 本文档隶属于《Spring Data JPA用法与技能探究》系列的第一篇。本系列文档规划对Spring Data JPA进行全方位的使用介绍。通过本篇内容,对JAVA体系中DB操作相关的组件、规范等有一定初步了解,也大致了解了应该如何选择是使用JPA还是MyBatis选型。
本文档隶属于《Spring Data JPA用法与技能探究》系列的第一篇。本系列文档规划对Spring Data JPA进行全方位的使用介绍。通过本篇内容,对JAVA体系中DB操作相关的组件、规范等有一定初步了解,也大致了解了应该如何选择是使用JPA还是MyBatis选型。

序言
Spring Data JPA作为Spring Data中对于关系型数据库支持的一种框架技术,属于ORM的一种,通过得当的使用,可以大大简化开发过程中对于数据操作的复杂度。本文档隶属于《
Spring Data JPA用法与技能探究》系列的第一篇。本系列文档规划对Spring Data JPA进行全方位的使用介绍,一共分为5篇文档,如果感兴趣,欢迎关注交流。《Spring Data JPA用法与技能探究》系列涵盖内容:
- 开篇介绍 —— 《JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?一文带你厘清个中曲直,给你个选择SpringDataJPA的理由!》
- 快速上手 —— 《SpringBoot集成JPA介绍》
- 深度进阶 —— 《JPA核心类型与用法介绍》
- 可靠保障 —— 《聊一聊数据库的事务,以及Spring体系下对事务的使用》
- 周边扩展 —— 《JPA开发辅助效率提升方案介绍》
本章节主要对Spring Data JPA的整体情况以及与其相关的一些概念进行一个简单的介绍。
在具体介绍Spring Data JPA之前,我们可以先来思考一个问题: 在JAVA中,如果需要操作DB,应该怎么做?
很多人可能首先想到的就是集成一些框架然后去操作就行了、比如mybatis、Hibernate框架之类的。
当然,也可能会有人想起JDBC。
再往深入想一下:
- JAVA里面的写的一段DB操作逻辑,是如何一步步被传递到DB中执行了的呢?
- 为什么JAVA里面可以去对接不同产商的DB产品?
- 为什么有JDBC、还会有各种mybatis或者诸如Hibernate等ORM框架呢?
- 这些JDBC、JPA、ORM、Hibernate等等相互之间啥关系?
- 除了MyBatis、Hibernate等习以为常的内容,是否还有其他操作DB的方案呢?
- ...
带着这些问题,我们接下来一步步的进行探讨,先树立对Spring Data JPA的正确印象。
1. 需要厘清的若干概念 1.1. JDBC谈到JAVA操作数据库相关的概念,JDBC是绕不过去的一个概念。
先来介绍下JDBC究竟是个什么概念。
JDBC(Java DataBase Connectivity),是java连接数据库操作的原生接口。
JDBC对Java程序员而言是API,为数据库访问提供标准的接口。由各个数据库厂商及第三方中间件厂商依照JDBC规范为数据库的连接提供的标准方法。
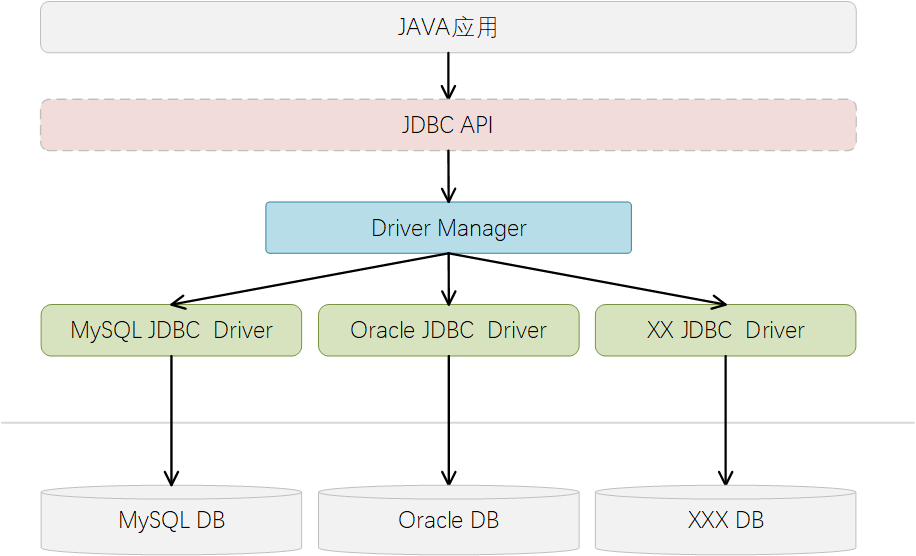
概念阐述的可能稍微有点抽象,说的直白点可以这么理解:各个产商的DB产品很多,JAVA联合各个DB产商定了个规范,JAVA可以按照规范去编写代码,就可以用相同的操作方法去操作不同产商的DB了。也就是说JDBC是JAVA与各个DB产商之间的一个约定规范、约束的是DB产商的实现规范。
基于JDBC,我们可以在JAVA代码中去执行DB操作,如下示意:
package com.txw.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
@SuppressWarnings("all") // 注解警告信息
public class JdbcTest01 {
public static void main(String[] args) throws Exception {
// 1.加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2 创建和数据库之间的连接
String username = "testdb";
String password = "testxxxxxx";
String url = "jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghai";
Connection conn = DriverManager.getConnection(url,username,password);
// 3.准备发送SQL
String sql = "select * from t_person";
PreparedStatement pstm = conn.prepareStatement(sql);
// 4.执行SQL,接收结果集
ResultSet rs = pstm.executeQuery();
// 5 处理结果集
while(rs.next()){
int personId1 = rs.getInt("person_id");
String personName1 = rs.getString("person_name");
int age1 = rs.getInt("age");
String sex1 = rs.getString("sex");
String mobile1 = rs.getString("mobile");
String address1 = rs.getString("address");
System.out.println("personId="+personId1+",personName="+personName1
+",age="+age1+",sex="+sex1+",mobile="+mobile1+",address="+address1);
}
// 6.释放资源
rs.close();
pstm.close();
conn.close();
}
}
从上面代码示例中可以看出JDBC的几个操作关键环节:
- 根据使用的DB类型不同,加载对应的JdbcDriver
- 连接DB
- 编写SQL语句
- 发送到DB中执行,并接收结果返回
- 对结果进行处理解析
- 释放过程中的连接资源
从演示代码里面,还可以看出,直接基于JDBC进行操作DB的时候,其弊端还是比较明显的:
- 业务代码里面耦合了字符串格式SQL语句,复杂场景维护起来比较麻烦;
- 非结构化的key-value映射方式处理结果,操作过于复杂,且不符合JAVA面向对象的思想;
- 需要关注过程资源的释放、操作不当容易造成泄露。
也正是由于JDBC上述比较明显的弊端,纯基于JDBC操作DB一般仅用于一些小型简单的场景,正式大型项目中,往往很少有直接基于JDBC进行编码开发的,而是借助一些封装框架来实现。
1.2. ORM框架对象-关系映射(Object-Relational Mapping,简称ORM)。ORM框架中贯穿着JAVA面向对象编程的思想,是面向对象编程的优秀代言人。
直白点说,ORM就是将代码里面的JAVA类与DB中的table表进行映射,代码中对相关JAVA类的操作,即体现为DB中对相关Table的操作。
ORM框架很好的解决了JDBC存在的一系列问题,简化了JAVA开发人员的编码复杂度。
1.3. JPA介绍JPA, 即Java Persistence API的缩写,也即JAVA持久化层API,这个并非是一个新的概念,其实在JDK5.x版本中就已经引入的一个概念。其宗旨是为POJO提供一个基于ORM的持久化操作的标准规范。
涵盖几个方面:
-
一套标准API
在javax.persistence的包下面提供,用来操作实体对象,执行CRUD操作,将开发者从烦琐的JDBC和SQL代码中解脱出来,按照JAVA思路去编写代码操作DB。 -
面向对象操作语言
通过面向对象的思路,避免代码与SQL的深度耦合。 -
ORM元数据映射
ORM,即Object Relation Mapping,对象关系映射。
JAVA应用程序,可以通过JPA规范,利用一些常见的基于JPA规范的框架来实现对DB的操作。而常见的一些ORM框架,比如Hibernate、EclipseLink、OpenJPA等等,其实都是提供了对JPA规范的支持,是JPA规范的具体实现提供者,用于辅助JAVA程序对数据库数据的操作。
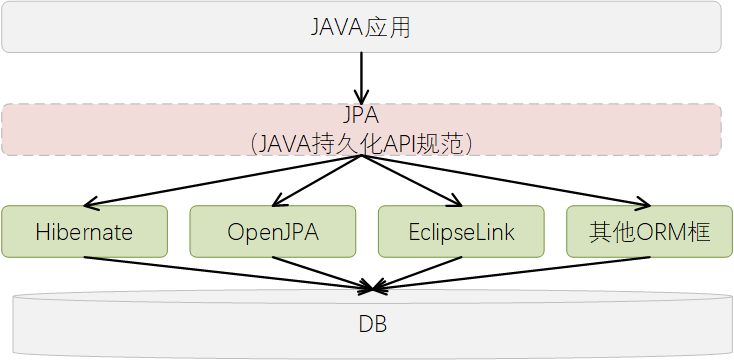
基于前面介绍,我们了解到JPA的基本概念,知晓JPA其实是一个基于ORM的JAVA API规范定义,那么这里提及的Spring Data JPA又是什么呢?其与JPA之间的关系又是如何呢?
Spirng Data JPA是Spring提供的一套简化JPA开发的框架,按照约定好的【方法命名规则】写DAO层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作,同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查询等等。

注意
Spring Data JPA不是一个完整JPA规范的实现,它只是一个代码抽象层,主要用于减少为各种持久层存储实现数据访问层所需的代码量。其底层依旧是Hibernate。
可以把Spring Data JPA理解为JPA规范的再次封装抽象。
hibernate是一个标准的orm框架,实现jpa接口。
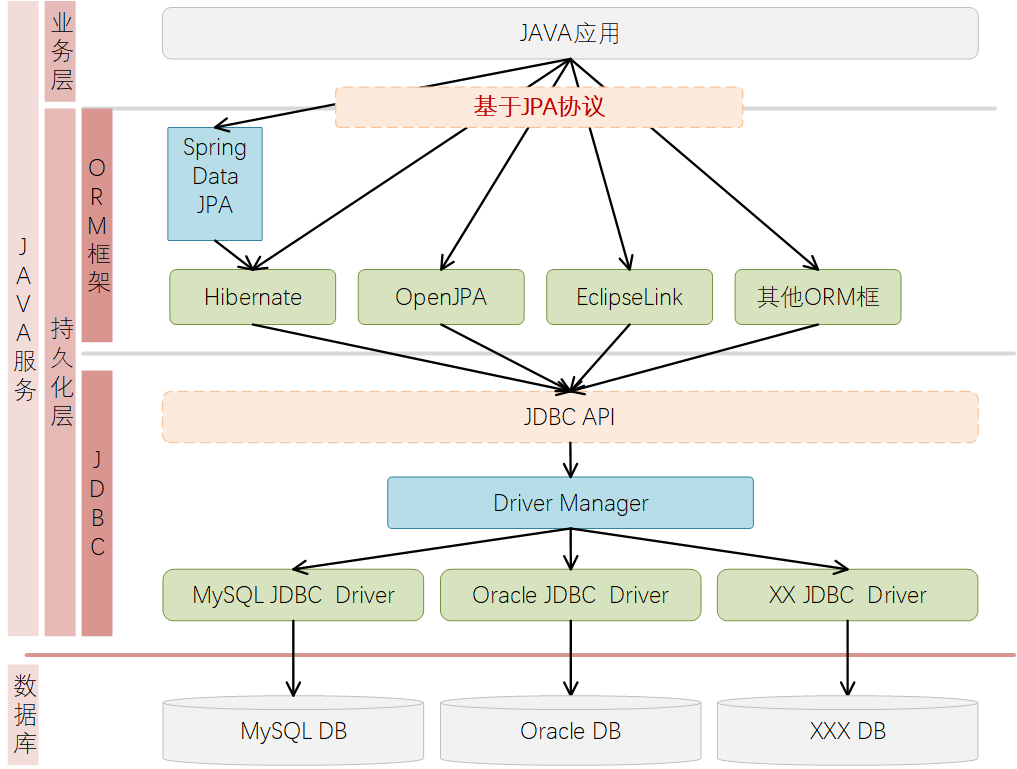
1.6. JDBC,ORM,JPA,Spring Data JPA之间到底啥关系一个简单粗暴的理解方式:
- JDBC是JAVA操作最终数据库的底层接口,JDBC是与各个DB产商之间约定的协议规范,基于这些规范,可在JAVA代码中往DB执行SQL操作。
- 因为JDBC负责将SQL语句执行到DB中,属于相对原始的接口,业务代码里面需要构建拼接出SQL语句,然后基于JDBC去DB中执行对应SQL语句。这样存在的问题会比较明显,JAVA代码中需要耦合大量的SQL语句、且因为缺少封装,实际业务编码使用时会比较繁琐、维护复杂。
- 为了能够将代码与SQL语句分离开,以一种更符合JAVA面向对象编程思维的方式来操作DB,诞生了ORM(Object Relation Mapping, 对象关系映射)概念,ORM将JAVA的Object与DB中的Table进行映射起来,管理Object也等同于对Table的管理与操作,这样就可以实现没有SQL的情况下实现对DB的操作。常见的ORM框架有
Hibernate、EclipseLink、OpenJPA等等。 - 为了规范ORM的具体使用,JAVA 5.x开始制定了基于ORM思想的Java持久化层操作API规范,也即JPA(注意,JPA只是一个基于ORM的JAVA API规范,供各个ORM框架提供API时遵循),当前主流ORM框架都是支持JPA规范的。
- Spring框架盛行的时代,为了能够更好适配,Spring Data JPA诞生, 这个可以理解为对JPA规范的二次封装(可以这么理解:Spring Data JPA不是一个完整JPA规范的实现,它只是一个代码抽象层,主要用于减少为各种持久层存储实现数据访问层所需的代码量),其底层使用的依旧是常规ORM框架(Hibernate)。
相互之间的关系详解,见下图示意。
在介绍Spring Data JPA的优势前,先看个代码例子。
场景:
一张用户表(UserEntity),信息如下:
代码中实现如下诉求:
(1)获取所有研发部门的人员:
List<UserEntity> users = userReposity.findAllByDepartment("DevDept");
(2)获取研发部门的管理员:
List<UserEntity> users = userReposity.findAllByDepartmentAndRole("DevDept", "Admin");
看完上面的例子,一个最直观的感受是什么?
简单!
没错,“简单”就是Spring Data JPA最大的优势!
对于大部分的常规操作,基于Spring Data JPA,开发人员可以更加专注于业务逻辑的开发,而不用花费太多的精力去关注DB层面的封装处理以及SQL的编写维护,甚至在DAO层都不需要去定义接口。
除了简化开发,JPA还有的另一个比较大的优势,就是其可移植性比较好,因为其通过JPQL的方式进行操作,与原生SQL之间几乎没有耦合,所以可以方便的将底层DB切换到别的类型。
2.2. Spring Data JPA整体实现逻辑基于前面的介绍,我们可以这样理解,JAVA业务层调用SpringData JPA二次封装提供的Repository层接口,进而基于JPA标准API进行处理,基于Hibernate提供的JPA具体实现,接着基于JDBC标准API接口,完成与实际DB之间的请求交互。整体的处理逻辑全貌图如下:
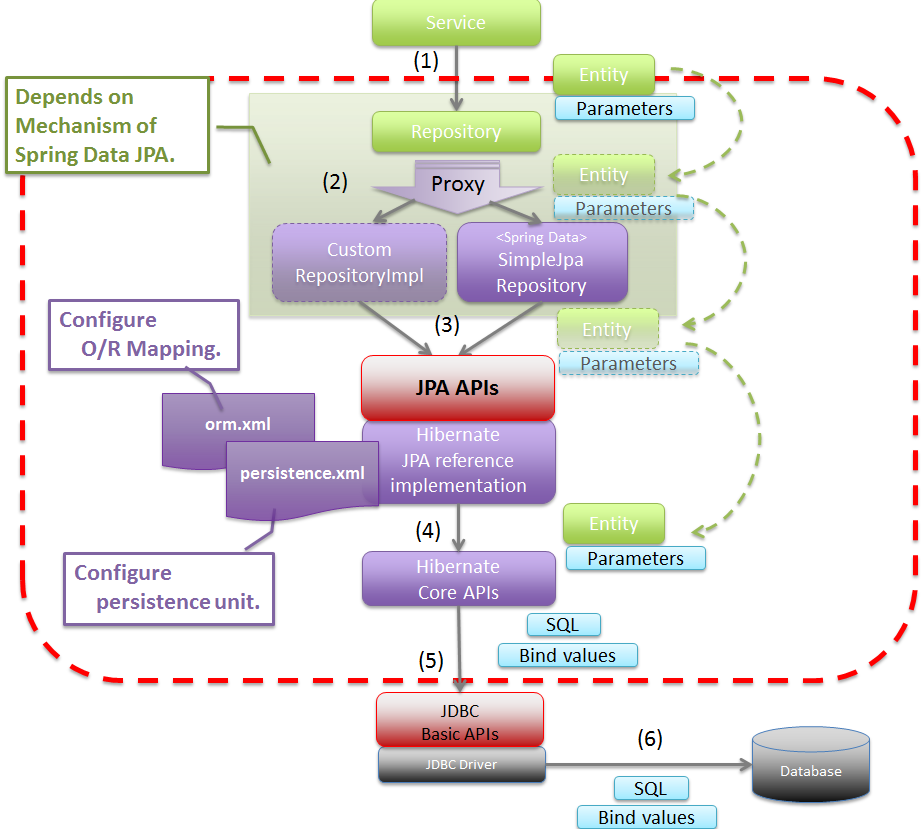
这里可以看出,JPA、Hibernate、SpringData JPA三者之间的关系:
- JPA(Java Persistence API)是规范,它指明了持久化、读取和管理 Java 对象映射到数据库表时的规范。
- Hibernate 则是一个 ORM 框架,它实现了 Java 对象到数据库表的映射。也就是说,Hibernate 提供了 JPA 的一种实现。
- Spring Data JPA 是 Spring Framework 的一部分。它不是 JPA 的实现,而是在 JPA 之上提供更高层次的抽象,可以减少很多模板代码。而 Spring Data JAP 的默认实现是 Hibernate,当然也可以其他的 JPA Provider。
提到JPA, 那么MyBatis绝对是无法回避的一个内容。的确,作为JAVA持久化层的优秀框架,MyBatis甚至是很多开发人员在项目构建初期脑海中唯一的选型方案。那么,JPA想要从MyBatis占领地中分一杯羹,究竟是具有哪方面的优势呢?
先来了解下MyBatis。
MyBatis是一款优秀的持久层框架,它支持定制化SQL、存储过程以及高级映射。MyBatis 避免了几乎全部的JDBC代码和手动设置参数以及获取结果集。MyBatis可使用简单的XML或注解来配置和映射原生信息,将接口和Java的POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
优势:
- MyBatis则是一个可以灵活编写sql语句
- MyBatis避免了几乎全部的JDBC代码和手动设置参数以及获取结果集,相比JDBC更方便
MyBatis与JPA的差异点:
- 设计哲学不同,MyBatis偏向于面向过程,JPA则将面向对象发挥到极致;
- MyBatis定制起来更加灵活,支持高度定制化的sql语句,支持任意编写sql语句;JPA相对更注重对已有高频简单操作场景的封装,简化开发人员的重复操作,虽然JPA也支持定制SQL语句,但是相比MyBatis灵活度略差。
至此,到底如何在JPA与MyBatis之间抉择,就比较清晰了:
- 如果你的系统中对DB的操作没有太多额外的深度定制、对DB的执行性能也不是极度敏感、不需要基于SQL语句做一些深度的优化,大部分场景都是一些基础CRUD操作,则无疑Spring Data JPA是比较理想的选择,它将大大降低开发人员在DB操作层面的投入精力。
- 如果你的业务中对DB高阶逻辑依赖太深,比如大部分场景都需要额外定制复杂SQL语句来实现,或者系统对性能及其敏感,需要基于Table甚至column维度进行深度优化,或者数据量特别巨大的场景,则相比较而言,MyBatis提供的调优定制灵活性上要更有优势一些。
综上分析,其实MyBatis与Spring Data JPA其实没有一个绝对的维度来评价谁更优一些,具体需要结合自身的实际诉求来选择。
再看个有意思的数据,此前有人统计过使用百度、谷歌等搜素引擎搜素JPA与Mybatis关键字的搜索热度与区域的数据,如下所示:

从图中可以看出,MyBatis在中国地区相对更受欢迎一些,但是在国外JPA的受欢迎度要更高一些。
3. 小结,承上启下好啦,本篇内容就介绍到这里。
通过本篇内容,对JAVA体系中DB操作相关的组件、规范等有了一定初步的了解,也大致了解了应该如何选择是使用JPA还是MyBatis选型。
后续几篇系列文章中,将会一步步的介绍下Spring Data JPA的核心内容与具体项目实现,一步步的揭开JPA的庐山真面目。
如果通过本文介绍,你对JPA也有进一步了解的兴趣,欢迎关注我的后续系列文档。
如果对本文有自己的见解,或者有任何的疑问或建议,都可以留言,我们一起探讨、共同进步。
我是悟道君,聊技术、又不仅仅聊技术~
期待与你一起探讨,一起成长为更好的自己。
