这是 Fall 2019 的最后一个实验,要求我们实现预写式日志、系统恢复和存档点功能,这三个功能分别对应三个类 LogManager、LogRecovery 和 CheckpointManager,下面进入正题。
为了达到原子性和持久性的目标,数据库系统会将描述事务所做修改的信息保存硬盘中。这些信息确保已提交事务中执行的所有修改都反映在数据库中,还可以确保系统崩溃并重新启动后,由中止或失败的事务所做的修改不会保留在数据库中。本次实验使用预写日志记录这些修改,预写日志也是使用的最广泛的记录方式,基本原理如下图所示。
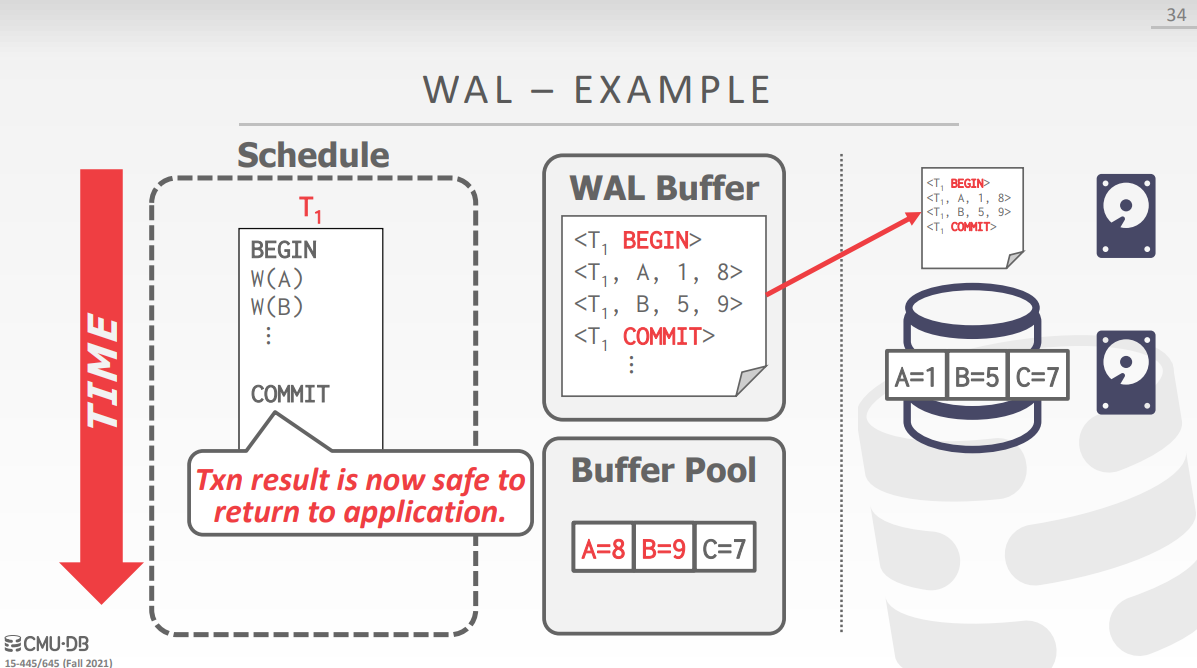
在内存中有一块缓冲区域 WAL Buffer,用于记录任何事务中执行的操作,每当执行一个操作,就会在缓冲区中添加一条记录,记录的格式有三种:物理日志、逻辑日志和混合式日志。物理日志记录了操作前后每个数据位的修改,逻辑日志只记录了 SQL 语句,而混合日志和物理日志很像,不过将偏移量换成了槽号。逻辑日志存在一些问题,比如重新执行 Now() 时间会发生改变,而物理日志的偏移量也会有问题,如果对页进行碎片整理会导致偏移量失效,所以实际上使用的是混合式的日志。
在 WAL Buffer 中添加完一条记录后,才会修改缓冲池中的数据,当日志被提交或者 WAL Buffer 满了之后(取决于具体策略),会将日志写到硬盘上,虽然这时候缓冲池中的脏页可能还没同步到硬盘上,但是只要保存完日志,我们就能保证数据已经安全了。正是因为缓冲池未动,日志先行,所以这种策略称为预写式日志。

日志管理器 LogManager 的声明如下所示,可以看到内部有两个缓冲区: log_buffer_ 和 flush_buffer_,前者用于添加记录,当满足一定条件时(后面会说到),需要交换这两个缓冲区的内容,然后使用 flush_thread_ 将 flush_buffer_ 写到硬盘上:
class LogManager {
public:
explicit LogManager(DiskManager *disk_manager)
: next_lsn_(0), persistent_lsn_(INVALID_LSN), disk_manager_(disk_manager) {
log_buffer_ = new char[LOG_BUFFER_SIZE];
flush_buffer_ = new char[LOG_BUFFER_SIZE];
}
~LogManager() {
delete[] log_buffer_;
delete[] flush_buffer_;
log_buffer_ = nullptr;
flush_buffer_ = nullptr;
}
void RunFlushThread();
void StopFlushThread();
/* flush log to disk */
void Flush();
lsn_t AppendLogRecord(LogRecord *log_record);
inline lsn_t GetNextLSN() { return next_lsn_; }
inline lsn_t GetPersistentLSN() { return persistent_lsn_; }
inline void SetPersistentLSN(lsn_t lsn) { persistent_lsn_ = lsn; }
inline char *GetLogBuffer() { return log_buffer_; }
private:
/** The atomic counter which records the next log sequence number. */
std::atomic<lsn_t> next_lsn_;
/** The log records before and including the persistent lsn have been written to disk. */
std::atomic<lsn_t> persistent_lsn_;
char *log_buffer_;
char *flush_buffer_;
int log_buffer_offset_ = 0;
int flush_buffer_offset_ = 0;
std::mutex latch_;
std::thread *flush_thread_;
std::condition_variable cv_;
std::condition_variable cv_append_;
std::atomic_bool need_flush_ = false;
DiskManager *disk_manager_;
};
当满足下述条件之一时,我们会使用日志线程将日志写到硬盘上:
log_buffer_的剩余空间不足以插入新的记录- 距离上一次保存日志的时间超过了
log_timeout - 缓冲池换出了一个脏页
实验提示说要用到 Future 和 Promise,但是感觉条件变量就够用了,加上一个 need_flush_ 判断条件避免发生虚假唤醒:
void LogManager::RunFlushThread() {
if (enable_logging) {
return;
}
enable_logging = true;
flush_thread_ = new std::thread([&] {
while (enable_logging) {
std::unique_lock<std::mutex> lock(latch_);
// flush log to disk if log time out or log buffer is full
cv_.wait_for(lock, log_timeout, [&] { return need_flush_.load(); });
if (log_buffer_offset_ > 0) {
std::swap(log_buffer_, flush_buffer_);
std::swap(log_buffer_offset_, flush_buffer_offset_);
disk_manager_->WriteLog(flush_buffer_, flush_buffer_offset_);
flush_buffer_offset_ = 0;
SetPersistentLSN(next_lsn_ - 1);
}
need_flush_ = false;
cv_append_.notify_all();
}
});
}
当数据库系统被关闭时,我们应该停止日志线程,同时将 log_buffer_ 中的记录全部保存到硬盘中:
void LogManager::StopFlushThread() {
enable_logging = false;
Flush();
flush_thread_->join();
delete flush_thread_;
flush_thread_ = nullptr;
}
void LogManager::Flush() {
if (!enable_logging) {
return;
}
std::unique_lock<std::mutex> lock(latch_);
need_flush_ = true;
cv_.notify_one();
// block thread until flush finished
cv_append_.wait(lock, [&] { return !need_flush_.load(); });
}
根据执行操作的不同,日志记录也分为多个种类:
enum class LogRecordType {
INVALID = 0,
INSERT,
MARKDELETE,
APPLYDELETE,
ROLLBACKDELETE,
UPDATE,
BEGIN,
COMMIT,
ABORT,
/** Creating a new page in the table heap. */
NEWPAGE,
};
日志记录由 LogRecord 类描述,每一种记录的格式如下所示:
Header (每种类型都拥有 Header,共 20 字节)
--------------------------------------------
| size | LSN | transID | prevLSN | LogType |
--------------------------------------------
插入类型日志记录
--------------------------------------------------------------
| HEADER | tuple_rid | tuple_size | tuple_data(char[] array) |
--------------------------------------------------------------
删除类型日志记录 (包括 markdelete, rollbackdelete, applydelete)
--------------------------------------------------------------
| HEADER | tuple_rid | tuple_size | tuple_data(char[] array) |
--------------------------------------------------------------
更新类型日志记录
----------------------------------------------------------------------------------
| HEADER | tuple_rid | tuple_size | old_tuple_data | tuple_size | new_tuple_data |
----------------------------------------------------------------------------------
新页类型日志记录
-----------------------------------
| HEADER | prev_page_id | page_id |
-----------------------------------
我们需要根据不同类型日志记录的格式将日志记录序列化到 log_buffer_ 中:
lsn_t LogManager::AppendLogRecord(LogRecord *log_record) {
std::unique_lock<std::mutex> lock(latch_);
// flush log to disk when the log buffer is full
if (log_record->size_ + log_buffer_offset_ > LOG_BUFFER_SIZE) {
// wake up flush thread to write log
need_flush_ = true;
cv_.notify_one();
// block current thread until log buffer is emptied
cv_append_.wait(lock, [&] { return log_record->size_ + log_buffer_offset_ <= LOG_BUFFER_SIZE; });
}
// serialize header
log_record->lsn_ = next_lsn_++;
memcpy(log_buffer_ + log_buffer_offset_, log_record, LogRecord::HEADER_SIZE);
int pos = log_buffer_offset_ + LogRecord::HEADER_SIZE;
// serialize body
switch (log_record->GetLogRecordType()) {
case LogRecordType::INSERT:
memcpy(log_buffer_ + pos, &log_record->insert_rid_, sizeof(RID));
pos += sizeof(RID);
log_record->insert_tuple_.SerializeTo(log_buffer_ + pos);
break;
case LogRecordType::MARKDELETE:
case LogRecordType::APPLYDELETE:
case LogRecordType::ROLLBACKDELETE:
memcpy(log_buffer_ + pos, &log_record->delete_rid_, sizeof(RID));
pos += sizeof(RID);
log_record->delete_tuple_.SerializeTo(log_buffer_ + pos);
break;
case LogRecordType::UPDATE:
memcpy(log_buffer_ + pos, &log_record->update_rid_, sizeof(RID));
pos += sizeof(RID);
log_record->old_tuple_.SerializeTo(log_buffer_ + pos);
pos += 4 + static_cast<int>(log_record->old_tuple_.GetLength());
log_record->new_tuple_.SerializeTo(log_buffer_ + pos);
break;
case LogRecordType::NEWPAGE:
memcpy(log_buffer_ + pos, &log_record->prev_page_id_, sizeof(page_id_t));
pos += sizeof(page_id_t);
memcpy(log_buffer_ + pos, &log_record->page_id_, sizeof(page_id_t));
break;
default:
break;
}
// update log buffer offset
log_buffer_offset_ += log_record->size_;
return log_record->lsn_;
}
在我们调用 TablePage::InsertTuple 等方法的时候,内部会调用 LogManager::AppendLogRecord 添加日志记录,但是事务开始、提交或者终止时也需要我们添加记录:
Transaction *TransactionManager::Begin(Transaction *txn) {
// Acquire the global transaction latch in shared mode.
global_txn_latch_.RLock();
if (txn == nullptr) {
txn = new Transaction(next_txn_id_++);
}
if (enable_logging) {
LogRecord log_record(txn->GetTransactionId(), txn->GetPrevLSN(), LogRecordType::BEGIN);
auto lsn = log_manager_->AppendLogRecord(&log_record);
txn->SetPrevLSN(lsn);
}
txn_map[txn->GetTransactionId()] = txn;
return txn;
}
void TransactionManager::Commit(Transaction *txn) {
txn->SetState(TransactionState::COMMITTED);
// 省略部分代码
if (enable_logging) {
LogRecord log_record(txn->GetTransactionId(), txn->GetPrevLSN(), LogRecordType::COMMIT);
auto lsn = log_manager_->AppendLogRecord(&log_record);
txn->SetPrevLSN(lsn);
}
// Release all the locks.
ReleaseLocks(txn);
// Release the global transaction latch.
global_txn_latch_.RUnlock();
}
void TransactionManager::Abort(Transaction *txn) {
txn->SetState(TransactionState::ABORTED);
// 省略部分代码
if (enable_logging) {
LogRecord log_record(txn->GetTransactionId(), txn->GetPrevLSN(), LogRecordType::ABORT);
auto lsn = log_manager_->AppendLogRecord(&log_record);
txn->SetPrevLSN(lsn);
}
// Release all the locks.
ReleaseLocks(txn);
// Release the global transaction latch.
global_txn_latch_.RUnlock();
}
如前所述,将缓冲池中的脏页换出时需要强制保存日志,在 Buffer Pool Manager 实验中我们实现了一个 GetVictimFrameId 方法,只要略作修改即可:
frame_id_t BufferPoolManager::GetVictimFrameId() {
frame_id_t frame_id;
if (!free_list_.empty()) {
frame_id = free_list_.front();
free_list_.pop_front();
} else {
if (!replacer_->Victim(&frame_id)) {
return INVALID_PAGE_ID;
}
// flush log to disk when victim a dirty page
if (enable_logging) {
Page &page = pages_[frame_id];
if (page.IsDirty() && page.GetLSN() > log_manager_->GetPersistentLSN()) {
log_manager_->Flush();
}
}
}
return frame_id;
}
日志管理器的测试结果如下所示:
本次实验使用的系统恢复策略较为简单,由于没有使用 Fuzzy Checkpoint,所以少了 Analysis 阶段,直接变成在 LogRecovery::Redo 函数中分析出当前活跃事务表 ATT 并进行重放,在 LogRecovery::Undo 函数中进行回滚。
LogRecovery 会不断调用 DiskManager::ReadLog 函数直到读取完整个日志,由于我们先前将 LogRecord 进行了序列化,此处需要进行反序列化以访问记录中的信息。由于 log_buffer_ 的大小为 LOG_BUFFER_SIZE,所以将日志文件读取到 log_buffer_ 的过程中可能截断最后一条记录,这时候需要返回 false 以表示反序列化失败:
bool LogRecovery::DeserializeLogRecord(const char *data, LogRecord *log_record) {
// convert data to record and check header
auto record = reinterpret_cast<const LogRecord *>(data);
if (record->size_ <= 0 || data + record->size_ > log_buffer_ + LOG_BUFFER_SIZE) {
return false;
}
// copy header
memcpy(reinterpret_cast<char *>(log_record), data, LogRecord::HEADER_SIZE);
// copy body
int pos = LogRecord::HEADER_SIZE;
switch (log_record->GetLogRecordType()) {
case LogRecordType::INSERT:
memcpy(&log_record->insert_rid_, data + pos, sizeof(RID));
pos += sizeof(RID);
log_record->insert_tuple_.DeserializeFrom(data + pos);
break;
case LogRecordType::MARKDELETE:
case LogRecordType::APPLYDELETE:
case LogRecordType::ROLLBACKDELETE:
memcpy(&log_record->delete_rid_, data + pos, sizeof(RID));
pos += sizeof(RID);
log_record->delete_tuple_.DeserializeFrom(data + pos);
break;
case LogRecordType::UPDATE:
memcpy(&log_record->update_rid_, data + pos, sizeof(RID));
pos += sizeof(RID);
log_record->old_tuple_.DeserializeFrom(data + pos);
pos += 4 + log_record->old_tuple_.GetLength();
log_record->new_tuple_.DeserializeFrom(data + pos);
break;
case LogRecordType::NEWPAGE:
memcpy(&log_record->prev_page_id_, data + pos, sizeof(page_id_t));
pos += sizeof(page_id_t);
memcpy(&log_record->page_id_, data + pos, sizeof(page_id_t));
break;
case LogRecordType::BEGIN:
case LogRecordType::COMMIT:
case LogRecordType::ABORT:
break;
default:
return false;
}
return true;
}
重放过程十分简单粗暴,遍历整个日志的记录,如果记录的日志序号大于记录操作的 tuple 保存到磁盘上的日志序列号,说明 tuple 被修改后还没保存到磁盘上就宕机了,这时候需要进行回放。在遍历的时候先无脑将记录对应的事务添加到 ATT 中,直到事务被提交或者中断才将其移出 ATT。
void LogRecovery::Redo() {
while (disk_manager_->ReadLog(log_buffer_, LOG_BUFFER_SIZE, offset_)) {
// offset of current log buffer
size_t pos = 0;
LogRecord log_record;
// deserialize log entry to record
while (DeserializeLogRecord(log_buffer_ + pos, &log_record)) {
// update lsn mapping
auto lsn = log_record.lsn_;
lsn_mapping_[lsn] = offset_ + pos;
// Add txn to ATT with status UNDO
active_txn_[log_record.txn_id_] = lsn;
pos += log_record.size_;
// redo if page was not wirtten to disk when crash happened
switch (log_record.log_record_type_) {
case LogRecordType::INSERT: {
auto page = getTablePage(log_record.insert_rid_);
if (page->GetLSN() < lsn) {
page->WLatch();
page->InsertTuple(log_record.insert_tuple_, &log_record.insert_rid_, nullptr, nullptr, nullptr);
page->WUnlatch();
}
buffer_pool_manager_->UnpinPage(page->GetPageId(), page->GetLSN() < lsn);
break;
}
case LogRecordType::UPDATE: {
auto page = getTablePage(log_record.update_rid_);
if (page->GetLSN() < lsn) {
page->WLatch();
page->UpdateTuple(log_record.new_tuple_, &log_record.old_tuple_, log_record.update_rid_, nullptr, nullptr,
nullptr);
page->WUnlatch();
}
buffer_pool_manager_->UnpinPage(page->GetPageId(), page->GetLSN() < lsn);
break;
}
case LogRecordType::MARKDELETE:
case LogRecordType::APPLYDELETE:
case LogRecordType::ROLLBACKDELETE: {
auto page = getTablePage(log_record.delete_rid_);
if (page->GetLSN() < lsn) {
page->WLatch();
if (log_record.log_record_type_ == LogRecordType::MARKDELETE) {
page->MarkDelete(log_record.delete_rid_, nullptr, nullptr, nullptr);
} else if (log_record.log_record_type_ == LogRecordType::APPLYDELETE) {
page->ApplyDelete(log_record.delete_rid_, nullptr, nullptr);
} else {
page->RollbackDelete(log_record.delete_rid_, nullptr, nullptr);
}
page->WUnlatch();
}
buffer_pool_manager_->UnpinPage(page->GetPageId(), page->GetLSN() < lsn);
break;
}
case LogRecordType::COMMIT:
case LogRecordType::ABORT:
active_txn_.erase(log_record.txn_id_);
break;
case LogRecordType::NEWPAGE: {
auto page_id = log_record.page_id_;
auto page = getTablePage(page_id);
if (page->GetLSN() < lsn) {
auto prev_page_id = log_record.prev_page_id_;
page->WLatch();
page->Init(page_id, PAGE_SIZE, prev_page_id, nullptr, nullptr);
page->WUnlatch();
if (prev_page_id != INVALID_PAGE_ID) {
auto prev_page = getTablePage(prev_page_id);
if (prev_page->GetNextPageId() != page_id) {
prev_page->SetNextPageId(page_id);
buffer_pool_manager_->UnpinPage(prev_page_id, true);
} else {
buffer_pool_manager_->UnpinPage(prev_page_id, false);
}
}
}
buffer_pool_manager_->UnpinPage(page_id, page->GetLSN() < lsn);
break;
}
default:
break;
}
}
offset_ += pos;
}
}
LogRecovery::Undo 会遍历 ATT 中的每一个事务,对事务的操作进行回滚,回滚的规则如下:
- 如果日志记录类型为
LogRecordType::INSERT,使用TablePage::ApplyDelete进行回滚 - 如果日志记录类型为
LogRecordType::UPDATE,使用TablePage::UpdateTuple进行回滚 - 如果日志记录类型为
LogRecordType::APPLYDELETE,使用TablePage::InsertTuple进行回滚 - 如果日志记录类型为
LogRecordType::MARKDELETE,使用TablePage::RollbackDelete进行回滚 - 如果日志记录类型为
LogRecordType::ROLLBACKDELETE,使用TablePage::MarkDelete进行回滚
void LogRecovery::Undo() {
for (auto [txn_id, lsn] : active_txn_) {
while (lsn != INVALID_LSN) {
// read log from dist and convert log buffer entry to log record
LogRecord log_record;
auto offset = lsn_mapping_[lsn];
disk_manager_->ReadLog(log_buffer_, LOG_BUFFER_SIZE, offset);
DeserializeLogRecord(log_buffer_, &log_record);
lsn = log_record.GetPrevLSN();
// rollback
switch (log_record.GetLogRecordType()) {
case LogRecordType::INSERT: {
auto page = getTablePage(log_record.insert_rid_);
page->WLatch();
page->ApplyDelete(log_record.insert_rid_, nullptr, nullptr);
page->WUnlatch();
buffer_pool_manager_->UnpinPage(page->GetPageId(), true);
break;
}
case LogRecordType::UPDATE: {
auto page = getTablePage(log_record.update_rid_);
page->WLatch();
page->UpdateTuple(log_record.old_tuple_, &log_record.new_tuple_, log_record.update_rid_, nullptr, nullptr,
nullptr);
page->WUnlatch();
buffer_pool_manager_->UnpinPage(page->GetPageId(), true);
break;
}
case LogRecordType::MARKDELETE:
case LogRecordType::APPLYDELETE:
case LogRecordType::ROLLBACKDELETE: {
auto page = getTablePage(log_record.delete_rid_);
page->WLatch();
if (log_record.log_record_type_ == LogRecordType::MARKDELETE) {
page->RollbackDelete(log_record.delete_rid_, nullptr, nullptr);
} else if (log_record.log_record_type_ == LogRecordType::APPLYDELETE) {
page->InsertTuple(log_record.delete_tuple_, &log_record.delete_rid_, nullptr, nullptr, nullptr);
} else {
page->MarkDelete(log_record.delete_rid_, nullptr, nullptr, nullptr);
}
page->WUnlatch();
buffer_pool_manager_->UnpinPage(page->GetPageId(), true);
break;
}
default:
break;
}
}
}
active_txn_.clear();
lsn_mapping_.clear();
}
存档点管理器用于保存日志并刷出缓冲池中所有的脏页,同时阻塞正在进行的事务。
void CheckpointManager::BeginCheckpoint() {
transaction_manager_->BlockAllTransactions();
log_manager_->Flush();
buffer_pool_manager_->FlushAllPages();
}
void CheckpointManager::EndCheckpoint() {
transaction_manager_->ResumeTransactions();
}
日志恢复和存档点的测试结果如下:
本次实验主要考察对预写式日志和数据库系统恢复的理解,代码上层面多了对多线程同步技术的要求,整个实验做下来感觉比较顺(除了被段错误坑了亿点时间外),以上~~