密码学与隐私计算在人工智能行业中的实践-矩阵元
由需要安全的数据流通和共享,提出隐私AI,即AI、密码学和系统安全技术的融合,解决安全的多方联合计算问题,分为三个方向:MPC(密码学)、FL(AI算法)和TEE(硬件)。
引言1、数据流动和共享价值很大!
2、数据泄露也很严重!
3、在多方下,进行安全的数据流动和共享很重要!
为了解决上述问题,首先给出了面向静态数据的保护手段,比如:数据防泄漏(DLP)、零信任等。
DLP介绍:https://zhuanlan.zhihu.com/p/449200078
零信任介绍:https://baijiahao.baidu.com/s?id=1736757199934182453&wfr=spider&for=pc
1、以上基于传统的访问控制技术,能保护静态数据,但不能保护动态数据。
2、隐私AI能解决:在多方计算中不会泄漏原始明文数据本身的信息。
3、引出本公司隐私计算框架:Rosetta。
应用 金融风控基于Tensorflow研发。
什么是金融风控?
银行等金融机构在贷前环节中,有一个重要的步骤是对用户的信用进行评级,这里需要综合考虑用户的收入数据、以往的经济行为数据等。一般用户相关的数据越多,对该用户的信用风险等级判断可能越准确,有助于银行更好地判定风险,这一分析过程在业内一般称为信用评分卡(A卡)。
如何实现?
一般先用逻辑回归等机器学习算法得到预测模型,再根据简单映射关系转换到标准评分卡中的分数。
多方使用场景:
三方各自独立部署自己的Rosetta 计算服务节点,彼此之间建立标准安全SSL 链接,便可以开始运行同一份训练程序。
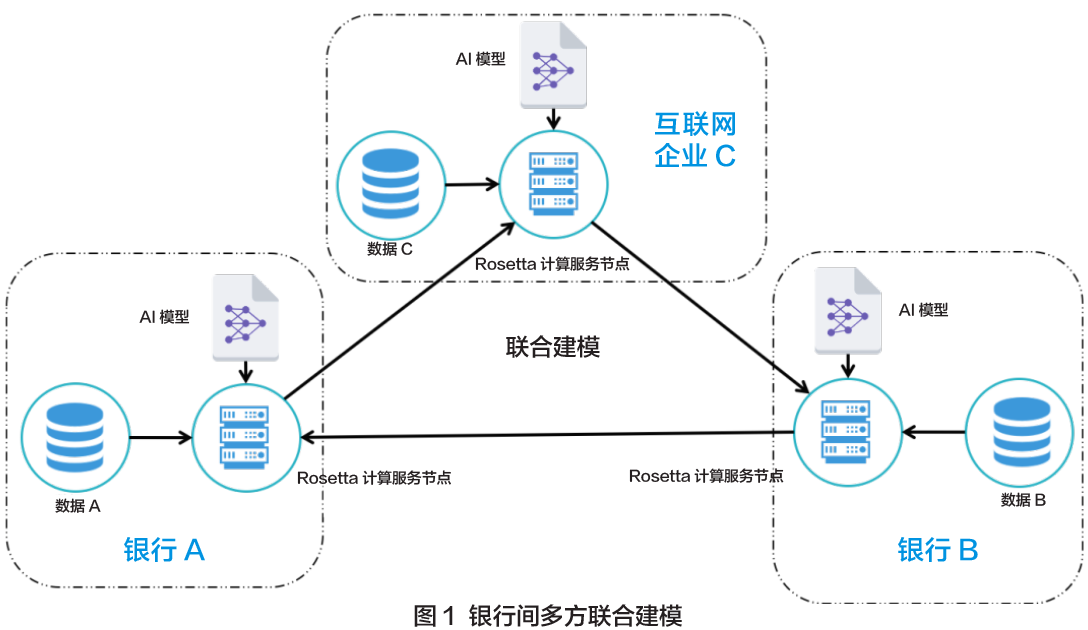
1、第一步就是各方先样本对齐,即数据求交。
2、设定银行A 的角色为P0,银行B 的角色为P1,互联网企业C 的角色为P2。在执行此Python 程序前,P0 需要将其私有的用户特征训练数据集放到train_feature_data.csv 中,将对应该用户是否为信用高风险的分类结果训练数据集放到train_label_data.csv 中。P1 和P2 只需要将各自私有的用户特征训练数据集也放到本地的train_feature_data.csv 文件中,然后调用Load_XY这一API,即可完成对数据的多方“加密分享”。
#!/usr/bin/env python3
import tensorflow as tf
import latticex.rosetta as rtt
# 改造点1:隐私数据预处理
rtt.activate("SecureNN")
# load local private data
file_feature = "./train_feature_data.csv"
file_label = "./train_label_data.csv"
cipher_X, cipher_Y = rtt.SecureDataSet(
label_owner=0, p2_owns_data=True).load_XY(file_feature, file_label, header=None)
# ... (利用TensorFlow表达计算逻辑)...
# 改造点2:在训练结束后,释放相关资源
rtt.deactivate()
3、还可以通过配置文件设定,在使用TF 的save 接口对得到的结果模型进行输出时,仅将明文结果保存到某一方。比如,在实际中,我们可以通过在系统额外的配置文件中配置SAVER_MODE=3,使得训练得到的模型结果仅提供给银行A 和银行B 使用,而不暴露给企业C。
4、运行仅需三方各自启动上述的同一脚本,并通过命令行参数设定自身的角色分别是P0、P1、P2 即可。
如图,原生的TensorFlow Operation 已经被我们替换成了具有隐私保护功能的’SecureOp’类型,而在整个训练过程中,中间训练得到的权重与bias 参数均为密文,不存在数据、模型泄露等问题。
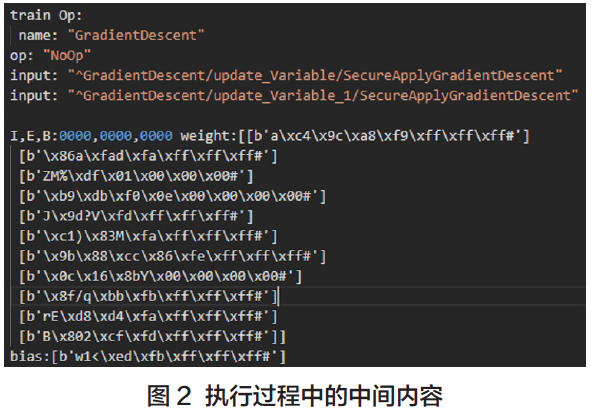
5、下面是在直接明文状态与在Rosetta 密文状态下的效果进行实际对比:
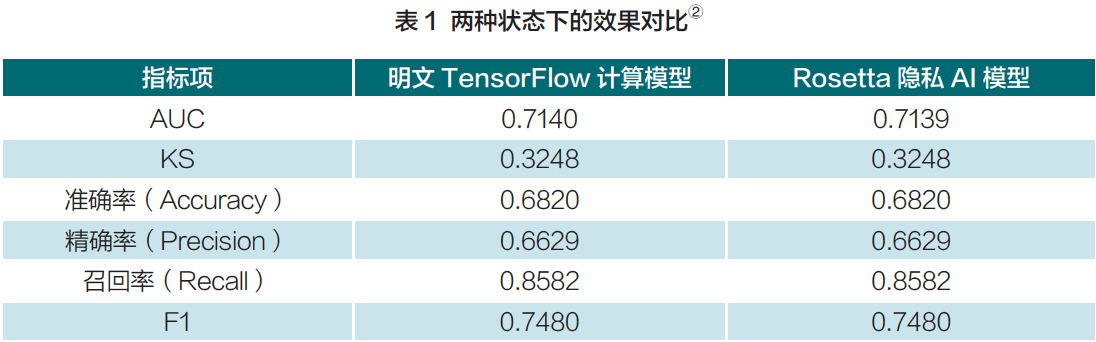
AUC、F1 等均为机器学习领域中常用的模型效果评测指标,它们反映出一个模型在测试数据集上的泛化能力。
- AUC 表示对于随机选取的一对正样本和负样本,该训练得到的分类器将正样本的分类score 高于负样本score 的概率,越接近于1,表明训练得到的分类器效果越好;
- F1 指标是对精确率(Precision)和召回率(Recall)的综合,当越接近于1 时,表明模型整体效果越好。
6、Rosetta中使用了很多MPC技术,比如SecureNN、秘密分享、布尔电路运算等
SecureNN论文:SecureNN: 3-Party Secure Computation for Neural Network Training
下面是一个简单的秘密分享的例子,假设Alice 和Bob 分别将自己的私有明文数据x 和y 转换为定点数之后,拆解为随机的两部分,然后各自执行本地的加法即可,得到的结果是“分享”在两方之间的。

即Alice有:\(x_0=x-r_z,y_0=r_y\),Bob有\(x_1=r_z,y_1=y-r_y\),最后两方相加得到\(x+y\)。
人脸识别该场景为一方有数据,一方有模型参数。假设一家专注于AI 视觉算法的公司A 有一套先进的人脸识别模型,并且模型参数在不断地迭代优化中,其服务可以通过RESTful API 访问。而另一家公司B 需要基于人脸识别系统构建用户认证系统,但是用户的人脸图像等敏感数据不能泄露.
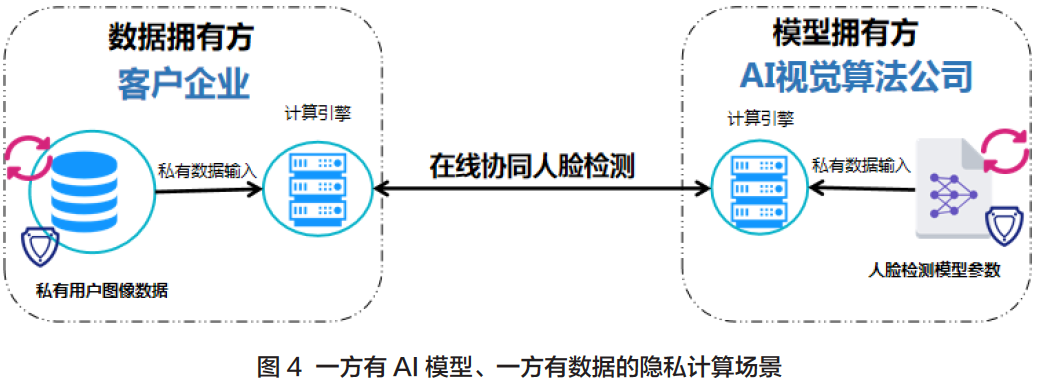
改造主要方式:先将本地待处理的数据集和模型参数都加密后,再进行计算。
以上述简单逻辑回归模型示例。假定A 公司角色是P0,B公司角色是P1,而P2只需要是一个临时的无输入、无输出的辅助节点,可以对基于MPC技术的整套业务过程进行加速。
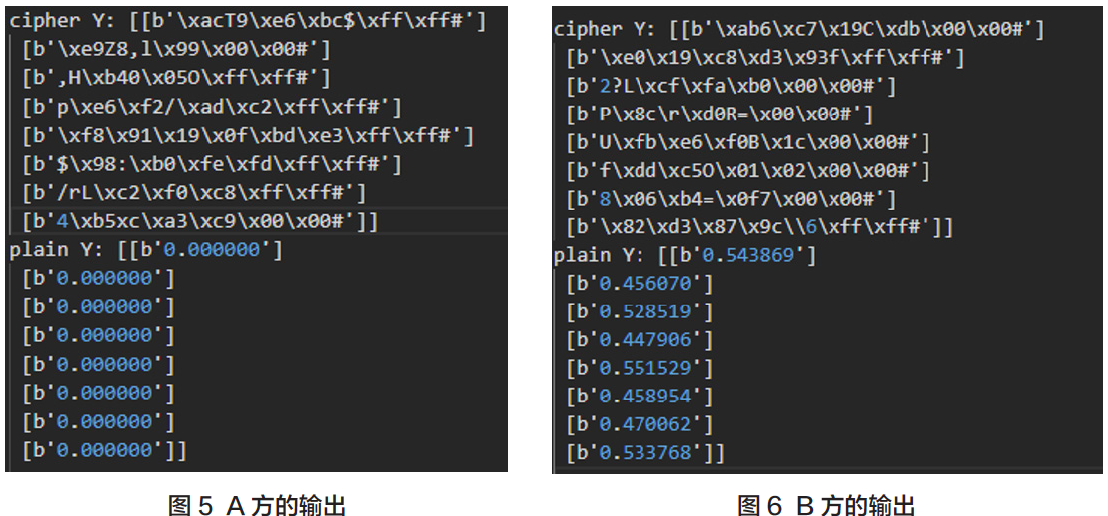
即B方按照预期顺利地拿到了预测的结果,而且在整个计算过程中,A方的模型参数不会暴露,B方的明文数据也不会暴露。
总结1、隐私计算处于起步,还有很多挑战。
2、性能提升
3、与具体场景结合使用
4、未来发展,比如:与区块链结合,可实现计算过程的可追溯性。