@[toc]
⛳️ 实战场景
本次要分析的站点是 credit.acla.org.cn/,一个律师群体常去的站点,作为一个爬虫工程师,这简直是送自己去喝茶。
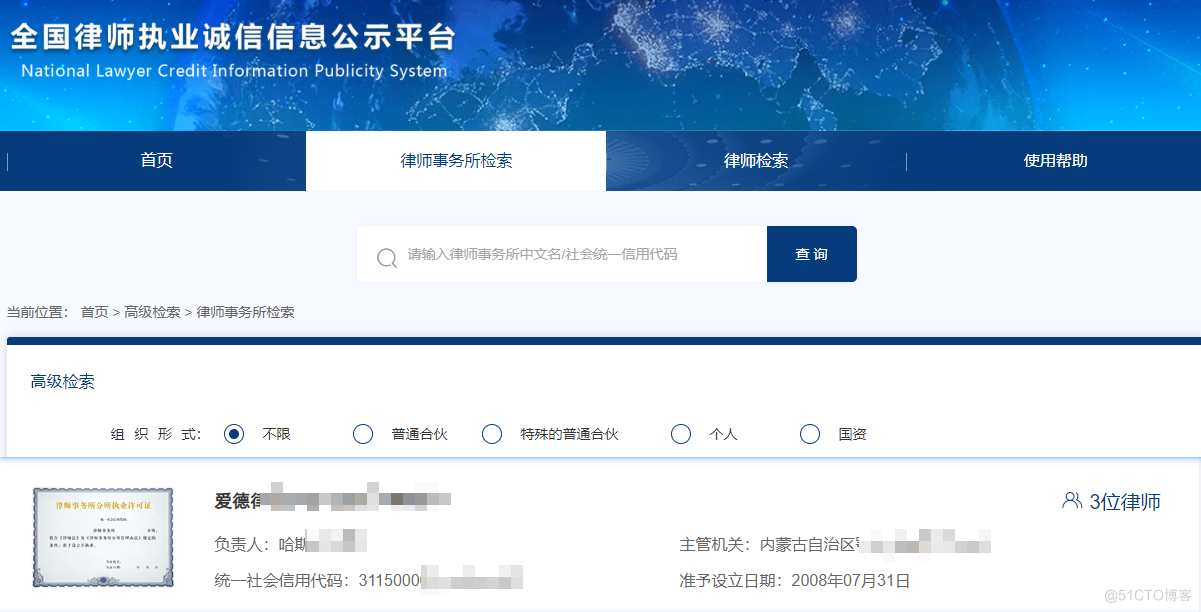 该站点反爬手段特别多,分析起来也特别有趣。
该站点反爬手段特别多,分析起来也特别有趣。
⛳️ 反爬实战
打开开发者工具,无限 debugger
(function anonymous() { debugger; });直接行号处右键一律不在此处暂停
字体反爬切换到 Elements 视图,很容易就发现了字体反爬的存在。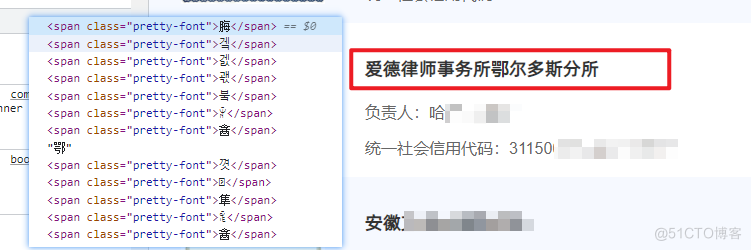 由于我们之前的博客涉及了大量字体反爬内容,本文就不在展开说明了。
由于我们之前的博客涉及了大量字体反爬内容,本文就不在展开说明了。
控制台清空接下来还出现了一个小细节,该站点在不断的执行清空控制台数据操作,也就是它不让你进行控制台测试。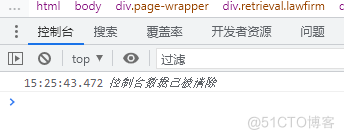 这一点反爬也很容解决,使用下述代码即可。
这一点反爬也很容解决,使用下述代码即可。
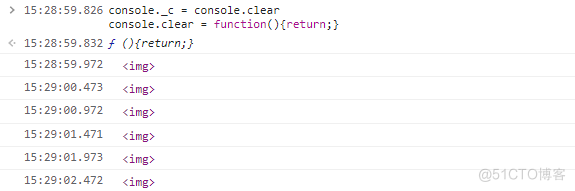 此时日志还会一直出现,需要取消日志输出。
此时日志还会一直出现,需要取消日志输出。
 此时 <img /> 也不会再次输出。
此时 <img /> 也不会再次输出。
类 JSFUCK 加密反爬
简单的反爬手段已经解决了,下面开始尝试获取网页数据,测试代码如下所示。
import requests headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)", "referer": "https://credit.acla.org.cn/" } res = requests.get('https://credit.acla.org.cn/credit/lawFirm?picCaptchaVerification=&keyWords=',headers=headers) print(res.text)运行代码,结果得到下述响应内容。 这加密长得特别像 jsfuck 加密,对于它的具体加密形式,其实不需要特别关注,我们只需要通过控制台查看对应内容即可。
这加密长得特别像 jsfuck 加密,对于它的具体加密形式,其实不需要特别关注,我们只需要通过控制台查看对应内容即可。
注意不要在 Pycharm 等工具的控制台直接复制代码去开发者工具中运行,要写入文件,然后复制整行内容。
在打开一个站点的控制台,例如百度,然后唤醒控制台,删除 $=~[]……() 代码段最后的 (),然后执行。
 解析代码之后,可以查看代码详情,其中涉及了多次 cookie 设置。
解析代码之后,可以查看代码详情,其中涉及了多次 cookie 设置。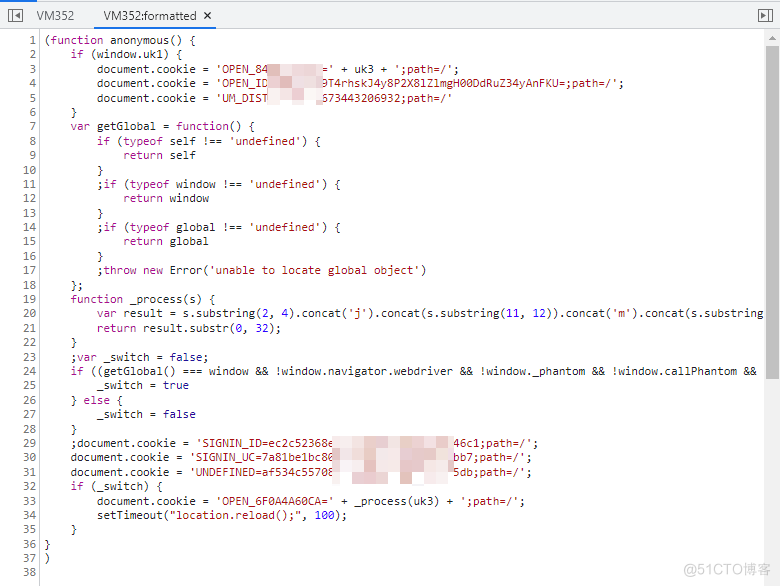 再次访问目标站点,分析之后,发现 lawFirm 地址被调用了两次,第一次返回的就是上述加密内容,因此可以得到结论,首次访问是获取 cookie,二次请求才是真实数据。
再次访问目标站点,分析之后,发现 lawFirm 地址被调用了两次,第一次返回的就是上述加密内容,因此可以得到结论,首次访问是获取 cookie,二次请求才是真实数据。 测试发现第二次请求果然所有 cookie 都进行了发送。
测试发现第二次请求果然所有 cookie 都进行了发送。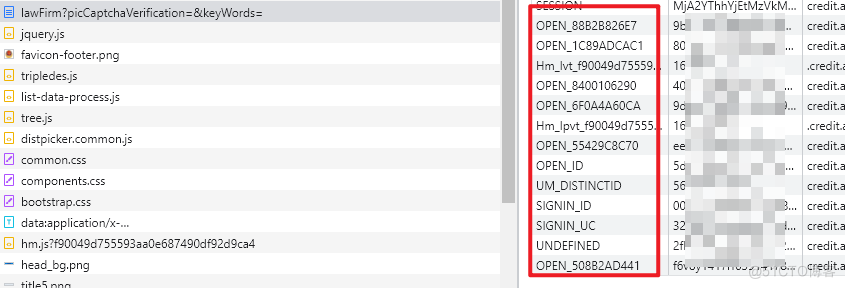 解析 JS 代码,原计划使用 execjs 模块,但是发现其无法解析,没办法只能切换为 py_mini_racer。
解析 JS 代码,原计划使用 execjs 模块,但是发现其无法解析,没办法只能切换为 py_mini_racer。
PyMiniRacer 是适用于 Python 的最小的现代嵌入式 V8。PyMiniRacer 支持最新的 ECMAScript 标准,支持 Assembly,并提供可重用的上下文。
本部分代码如下所示。
import requests import re from py_mini_racer import MiniRacer import execjs headers = { "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36", "referer": "https://credit.acla.org.cn/credit/lawFirm?picCaptchaVerification=&keyWords=" } res = requests.get('https://credit.acla.org.cn/credit/lawFirm?picCaptchaVerification=&keyWords=',headers=headers) # with open('aaa.html', 'w') as f: # f.write(res.text) pattern = re.compile('(\$\=\~\[\];.*?[\s\S]*)</script>') data = pattern.findall(res.text)[0] # print(data[0]) script_str = data[:-1].strip() script_str = script_str.replace('();','') """ # 删除最终的自执行代码 script_str = script_str.replace(')();','') # 删除包裹函数 script_str = script_str.replace(';$.$(',';') """ ctx = MiniRacer() print(script_str) print(ctx.eval(script_str))代码输入如下内容: 这里出现了一个 JSFunction 对象,代表代码 JS 代码被执行了,解决办法在上述代码也存在,就是删除自执行部分代码。
这里出现了一个 JSFunction 对象,代表代码 JS 代码被执行了,解决办法在上述代码也存在,就是删除自执行部分代码。
再次运行,得到解密后的 JS 代码。 跳转链接反爬原以为本站点的所有反爬都已经解决了,结果当点击事务所详情页的时候,发现地址也被加密了。
跳转链接反爬原以为本站点的所有反爬都已经解决了,结果当点击事务所详情页的时候,发现地址也被加密了。
 这个地方断点下的很有趣,因为该点击事件是通过 onclick 绑定到标签上的,所以添加断点的方式是通过事件定位之后,添加到 DOM 元素上。
这个地方断点下的很有趣,因为该点击事件是通过 onclick 绑定到标签上的,所以添加断点的方式是通过事件定位之后,添加到 DOM 元素上。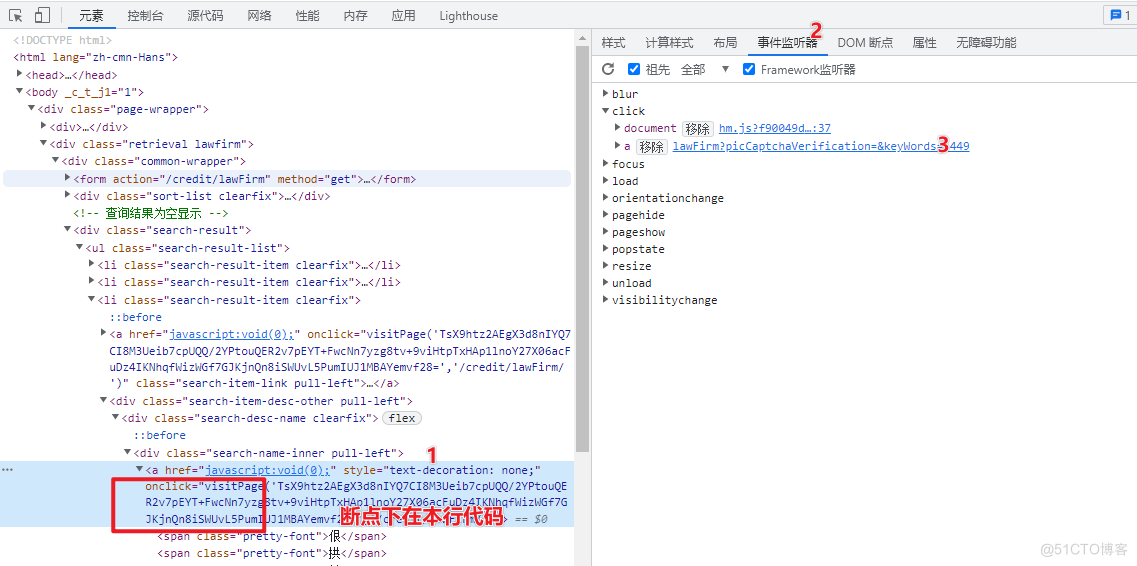 打断点效果~
打断点效果~ 再次点击详情页,可以进入该断点,稍加调试即可发现核心加密函数。
再次点击详情页,可以进入该断点,稍加调试即可发现核心加密函数。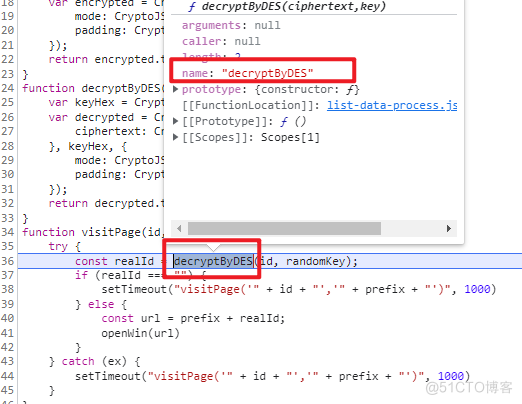 提取加密函数核心代码,如下所示,一个简单的 DES_ECB 加密。
提取加密函数核心代码,如下所示,一个简单的 DES_ECB 加密。
剩下的事情就是秘钥 keyHex 的获取,这部分稍加调试即可实现。
⛳️ 反爬总结
实在没有想到,一个站点的搜索页面竟然存在如此多的反爬手段,看来律师事务所的数据,实在是不易采集,大家加油,版权问题,无法放出完整代码,如需获取,请点击卡片。