归并排序 首先把数组分成一半,想办法把左右两边数组排序,之后呢再将它们归并起来,这就是归并排序的基本思想。 这样的话如果有N个元素,就会分成log(n)层,如果整个归并过程我
首先把数组分成一半,想办法把左右两边数组排序,之后呢再将它们归并起来,这就是归并排序的基本思想。
这样的话如果有N个元素,就会分成log(n)层,如果整个归并过程我们可以以O(n)时间复杂度解决的话,那么我们就设计成了一个 Nlog(n)级别的排序算法。
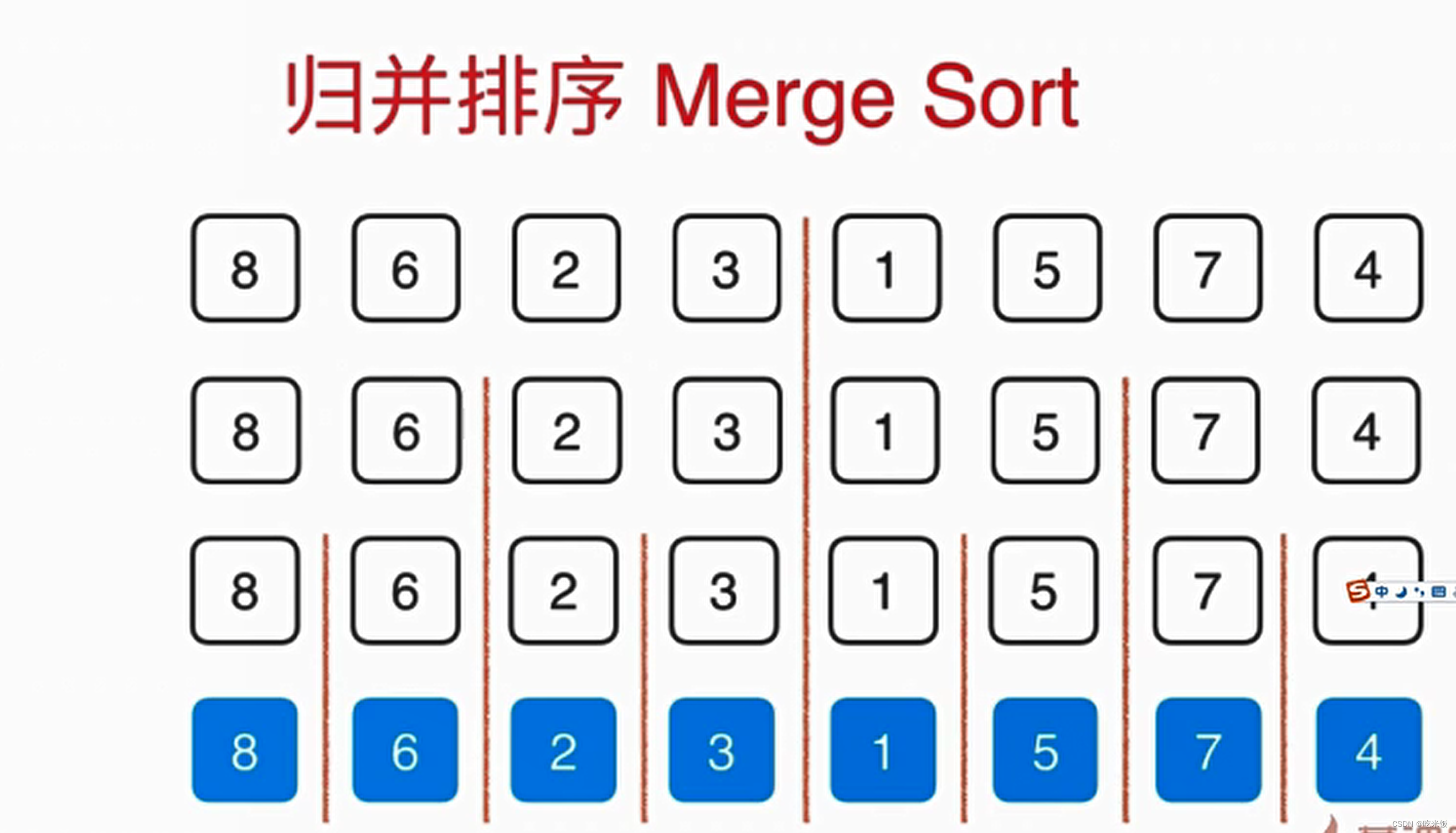
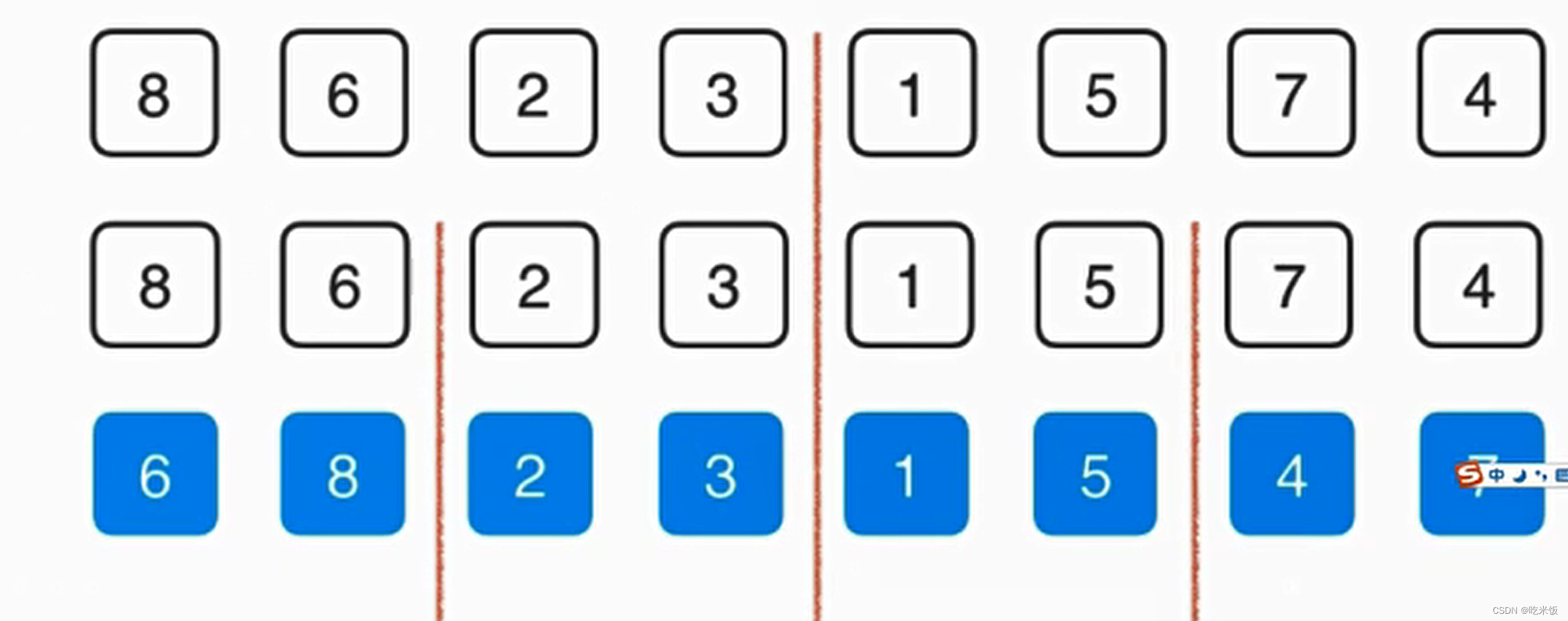
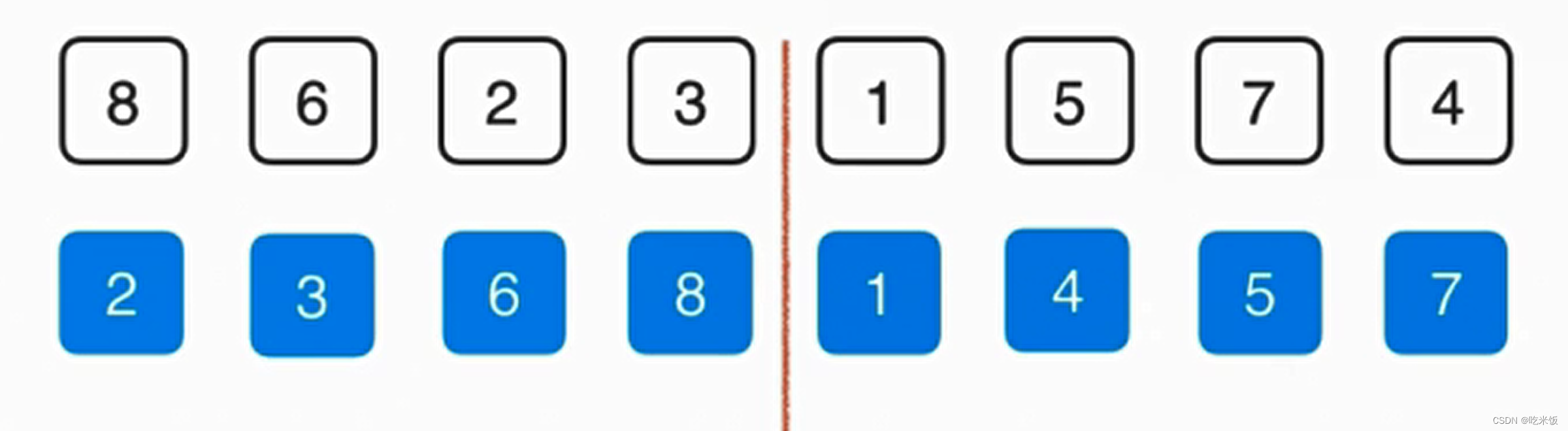

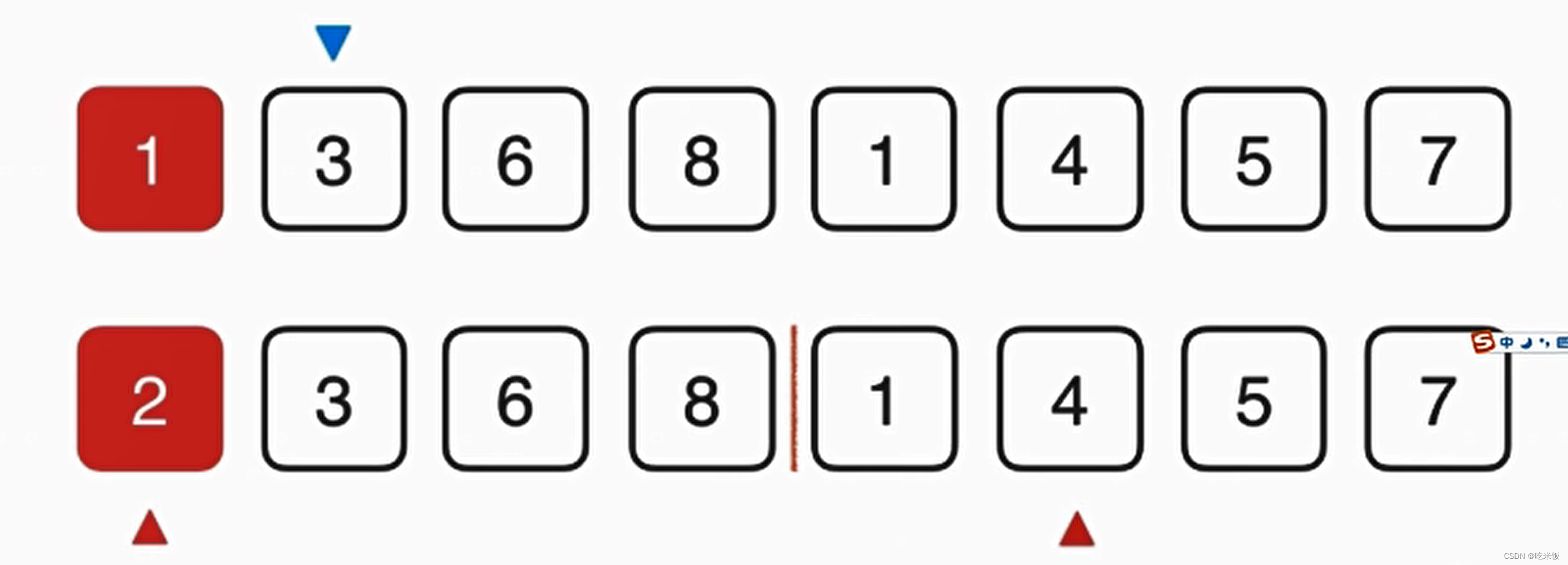
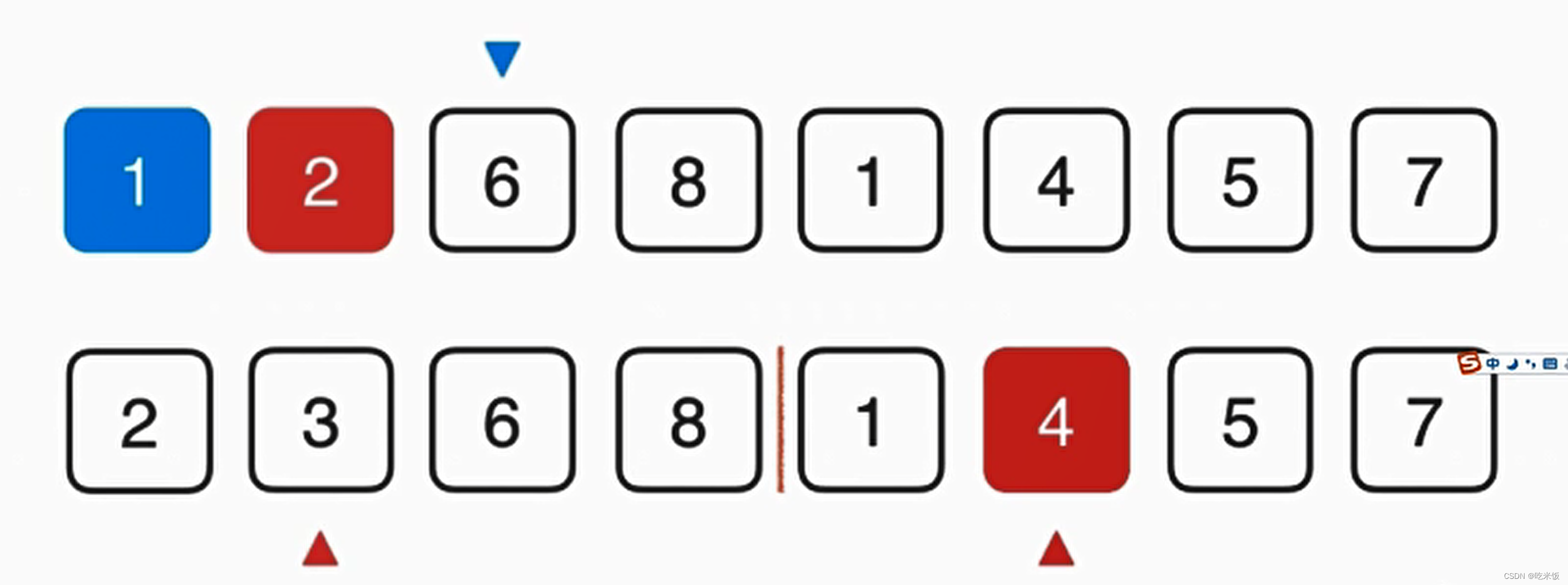
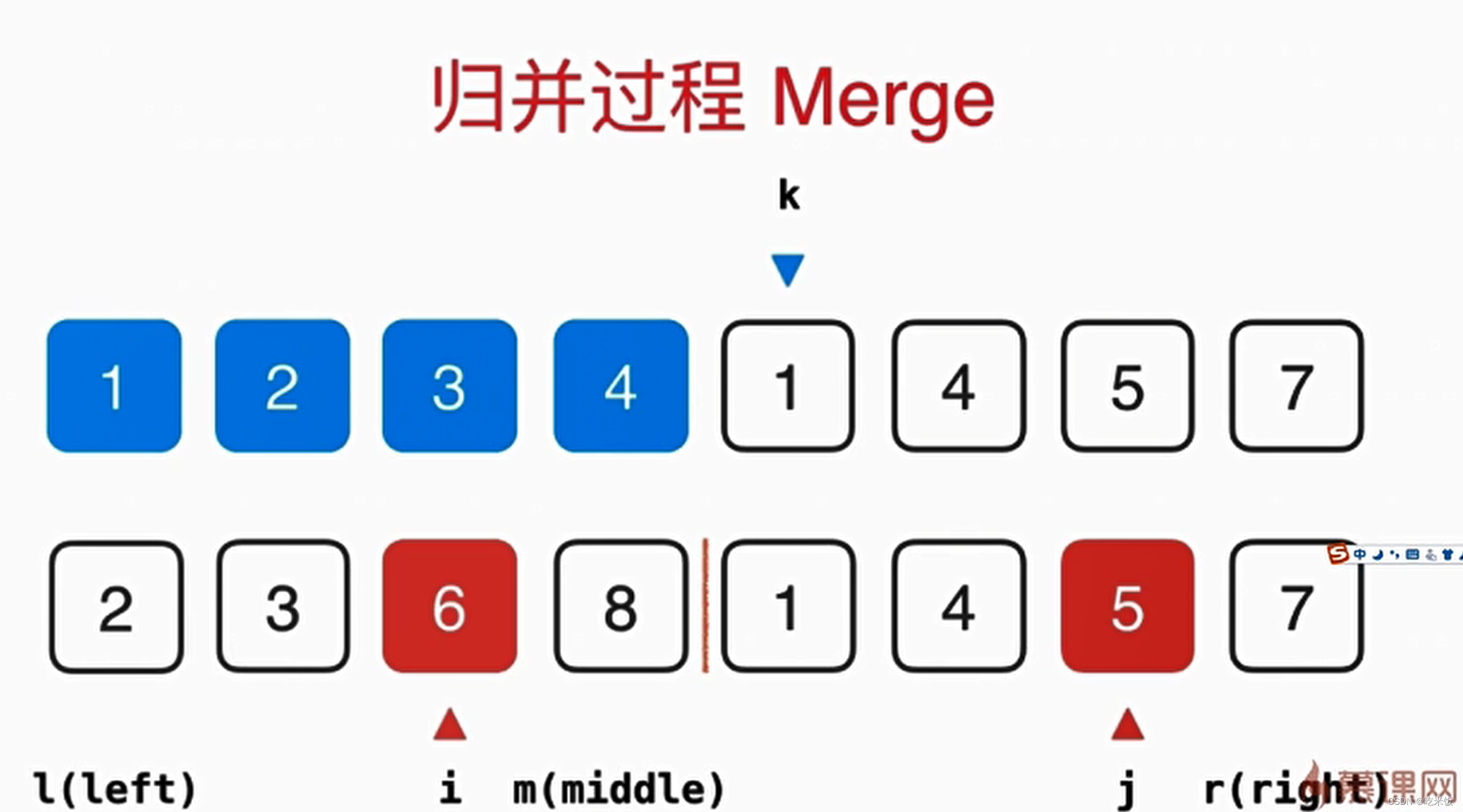
这个归并的过程需要O(n)的辅助空间,把两个已经排好序的数组合并成一个排序数组,整体呢需要三个索引在数组中追踪,其中蓝色的箭头表示最终在归并的过程中我们需要跟踪的位置,而俩个红色的箭头表示当前已经排好序的数组,分别指向当前要考虑的元素。
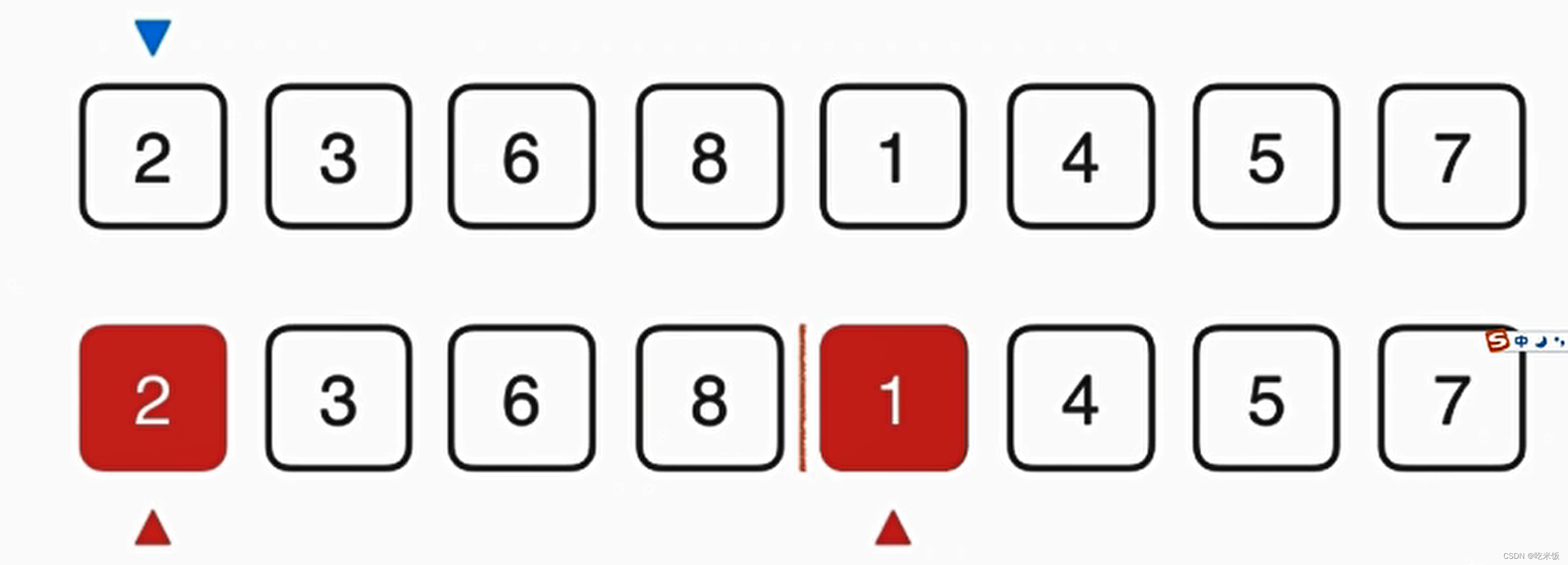
首先我们要看1和2谁先放在最终数组中,显然1比2小所以我们首先把1放在最终数组中,这样蓝色箭头就可以考虑下一元素应该放谁,与此同时,下面红色箭头1所在数组也可以考虑下一元素了,此时1这个元素就最终有序了,然后我们就可以考虑2和4谁放入最终数组,显然是2,以此类推。

- 对于arr[mid] <= arr[mid+1]的情况相当于整个arr就是有序,不进行merge
- 对于小规模数组近乎有序的概率比较大, 使用插入排序有优势
// 对arr[l...r]范围的数组进行插入排序
template<typename T>
void insertionSort(T arr[], int l, int r) {
for (int i = l + 1; i <= r; i++) {
T e = arr[i];
int j;
for (j = i; j > l && arr[j - 1] > e; j--) {
arr[j] = arr[j - 1];
}
arr[j] = e;
}
}
// 将arr[l...mid]和arr[mid+1...r]两部分进行归并
template<typename T>
void __merge(T arr[], const int l, const int mid, const int r) {
T aux[r - l + 1];
for (int i = l; i <= r; ++i) {
aux[i - l] = arr[i];
}
// 初始化,i指向左半部分的起始索引位置l;j指向右半部分起始索引位置mid+1
int i = l, j = mid + 1;
for (int k = l; k <= r; ++k) {
if (i > mid) { // 如果左半部分元素已经全部处理完毕
arr[k] = aux[j - l];
++j;
} else if (j > r) { // 如果右半部分元素已经全部处理完毕
arr[k] = aux[i - l];
++i;
} else if (aux[i - l] < aux[j - l]) { // 左半部分所指元素 < 右半部分所指元素
arr[k] = aux[i - l];
++i;
} else { // 左半部分所指元素 >= 右半部分所指元素
arr[k] = aux[j - l];
++j;
}
}
}
// 递归使用归并排序,对arr[l...r]的范围进行排序
template<typename T>
void __mergeSort(T arr[], const int l, const int r) {
/*if (l >= r) {
return;
}*/
// 优化2: 对于小规模数组近乎有序的概率比较大, 使用插入排序有优势
if (r - l <= 15) {
insertionSort(arr, l, r);
return;
}
int mid = l + (r - l) / 2;
__mergeSort(arr, l, mid);
__mergeSort(arr, mid + 1, r);
// 优化1: 对于arr[mid] <= arr[mid+1]的情况相当于整个arr就是有序,不进行merge
// 对于近乎有序的数组非常有效,但是对于一般情况,有一定的性能损失
if (arr[mid] > arr[mid + 1]) {
__merge(arr, l, mid, r);
}
}
//归并排序
template<typename T>
void mergeSort(T arr[], const int n) {
__mergeSort(arr, 0, n - 1);
}
使用自底向上的归并排序算法 Merge Sort BU 也是一个O(nlogn)复杂度的算法,虽然只使用两重for循环,但是,Merge Sort BU也可以在1秒之内轻松处理100万数量级的数据,需要注意的是:不要轻易根据循环层数来判断算法的复杂度,Merge Sort BU就是一个反例。
比较Merge Sort和Merge Sort Bottom Up两种排序算法的性能效率,整体而言, 两种算法的效率是差不多的。但是如果进行仔细测试,从统计意义上来讲自顶向下的归并排序会略胜一筹。不过Merge Sort Bottom Up 有一个非常重要的作用,这个代码中没有使用数组的索引获取元素特性,就因如此可以非常好的在nlog(n)的时间对链表这样的数据结构进行排序。
template<typename T>
void mergeSortBU(T arr[], const int n) {
// Merge Sort Bottom Up 优化
// 对于小数组, 使用插入排序优化
for (int i = 0; i < n; i += 16) {
insertionSort(arr, i, std::min(i + 15, n - 1));
}
for (int sz = 16; sz < n; sz += sz) {
for (int i = 0; i < n - sz; i += sz + sz) {
// 对于arr[mid] <= arr[mid+1]的情况,不进行merge
if (arr[i + sz - 1] > arr[i + sz]) {
__merge(arr, i, i + sz - 1, std::min(i + sz + sz - 1, n - 1));
}
}
}
}

