 集群部署“兵马未动,粮草先行”,与其盲目上马一套Kafka环境然后事后费力调整,不如一开始就思考好实际场景下业务所需的集群环境。本文从Kafka集群众多的参数配置项选取了一些特别特别重要的参数配置做了介绍,相信了解这些参数配置之后,对于我们后续优化Kafka集群配置会大有裨益。
1 如何规划Kafka
集群部署“兵马未动,粮草先行”,与其盲目上马一套Kafka环境然后事后费力调整,不如一开始就思考好实际场景下业务所需的集群环境。本文从Kafka集群众多的参数配置项选取了一些特别特别重要的参数配置做了介绍,相信了解这些参数配置之后,对于我们后续优化Kafka集群配置会大有裨益。
1 如何规划Kafka
集群部署“兵马未动,粮草先行”,与其盲目上马一套Kafka环境然后事后费力调整,不如一开始就思考好实际场景下业务所需的集群环境。在考量部署方案时需要通盘考虑,不能仅从单个维度上进行评估,下面是几个重要的维度的考量和建议:
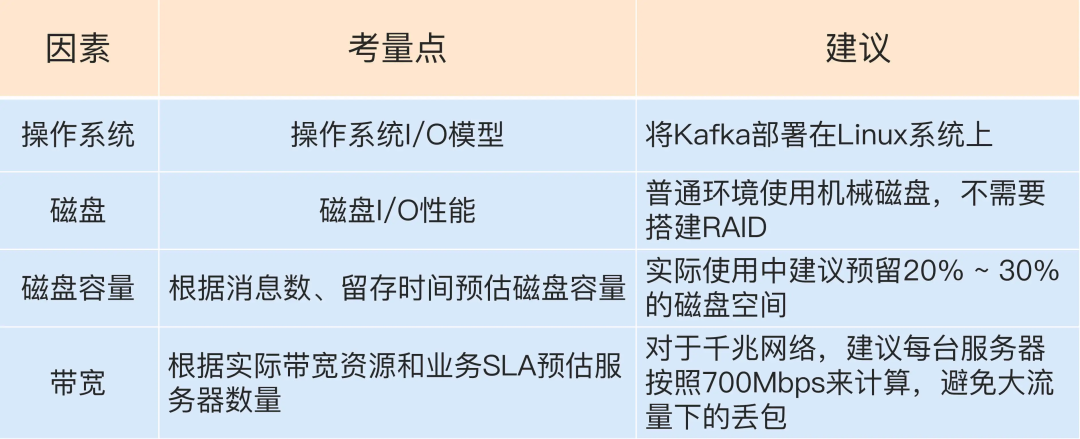
这里重点说说操作系统的因素。Linux系统比其他系统(特别是Windows系统)更加适合部署Kafka,主要体现在三个方面:
-
I/O模型的使用
-
数据网络传输效率
-
社区支持度
一句话总结:在Linux部署Kafka能够享受到零拷贝技术带来的快速数据传输特性。
2 一些重要的集群参数配置我们从多个维度来看看分别有哪些重要的集群参数:
Broker端参数(1)与存储信息相关的参数
log.dirs 必填,线上环境一定要配置多个路径,有条件最好挂载到不同的物理磁盘,可以提高读写性能和实现故障转移。
/home/kafka1,/home/kafka2,/home/kafka3
log.dir 非必填,建议不填。
(2)与ZooKeeper相关的参数
zookeeper.connect是与zookeeper相关的最重要的参数,没有之一。
zk1:2181,zk2:2181,zk3:2181
(3)与Broker连接相关的参数
listeners:监听器,告诉外部连接通过什么协议访问指定主机名和端口的Kafka服务。这里的协议名称可能是标准的名字,比如 PLAINTEXT 表示明文传输、SSL 表示使用 SSL 或 TLS 加密传输等。
PLAINTEXT://0.0.0.0:9091
advertised.listeners:这组监听器是Broker用于对外发布的。
PLAINTEXT://kafka1:9091
(4)关于Topic管理的参数
auto.create.topics.enable:是否允许自动创建topic,建议线上环境将其设置为false,即不允许自动创建Topic。
auto.leader.rebalance.enable:是否允许Kafka定期对一些Topic分区进行Leader重新选举,建议线上环境设置为false,因为换一次Leader成本很高。
(5)关于数据留存的参数
log.retention.{hours|minutes|ms}:这是个“三兄弟”,都是控制一条消息数据被保存多长时间。从优先级上来说 ms 设置最高、minutes 次之、hours 最低。
虽然 ms 设置有最高的优先级,但是通常情况下我们还是设置 hours 级别的多一些,比如log.retention.hours=168表示默认保存 7 天的数据,自动删除 7 天前的数据。
log.retention.bytes:这是指定 Broker 为消息保存的总磁盘容量大小。
这个值默认是 -1,表明你想在这台 Broker 上保存多少数据都可以,至少在容量方面 Broker 绝对为你开绿灯,不会做任何阻拦。这个参数真正发挥作用的场景其实是在云上构建多租户的 Kafka 集群:设想你要做一个云上的 Kafka 服务,每个租户只能使用 100GB 的磁盘空间,为了避免有个“恶意”租户使用过多的磁盘空间,设置这个参数就显得至关重要了。
message.max.bytes:控制 Broker 能够接收的最大消息大小。
这个值默认的 1000012 太少了,还不到 1MB。实际场景中突破 1MB 的消息都是屡见不鲜的,因此在线上环境中设置一个比较大的值还是比较保险的做法。毕竟它只是一个标尺而已,仅仅衡量 Broker 能够处理的最大消息大小,即使设置大一点也不会耗费什么磁盘空间的。
Topic级别参数retention.ms:规定了该 Topic 消息被保存的时长。默认是 7 天,即该 Topic 只保存最近 7 天的消息。一旦设置了这个值,它会覆盖掉 Broker 端的全局参数值。
retention.bytes:规定了要为该 Topic 预留多大的磁盘空间。和全局参数作用相似,这个值通常在多租户的 Kafka 集群中会有用武之地。当前默认值是 -1,表示可以无限使用磁盘空间。
对于Topic级别的参数,建议统一使用kafka-configs来修改Topic级别的参数。例如,下面使用了kafka-configs命令将发送消息的最大值改为10MB。
bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name transaction --alter --add-config max.message.bytes=10485760JVM级别参数
KAFKA_HEAP_OPTS:指定堆大小。
KAFKA_JVM_PERFORMANCE_OPTS:指定 GC 参数。
例如,我们可以这样启动 Kafka Broker,即在启动 Kafka Broker 之前,先设置上这两个环境变量:
$> export KAFKA_HEAP_OPTS=--Xms6g --Xmx6g操作系统级别参数
$> export KAFKA_JVM_PERFORMANCE_OPTS= -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true
$> bin/kafka-server-start.sh config/server.properties
通常情况下,Kafka 并不需要设置太多的 OS 参数,下面列出几个最好关注一下的因素:
-
文件描述符限制
-
通常情况下将它设置成一个超大的值是合理的做法,比如ulimit -n 1000000。
-
文件系统类型
-
根据官网的测试报告,XFS 的性能要强于 ext4,所以生产环境有条件的话最好还是使用 XFS。
-
Swappiness
-
建议将 swappniess 配置成一个接近 0 但不为 0 的值,比如 1。
-
提交时间
-
这个定期就是由提交时间来确定的,默认是 5 秒。一般情况下我们会认为这个时间太频繁了,可以适当地增加提交间隔来降低物理磁盘的写操作。
本文从Kafka集群众多的参数配置项选取了一些特别特别重要的参数配置做了介绍,相信了解这些参数配置之后,对于我们后续优化Kafka集群配置会大有裨益。
参考资料极客时间,胡夕《Kafka核心技术与实战》
B站,尚硅谷《Kafka 3.x入门到精通教程》
