目录
架构分层: 1
访问层架构设计 3
LVS 3
Nginx 4
API网关层架构设计 6
分布式会话管理 6
接入层控制 7
服务调用及聚合 7
核心服务层架构设计 8
服务通信 8
任务调度 9
池化技术 10
缓存技术 11
隔离技术 12
队列技术 12
数据存储 12
接入层架构设计-代理访问 14
一个好的架构需要依靠实际项目的打磨,在项目的过程中不断进化自己符合实际产品情况、运营情况、资源情况的架构设计能力,并在项目过程中不断深入强化各层知识能力的理解和应用;
架构设计分层实现
访问层架构,用于web接入|反向代理|负载均衡等;
接口层(API网关层架构),用于负责业务api网关处理;
核心服务层架构,业务服务的核心处理模块,具备服务治理、调度、异步通信等核心服务能力;
存储接入层,用于提供透明的存储结构的访问代理层;
存储层,最终数据的落地及提供数据的能力;
监控|限流|降级
掌握主流互联网高性能后端服务平台的系统分层模型及设计思想;
掌握web接入层负载均衡,前置缓存等设计技术;
掌握dubbo服务治理、异步MQ、任务调度、缓存、隔离队列等核心服务层设计技术;
掌握redis、sql、nosql及代理接入、分库分表等技术;
掌握服务监控、应用限流降级等相关技术;
架构分层:
分而治之|各司其职|有有条不紊的结合;
OSI分层|MVC|基于领域模型的分层设计;
分层模型v0.1时代--servlet jsp时代:
servlet+tomcat完成web接入;
使用javabean+jdbc完成数据层接入;
使用jsp完成页面展示;
分层模型v1.0时代--mvc分层(SSH时代):
web层
业务层
数据访问层
数据持久层
SSH时代:
struts解决接入及表示层;
spring解决业务服务、事务处理、传话管理等问题;
hibernate解决数据存储接入问题;
分层模型v1.5时代--SSM(SpringMVC|Spring|MyBatis):
SpringMVC解决接入及表示层;
Spring解决业务服务、事务处理、会话管理等问题;
MyBatis解决数据接入层;
分层模型v2.0时代--SpringBoot all in one:
整合了所有Spring的框架功能;
提供了简单的配置及注解的接入方式;
提供all in one的服务;
存在问题:解决了单一应用内的软件分层,却没解决整体应用的分层;单一应用性能瓶颈,无法支撑亿级流量;团队协作问题;
分层模型v3.0时代--分布式分层:
水平扩展;
负载均衡;
高可用;
数据一致性;
分布式分层-web概念层:
客户端:移动设备|PC;
访问层:LVS|上游nginx|应用nginx;
接口层:websocket|http|https|tcp|udp|API网关;
分布式分层-业务概念层:
服务层:
服务通信(dubbo|mq);
任务调度(quartz|elasticJob);
业务服务模块(商品服务|订单服务|营销服务|搜索服务|推荐服务|短信服务|安全服务|统计服务);
服务管理(服务配置|服务治理);
基础服务组件(设备管理|隔离管理|缓存管理|队列管理);
监控(cat|zabbix);
分布式分层-数据访问及存储层:
存储接入层(MyCat|ES Client|Redis Proxy);
存储层(mongodb|solr|elastic search|redis|memcached|oracle|mysql);
访问层架构设计
LVS
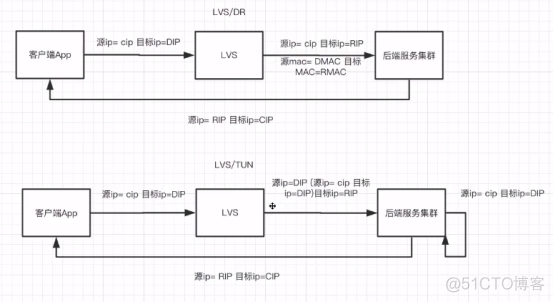
LVS集群采用IP负载均衡技术和基于内容请求分发技术,将请示均衡地转移到不同的服务器上执行,且调度器自动屏蔽掉服务器的故障,从而将一组服务器构成一个高性能的、高可用的虚拟服务器,整个服务器集群的结构对客户是透明的,而且无需修改客户端和服务器的程序;
IP层的负载均衡协议,无应用层回调消耗;
通过LVS-DR或LVS-TUN模型的特性使得请求返回不过LVS;
自动故障转移,心跳检测;
配合主从keepalive加vip实现自身高可用;
LVS-NAT;
LVS-DR(同一机房);
LVS-TUN(跨机房且RealServer要支持隧道协议);
LVS调度策略:
无脑轮询,带权重的无脑轮询;
最少链接,带权重的最少链接;
ip_hash,ip_hash_group;
Nginx
接入层Nginx
应用层Nginx
Nginx功能:
请求解析|负载均衡|缓存调度|授权认证|接入处理|业务逻辑|响应处理|压缩技术;
接入层Nginx主要职责:
请求解析;
请求业务路由;
业务负载均衡;
响应压缩;
应用层Nginx主要职责:
应用负载均衡(动静分离);
缓存调度;
授权认证;
业务逻辑;
业务限流;
业务降级;
Nginx高性能原因:
master-worker进程模型;
流式处理请求workflow,有主子请求;
协程机制;
nginx lua;
selector&epoll
apache select;
nginx epoll;
java nio selector linux 2.6+ epoll;
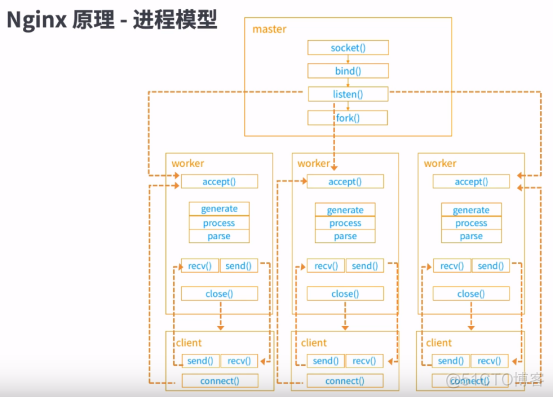
高性能线程模型:boss进程epoll注册,由work进程池竞争accept mutex用来获得连接的accept权限及后续的recv、send操作权限,本质在处理上仍然是等待阻塞式的效率。因此work进程内的workflow不能有阻塞式的操作,解决方式是通过协程去处理;
协程
线程
栈,局部变量在用户空间模拟;
协程间是协作关系;
切换开销小;
临界区不需要加锁;
遇到阻塞主动放弃切换;
栈,局部变量是内核空间的映射;
多线程并发运行竞争cpu;
切换开销大;
临界区需要同步加锁;
遇到阻塞进入等待cpu切换;
openresty,lua的集成开发环境
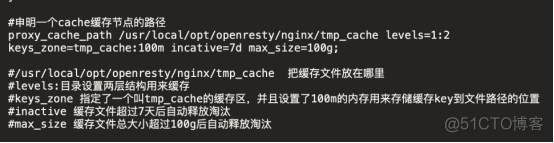
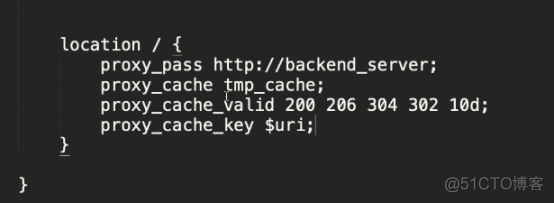
缓存配置(需在代理模式下使用):
API网关层架构设计
分布式会话管理
会话管理:
由于http请求的无状态性,因此引入了session会话管理机制,标识bs端之间会话状态;
分布式会话管理:
区别于传统的依赖web server session的会话管理状态,需要引入集中的会话存储容器,用于鉴别分布式状态下的bs端之间的会话标识;
集中式的会话管理,凭证放到redis|memcache|数据库中,重写session处理方式
会话管理的几种方式:
基于server端的session管理(依赖webserver的session容器;cookie跨域访问问题处理复杂;浏览器彬cookie问题);
基于cookie的管理方式(cookie跨域访问问题处理复杂;浏览禁用cookie问题);
基于token的管理方式(有效存储token,保证每次调用都能拿到token;需要应用代码处理将token加到header或接口传参内;不依赖浏览器cookie禁用问题,移动native应用hybrid开发方式支持好);
安全问题:
cookie并非安全,被劫持概率高,xss|csrf安全攻击等;
token凭证被劫持,伪造请求;
https请求防泄漏;
风控主动失效及过期机制;
接入层控制
控制什么:
通过api网关接入层控制程序入口处需要实现的逻辑,包括
身份验证(通过会话管理获取登陆用户凭证;通过用户凭证获取到用户身份信息;通过对应url是否可被对应身份的用户访问);
流量控制(对应url的流量是否可以承载,若不能,限流;对应服务分级的流量是否可以承载,若不能,限流;对应整个系统的总流量 是否可以承载,若不能,限流);
路由服务(根据对应url的规则寻找到响应服务;判定服务状态,做服务路由调用);
记录调试或统计信息(切面打印日志调试信息;切面打印cat监控);
实现原理:
使用不同接入层框架的通用Filter功能实现(java Servlet Filter|Spring MVC HandlerInterceptor|spring cloud中的Zuul Filter);
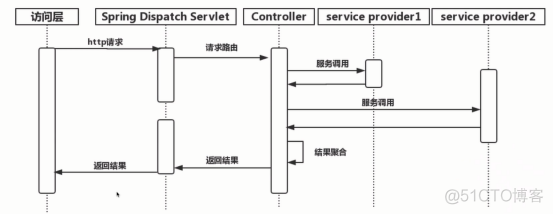
服务调用及聚合
api网关通过了接入层控制并路由后进入核心的服务调用环节,通过对后端服务的调用并聚合服务输出的数据后返回访问层;
2种:
“重”接入:spring mvc + dubbo;
优点:可灵活的在web层处理业务逻辑,聚合服务;
缺点:服务单一性不够,且过度的web层业务聚合能力会导致服务不便于管理;
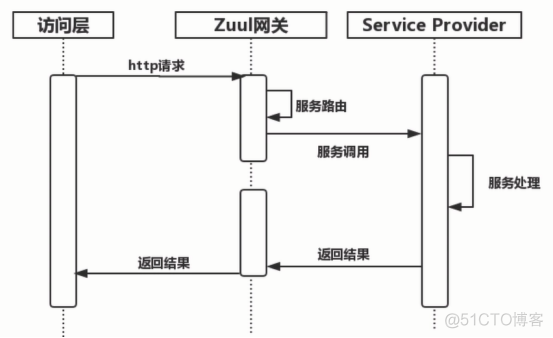
“轻”接入:spring cloud zuul;
优点:服务单一,可提供配置化接入;
缺点:聚合服务处理不够灵活,需要由service provider提供聚合服务能力;
核心服务层架构设计
服务通信
传统的服务和服务分层:
web层<-->业务层<-->数据访问层<-->数据持久层;
缺点:所有服务耦合在一起;隔离性弱,互相影响;部署臃肿;开发维护困难;
微服务:
多个传统的服务;
微服务指开发一个单个小型的但有业务功能的服务,每个服务都有自己的处理和轻量通信机制,可部署在单个或多个服务器上;
优点:服务高内聚、低耦合;隔离性强,不会互相影响;单独部署;独立开发;
要解决的问题:服务治理(服务调用通信、健康管理、限流熔断);数据一致性;调用性能;研发流程、调试、部署;
dubbo服务治理:
dubbo是用来解决微服务内服务治理问题的轻量级开源java rpc框架;
三大核心能力:面向接口的远程方法调用;智能容错和负载均衡;服务自动注册和发现;
服务治理的功能:服务提供者注册服务;服务消费者获取服务,并通过负载均衡策略选择服务提供者;动态增减服务提供者和服务消费者;服务监控;服务限流;服务降级;高容错;定制化开发;
总结:
服务提供者注册服务到注册中心;
服务消费者从注册中心获取服务,并通过负载均衡策略选择服务提供者;
动态增减服务提供者和服务消费者;
代码举例:
服务提供者提供用户信息发布服务;
服务消费者获取用户信息获取服务;
调用服务;
异步化消息服务
同步通信和异步通信通常用来形容一次方法调用;
同步通信方法,调用一旦开始,调用者必须等到方法调用返回后,才能继续后续的行为;
异步通信方法,调用更像是消息传递,一旦开始,方法调用就会立即返回,调用者就可以继续后续的操作。异步方法通常会在另一个线程中“真实”地执行,整个过程不会阻碍调用者的工作;
异步化好处:不会阻塞原来的业务;服务调用之间解耦,无需互相关注感知;
消息服务分类:
JMS(apache ActiveMQ),缺点:向consumer主动推消息,以消息为单位管理且消息在磁盘上不是连续的;点对点(发送者|接收者一对一发送,每个消息都被发送到一个特定的队列,接收者从队列中获取消息,队列保留着消息,直到他们被消费或超时);发布订阅(客户端将消息发送到主题,消息队列存放主题,订阅者消费主题消息);
Kafka(流式处理),发布订阅(客户端将消息发送到主题,消息队列存放主题,订阅者消费主题消息,消息持久化到队尾,消费通过客户端指针,吞吐量高);
RokcetMQ(分布式一致性),在kafka基础上开发且具有简单api,nameserver|broker中有多个queue|消息是连续的且通过offset指针定位消息消费情况|consumer拉取消息|有失败重试队列|支持事务型消息;发布订阅(客户端将消息发送到主题,消息队列存放主题,订阅者消费主题消息,消息队列维护高可用,并支持事务回溯机制);
任务调度
任务task,需要依靠计算机程序完成的一系列事情;
调度control,执行控制任务的指挥,触发,规则程序;
任务调度,使用一系列的触发规则在特定的时间点指挥计算机完成一系列的事情;
应用场景:
业务跑批轮询等待处理;
失败异常重度;
定时处理任务;
单机调度方式及实现:
Timer定时器机制,所有任务都是同一个线程来调度,因此所有的任务都是串形执行的,同一时间只能有一个任务在执行;
ScheduledExecutor,每一个被调度的任务都会由线程池中一个线程去执行,因此任务是并发的,而且相互不会产生干扰,如果任务数 > 线程池数量则要等待;
Quartz,任务+调度,Scheduler+JobDetail+Trigger(Crontab)+线程池;
分布式调度方式及实现:
Quartz分布式版本,前提(1保证2台主机的时间是同步对称的;2代码部署也要对称;3需要中间层同步竞争锁),数据库内部会存放对应的trigger当次执行的任务时间及下次要执行的时间及任务的当前状态,被谁执行了;
Elastic-Job分片分布式,zookeeper+多主机任务,前提(1保证主机时间同步;2代码部署对称;3需要中间层同步竞争锁;4任务要带分片属性);
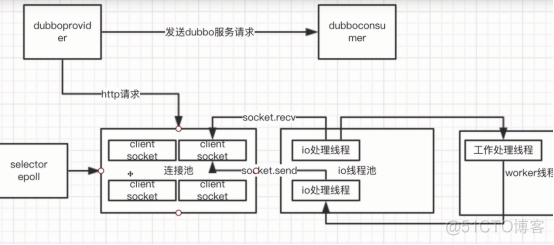
池化技术
池化技术是用来减少系统消耗,提升系统性能的;
简单来说,池化技术就是通过复用来提升性能;
对象池:利用利用对象来减少创建对象、垃圾回收的开销,如线程池通过利用线程提升性能;
连接池:数据库连接池、redis连接池、http连接池,通过复用tcp连接来减少创建和释放连接的时间;
常用连接池:
Java线程池(核心(最小)线程数大小,最大线程数大小,等待队列长度,拒绝策略,idle等待时间);
数据库连接池(核心连接数,最大连接数,连接等待时间,数据读取时间,等待释放时间,validate);
HttpClient连接池|Dubbo连接池|Redis连接池|Tomcat连接池;
高并发的设计原则:宁可限、不要烂;
缓存技术
缓存是分布式系统中的重要组件,主要解决高并发、大数据场景下,热点数据访问的性能问题,提供高性能的数据快速访问;
设计原则:
将数据写入|读取速度更快的存储设备;
将数据缓存到离应用最近的应用;
将数据缓存到离用户最近的位置;
缓存分类:
CDN缓存;
反向代理缓存;
分布式缓存redis;
本地应用缓存jvm guava;
如何缓存:
实时写入;
异步写入;
读取时实时写入;
读取时异步写入;
如何失效:
固定时间;
相对时间;
多级缓存:
CDN缓存;
nginx代理缓存;
nginx lua shared dict缓存;
nginx lua redis缓存;
tomcat本地缓存;
tomcat redis缓存;
数据库;
缓存不一致性:
容忍性;
异步更新性;
隔离技术
隔离指将系统或资源分割开,系统隔离是为了在系统发生故障时能限定传播范围和影响范围,即发生故障后不会出现滚雪球效应,从而保证只有出问题的服务不可用,其他服务仍可用;
常见隔离维度:
硬件隔离(虚拟机);
操作系统隔离(容器虚拟化);
进程隔离(系统拆分);
线程隔离(线程孙悦独立);
读写隔离(读写分离);
动静隔离(动态资源静态资源分离);
热点隔离(热点账户、热点数据等);
队列技术
队列在数据结构中是一种线性表,从一端插入数据,然后从另一端删除数据;
队列的用途:
异步处理;
系统解耦;
流量削峰(排队有时候比并发效率更高;排队可控制并发流量涌入);
应用场景:
mysql innodb primary key mutex;
redis key update flush,单线程排队;
数据存储
分布式存储,提供可无限扩展的网络文件系统;
关系型数据库,提供事务一致性的存取介质;
非关系型数据库,提供高性能的简化存储;
数据磁盘or内存,性能和稳定的选择;
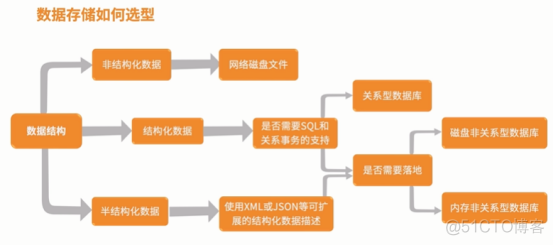
数据结构:
结构化数据;
非结构化数据;
半结构化数据;
数据库系统:
结构化;
非结构化;
数据是否落地:
磁盘落地数据库;
内存级数据库;
混合级数据库;
数据存储的重要性:
所有的用户操作及变更最终都反映在数据存储层面;
数据存储需要确保最终一致性;
数据存储是系统的性能瓶颈点;
常用的数据存储中间件:
NAS,网络文件系统,基底层设备,提供文件磁盘;
阿里OSS,阿里云OSS网络文件存储;
SQL关系型数据库,MySQL|MS SQL|DB2|SQLite;
非关系型数据库,MongoDB|HBase;
缓存型数据库,H2|MemCache|Redis;
关系型与非关系型:
关系型
非关系型
存储格式
关系型存储格式
key-value存储格式
查询速度
需要依赖索引提高查询
使用key查询速度快,大多使用单线程存储,无需锁
事务性保障
事务保障效率高
没有事务概念
复杂查询
可进行join的复杂查询
能力较弱,但字段不固定时可以应用,适合半结构化数据
接入层架构设计-代理访问
代理对象分类:
反向代理;
数据库代理;
redis代理;
代理访问定义,代理一个或一群后端的被访问对象,使得调用端看似在直接访问后端对象一样,代理访问的代理器从而可实现多种负载均衡,故障转移,缓存策略等个性化配置,同时又可分散被代理的后端对象压力;
为什么要代理访问:
集中收口逻辑;
负载均衡;
路由策略,分库分表;
故障转移;
缓存策略;
减少后端被代理对象压力;
常见的被代理对象:
后端应用服务器,nginx;
数据库服务器,mycat;
缓存服务器,twemproxy;
后端代理服务器:
有,仅需要一个公网IP绑定到代理服务器|可故障自动转移|代理服务器可负载均衡|代理服务器可集中缓存热点服务器;
没有,需要多个公网IP支持多服务器|无法故障自动转移|负载均衡只能依靠DNS轮询寻址|每个后端服务器各自缓存热点数据;
数据库代理:
有,可支持分库分表的路由策略逻辑|可支持主从切换|可支持连接池管理;
没有,应用层需要处理分库分表逻辑|应用层需要处理主从切换|应用层需要各个数据库都维护连接池|数据库连接数量不够;
监控
硬件指标|软件指标|接口指标|异常指标|大盘指标;
硬件指标:cpu idle time|free memory|io wait|network free;
软件指标:cpu load average|ParNewCount|ParNewTime|Old GC Count|Old GC Time;
接口指标:url/dubbofailure times|url/dubbo 9599.9 99.99 lines;
异常指标:Exception times and content;
大盘指标:基线成功率|基线失败率|总体响应时间指标;
限流
为什么限流?
流量远比能力大;
永远不知道对方怎么样;
永远不知道自己怎么样;
限流维度1:URL|Dubbo接口|SQL操作数;
限流维度2:限制TPS/QPS|限制并发数|限制总数;
限流算法原理:
限制并发数,在dubbo_provider内存内以接口名为单位设置一个计数器,当调用开始,计数器-1,并判断是否到0,若到0了则返回限流异常,否则执行业务逻辑返回后将计数器+1;
令牌桶算法,以桶模拟对应的接口令牌池,若有请求进入则获取对应的令牌并返回给调用方代表可以执行操作,然后有一个计时器每隔一秒钟重置桶内的令牌数量则可以访问的tps;
漏桶算法,匀速流出tps,若要访问则流入tps的量不能大于桶内剩余的容量,和令牌桶相比可以允许有突发流量的发生;
单机限流,很难保证绝对意义上的负载均衡;
集群限流,对应所有的操作都要通过中央管理点,性能瓶颈;
降级
当系统遇到某些情况下主动或被动采取的一种保护策略,既可以保护系统正常运行,又可以使得用户体验在可接受的损失范围内;
为什么要降级?
保护系统;
保护用户体验;
排查问题;
怎样降级?
关闭接口并设置默认返回;
降级逻辑;