编写一段程序,从网站上抓取特定资源,比如自动化的下载kegg colorful pathway的通路图,这样的程序就是一个基础的网络爬虫了。在python中,通过内置模块urlib, 可以实现常规的网页抓
编写一段程序,从网站上抓取特定资源,比如自动化的下载kegg colorful pathway的通路图,这样的程序就是一个基础的网络爬虫了。在python中,通过内置模块urlib, 可以实现常规的网页抓取任务。
该内置模块包含以下4个子模块
其中urllib.request 子模块是最常用的,用来从网站获取源代码。基本用法如下
import urllib.requestf = urllib.request.urlopen('https://www.python.org/')
f.read().decode('utf-8')
该用法适用于处理简单的GET请求的网站资源,除了GET外,还要一种POST提交方式,需要从表单中获取对应数据。对于post请求,urllib也可以轻松实现,用法如下
import urllib.parseimport urllib.request
url = 'https://www.test.com'
# 表单数据用字典来存储
params = {
'gene':'tp53',
'pages':'10'
}
# 使用parse对url进行正确的编码
data = bytes(urllib.parse.urlencode(params), encoding='utf8')
response = urllib.request.urlopen(url, data=data)
response.read().decode('utf-8')
urllib还有更加高级的玩法,举例如下
1. 模拟浏览器
火狐,谷歌等网页浏览器可以与网站交互,显示对应的网页,以谷歌浏览器为例,通过快捷键F12的调试模式,可以看到浏览器在发送HTTP请求时的头文件,截图如下
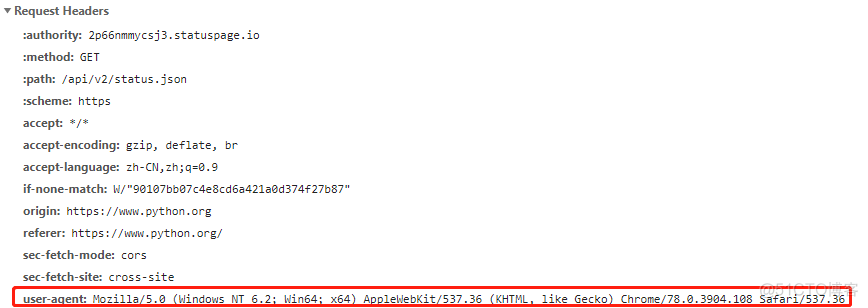
其中,红框表示的部分就是浏览器的标识,拷贝其中的信息,就可以将程序伪装成浏览器来与网站进行交互,用法如下
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
request = urllib.request.Request('https://www.python.org/', headers = headers)
response = urllib.request.urlopen(request)
response.read().decode('utf-8')
部分网站禁止爬虫程序来获取其资源,如果识别到一个不是浏览器的请求,会进行拦截,伪装成浏览器,可以通过网站反爬虫机制的第一个封锁线。
2. 网站登录
对于需要登录后才可以获取的网页,爬取的方式如下
url = 'https://www.test.com/'user = 'root'
password = 'passwd'
# 先进行账号,密码的验证
pwdmgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
pwdmgr.add_password(None,url ,user ,password)
auth_handler = urllib.request.HTTPBasicAuthHandler(pwdmgr)
opener = urllib.request.build_opener(auth_handler)
response = opener.open(url)
response.read().decode('utf-8')
一个健壮的爬虫程序是需要考虑很多的因素的,通过内置的urllib只是可以满足大多数自动化下载的需求,如果要功能更加强大和晚上的爬虫,就需要借助第三方模块以及成熟的爬虫框架了。
·end·

一个只分享干货的
生信公众号