作为一个常年在一线带组的Owner以及老面试官,我们面试的目标基本都是一线的开发人员。从服务端这个技术栈出发,问题的范围主要还是围绕开发语言(Java、Go)等核心知识点、数据库技术、缓存技术、消息中间件、微服务框架的使用等几个方面来提问。
MySQL作为大厂的主流数据存储配置,当然是被问的最多的,而其中重点区域就是索引的使用和优化。
- 正确理解和计算索引字段的区分度,下面是计算规则,区分度高的索引,可以快速得定位数据,区分度太低,无法有效的利用索引,可能需要扫描大量数据页,和不使用索引没什么差别。我们创建索引的时候,尽量选择区分度高的列作为索引。
selecttivity = count(distinct c_name)/count(*)
- 正确理解和计算前缀索引的字段长度,下面是判断规则,合适的长度要保证高的区分度和最恰当的索引存储容量,只有达到最佳状态,才是保证高效率的索引。下买呢长度为6的时候是最佳状态。
select count(distinct left(c_name , calcul_len)) / count(*) from t_name;
mysql> SELECT
count(DISTINCT LEFT(empname, 3)) / count(*) AS sel3,
count(DISTINCT LEFT(empname, 4)) / count(*) AS sel4,
count(DISTINCT LEFT(empname, 5)) / count(*) AS sel5,
count(DISTINCT LEFT(empname, 6)) / count(*) AS sel6,
count(DISTINCT LEFT(empname, 7)) / count(*) AS sel7
FROM
emp;
+--------+--------+--------+--------+--------+
| sel3 | sel4 | sel5 | sel6 | sel7 |
+--------+--------+--------+--------+--------+
| 0.0012 | 0.0076 | 0.0400 | 0.1713 | 0.1713 |
+--------+--------+--------+--------+--------+
1 row in set
- 联合索引注意最左匹配原则:按照从左到右的顺序匹配,MySQL会一直向右匹配索引直到遇到范围查询(>、<、between、like)然后停止匹配。如 depno=1 and empname>'' and job=1 ,如果建立(depno,empname,job)顺序的索引,empname 和 job是用不到索引的。
- 应需而取策略,查询记录的时候,不要一上来就使用*,只取需要的数据,可能的话尽量只利用索引覆盖,可以减少回表操作,提升效率。
- 正确判断是否使用联合索引( 策略篇 联合索引的使用那一小节有说明判断规则),也可以进一步分析到索引下推(IPC),减少回表操作,提升效率。
- 避免索引失效的原则:禁止对索引字段使用函数、运算符操作,会使索引失效。这是实际上就是需要保证索引所对应字段的”干净度“。
- 避免非必要的类型转换,字符串字段使用数值进行比较的时候会导致索引无效。
- 模糊查询'%value%'会使索引无效,变为全表扫描,因为无法判断扫描的区间,但是'value%'是可以有效利用索引。
- 索引覆盖排序字段,这样可以减少排序步骤,提升查询效率
- 尽量的扩展索引,非必要不新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
- 无需强制索引顺序,比如 建立(depno,empno,jobno)顺序的索引,你可以是 empno = 1 and jobno = 2 and depno = 8。因为MySQL的查询优化器会根据实际索引情况进行顺序优化,所以这边不强制顺序一致性。但是同等条件下还是按照顺序进行排列,比较清晰,并且节省查询优化器的处理。
explain命令大家应该很熟悉,具体用法和字段含义可以参考官网explain-output,这里需要强调rows是核心指标,绝大部分rows小的语句执行一定很快,因为扫描的内容基数小。
所以优化语句基本上都是在优化降低rows值。
注意几个核心关键参数:possible_keys、key、rows、select_type,对于优化指导很有意义。
- select_type:表示查询中每个select子句的类型(Simple、Primary、Depend SubQuery)
- possible_keys :指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询使用
- key:key列显示MySQL实际决定使用的键(索引),未走索引是null
- rows:表示MySQL根据表统计信息及索引选用情况,估算所需要扫描的行数
慢查询优化基本步骤
- 先运行查看实际耗时,判断是否真的很慢(注意设置SQL_NO_CACHE)。
- 高区分度优先策略:where条件单表查,锁定最小返回记录表的条件。
就是查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高。区分度高的字段往前排。 - explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
- order by limit 形式的sql语句让排序的表优先查
- 了解业务方的使用场景,根据使用场景适时调整。
- 加索引时参照建上面索引的十大原则
- 观察结果,不符合预期继续从第一步开始分析
下面几个例子详细解释了如何分析和优化慢查询。
复杂查询条件的分析
一般来说我们编写SQL的方式是为了 是实现功能,在实现功能的基础上保证MySQL的执行效率也是非常重要的,这要求我们对MySQL的执行计划和索引规则有非常清晰的理解,分析下面的案例:
1 mysql> select a.*,b.depname,b.memo from emp a left join
2 dep b on a.depno = b.depno where sal>100 and a.empname like 'ab%' and a.depno=106 order by a.hiredate desc ;
3 +---------+---------+---------+---------+-----+---------------------+------+------+-------+------------+----------+
4 | id | empno | empname | job | mgr | hiredate | sal | comn | depno | depname | memo |
5 +---------+---------+---------+---------+-----+---------------------+------+------+-------+------------+----------+
6 | 4976754 | 4976754 | ABijwE | SALEMAN | 1 | 2021-01-23 16:46:24 | 2000 | 400 | 106 | kDpNWugzcQ | TYlrVEkm |
7 ......
8 +---------+---------+---------+---------+-----+---------------------+------+------+-------+------------+----------+
9 744 rows in set (4.958 sec)
总共就查询了744条数据,却耗费了4.958的时间,我们看一下目前表中现存的索引以及索引使用的情况分析
1 mysql> show index from emp;
2 +-------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
4 +-------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
5 | emp | 0 | PRIMARY | 1 | id | A | 4952492 | NULL | NULL | | BTREE | | |
6 | emp | 1 | idx_emo_depno | 1 | depno | A | 18 | NULL | NULL | | BTREE | | |
7 +-------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
8 2 rows in set
9
10 mysql> explain select a.*,b.depname,b.memo from emp a left join
11 dep b on a.depno = b.depno where sal>100 and a.empname like 'ab%' and a.depno=106 order by a.hiredate desc ;
12 +----+-------------+-------+------+---------------+---------------+---------+-------+--------+-----------------------------+
13 | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
14 +----+-------------+-------+------+---------------+---------------+---------+-------+--------+-----------------------------+
15 | 1 | SIMPLE | a | ref | idx_emo_depno | idx_emo_depno | 3 | const | 974898 | Using where; Using filesort |
16 | 1 | SIMPLE | b | ref | idx_dep_depno | idx_dep_depno | 3 | const | 1 | NULL |
17 +----+-------------+-------+------+---------------+---------------+---------+-------+--------+-----------------------------+
18 2 rows in set
可以看出,目前在emp表上除了主键只存在一个索引 idx_emo_depno ,作用在部门编号字段上,该索引的目标是过滤出具体部门编号下的数据。
通过explain 分析器可以看到 where条件后面是走了 idx_emo_depno 索引,但是也比较了 97W的数据,说明该字段的区分度并不高,根据高区分度优先原则,我们对这个表的三个查询字段分别进行区分度计算。
1 mysql> select count(distinct empname)/count(*),count(distinct depno)/count(*),count(distinct sal)/count(*) from emp;
2 +----------------------------------+--------------------------------+------------------------------+
3 | count(distinct empname)/count(*) | count(distinct depno)/count(*) | count(distinct sal)/count(*) |
4 +----------------------------------+--------------------------------+------------------------------+
5 | 0.1713 | 0.0000 | 0.0000 |
6 +----------------------------------+--------------------------------+------------------------------+
7 1 row in set
这是计算结果,empname的区分度最高,所以合理上是可以建立一个包含这三个字段的联合索引,顺序如下:empname、depno、sal;
并且查询条件重新调整了顺序,符合最左匹配原则;另一方面根据应需而取的策略,把b.memo字段去掉了。
1 mysql> select a.*,b.depname from emp a left join
2 dep b on a.depno = b.depno where a.empname like 'ab%' and a.depno=106 and a.sal>100 order by a.hiredate desc ;
3 +---------+---------+---------+---------+-----+---------------------+------+------+-------+------------+
4 | id | empno | empname | job | mgr | hiredate | sal | comn | depno | depname |
5 +---------+---------+---------+---------+-----+---------------------+------+------+-------+------------+
6 | 4976754 | 4976754 | ABijwE | SALEMAN | 1 | 2021-01-23 16:46:24 | 2000 | 400 | 106 | kDpNWugzcQ |
7 ......
8 +---------+---------+---------+---------+-----+---------------------+------+------+-------+------------+
9 744 rows in set (0.006 sec)
这边还有一个问题,那就是联合索引根据最左匹配原则:必须按照从左到右的顺序匹配,MySQL会一直向右匹配索引直到遇到范围查询(>、<、between、like)然后停止匹配。
所以语句中 执行到a.empname 字段,因为使用了like,后面就不再走索引了。在这个场景中, 独立的empname字段上的索引和这个联合索引效率是差不多的。
另外排序字段hiredate也可以考虑到覆盖到索引中,会相应的提高效率。
无效索引的分析
有一个需求,使用到了用户表 userinfo 和消费明细表 salinvest ,目的想把2020年每个用户在四个品类等级(A1、A2、A3、A4)上的消费额度进行统计,所以便下了如下的脚本:
1 select (@rowNO := @rowNo+1) AS id,bdata.* from
2 (
3 select distinct a.usercode,a.username,
4 @A1:=IFNULL((select sum(c.ltimenum) from `salinvest` c where c.usercode=a.usercode AND c.gravalue='A1'
5 and c.logdate between '2020-01-01' and '2020-12-31'),0) as A1,
6 @A2:=IFNULL((select sum(c.ltimenum) from `salinvest` c where c.usercode=a.usercode AND c.gravalue='A2'
7 and c.logdate between '2020-01-01' and '2020-12-31'),0) as A2,
8 @A3:=IFNULL((select sum(c.ltimenum) from `salinvest` c where c.usercode=a.usercode AND c.gravalue='A3'
9 and c.logdate between '2020-01-01' and '2020-12-31'),0) as A3,
10 @A4:=IFNULL((select sum(c.ltimenum) from `salinvest` c where c.usercode=a.usercode AND c.gravalue='A4'
11 and c.logdate between '2020-01-01' and '2020-12-31'),0) as A4,
12 ,(@A1+@A2+@A3+@A4) as allnum
13 from userinfo a
14 inner JOIN `salinvest` b on a.usercode = b.usercode
15 where b.logdate between '2020-01-01' and '2020-12-31'
16 order by allnum desc
17 ) as bdata,(SELECT @rowNO:=0) b;
这个查询看起来貌似没什么问题 ,虽然用到了复合查询、子查询,但是如果索引做的正确,也不会有什么问题。那我们来看看索引,有一个联合索引,符合我们最左匹配原则和高区分度优先原则:
1 mysql> show index from salinvest;
2 +------------+------------+------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
4 +------------+------------+------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
5 | lnuminvest | 0 | PRIMARY | 1 | autocode | A | 5 | NULL | NULL | | BTREE | | |
6 | lnuminvest | 1 | idx_salinvest_complex | 1 | usercode | A | 2 | NULL | NULL | YES | BTREE | | |
7 | lnuminvest | 1 | idx_salinvest_complex | 2 | gravalue | A | 2 | NULL | NULL | YES | BTREE | | |
8 | lnuminvest | 1 | idx_salinvest_complex | 3 | logdate | A | 2 | NULL | NULL | YES | BTREE | | |
9 +------------+------------+------------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
10 4 rows in set
那我们来看看它的执行效率:
mysql> select (@rowNO := @rowNo+1) AS id,bdata.* from
(
select (@rowNO := @rowNo+1) AS id,bdata.* from
(
select distinct a.usercode,a.username,
@A1:=IFNULL((select sum(c.ltimenum) from `salinvest` c where c.usercode=a.usercode AND c.gravalue='A1'
and c.logdate between '2020-01-01' and '2020-12-31'),0) as A1,
@A2:=IFNULL((select sum(c.ltimenum) from `salinvest` c where c.usercode=a.usercode AND c.gravalue='A2'
and c.logdate between '2020-01-01' and '2020-12-31'),0) as A2,
@A3:=IFNULL((select sum(c.ltimenum) from `salinvest` c where c.usercode=a.usercode AND c.gravalue='A3'
and c.logdate between '2020-01-01' and '2020-12-31'),0) as A3,
@A4:=IFNULL((select sum(c.ltimenum) from `salinvest` c where c.usercode=a.usercode AND c.gravalue='A4'
and c.logdate between '2020-01-01' and '2020-12-31'),0) as A4,
,(@A1+@A2+@A3+@A4) as allnum
from userinfo a
inner JOIN `salinvest` b on a.usercode = b.usercode
where b.logdate between '2020-01-01' and '2020-12-31'
order by allnum desc
) as bdata,(SELECT @rowNO:=0) b;
+----+------------+---------+------+------+------+------+------+--------+
| id | usercode | username | A1 | A2 | A3 | A4 |allnum
+----+------------+---------+------+------+------+------+------+--------+
| 1 | 063105015 | brand | 789.00 | 1074.50 | 998.00 | 850.00 |
......
+----+------------+---------+------+------+------+------+------+--------+
6217 rows in set (12.745 sec)
我这边省略了查询结果,实际上结果输出6000多条数据,在约50W的数据中进行统计与合并,输出6000多条数据,花费了将近13秒,这明显是不合理的。
我们来分析下是什么原因:
1 mysql> explain select (@rowNO := @rowNo+1) AS id,bdata.* from
2 (
3 select distinct a.usercode,a.username,
4 @A1:=IFNULL((select sum(c.ltimenum) from `salinvest` c where c.usercode=a.usercode AND c.gravalue='A1'
5 and c.logdate between '2020-01-01' and '2020-12-31'),0) as A1,
6 @A2:=IFNULL((select sum(c.ltimenum) from `salinvest` c where c.usercode=a.usercode AND c.gravalue='A2'
7 and c.logdate between '2020-01-01' and '2020-12-31'),0) as A2,
8 @A3:=IFNULL((select sum(c.ltimenum) from `salinvest` c where c.usercode=a.usercode AND c.gravalue='A3'
9 and c.logdate between '2020-01-01' and '2020-12-31'),0) as A3,
10 @A4:=IFNULL((select sum(c.ltimenum) from `salinvest` c where c.usercode=a.usercode AND c.gravalue='A4'
11 and c.logdate between '2020-01-01' and '2020-12-31'),0) as A4,
12 ,(@A1+@A2+@A3+@A4) as allnum
13 from userinfo a
14 inner JOIN `salinvest` b on a.usercode = b.usercode
15 where b.logdate between '2020-01-01' and '2020-12-31'
16 order by allnum desc
17 ) as bdata,(SELECT @rowNO:=0) b;
18 +----+--------------------+------------+------------+--------+------------------------+------------------------+---------+-----------------------+------+----------+-----------------------------------------------------------+
19 | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
20 +----+--------------------+------------+------------+--------+------------------------+------------------------+---------+-----------------------+------+----------+-----------------------------------------------------------+
21 | 1 | PRIMARY | <derived8> | NULL | system | NULL | NULL | NULL | NULL | 1 | 100 | NULL |
22 | 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100 | NULL |
23 | 8 | DERIVED | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
24 | 2 | DERIVED | b | NULL | index | idx_salinvest_complex | idx_salinvest_complex | 170 | NULL | 5 | 20 | Using where; Using index; Using temporary; Using filesort |
25 | 7 | DEPENDENT SUBQUERY | c | NULL | ALL | idx_salinvest_complex | NULL | NULL | NULL | 5 | 20 | Using where |
26 | 6 | DEPENDENT SUBQUERY | c | NULL | ALL | idx_salinvest_complex | NULL | NULL | NULL | 5 | 20 | Using where |
27 | 5 | DEPENDENT SUBQUERY | c | NULL | ALL | idx_salinvest_complex | NULL | NULL | NULL | 5 | 20 | Using where |
28 | 4 | DEPENDENT SUBQUERY | c | NULL | ALL | idx_salinvest_complex | NULL | NULL | NULL | 5 | 20 | Using where |
29 +----+--------------------+------------+------------+--------+------------------------+------------------------+---------+-----------------------+------+----------+-----------------------------------------------------------+
30 9 rows in set
看最后四条数据,看他的possible_key和 实际的key,预估是走 idx_salinvest_complex 索引,实际是走了空索引,这个是为什么呢? 看前面的select_type 字段,值是 DEPENDENT SUBQUERY,了然了。
官方对 DEPENDENT SUBQUERY 的说明:子查询中的第一个SELECT, 取决于外面的查询 。
什么意思呢?它意味着两步:
第一步,MySQL 根据 select distinct a.usercode,a.username 得到一个大结果集 t1,这就是我们上图提示的6000用户。
第二步,上面的大结果集 t1 中的每一条记录,等同于与子查询 SQL 组成新的查询语句: select sum(c.ltimenum) from salinvest c where c.usercode in (select distinct a.usercode from userinfo a) 。
也就是说, 每个子查询要比较6000次,几十万的数据啊……即使这两步骤查询都用到了索引,但还是会很慢。
这种情况下, 子查询的执行效率受制于外层查询的记录数,还不如拆成两个独立查询顺序执行呢。
这种慢查询的解决办法,网上有很多方案,最常用的办法是用联合查询代替子查询,可以自己去查一下。
3 适当的分库分表物理服务机的CPU、内存、存储设备、连接数等资源有限,某个时段大量连接同时执行操作,会导致数据库在处理上遇到性能瓶颈。为了解决这个问题,行业先驱门充分发扬了分而治之的思想,对大库表进行分割,
然后实施更好的控制和管理,同时使用多台机器的CPU、内存、存储,提供更好的性能。而分治有两种实现方式:垂直拆分和水平拆分。
垂直分库其实是一种简单逻辑分割,比如数据库中建立独立的商品库 Products、订单库Orders,积分库Scores 等。
3.2 垂直分表比较适用于那种字段比较多的表,假设我们一张表有100个字段,分析了一下当前业务执行的SQL语句,有20个字段是经常使用的,而另外80个字段使用比较少。把20个字段放在主表里面,我们再创建一个辅助表,存放另外80个字段。
3.3 库内分表按照一定的策略对单个大容量表进行拆分。
3.4 分库分表分库分表在库内分表的基础上,将分的表挪动到不同的主机和数据库上。可以充分的使用其他主机的CPU、内存和IO资源。
4 完整的索引知识体系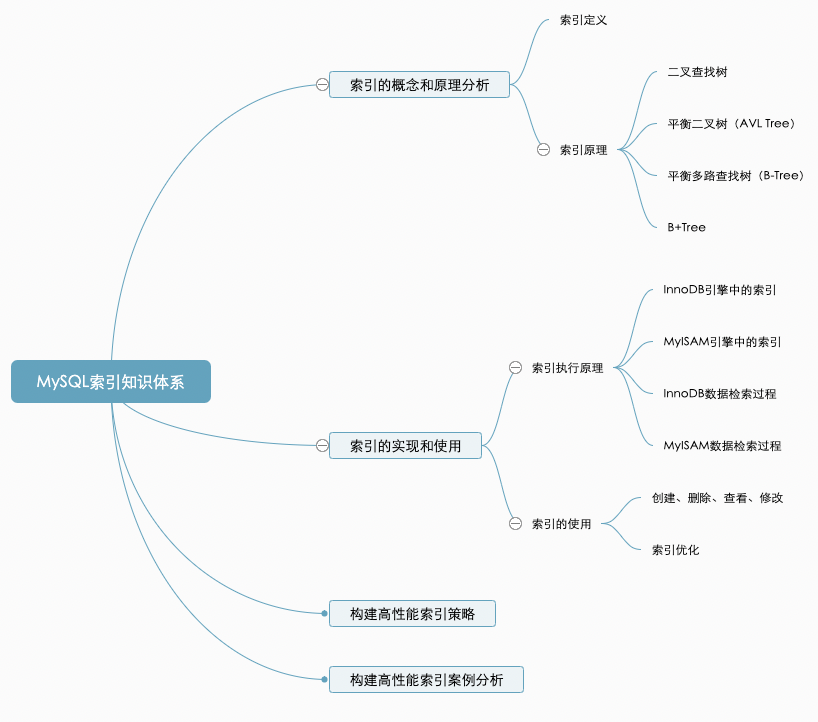
参考笔者之前写的索引四篇+分库分表两篇
MySQL全面瓦解22:索引的介绍和原理分析
MySQL全面瓦解23:MySQL索引实现和使用
MySQL全面瓦解24:构建高性能索引(策略篇)
MySQL全面瓦解25:构建高性能索引(案例分析篇)
MySQL全面瓦解28:分库分表
MySQL全面瓦解29:分库分表之Partition功能详解
 架构与思维·公众号:撰稿者为bat、字节的几位高阶研发/架构。不做广告、不卖课、不要打赏,只分享优质技术
★ 加公众号获取学习资料和面试集锦
码字不易,欢迎关注,欢迎转载
架构与思维·公众号:撰稿者为bat、字节的几位高阶研发/架构。不做广告、不卖课、不要打赏,只分享优质技术
★ 加公众号获取学习资料和面试集锦
码字不易,欢迎关注,欢迎转载