学习曲线是模型学习性能随经验或时间变化的曲线图。学习曲线是机器学习中广泛使用的诊断工具,用于从训练数据集中逐步学习的算法。 可以在训练期间每次更新后在训练数据集和保留验证数据集上评估模型,并且可以创建测量性能的图以显示学习曲线。在训练期间查看模型的学习曲线可用于诊断学习问题, 例如欠拟合或过拟合模型,以及训练和验证数据集是否具有适当的代表性。在这篇文章中,您将逐步理解学习曲线以及如何使用它们来诊断机器学习模型的学习和泛化行为,例如 图中显示了常见的学习问题。读完这篇文章,你会知道:
- 学习曲线是根据经验显示学习性能随时间变化的图表。
- 训练和验证数据集上模型性能的学习曲线可用于诊断欠拟合、过拟合或拟合良好的模型。
- 模型性能的学习曲线可用于诊断训练或验证数据集是否不能相对代表问题域。
1 机器学习中的学习曲线
通常,学习曲线是在 x 轴上显示时间或经验,在 y 轴上显示学习或改进的图。例如,如果您正在学习一种乐器,您的乐器技能可以在一年内每周进行评估并分配一个数字分数。 52 周的分数图是一条学习曲线,可以显示您对乐器的学习随着时间的推移发生了怎样的变化。
- 学习曲线:学习(y 轴)与经验(x 轴)的线图。
学习曲线广泛用于机器学习中,用于随着时间的推移逐步学习(优化其内部参数)的算法,例如深度学习神经网络。
用于评估学习的指标可能是最大化,这意味着更好的分数(更大的数字)表示更多的学习。 一个例子是分类准确性。
更常见的是使用最小化的分数,例如损失或错误,其中更好的分数(较小的数字)表示更多的学习,0.0 的值表示训练数据集被完美地学习并且没有犯错误。
在机器学习模型的训练过程中,可以评估模型在训练算法每一步的当前状态。 可以在训练数据集上对其进行评估,以了解模型“学习”的程度。 它也可以在不属于训练数据集的保留验证数据集上进行评估。 对验证数据集的评估可以了解模型的“泛化”程度。
- 训练学习曲线:根据训练数据集计算的学习曲线,可以了解模型的学习效果。
- 验证学习曲线:根据保留验证数据集计算的学习曲线,可以了解模型的泛化程度。
在训练和验证数据集的训练过程中,为机器学习模型创建双重学习曲线是很常见的。
在某些情况下,为多个指标创建学习曲线也很常见,例如在分类预测建模问题的情况下,可以根据交叉熵损失优化模型,并使用分类准确度评估模型性能。 在这种情况下,创建了两个图,一个用于每个度量的学习曲线,每个图可以显示两条学习曲线,一个用于训练数据集和验证数据集。
- 优化学习曲线:根据优化模型参数的指标计算的学习曲线,例如:loss。
- 性能学习曲线:根据评估和选择模型的指标计算的学习曲线,例如:accuracy。
2 诊断模型行为
学习曲线的形状和动态可用于诊断机器学习模型的行为,进而可能建议可用于改进学习和/或性能的配置更改类型。您可能会在学习曲线中观察到三种常见的动态; 他们是:
- 欠拟合。
- 过拟合。
- 正好拟合。
我们将通过示例仔细研究每一个。 这些示例将假设我们正在查看一个最小化指标,这意味着 y 轴上较小的相对分数表示更多或更好的学习。
2.1 欠拟合学习曲线
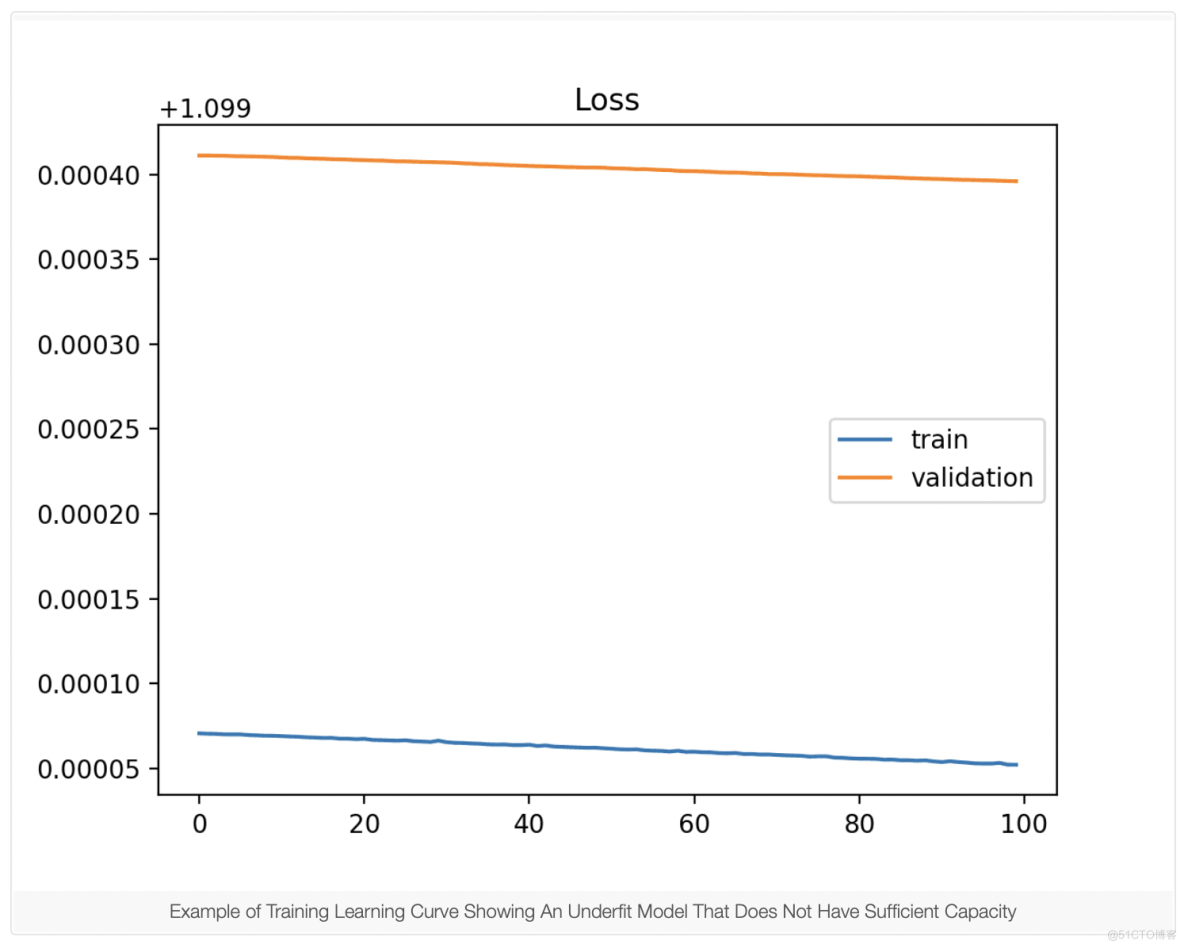
欠拟合是指无法学习训练数据集的模型。只能从训练损失的学习曲线中识别欠拟合模型。它可能会显示一条平坦的线或相对较高损失的噪声值,表明该模型根本无法学习训练数据集。下面提供了一个示例,当模型没有合适的容量来应对复杂性时很常见的数据集。
欠拟合模型也可以通过训练损失来识别,该损失正在减少并在图的末尾继续减少。这表明该模型能够进一步学习和可能的进一步改进,并且训练过程过早停止。
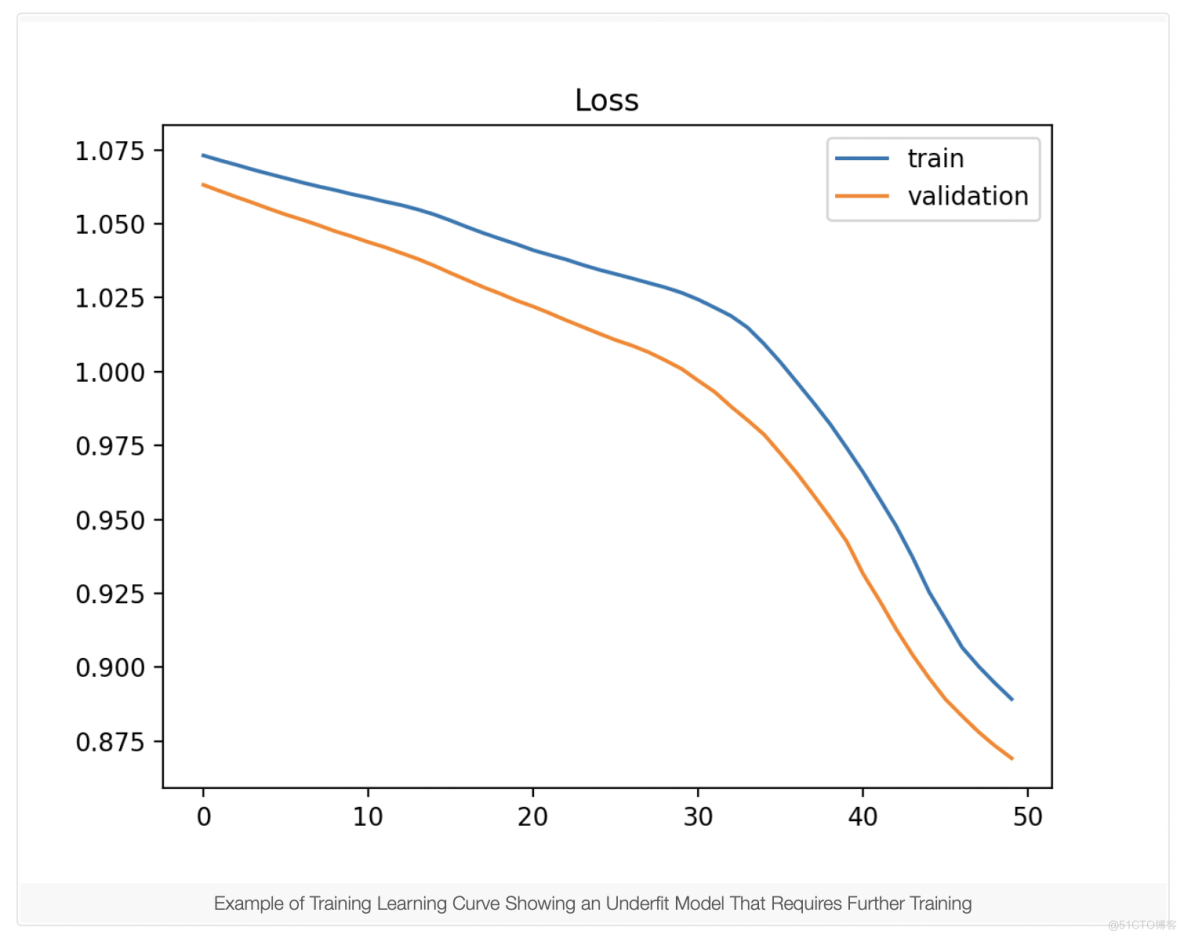
在以下情况下,学习曲线图显示拟合不足:
- 无论训练如何,训练损失都保持不变。
- 训练损失继续减少,直到训练结束。
2.2 过拟合学习曲线
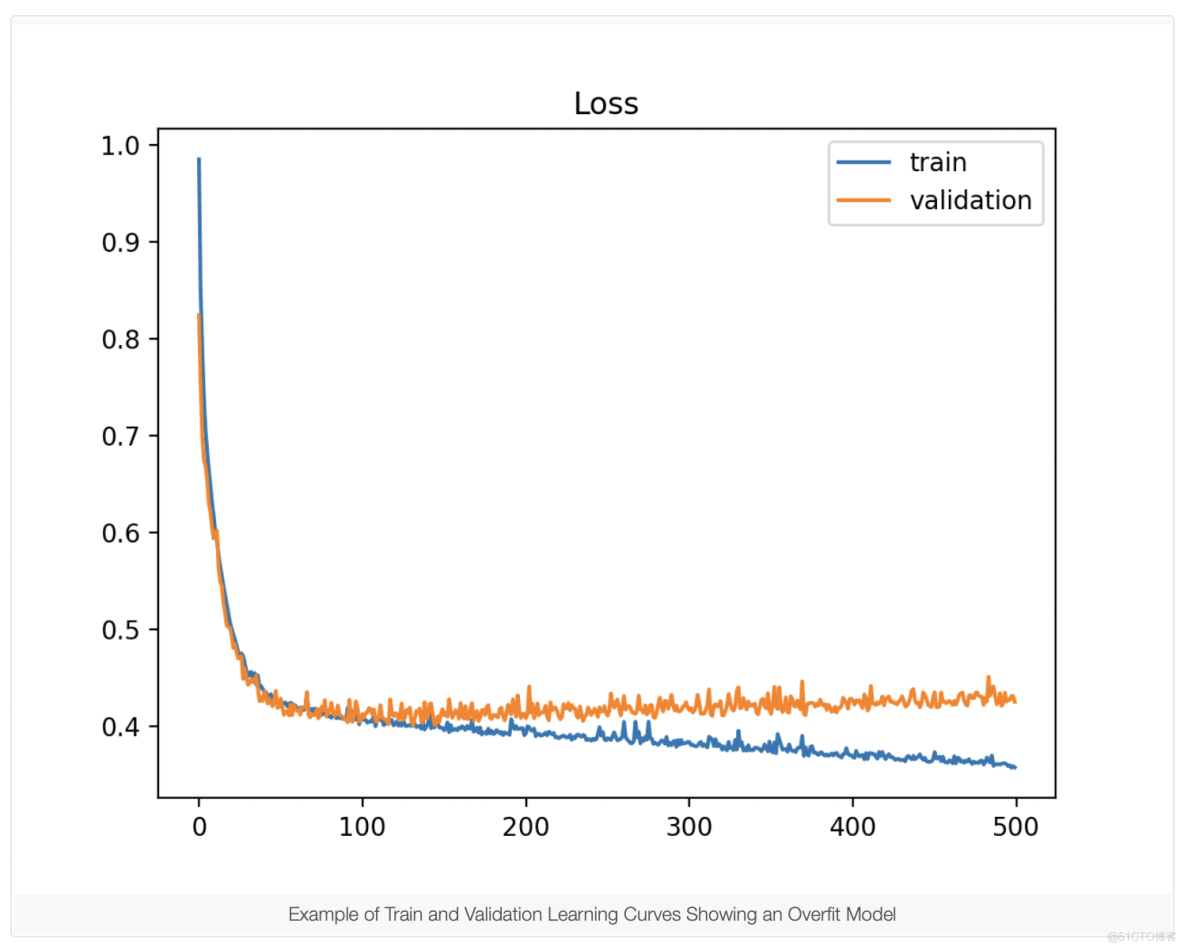
过度拟合是指模型对训练数据集的学习过好,包括训练数据集中的统计噪声或随机波动。过度拟合的问题在于,模型对训练数据越专业,它对新数据的泛化能力就越差,从而导致泛化误差增加。 这种泛化误差的增加可以通过模型在验证数据集上的性能来衡量。如果模型的容量超过问题所需的容量,并且反过来又具有太大的灵活性,则通常会发生这种情况。 如果模型训练时间过长,也会发生这种情况。
如果出现以下情况,学习曲线图会显示过度拟合:
- 随着经验的增加,训练损失图继续减少。
- 验证损失图减小到一个点并再次开始增加。
验证损失的拐点可能是训练可以停止的点,因为在该点之后的经验显示过拟合的动态。下面的示例图演示了一个过拟合的情况。
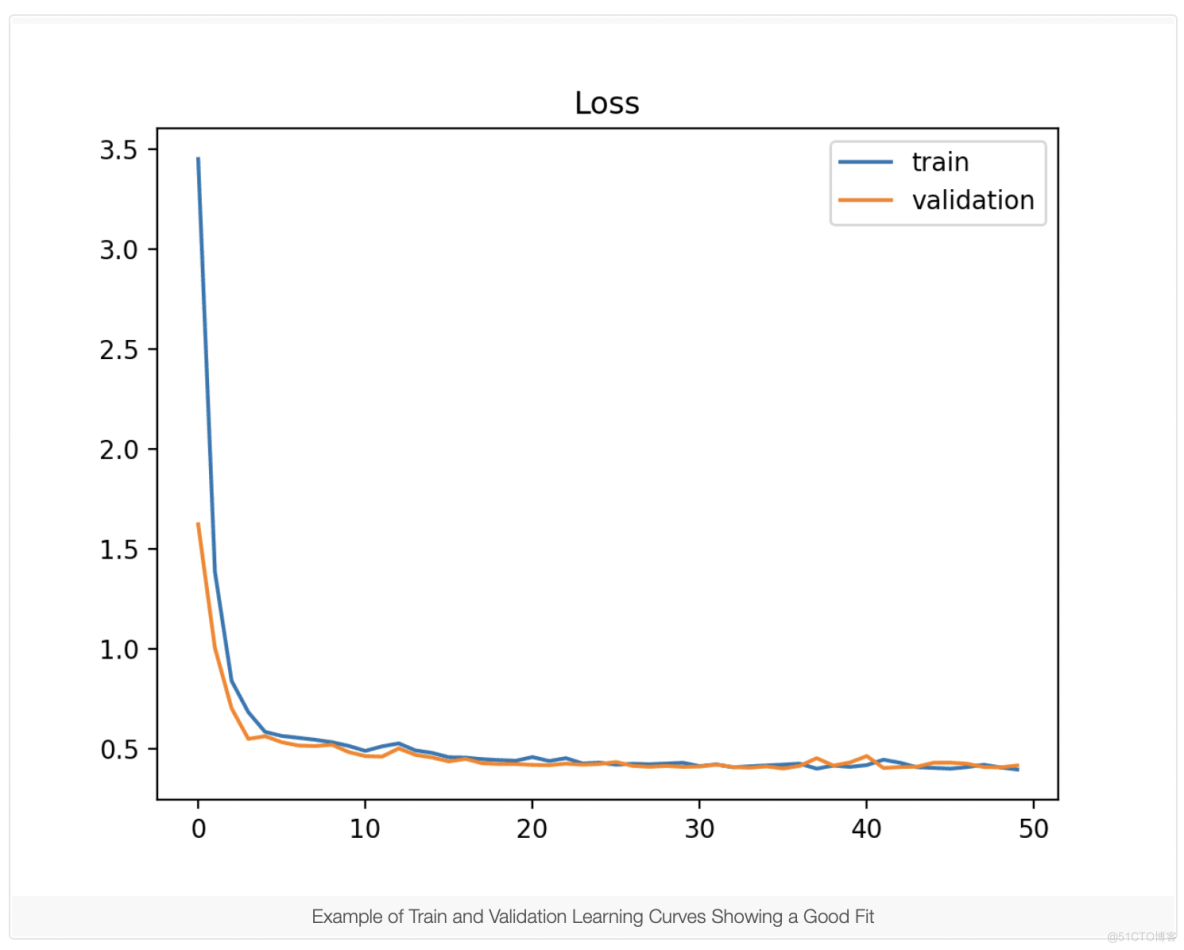
2.3 良好拟合学习曲线
良好拟合是学习算法的目标,存在于过拟合和欠拟合模型之间。良好拟合由训练和验证损失确定,该损失降低到稳定点,两个最终损失值之间的差距最小。损失 模型在训练数据集上的比例几乎总是低于验证数据集。 这意味着我们应该预期训练和验证损失学习曲线之间存在一些差距。 这种差距被称为“泛化差距”。
如果满足以下条件,学习曲线图将显示良好拟合:
- 训练损失图减小到稳定点。
- 验证损失图下降到一个稳定点,并且与训练损失有一个小的差距。
对良好拟合的持续训练可能会导致过度拟合。下面的示例图展示了一个良好拟合的案例。
3 诊断不具代表性的数据集
学习曲线也可用于诊断数据集的属性以及它是否具有相对代表性。不具代表性的数据集是指可能无法捕获相对于从同一域中提取的另一个数据集的统计特征的数据集,例如在训练和验证之间数据集。 如果数据集中的样本数量相对于另一个数据集太小,则通常会发生这种情况。
有两种常见的情况可以观察到; 他们是:
- 训练数据集相对不具代表性。
- 验证数据集相对不具代表性。
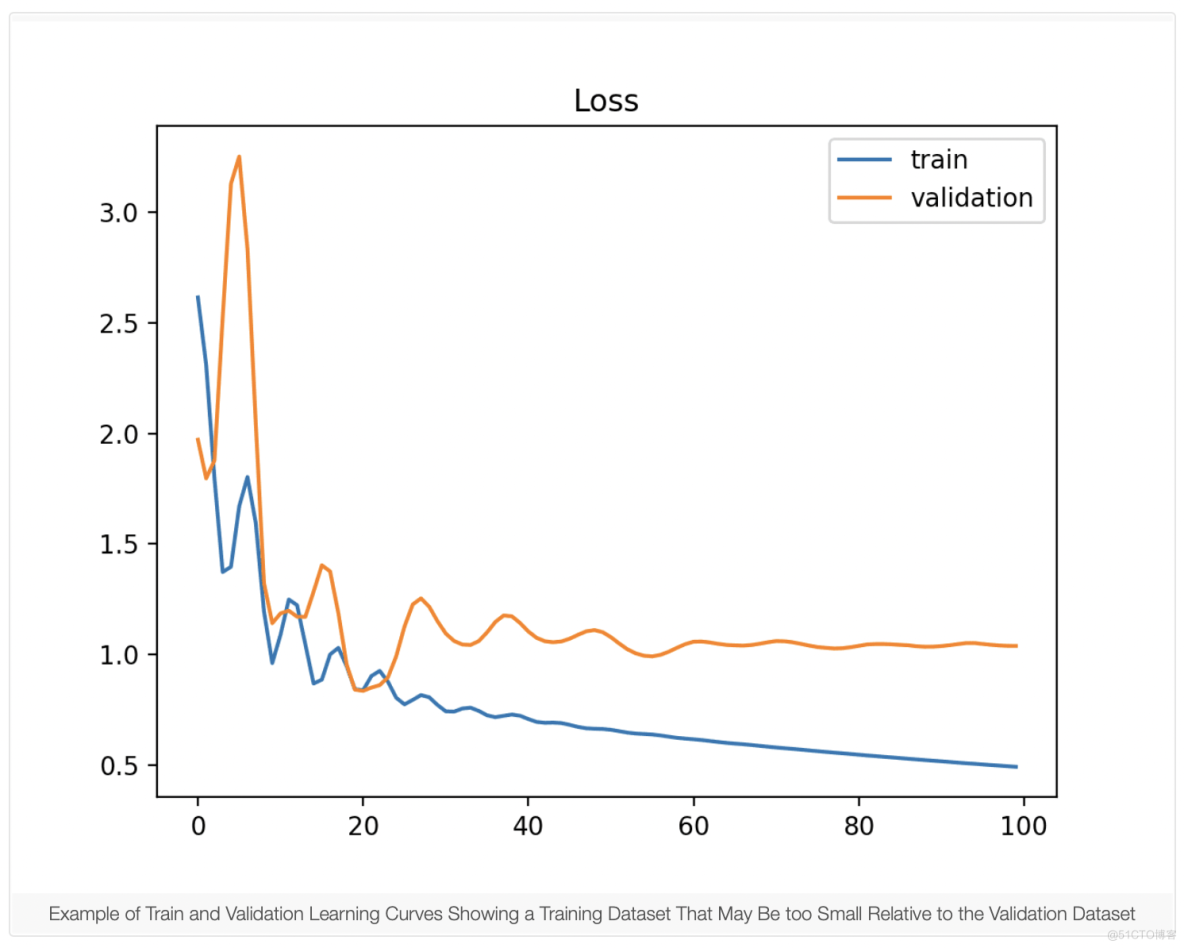
3.1 不具代表性的训练数据集
一个不具代表性的训练数据集意味着训练数据集没有提供足够的信息来学习问题,相对于用于评估它的验证数据集。如果训练数据集的示例与验证数据集相比太少,可能会发生这种情况。这种情况可以 由显示改进的训练损失的学习曲线和显示改进的验证损失的学习曲线来识别,但两条曲线之间仍然存在很大差距。
3.2 不具代表性的验证数据集
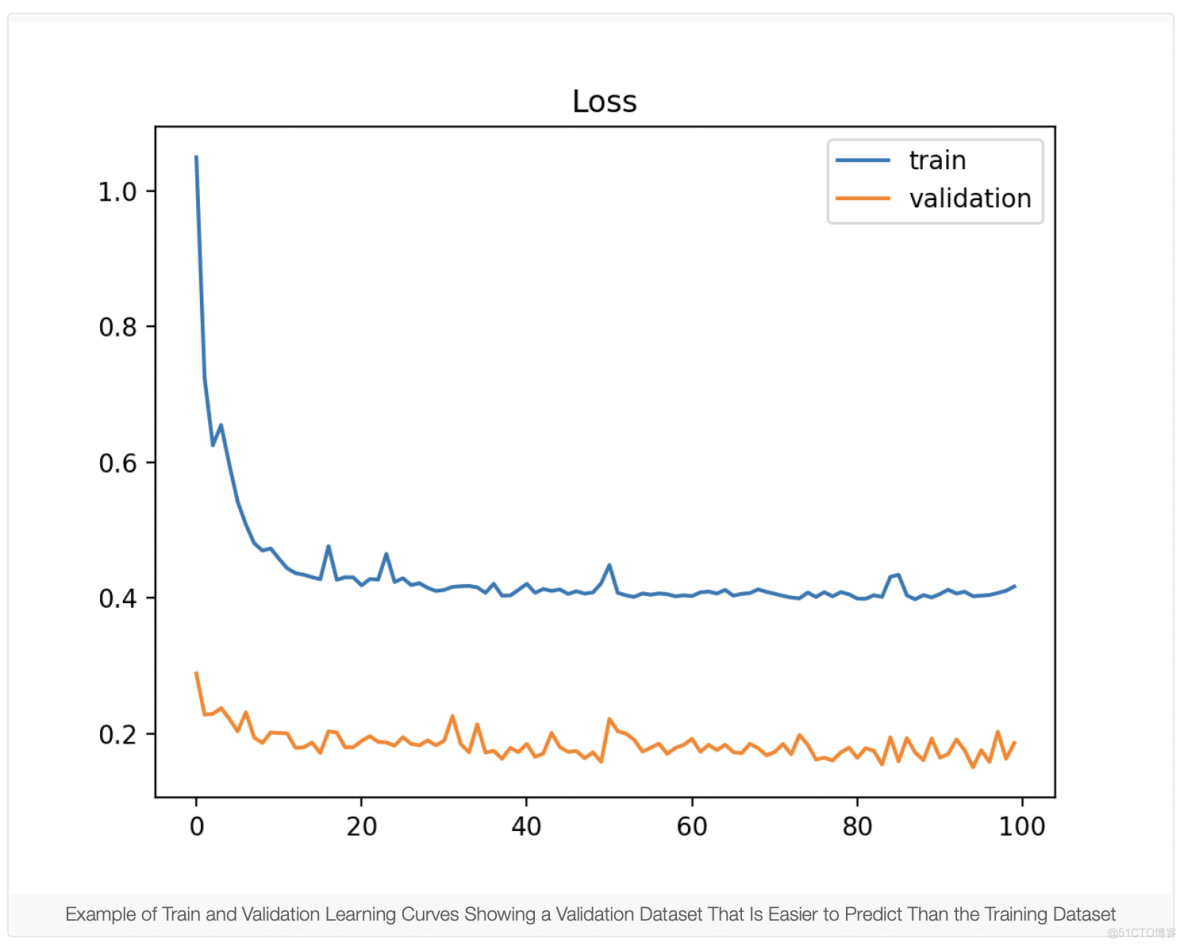
不具代表性的验证数据集意味着验证数据集没有提供足够的信息来评估模型的泛化能力。如果验证数据集的示例与训练数据集相比太少,则可能会发生这种情况。这种情况可以通过学习来识别 训练损失曲线看起来很合适(或其他拟合),验证损失的学习曲线显示训练损失周围的嘈杂运动。
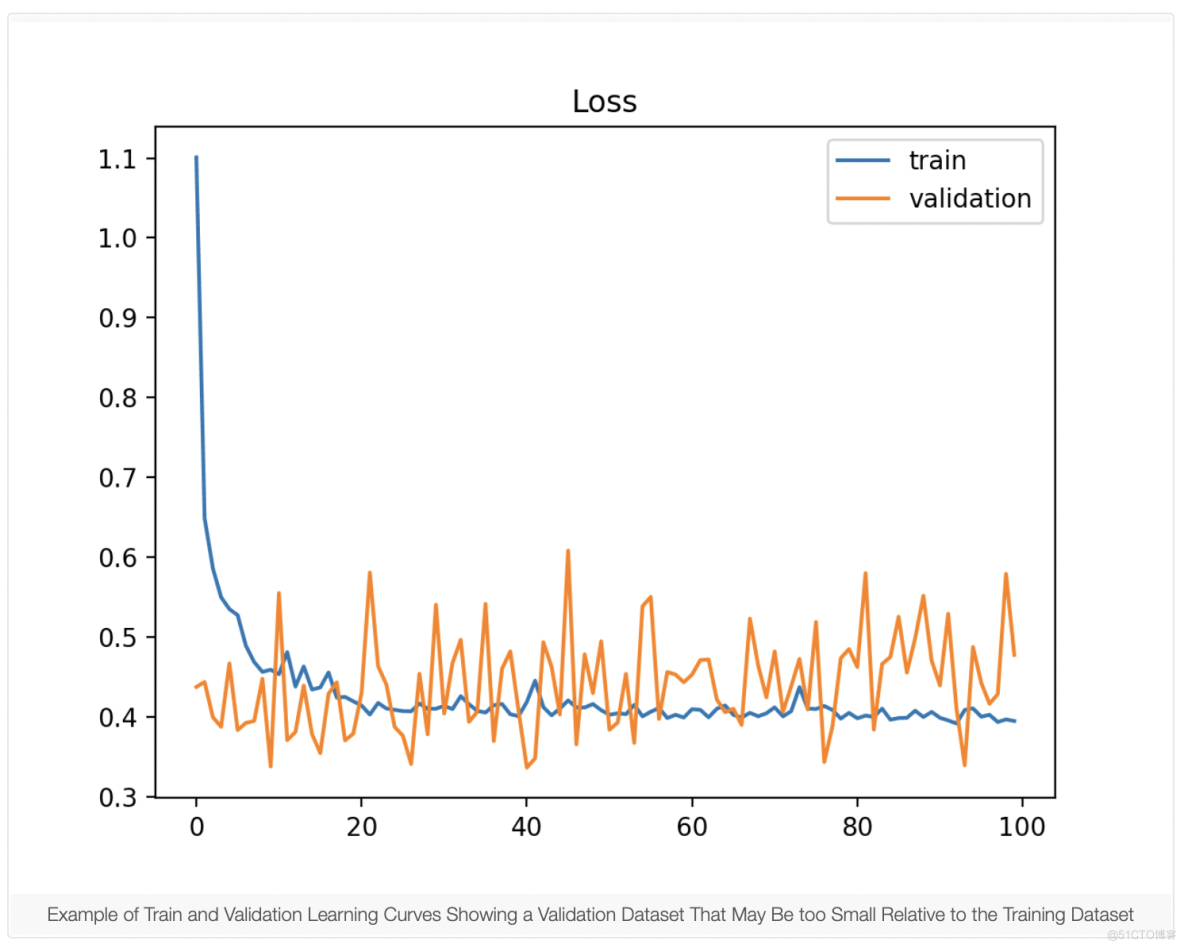
它也可以通过低于训练损失的验证损失来识别。 在这种情况下,它表明验证数据集可能比训练数据集更容易被模型预测。