在查看一个数据的分布时,常用的可视化形式有直方图,密度分布图等,在seaborn中,相关的函数有以下几个 1. histplot.通过直方图来展示数据分布 2. kdeplot,通过密度分布图来展示数据分
在查看一个数据的分布时,常用的可视化形式有直方图,密度分布图等,在seaborn中,相关的函数有以下几个
1. histplot. 通过直方图来展示数据分布
2. kdeplot, 通过密度分布图来展示数据分布
3. ecdfplot. 通过累积分布曲线来展示数据分布
4. rugplot. 通过x轴和y轴的边际分布来展示数据分布
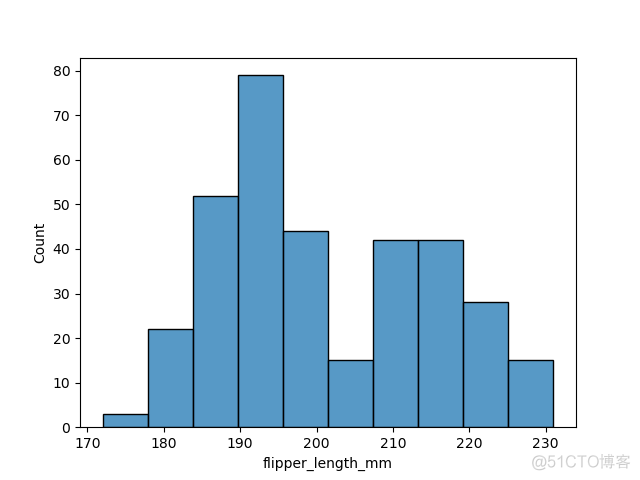
下面通过一些基本的例子来感受下各自的可视化形式,histplot示例如下
>>> df = pd.read_csv('penguins.csv')>>> sns.histplot(df, x='flipper_length_mm')
>>> plt.show()
输出结果如下
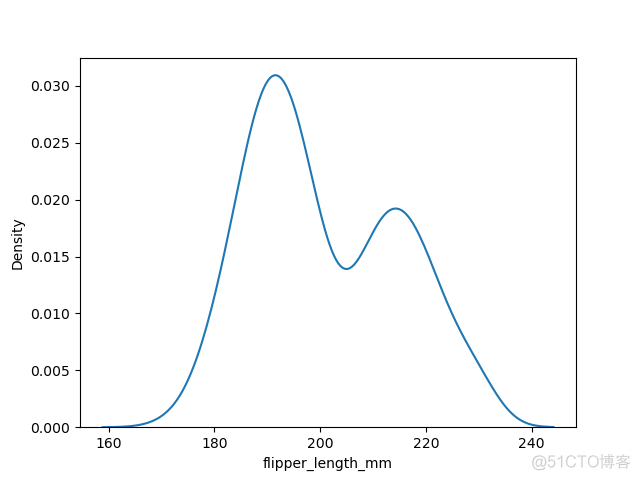
kedplot示例如下
>>> sns.kdeplot(data=df, x='flipper_length_mm')>>> plt.show()
输出结果如下
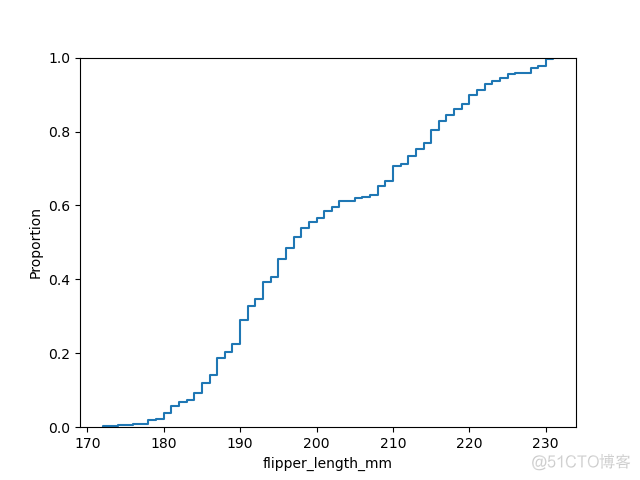
ecdfplot示例如下
>>> sns.ecdfplot(data=df, x='flipper_length_mm')>>> plt.show()
输出结果如下
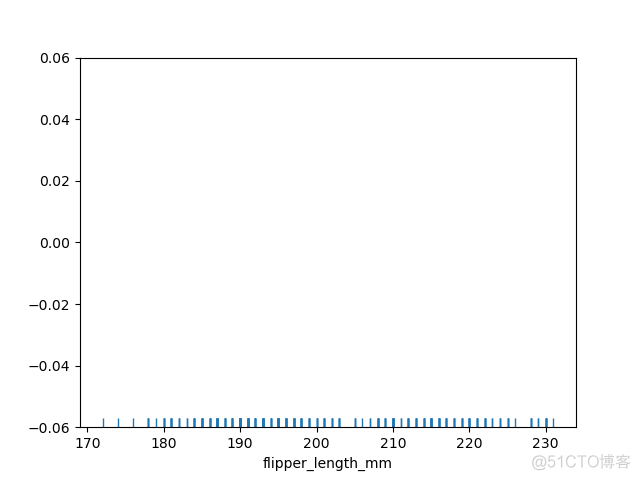
rugplot示例如下
>>> sns.rugplot(data=df, x='flipper_length_mm')>>> plt.show()
输出结果如下
在实际使用中,histplot和kdeplot是使用的最高频的,其次是rugplot, 最后是ecdfplot。对于这一类函数而言,有许多的通用参数,以histplot为例,来看下这些参数的作用
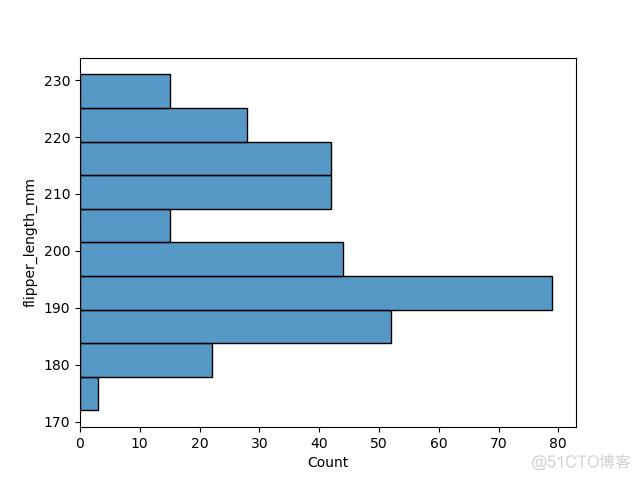
1. x和y
数据分布通常是对数据框中的某一列进行查看,通过切换x和y参数,可以将图表倒置,示例如下
>>> sns.histplot(df, y='flipper_length_mm')>>> plt.show()
输出结果如下
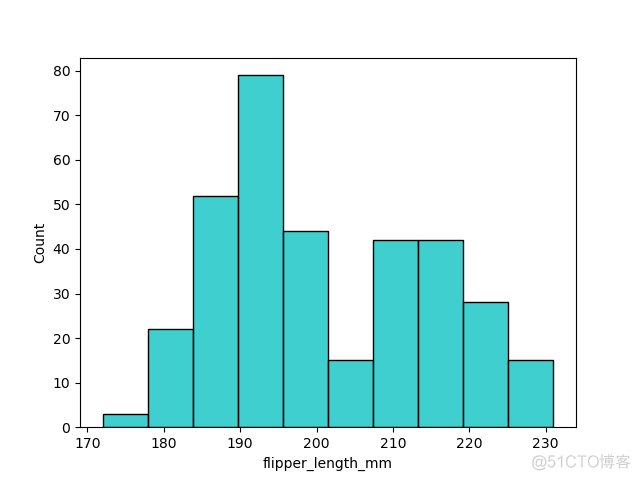
2. color
color参数控制填充的颜色,示例如下
>>> sns.histplot(df, x='flipper_length_mm', color='c')>>> plt.show()
输出结果如下
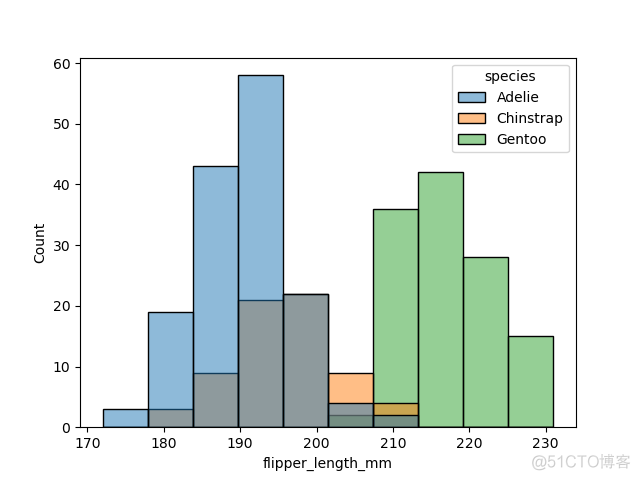
3. hue
数据分布也是支持属性映射的,但是可以映射的属性就只有颜色属性了,所以只支持hue参数,示例如下
>>> sns.histplot(df, x="flipper_length_mm", hue="species")>>> plt.show()
输出结果如下
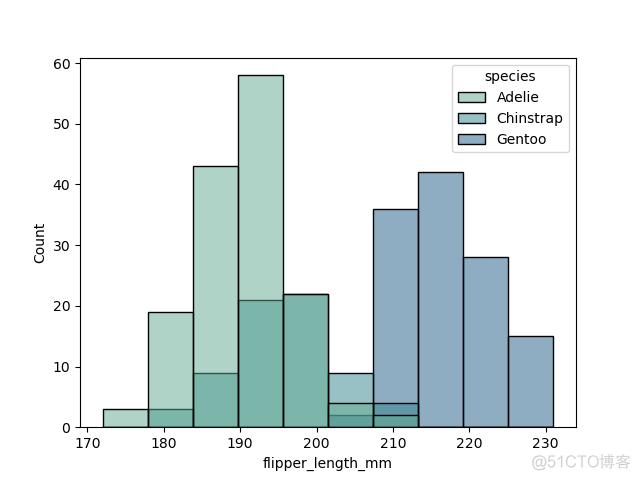
4. pattle
pattle参数用于指定颜色梯度,示例如下
>>> sns.histplot(df, x="flipper_length_mm", hue="species",palette="crest")>>> plt.show()
输出结果如下
除了通用参数外,每个函数还有自己专属的一些参数,这些参数很多,无法一一详细描述,可以通过官网的API文档详细查看。
这几个函数对应的高阶函数为displot, 基本用法如下
>>> sns.displot(data=df, x="flipper_length_mm", hue="species", col="sex", kind="kde")>>> plt.show()
输出结果如下
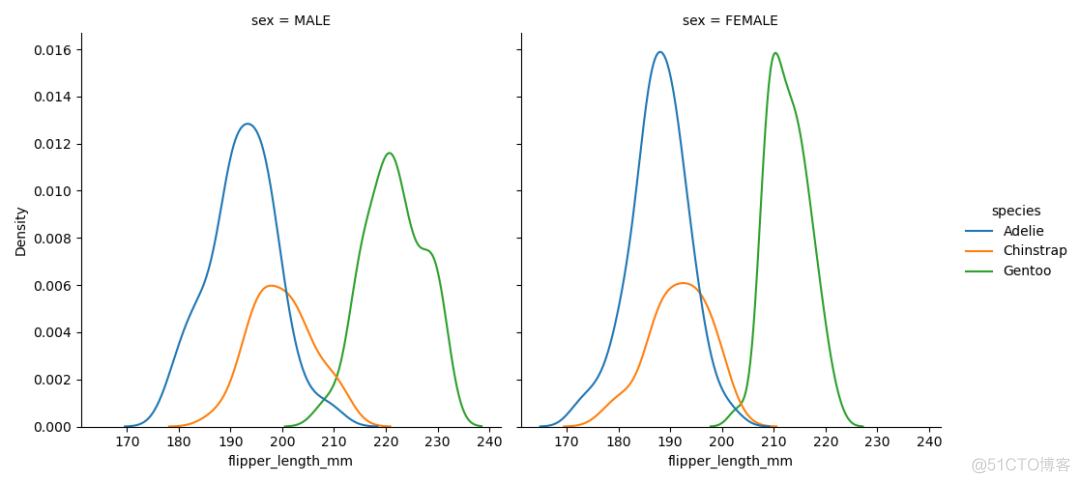
通过kind参数来指定调用的子函数,通过col和row参数来实现分面的效果。
·end·

一个只分享干货的
生信公众号