网络爬虫是一个从网站上自动下载数据,并进行格式化整理的计算机程序,近几年网络爬虫工程师这一职位,也是相当多火热。python作为一个全能型选手,进行爬虫开发也是不在话下。
网络爬虫是一个从网站上自动下载数据,并进行格式化整理的计算机程序,近几年网络爬虫工程师这一职位,也是相当多火热。python作为一个全能型选手,进行爬虫开发也是不在话下。
开发一个网络爬虫,我们需要以下几个方面的基础
1. 网页内容下载
爬虫的首要任务就是能够从网站上抓取数据,在python中, 常用的模块有以下几个
1. urllib
2. request
3. selenium
urllib是内置模块,提供了基础的下载功能,request属于第三方模块,提供了更加便利的接口,selenium是一个自动化浏览器测试的模块,适用于处理动态网页的抓取。
2. html内容清洗
我们需要的是只是网页中的部分内容,所以下载之后,我们需要进行数据清洗工作,从原始数据中提取我们需要的信息,常用的提取的技术有以下两种
1. 正则表达式
2. xpath表达式
在实际使用中,也可以通过beautifulsoup等第三方模块来提取数据。
3. 数据库内容的存储
对于需要大量的数据,可以将提取的数据存储到数据库中,提高检索效率,此时就是需要使用python与数据库进行交流,常用的数据库有以下几个
1. sqlite
2. mysql
3. monogodb
在实际开发中,为了应对网站的反爬虫机制,我们还需要掌握更多的技能,比如用户代理,IP代理,cookie账号登录,网页抓包分析等,下面是一个大神总结的爬虫和反爬虫之间你来我往的较量机制
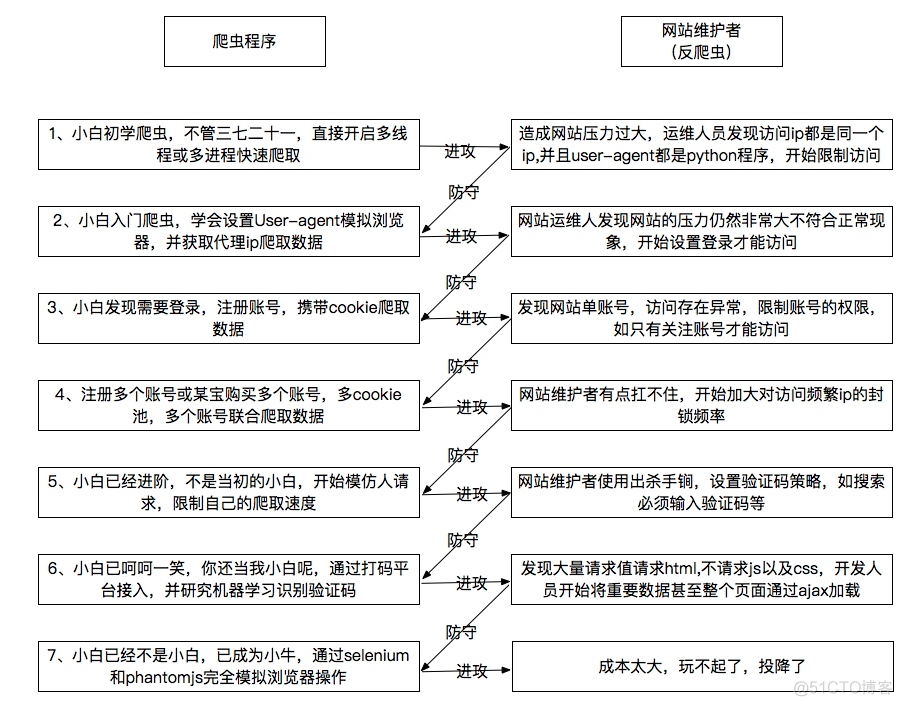
也给我们清晰的展示了学习爬虫开发的路径,在后续的章节,我会按照这个图谱来更新相关的内容。
·end·
—如果喜欢,快分享给你的朋友们吧—
关注我们,解锁更多精彩内容!
