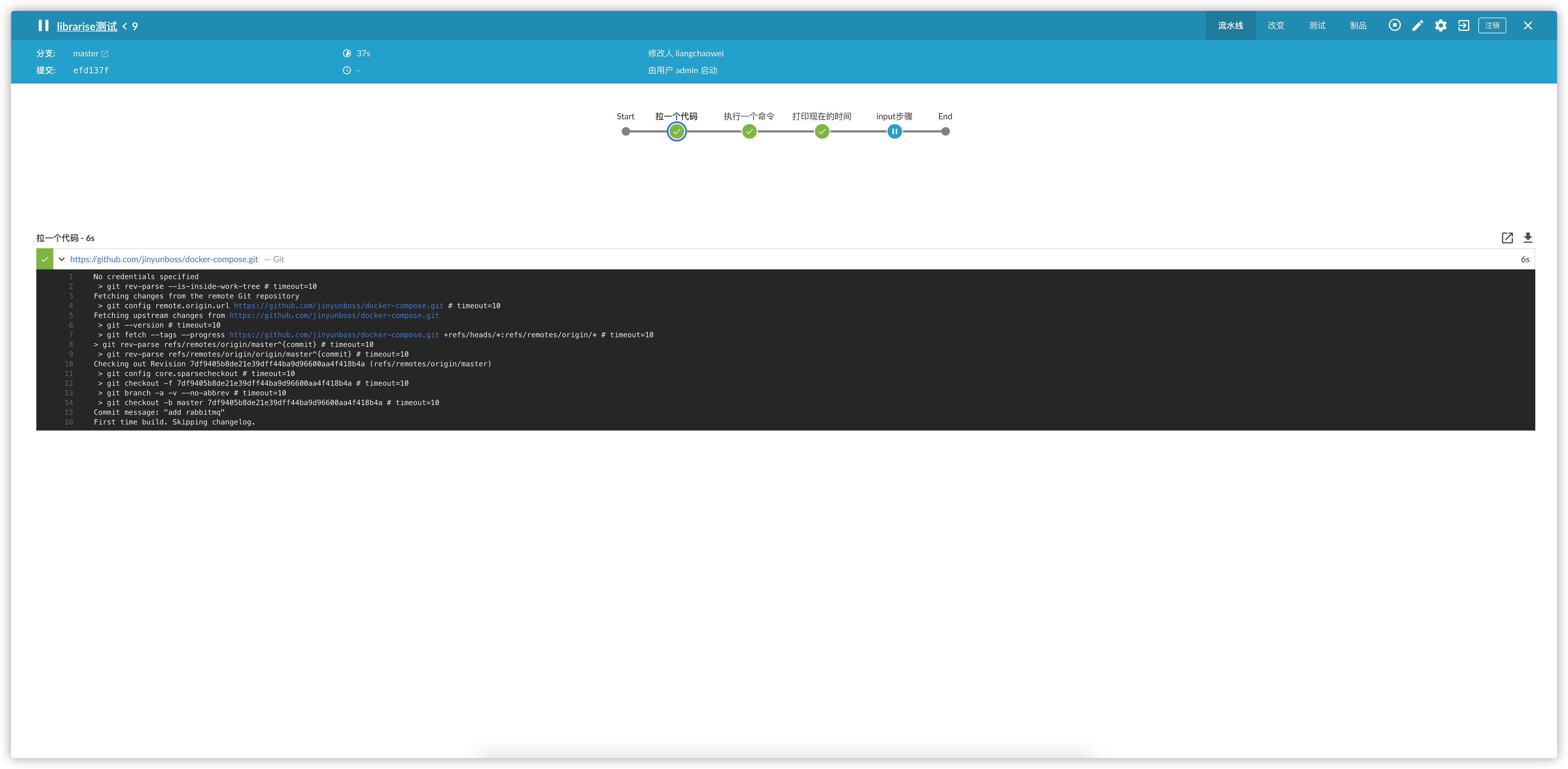
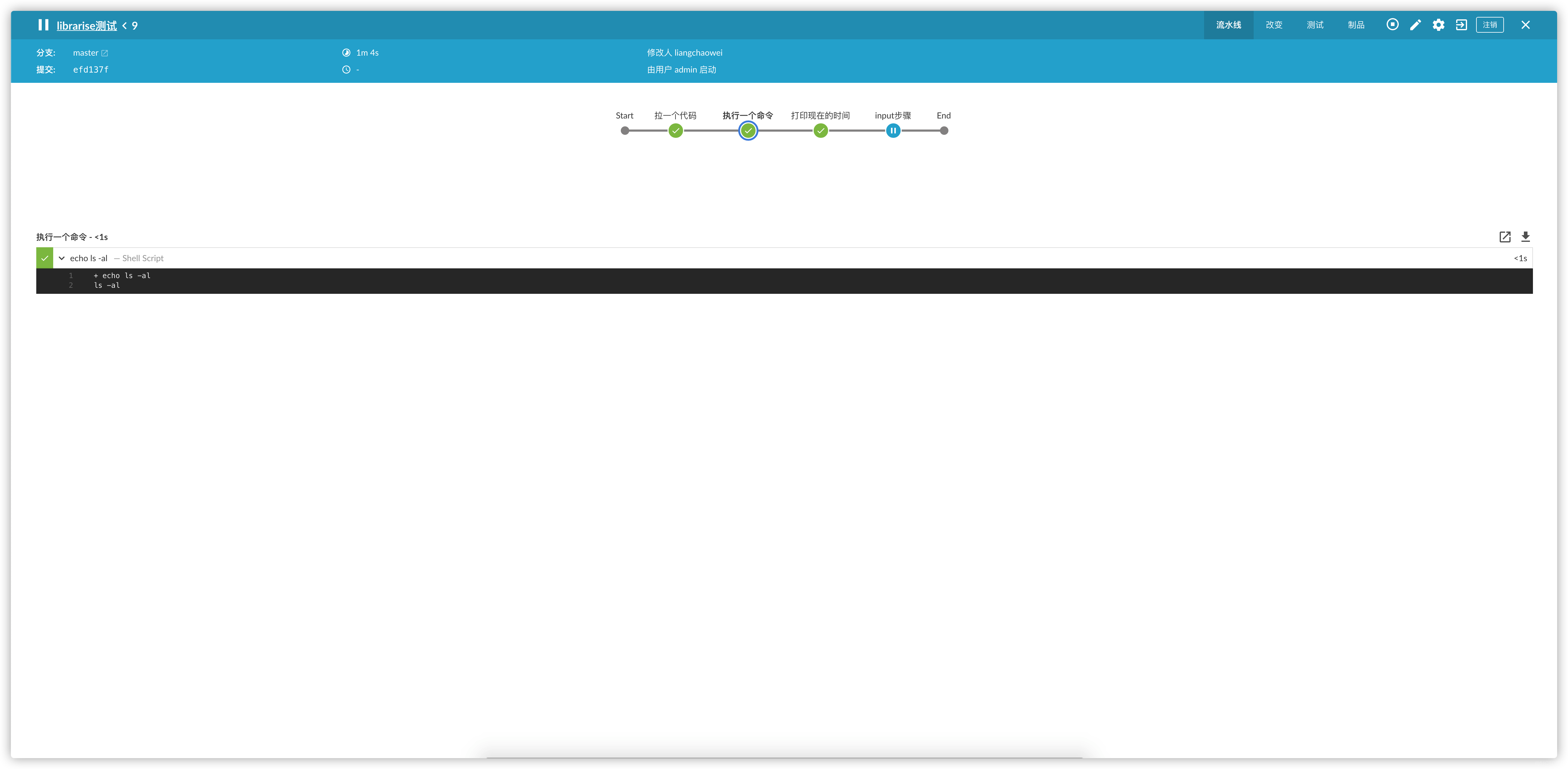
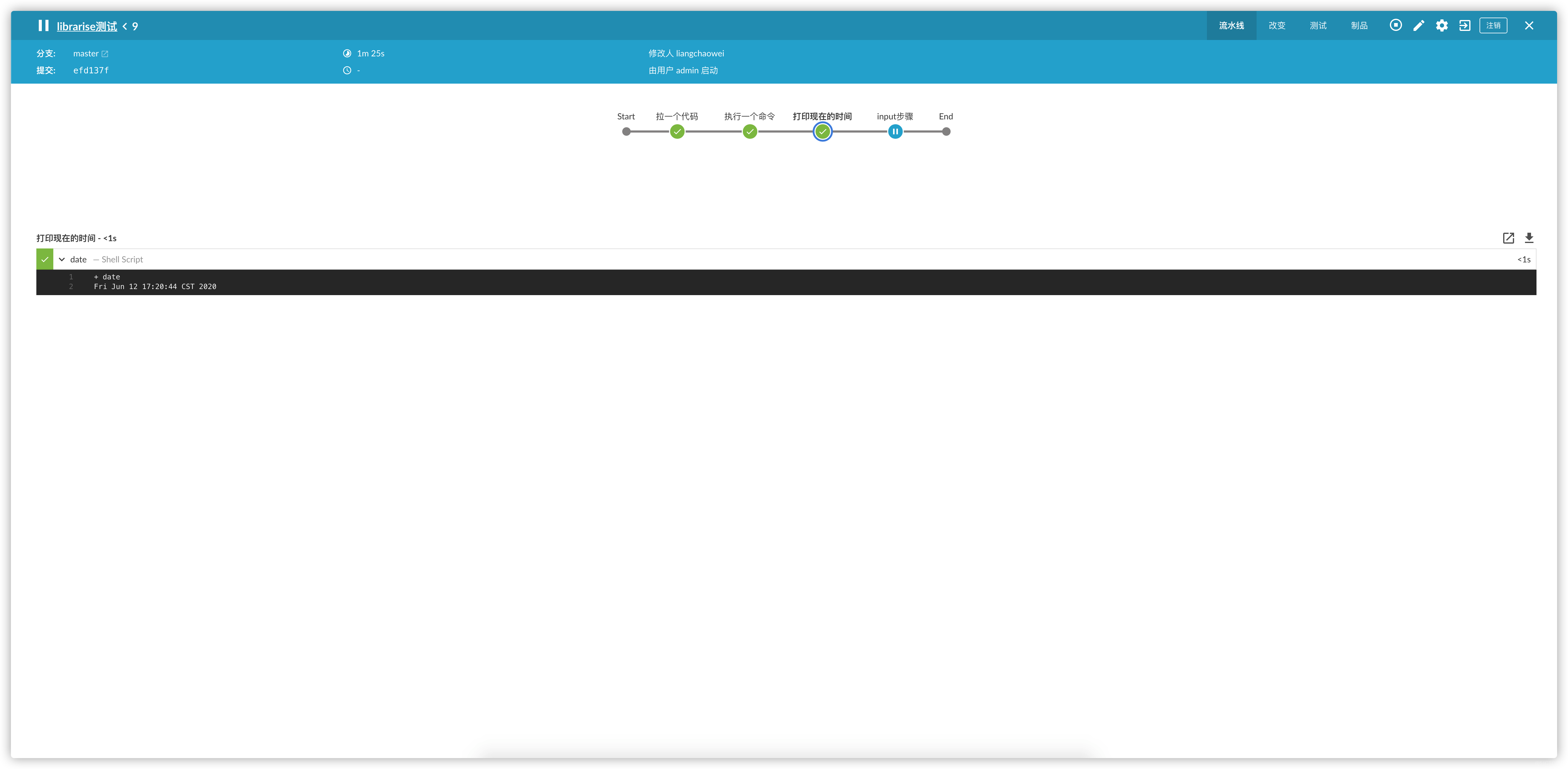
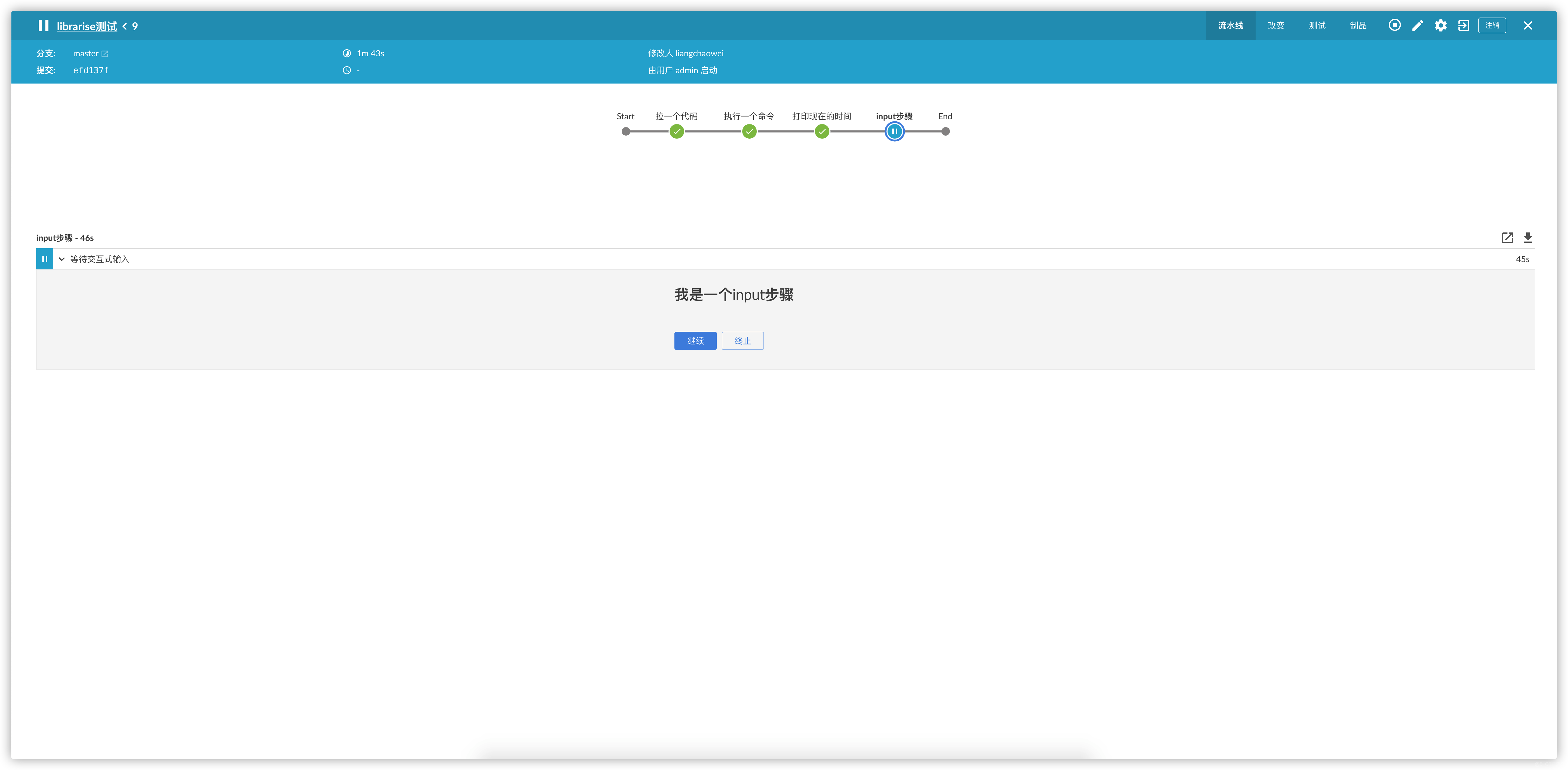
stage("来个声明式的pipeline")
上面我们看到了脚本式的pipeline,当然声明式的也可以.来瞅瞅
- 在vars目录下新建个buildDeclarative.groovy文件,然后在build中写pipeline
// vars/buildDeclarative.groovy
def call(params) {
pipeline {
agent any
options {
// 禁止同时运行多个流水线
disableConcurrentBuilds()
}
environment {
examples_var1 = sh(script: 'echo "当前的时间是: `date`"', returnStdout: true).trim()
}
stages{
stage("声明式流水线: 拉一个代码") {
steps {
git url: "${params.git_url}"
}
}
stage("声明式流水线: 执行一个命令"){
steps {
script {
sh "${params.cmd}"
}
}
}
stage("声明式流水线: 打印现在的时间"){
steps {
script {
inputMsg([id:"${params.input_id}",msg:"${params.input_msg}"])
}
}
}
}
}
}
@Library('lotbrick') _
buildDeclarative([
git_url:"https://github.com/jinyunboss/docker-compose.git",
cmd:"ls -al",
input_id: "input1",
input_msg: "声明式流水线的input"
])
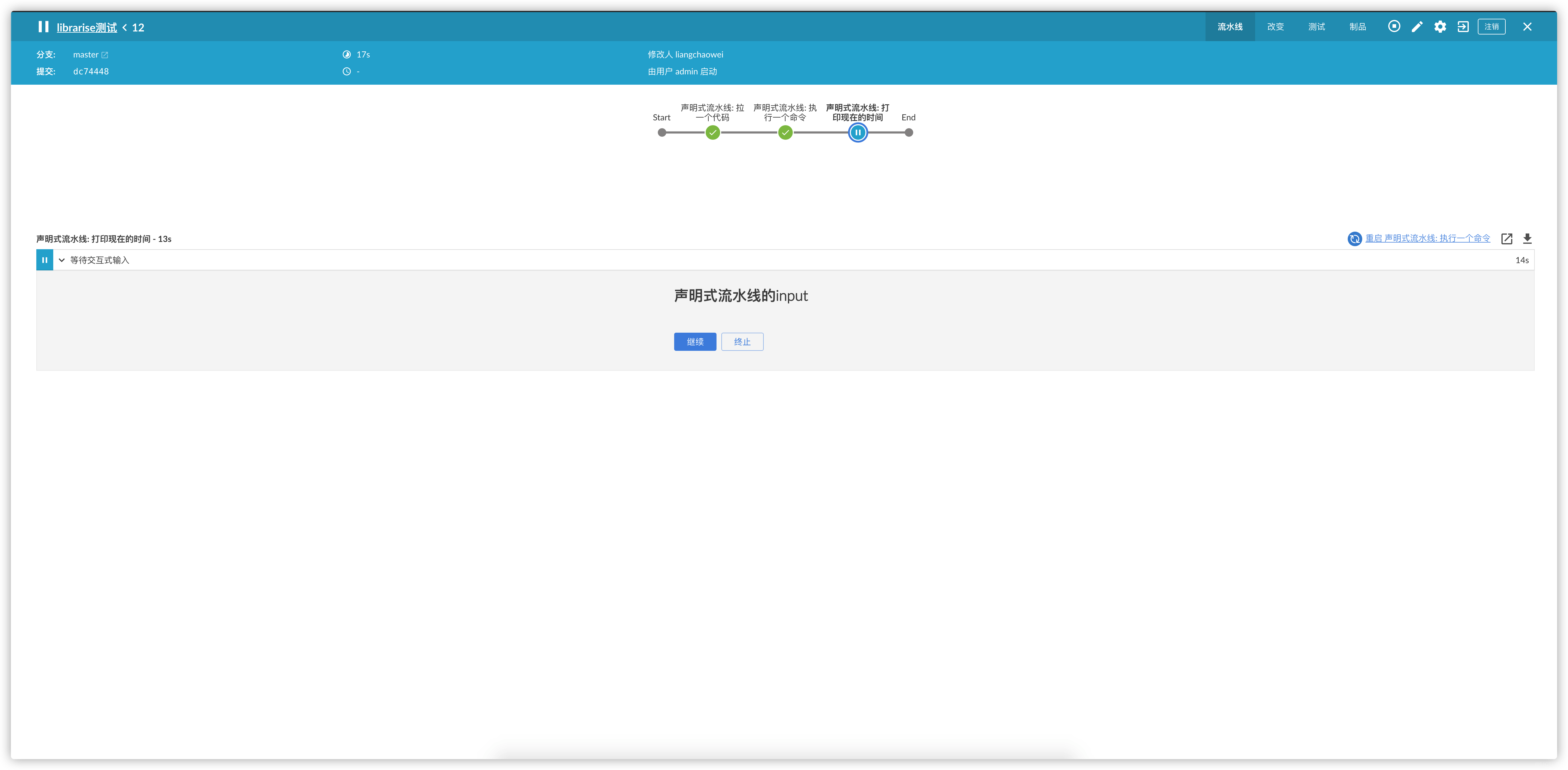
stage("hide your Jenkinsfile")
通过上面的例子,我觉得应该了解来基本的共享库的用法了.那么来点骚操作来解决我们开头的几个问题,首先,既然是多分支的仓库,那么肯定要两个Jenkinsfile,对应不同的环境和发布步骤其次,在项目仓库中所有分支的Jenkinsfile内容要一致,解决合并冲突的问题综合上面的问题来看,我们需要的解决的问题只有一个,隐藏我们的Jenkinsfile
- 再建立一个仓库,用来存放我们的构建步骤的groovy,也就是实际的Jenkinsfile
# 因为我们要用多分支的Job,所以,我们的目录结构要这样
#
# 目录结构如下:
├── jenkins.lotbrick.com
│ ├── dev.groovy
│ └── master.groovy
└── www.lotbrick.com
├── dev.groovy
└── master.groovy
- 修改www.lotbrick.com/master.groovy
def call(params) {
pipeline {
agent any
options {
// 禁止同时运行多个流水线
disableConcurrentBuilds()
}
environment {
examples_var1 = sh(script: 'echo "当前的时间是: `date`"', returnStdout: true).trim()
}
stages{
stage("master: 执行一个命令"){
steps {
script {
sh "ls -al"
}
}
}
stage("master: 打印现在的时间"){
steps {
echo "${examples_var1}"
}
}
stage("master: 打印JOB_NAME"){
steps {
echo "${JOB_NAME}"
}
}
}
}
}
// 记得要return哟,因为我们是调用这个文件
return this
// vars/run.groovy
def call(params){
// 定义jenkinsfile的路径
def jenkinsfile_dir = "/data/jenkins-jenkinsfile/"
node {
// echo "${jenkinsfile_dir}"
// echo "${params.env.JOB_NAME}"
// 加载Jenkinsfile的groovy文件
def jenkinsfile = load("${jenkinsfile_dir}/${params.env.JOB_NAME}.groovy")
// 调用groovy中的call函数,将params也就是job运行时的所有公开的函数和变量传进去
jenkinsfile.call(params)
// "${name}"(params)
//evaluate('aaa(params)')
}
}
- 将这个存有实际groovy的仓库放到Jenkins服务器上的/data/jenkins-jenkinsfile/路径
[root@jenkins jenkins-jenkinsfile]# ll
total 8
drwxr-xr-x 2 root root 4096 Jun 12 18:07 jenkins.lotbrick.com
drwxr-xr-x 2 root root 4096 Jun 12 18:07 www.lotbrick.com
[root@jenkins jenkins-jenkinsfile]# tree
.
├── jenkins.lotbrick.com
│ ├── dev.groovy
│ └── master.groovy
└── www.lotbrick.com
├── dev.groovy
└── master.groovy
2 directories, 4 files
[root@jenkins jenkins-jenkinsfile]# pwd
/data/jenkins-jenkinsfile
[root@jenkins jenkins-jenkinsfile]#
@Library('lotbrick') _
run(this)
- 新建一个名为www.lotbrick.com的多分支流水线的Job
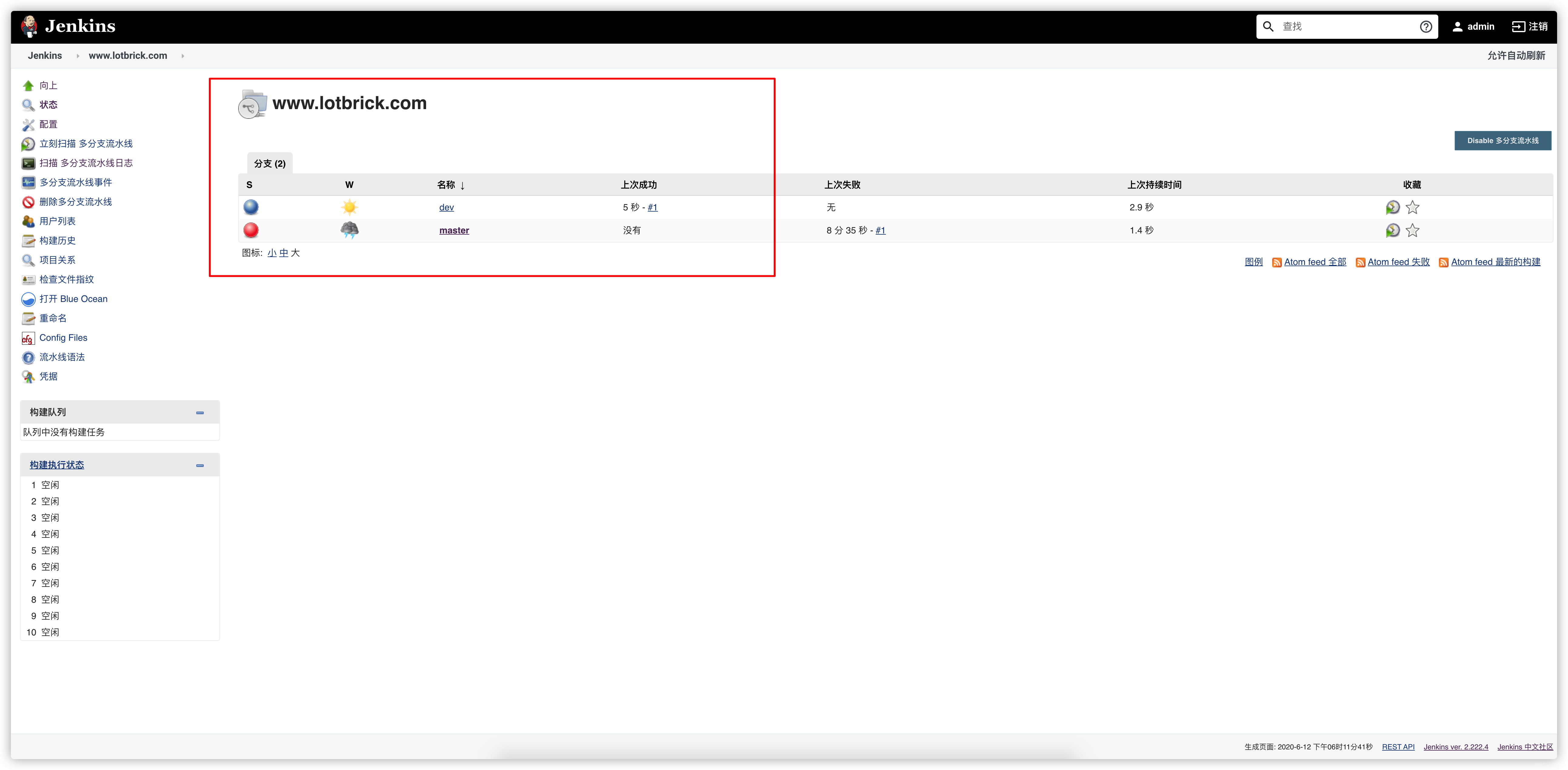
建立好Job之后就能看到Jenkins已经发现了我们仓库的两个分支了,接下来分别运行两个分支的Job
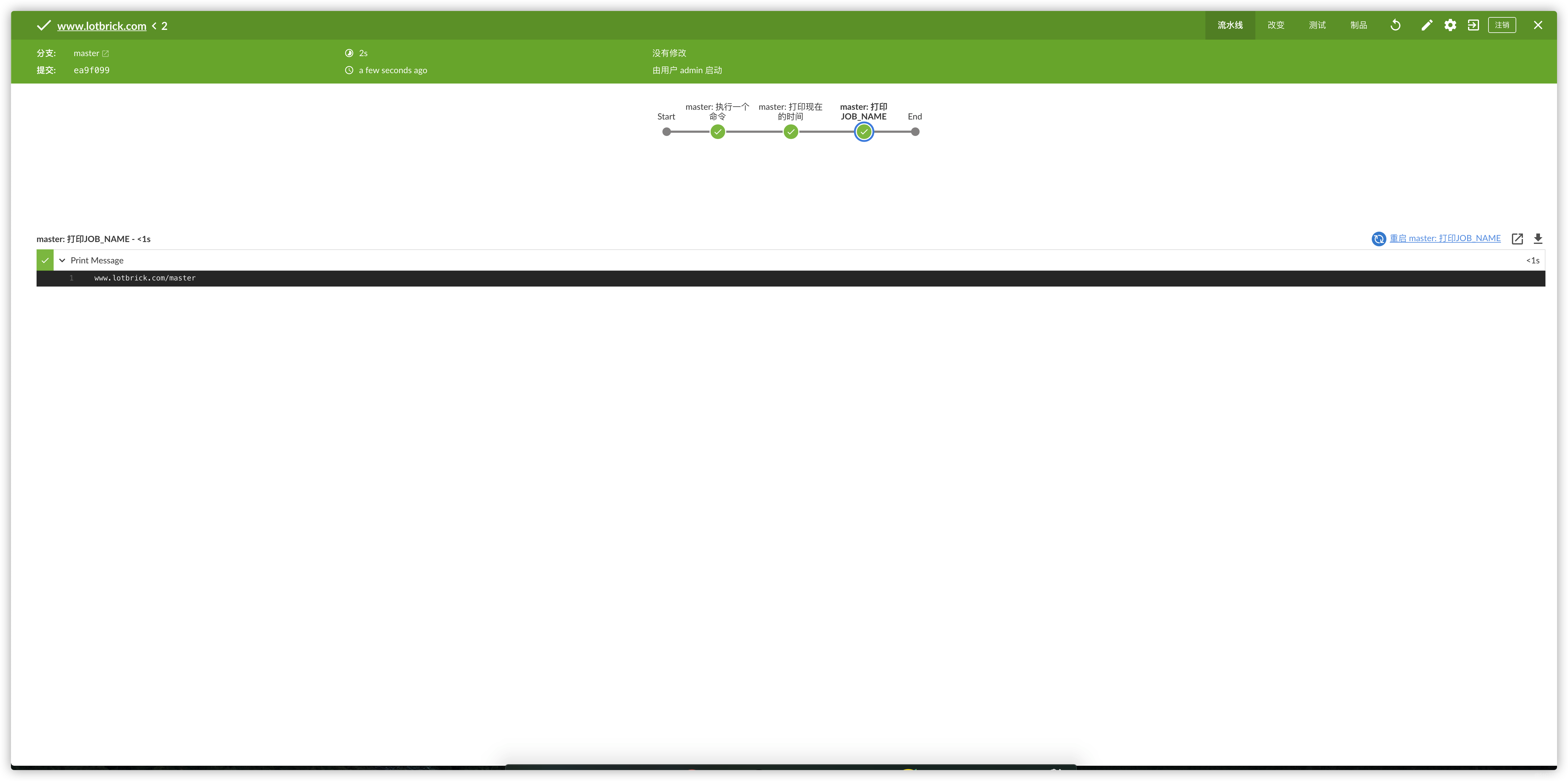
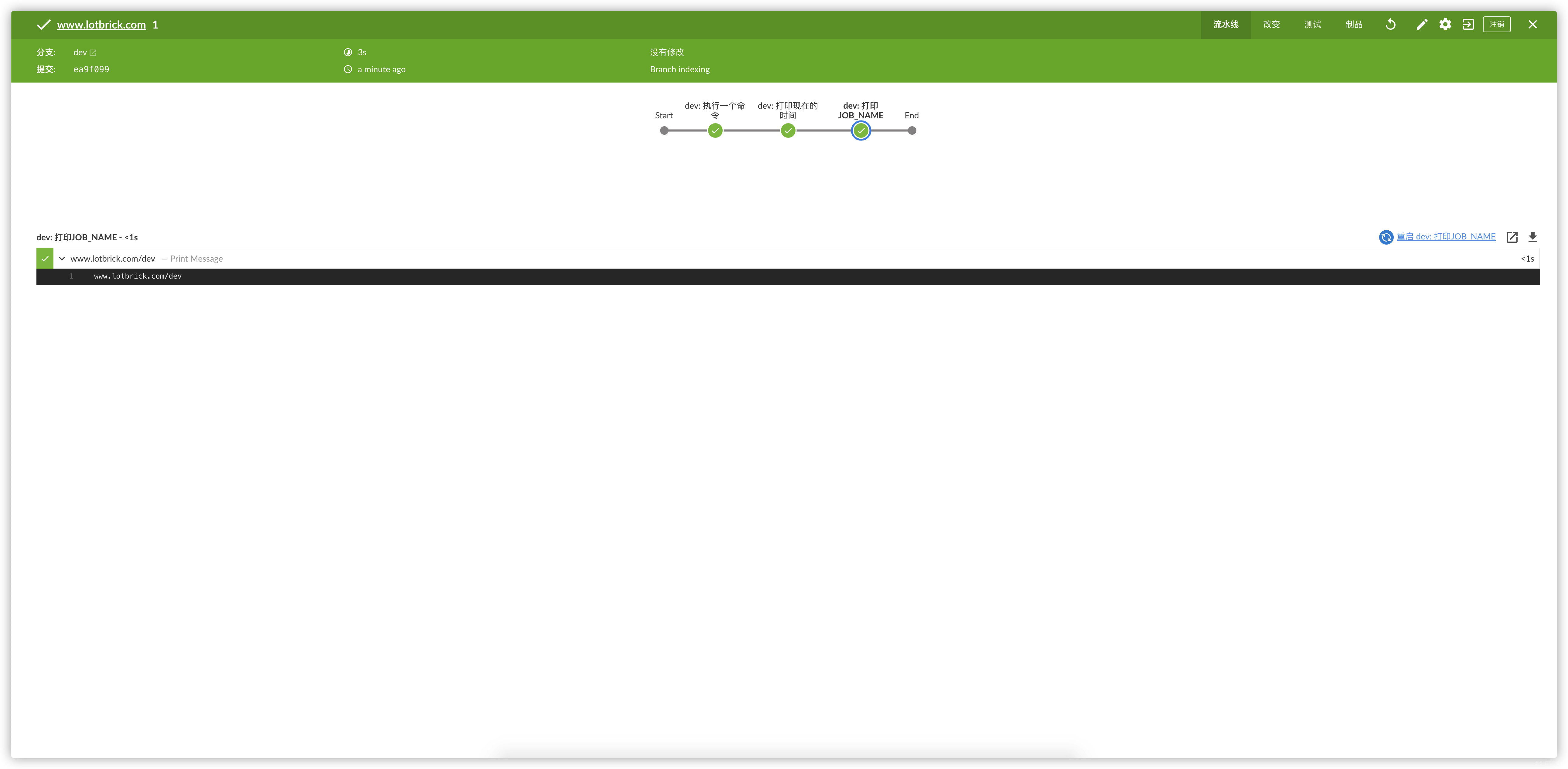
stage("意外发现")
按照官方的 load 函数的示例,加载其他groovy文件的方式就是上面的样子.但是,仔细想了想,官方的给的例子是相当于调用函数,所以要有def和return this.那我如果直接把文件内容拿过来执行呢?结果发现直接在文件中写完整的pipeline,然后直接load执行也是可以的.
例子的话,参考: jenkins-jenkinsfile/jenkins.lotbrick.com/master
@Library('lotbrick') _
run(this)
def call(params){
// 定义jenkinsfile的路径
def jenkinsfile_dir = "/data/jenkins-jenkinsfile/"
node {
// 直接load加载Jenkinsfile的groovy文件,例如:jenkins.lotbrick.com/master,这时候Jenkins就会执行这段代码
load("${jenkinsfile_dir}/${params.env.JOB_NAME}")
}
}
- jenkins.lotbrick.com/master
pipeline {
agent any
options {
// 禁止同时运行多个流水线
disableConcurrentBuilds()
}
environment {
//多分支的流水线使用,获取当前Job的名字
PROJECT_NAME = sh(script: 'echo ${JOB_NAME%/*}', returnStdout: true).trim()
}
stages {
stage("并行执行") {
parallel {
stage('并行执行1') {
steps {
sh 'echo '这是并行执行 1 的步骤''
}
stage('并行执行2') {
steps {
sh 'echo '这是并行执行 2 的步骤''
}
}
}
}
stage('打印消息') {
steps{
echo "${PROJECT_NAME}"
}
}
}
}
总结
最后我们来分析一下执行的过程:
Jenkins扫描发现仓库的两个分支
运行master分支
jenkins调用master分支的Jenkinsfile
Jenkinfile中有libraries库,克隆库到workspace/JOB_NAME@libs
运行 run.groovy 中的 call函数
通过load加载其他的groovy文件
执行groovy文件中的pipeline
- 为什么我们要独立出一个仓库来放实际的pipeline呢,而不是像上面一样直接写在vars目录下
仔细看上面的执行过程,第4步,克隆库文件到workspace/JOB_NAME@libs,如果我们有十个JOB,那么Jenkins就会克隆十次.当我们把实际的pipeline写在vars目录下的时候,日积月累这个目录文件很多的时候,那么就会导致重复克隆,影响执行效率最要命的是,vars目录下的文件会直接变成全局的变量,可以直接调用的,变量太多.JAVA的内存消耗可以很恐怖的(感觉会这样)
我没有考虑多个node的情况,咱这只是个小公司,没这么多项目来发布但是我知道的一点就是,当pipeline的 agent选项为any的时候,Jenkins会默认把代码拉到当前node的workspace下,所以不需要再去拉一遍代码
