数据结构:jdk版本:1.8
HashMap的底层主要基于数组+链表/红黑树实现,数组优点就是查询块,HashMap通过计算hash码获取到数组的下标来查询数据。同样也可以通过hash码得到数组下标,存放数据。
哈希表为了解决冲突,HashMap采用了链表法,添加的数据存放在链表中,如果发送冲突,将数据放入链表尾部。
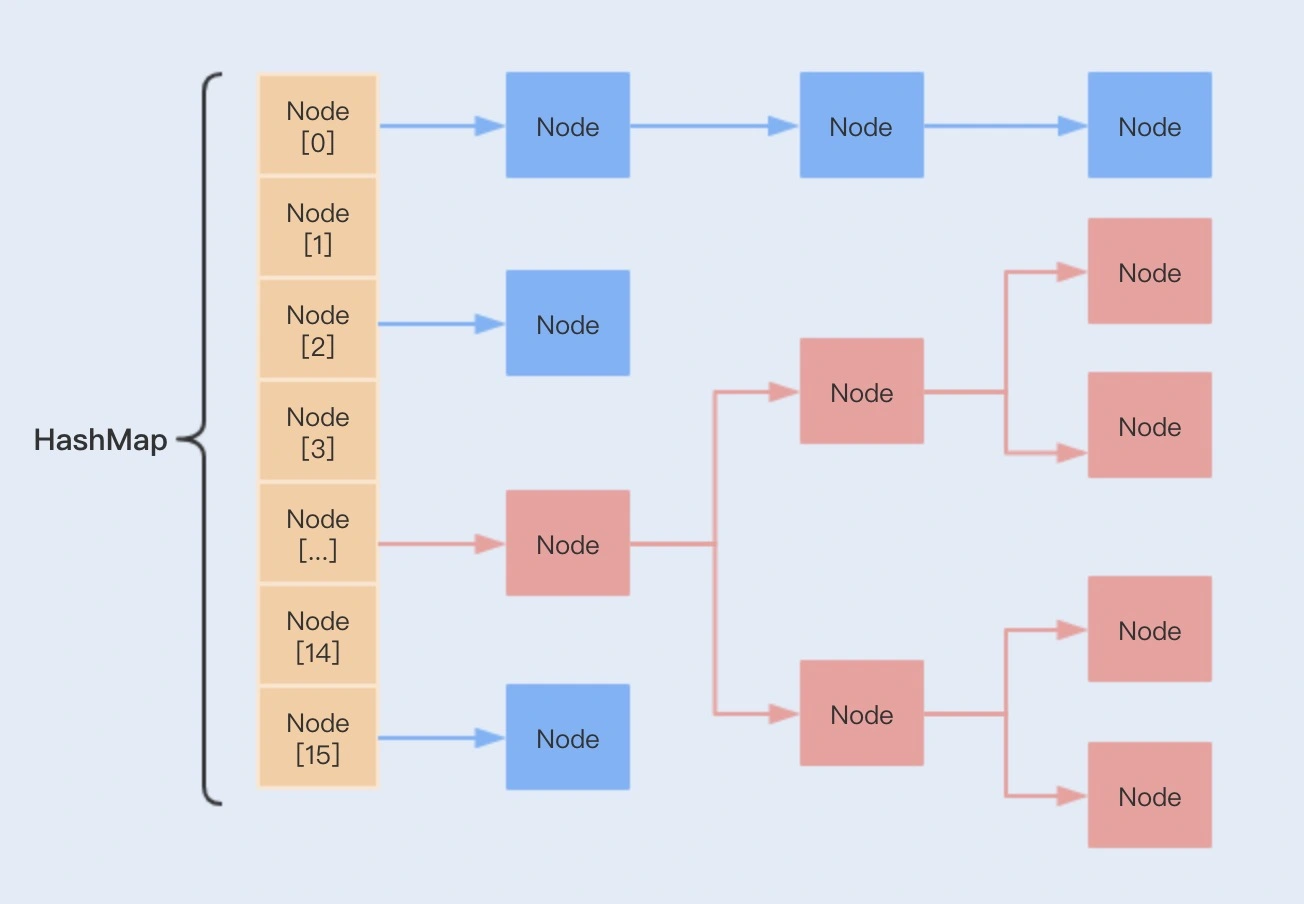
上图左侧部分是一个哈希表,也称为哈希数组(hash table):
// table数组
transient Node<K,V>[] table;
table数组的引用类型是Node节点,数组中的每个元素都是单链表的头结点,链表主要为了解决上面说的hash冲突,Node节点包含:
hashhash值key键value值nextnext指针
Node节点结构如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
// 省略 get/set等方法
}
// 储存元素数组
Node<K,V>[] table;
// 元素个数
int size;
// 数组扩容临界值,计算为:元素容量*装载因子
int threshold
// 装载因子,默认0.75
float loadFactor;
// 链表长度为 8 的时候会转为红黑树
int TREEIFY_THRESHOLD = 8;
// 长度为 6 的时候会从红黑树转为链表
int UNTREEIFY_THRESHOLD = 6;
- size记录元素个数
- threshold 扩容的临界值,等于元素容量*装载因子
- TREEIFY_THRESHOLD 8 链表个数增加到
8会转成红黑树 - UNTREEIFY_THRESHOLD 6 链表个数减少到
6会退化成链表 - loadFactor 装载因子,默认为
0.75
获取哈希数组下标loadFactor 装载因子等于扩容阈值/数组长度,表示元素被填满的程序,越高表示空间利用率越高,但是
hash冲突的概率增加,链表越长,查询的效率降低。越低hash冲突减少了,数据查询效率更高。但是示空间利用率越低,很多空间没用又继续扩容。为了均衡查询时间和使用空间,系统默认装载因子为0.75。
添加、删除和查找方法,都需要先获取哈希数组的下标位置,首先通过hash算法算出hash值,然后再进行长度取模,就可以获取到元素的数组下标了。
首先是调用hash方法,计算出hash值:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
先获取hashCode值,然后进行高位运算,高位运算后的数据,再进行取模运算的速度更快。
算出hash值之后,再进行取模运算:
(n - 1) & hash
上面的n是长度,计算的结果就是数组的下标了。
/**
* default initial capacity (16)
* the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
设置默认装载因子0.75,默认容量16。
// 指定初始值大小
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 指定初始值和默认装载因子 0.75
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0),,
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
HashMap(int initialCapacity) 指定初始容量,调用HashMap(int initialCapacity, float loadFactor) 其中loadFactor为默认的0.75。
首先做容量的校验,小于零报错,大于最大容量赋值最大值容量。然后做装载因子的校验,小于零或者是非数字就报错。
tableSizeFor使用右移和或运算,保证容量是2的幂次方,传入2的幂次方,返回传入的数据。传入不是2的幂次方数据,返回大于传入数据并接近2的幂次方数。比如:
- 传入
10返回16。 - 传入
21返回32。
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
将集合m的数据添加到HashMap集合中,先设置默认装载因子,然后调用putMapEntries添加集合元素到HashMap中,putMapEntries是遍历数组,添加数据。
本文基于jdk1.8解析HashMap源码,主要介绍了:
HashMap是基于数组+链表/红黑树结构实现。采用链表法解决hash冲突。- Node 节点记录了数据的
key、hash、value以及next指针。 HashMap主要属性:- size 元素个数
- table[] 哈希数组
- threshold 扩容的阈值
- loadFactor 装载因子
- TREEIFY_THRESHOLD 8,链表个数为8转成红黑树。
- UNTREEIFY_THRESHOLD 6 ,链表个数为6红黑树转为链表。
- 添加、删除以及查找元素,首先要先获取数组下标,
HashMap先调用hasCode方法,hashCode()的高16位异或低16位,大大的增加了运算速度。然后再对数组长度进行取模运算。本质就是取key的hashCode值、高位运算、取模运算。 HashMap几个构造方法:HashMap()设置默认装载因子0.75和默认容量16。HashMap(int initialCapacity)设置初始容量,默认装载因子0.75,容量是一定要是2的幂次方,如果不是2的幂次方,增加到接近2的幂次方数。HashMap(Map<? extends K, ? extends V> m)主要是遍历添加的集合,添加数据。
深入浅出HashMap的设计与优化
Java 8系列之重新认识HashMap
感觉不错的话,就点个赞吧!