文件操作 r,只读模式(默认)。 w,只写模式。【不可读;不存在则创建;存在则删除内容;】 a,追加模式。【可读; 不存在则创建;存在则只追加内容;】 "+" 表示可以同时读写某
文件操作
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
- "+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,写读
- a+,同a
wb, rb, ab : 处理的是非文本
f = open('yest2', 'w', encoding='utf-8') # 指定utf-8打开,不指定按电脑系统的gbk打开,打不开会报错f.write('\n我爱北京天安门, \n')
f.write('天安门上太阳升. ')
f.flush() # 刷新
新建了一个yest2的文本文档,里面写了我爱北京天安门, 天安门上太阳升.重新修改时会将里面的覆盖。如果w改为a(append),则会在上面两句话的后面加上新的,不会覆盖,w会新建一个文件,如果之前有同名的文件,则会把之前的覆盖。不用print,内容直接会出现在yest2里
f = open('yestday2', 'r', encoding='utf-8')data1 = f.read()
data2 = f.read()
print(data1)
print(data2)
# 只会打印出data1的数据,因为data1已经读到最后了,data2它还是往下读,已经没有数据了,所以它为空。
f = open('yestday2', 'r', encoding='utf-8')
print(f.readlines())
结果:
['1111111\n', '222222\n', '33333333\n', '4444444']# readlines按行打印在一个列表里f = open('yestday2', 'r', encoding='utf-8')
print(f.readline())
print(f.readline())
# 打印出了两行
f = open('yestday2', 'r', encoding='utf-8')
for i in range(5):
print(f.readline())
# 读了五行
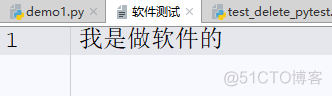
创建一个文件名为软件测试,里面写一句我是做软件的
bs = f.read()
print(bs)
print(bs.decode("utf-8")) # 需要解码
结果:
b'\xe6\x88\x91\xe6\x98\xaf\xe5\x81\x9a\xe8\xbd\xaf\xe4\xbb\xb6\xe7\x9a\x84'我是做软件的
r+模式, 默认情况下光标在文件的开头, 必须先读, 后写
f = open("软件测试", mode="r+", encoding="utf-8")s = f.read()
f.write("周润发")
f.flush()
f.close()
print(s)

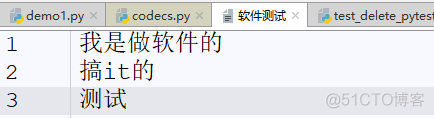
r+在没有任何操作之前进行写. 在开头写 . 如果读取了一些内容. 再写, 写入的是最后
f.read(3)
f.seek(6) # 移动到xx位置
print(f.read())
结果:
做软件的搞it的
测试# 移动到开头: f.seek(0) 开头
# 移动到末尾: f.seek(0, 2) 末尾 第二个参数有三个值. 0: 再开头, 1: 在当前, 2: 末尾
# seek(n) 光标移动到n位置, 注意, 移动的单位是byte. 所以如果是UTF8的中⽂部分要是3的倍数.f = open('yestday2', 'r', encoding='utf-8')
print(f.tell()) # 光标在第几个字符后 0
print(f.readline()) # 打印一行
print(f.read(5)) # 打印5个字符
print(f.readline())
print(f.tell())
f.seek(10) # 光标返回到第十个字符,开始就是0
print(f.readline()) # 光标之后的一行打印出来
f.truncate(10) # 截取多少个字符,从文件头开始,有seek也是从头开始的f = open('yestday2', 'r', encoding='utf-8')
print(f.encoding) # 返回编码
print(f.name) # 打印名称
print(f.readable()) # 判断文件是否可读
print(f.writable()) # 判断文件是否可写
print(f.seekable()) # 判断光标是否可返回
结果:
utf-8yestday2
True
False
Truef = open('yestday2', 'r', encoding='utf-8')
f_f = open('yestday7', 'w', encoding='utf-8')
for line in f:
if '那三年的第一年写的' in line:
line = line.replace('那三年的第一年写的', '那三年的每 一天写的')
f_f.write(line)
f.close()
f_f.close()
判断三年的第一年写的在不在line里面,如果在,执行line=line.replace('那三年的第一年写的','那三年的每 一天写的')将里面的文字替换,然后执行f_f.write(line),如果不在,直接执行f_f.write(line)
import oswith open("吃的", mode="r", encoding="utf-8") as f1, \
open("吃的_副本", mode="w", encoding="utf-8") as f2:
for line in f1:
s = line.replace("菜", "肉")
f2.write(s)
os.remove("吃的") # 删除文件
os.rename("吃的_副本", "吃的") # 重命名文件
with open('yestday2','r',encoding='utf-8') as f:
with就是程序执行完后系统自行关闭,不用输close(),as f 将前面的文件赋值给 f
enumerate
作用:可以打印出下标
之前打印下标是这样操作的
list1 = ["这", "是", "一个", "测试"]for i in range(len(list1)):
print(i, list1[i])
结果:
0 这1 是
2 一个
3 测试
使用enumerate
list1 = ["这", "是", "一个", "测试"]for index, item in enumerate(list1):
print(index, item)
结果:
0 这1 是
2 一个
3 测试for index, line in enumerate(f.readlines()):
if index == 9:
print('----我是分割线----------')
continue
print(line.strip()) # 去掉空格
打印了九行后,打印出----我是分割线----------,返回for,从第十行接着往下打印
import sys, timefor i in range(20):
sys.stdout.write('*') # 打印#标准输出到屏幕,stdout标准输出
sys.stdout.flush() # 及时刷新,如果没有,20个 *10s之后一起打印出来
time.sleep(0.5) # 打印一个,等待时间0.5s
每隔0.5s打印出来一个*