1、bash中,在一条命令后加入1 >&2意味着“标准输出重定向到标准错误输出”;
0标准输入stdin
1标准输出stdout
2标准报错输出stderr
>输出重定向符
<输入重定向符
2>标准错误输出
2、String类和StringBuffer类,都用来代表字符串,StringBuffer的内部实现和String不同,StringBuffer在进行字符串处理时不生成新的对象,在内存使用上优于String类,StringBuffer适用于变长(实际使用时如果经常需要对一个字符串进行修改,如插入|删除等操作),String定长;
3、标识符不合法的是const,另$double|hello|BigMeaninglessName合法;
标识符不合法的是:1234|new|car.taxi;
4、用union上下连接的各个select都可以带有自己的order by子句(X错误);
(select * from t1 where username like 'I%' order by score asc)
union
(select * from t1 where username like '%m%' order by score asc) # 在没有括号的情况下会报Incorrect usage of UNION and ORDER BY,这种写法虽然不报错了,但括号中的order by并没有效果
select * from t1 where username like 'I%'
union
select * from t1 where username like '%m%' order by score asc; # 在后一个语句中再使用order by,即对整个结果进行order by
select * from
(select * from t1 where username like 'I%' order by score asc) t3
union
select * from
(select * from t1 where username like '%m%' order by score asc) t4 # order by不能直接出现在union的子句中,但可以出现在子句的子句中
另,union会过滤掉2个结果集中重复的行,而union all不会过滤掉重复行;
5、nginx反向代理worker_processes=8,worker_connections=1000,求最大并发数8*1000/2=4000;
nginx作为http服务器时,max_clients = worker_prcesees * worker_connections;
nginx作为反向代理时,max_clients = worker_processes * worker_connections /2;
6、Elasticsearch的每个实例都是一个节点,多个节点的集合可以协调工作,形成一个Elasticsearch集群;
7、SpringBoot允许配置多协议,在不同服务上支持不同协议或同一服务上同时支持多种协议,比如在单一服务上同时提供http协议服务和tcp协议服务;
8、Redis支持的list数据类型数据不支持索引下标操作(X错误);
9、多选,RocketMQ中重要的角色有:Producer|Consumer|NameServer|Broker;
生产者|消费者|代理;
10、哪个不是常见的服务器品牌商,Western Digital,另HP|DELL|LENOVO是;
11、在centos linux中,查看kernel信息命令是uname -a;
12、以下方法定义,该方法的返回类型是double;
ReturnTypemethod(bytex, double) {return (short)x+y*2}
13、多选,java常用的线程池有:
newCachedThreadPool可缓存线程池,线程数量不定,最大线程数为Integer.MAX_VALUE,默认timeout=60s,适合执行大量耗时较少的任务;
newFixedThreadPool定长线程池,指定工作线程数量的线程池,线程空闲时不会被回收,被称为可重用固定线程数的线程池;
newScheduledThreadPool定长线程池,核心线程数量固定,而非核心线程数是没有限制的,当非核心线程闲置时会被立即回收,主要用于执行定时任务和具有固定周期的重复任务;
newSingleThreadExecutor单线程化的线程池,只有一个核心线程,以无界队列方式来执行该线程,确保所有任务在同一个线程中按顺序执行,且可在任意给定的时间不会有多个线程是活动的;
14、SpringCloud的组件Ribbon是一个负载均衡客户端,可以很好地控制http和tcp的一些行为,Ribbon默认集成了feign组件和Hystrix实现了熔断功能(X错误);
SpringCloud五大常用组件:
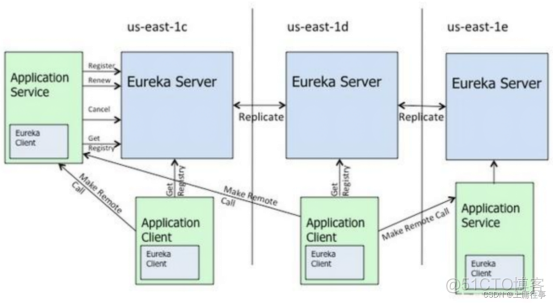
Eureka,服务注册与发现,实现服务治理,分Eureka服务端(用作服务注册中心,支持集群部署)和客户端(是一个java客户端,用来处理服务注册与发现),在应用启动时,Eureka客户端向服务端注册自己的服务信息,同时将服务端的服务信息缓存到本地,客户端会和服务端周期性地进行心跳交互,以更新服务租约和服务信息;
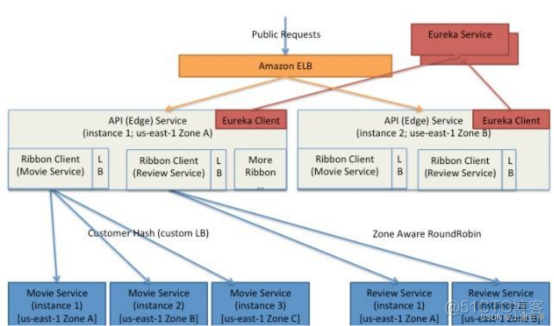
Ribbon,客户端负载均衡,主要提供客户侧的软件负载均衡算法,是一个基于http和tcp的客户端负载均衡工具,它基于netflix ribbion实现,通过springcloud的封装可让我们轻松地将面向服务的rest模板请求自动转换成客户端负载均衡的服务调用,关键点就是将外界的rest调用,根据负载均衡策略转换为微服务调用;
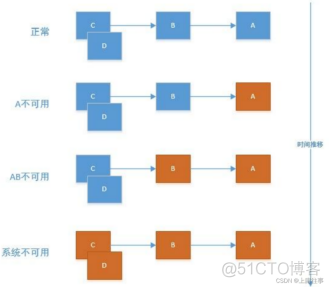
Hystrix,断路器,保护系统,控制故障范围,为保证其高可用,单个服务通常会集群部署,由于网络原因或自身原因,服务并不能保证100%可用,如果单个服务出现问题,调用这个服务就会出现线程阻塞,此时若有大量的请求涌入,Servlet容器的线程资源会被消耗完毕,导致服务瘫痪,服务与服务之间的依赖性,故障会传播,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的雪崩效应;
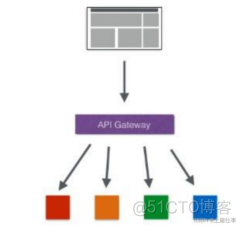
Zuul,服务网关,作用api网关|路由|负载均衡等多种作用,类似nginx反向代理的功能,不过netflix自己增加了一些配合其他组件的特性,在微服务架构中,后端服务往往不直接开放给调用端,而是通过一个api网关根据请求的url路由到相应的服务,当添加api网关后,在第三方调用端和服务提供方之间就创建了一面墙,这面墙直接与调用方通信进行权限控制,后将请示均衡分发给后台服务端;
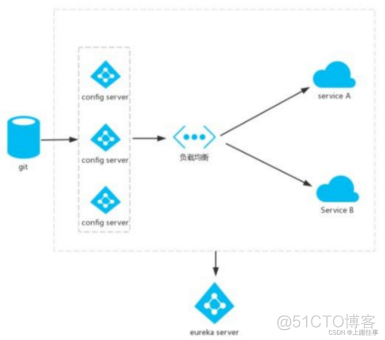
Config,分布式配置,作用配置管理,SpringCloud Config提供服务器端和客户端,服务器存储后端的默认实现使用git,因此它轻松支持标签版本的配置环境,以及可访问用于管理内容的各种工具,这是静态的,动态的需要配合springcloud bus实现动态的配置更新;
15、Which storage option ofr MySQL data directory typically offers the worst performance in a highly concurrent, OLTP-heavy, IO-bound workload? NFS
另RAID5|iSCSI|
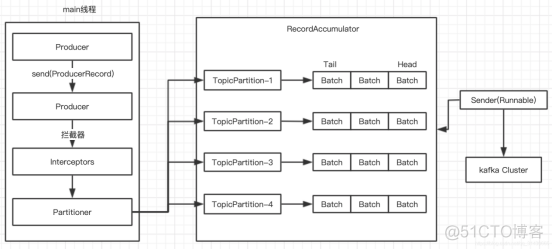
16、生产者发送消息采取异步发送方式,在消息发送过程中,与下列哪个参数不相关:ProducerRecord;
ProducerRecord、RecordMetadata包含了返回的结果信息;
发送时涉及到的重要线程是Sender线程,及线程共享的变量RecordAccumulator,sender线程不断从accumulator中拉取消息发送到broker;
17、mongodb分片是基于区域的,所以一个集合的所有对象都放在同一个块中(V正确);
只有当存在多余一个块的时候,才会有多个分片获取数据的选项;
18、多选,说法正确的是:
字符型既可用单引号也可用双引号;
字符型的87398143不参与计算;
87398143不能声明为数值型;X错误
数值型的87398143将参与计算;
19、可获取以6-20个字母组成的name是:name regexp '[a-zA-Z]{6,20}'
20、在正则表达式中,匹配任意一个字符的符号是_;
*任意长度任意字符
?任意单个字符
[]指定范围内的任意单个字符
[^]指定范围外的任意单个字符
21、多选,Redis持久化机制的说法,正确的是:
Redis默认采用RDB机制;
RDB是以快照形式存储数据结果,存储格式简单;
AOF持久化机制是以日志形式存储操作过程,存储格式复杂;
持久化的目的是防止数据的意外丢失,确保数据安全性;
22、Kafka对于某一topic中指定数据默认保存时间为7天(168时):
23、存储过程的叙述错误的是:
MySQL允许在存储过程创建时引用一个不存在的对象;
存储过程可以带多个输入参数,也可以带多个输出参数;
使用存储过程可以减少网络流量;
在一个存储过程中不可以调用其他存储过程;(X错误)
24、redis中RDB和AOF两种持久化机制的比较,错误的是:
对业务数据敏感的应用场景选用AOF持久化机制;
追求大数据集恢复速度的应用场景选用RDB;
AOF持久化机制比RDB的存储速度快;
AOF比RDB的恢复速度快;(X错误)
25、查看selinux的状态:getenforce;
26、可以回收代理权限的是:revoke proxy on ACCOUNT1 from ACCOUNT2;
27、多选,nginx默认限流算法:漏斗|令牌桶;
令牌桶,算法思想,令牌以固定速率产生,并缓存到令牌桶中;令牌桶放满时,多余的令牌被丢弃;请求要消耗等比例的令牌才能被处理;令牌不够时,请求被缓存;
漏桶,算法思想,请求(水)从上方倒入水桶,从水桶下方流出(被处理);来不及流出的水存在水桶中(缓冲),以固定速率流出;水桶满后水溢出(丢弃);核心是缓存请求、匀速处理、多余的请求直接丢弃;
相比漏桶算法,令牌桶算法不同之处在于它不但有一只桶,还有个队列,这个桶是用来存储令牌的,队列才是用来存放请求的,从作用上来说,漏桶和令牌桶算法最明显的就是是否允许突发流量burst的处理,漏桶算法能够强行限制数据的实时传输(处理)速率,对突发流量不做额外处理,而令牌桶算法能够在限制数据的平均传输速率的同时允许某种程度的突发传输;
限速模块:ngx_http_limit_conn_module按连接数限速,ngx_http_limit_req_module按请求速率限速;
28、Dubbo默认会在启动时检查依赖的服务是否可用,不可用时会抛出异常,阻止Spring初始化完成,默认check=true,可通过check=false关闭检查;
29、Which statement best describe a 'warm' backup?
It is similar to a 'hot' backup, but differs in that it does not permit(许可|批准) write operations.
30、redis集群模式,master-slave|redis-cluster|sentinel;
31、多选,哪些是mysql数据类型:BIGINT|INTEGER|MEDIUMINT|SMALLINT|TINYINT|INT;
32、一张表的主键个数,至多1个;
33、哪个一个操作符的优先级最高,();
运算优先级别最低的是:赋值运算符;
34、当一个服务调用另外一个服务时,由于网络原因或者自身原因出现问题时,服务的调用者就会等待被调用者的响应,当更多的服务请求到这些资源时,会导致更多的请求等待,这样就会发生连锁反应(雪崩效应),SpringCloud的Hystrix组件是解决这一问题的;(X错误)
35、mysql所创建的数据库和表的名字,都可以使用中文(V正确);
36、根据关系模型的完整性规则,一个关系中的主键不允许空值;
37、Spring的AOP动态代理机制都有哪些?CGLib库|JDK动态代理;
38、关于topic和partition的描述正确的是:
Kafka中的消息是以partition进行分类的(X错误);
与partition不同,topic是逻辑上的概念而非物理上的概念;
每个partititon对应于一个log文件;
一个partition分为多个segment;
39、对于kafka而言,订阅消息的高传送速度,与哪个技术无关?IO读写技术
40、redis中的故障转移机制中cluster-node-timeout的默认值为1500ms;
41、常用的负载均衡算法:轮询|随机法|最大连接数,而源地址hash不是;
7种:
完全随机算法;
加权随机算法;
完全轮询算法;
加权轮询算法;
平滑加权轮询算法;
哈希算法;
最小压力算法;
42、NULL和Null都代表空值(V正确)
43、对于显示操作说法正确的是:
show databases;显示所有数据库;
show tables;显示所有表;
44、常见的序列化协议有:hessian|kyro|protostuff|protobuf;
45、Spring框架中的单例bean是线程安全的(X错误);
46、多选,关于kafka清理过期数据的说法,正确的是:
清理的策略包括删除和压缩;
log.cleanup.policy=delete启用删除策略;
log.cleanup.policy=compact启用压缩策略;
启用压缩策略后只保留每个key指定版本的数据;X错误
47、为了让Mysql较好地支持中文,在安装Mysql时应将数据库服务器的缺少字符集设定为utf-8;
48、mysql的默认端口3306;
49、如果要回滚一个事务,则要使用rollback transaction语句;
50、关于redis中hash数据类型的操作指令,错误的是:
hvals <key>,用于获取该hash集合中所有的value;
hincrby <key> <field> <increment>,用于为指定key对应的field增加指定值;
hsetnx <key> <field> <value>,用于在filed不存在时将其值设置为value;
hkeys <key>,用于获取该hash集合中所有的key(错误,应为获取所有哈希表中的字段);
51、select (NULL <==> NULL) is NULL;的结果是1(X错误);
52、主键的建立有(三)种方法;
create table stu (sno char(5) primary key, sname char(20) not null); # 定义字段时直接指定PK
cretae table stu (sno char(5), constraint pk_stu primary key(sno), sname char(20) not null); # 定义字段之后,再定义PK
alter table stu add constraint pk_stu primary key(sno); # 通过修改表设置PK
# 创建FK三种方法
create table sc (sno char(5) constraint fk_stu references stu(sno), cno char(5)); # 写在属性定义里面
create table sc (sno char(5), constraint fk_stu references stu(sno), cno char(5)); # 写在属性定义外面
alter table sc add constraint fk_stu foreign key(sno) references stu(sno);
53、ElasticSearch支持动态变更数据类型(X错误);
54、哪个注解关键字来指明注解作用的范围:Target;
自定义注解的元注解:
1) @Target,作用域,constructor构造方法声明,field字段声明,local_variable局部变量声明,method方法声明,package包声明,parameter参数声明,type类、接口声明;
2) @Retention,生命周期,source只在源码显示编译时会丢弃,class编译时会记录到class中运行时忽略,runtime运行时存在可通过反射读取;
用@Retention(RetentionPolicy.CLASS)修饰的注解,表示注解的信息被保留在class文件(字节码文件)中当程序编译时,但不会被虚拟机读取在运行时;
用@Retention(RetentionPolicy.SOURCE)修饰的注解,表示注解的信息会被编译器抛弃,不会留在class文件中,注解的信息只会留在源文件中;
用@Retention(RetentionPolicy.RUNTIME)修饰的注解,表示注解的信息被保留在class文件(字节码文件)中当程序编译时,会被虚拟机保留在运行时;
所以他们用反射的方式读取;
3) Inherited,标识注解,允许子类继承;
4) Documented,生成javadoc;
55、在c/s模式中,客户端不能和服务器端安装在同一台机器上(X错误);
56、多选,通过申请拿到数据中心物理机或虚拟机资源后,哪些操作不能做:
随意添加普通账号,并添加sudo权限;
把密码改成123456方便记忆;
把密码明文保存在电脑桌面;
批量修改/etc/下的文件或权限;
57、使用create table语句的(FULLTEXT)子句,在创建基本表时可启用全文本搜索;
58、为数据表创建索引的目的是,提高查询的检索性能;
59、查找表结构用DESC;
60、LTRIM、RTRIM、TRIM函数既能去除半角空格,又能去除全角空格(X错误);
61、要快速完全清空一张表中的记录可用truncate table;
62、哪个命令可列出定义在以后特定时间运行一次的所有任务,atq;
63、update语句可以有where子句和limit子句;
可使误操作风险降低;
当更新语句中的where字段没有索引时,如果没有使用limit会锁全表;如果使用了limit,mysql会通过主键索引找到对应的记录,此时只会给索引搜寻过的行加上行锁并不会把后面的行锁住;
64、ElasticSearch中哪个方法标识根据词条查询数据:QueryBuilders.termQuery;
65、ldconfig的配置文件是:/etc/ld.so.conf;
66、What are three typical causes of MySQL becoming suddenly slow or unavailable?
A configuration change was made.
Monitoring has not enabled Performance Schema instruments.
The hardware includes a single point of failure. The MySQL Query Cache is disabled.
67、编译时不会出现警告或错误的是:bollean b=null;而int i=10.0、char c='c'、floa t f=3.14会;
68、服务器中的RAID管理程序可用于故障磁盘修复和重建;
69、如果你的umask设置为022,缺省的你创建的文件的权限为:rw-r--r--;
umask决定目录和文件被创建时得到的初始权限,新建的目录权限是755,新建的文件权限是644;
70、Springboot中可通过spring.profiles.active参数实现读取不同环境配置;
71、Kafka的消息归纳分类是依据topic进行的;
72、多选,属于kafka生产者分区写入策略的是:
轮询分区策略,默认策略,使用最多,可最大限度地保证所有消息平均分配到分区里面,如果在生产消息时,key为null则使用轮询算法均衡地分配分区;
随机分区策略,基本废弃,可能会造成数据倾斜;
按key分区分配策略,key.hash() % 分区的数量,然后shuffle到对应的分区,有可能会出现数据倾斜,如某个key包含了大师的数据,因为key一样,所有的数据都将分配到一个分区中,造成该分区的消息数量远大于其他分区;
自定义分区策略,通过自定义方法实现;
73、在java中一个类可同时定义许多同名的方法,这些方法的形式参数个数、类型、顺序各不相同,传回的值也不相同,这种面向对象程序的特性称为(重载);
74、在数据库系统中,有哪几种数据模型,网状模型、层次模型、关系模型;
75、消息在发往kafka前,要经历拦截器、序列化器、分区器等一系列的动作,其执行顺序是拦截器-->序列化器-->分区器;
76、redis数据存储中redisObject对象的说法:
refcount记录的是该对象被引用的次数,占4个byte;
lru记录对象最后一次被命令程序访问的时间,占24个bit(X错误);
type字段表示对象的类型,占4个bit;
encoding表示对象的内部编码,占4个bit;
77、mysql支持的数据表类型有:ISAM|MyISAM|HEAP|INNODB;
78、对于使用分布式消息队列MQ的优势:
异步处理,相比于传统的串行、并行方式,提高了系统的吞吐量;
应用解耦,系统间通过消息通信,不用关心其他系统的处理;
流量削峰,可以通过消息队列长度控制请求量,可以缓解短时间内的高并发请求;
高吞量,提高单位时间内系统处理的请求数量(X错误);
79、与权限相关的数据表有:user|db|tables_priv|columns_priv;
80、查找某个命令文件出自什么安装包,使用rpm -qf FILENAME;
rpm -ql PACKAGENAME;
81、RocketMQ中提供了两种consumer从broker中拉取消息的类型,其中pull consumer留有一个回调接口供用户去实现(X错误);
82、redis2.8以后版本中通过info server可查看节点的服务器运行id即run_id;
83、在zabbix客户端的配置文件zabbix_agentd.conf中添加上自定义的UserParameter是方便zabbix调用脚本去获取待监控服务的信息;
84、mysql如果需要存储定长字段,如身份证号,哪种数据类型更合适,char;
85、冗余阵列中磁盘使用率最高的是5;
冗余阵列中安全性最高的是1;
86、Netflix Riboon HTTP client该http客户端不支持patch方法,且有内置的重试机制;
87、删除用户账号命令是drop user;
88、哪个方法用于定义线程的执行体,run();
89、Ealsticsearch中doc_values是默认开启的;
90、zookeeper的znode有四种类型:
PERSISTENT,永久节点,从一开始被创建永久存在直到被主动删除,不会因为client的session断开而被删除;
PERSISTENT_SEQUENTIAL,永久有序节点,跟PERSISTENT一样,唯一的区别是节点名会被追加一个单调递增的十进制序号;
EPHEMERAL,临时节点,被client创建,client断开连接,节点就被删除,节点名会被追加一个单调递增的十进制序号;
在3.5.5+版本,又增加了3种类型:
CONTAINER,容器类型,主要用于zk的leader选举和分布式锁等场景,其特点是,当容器节点的最后一个子节点被删除,则该节点会变成候选删除节点,在将来的某个时刻被zk服务删除;
PERSISTENT_WITH_TTL,带过期时间的永久节点,特性跟PERSISTENT类似,区别是一量在过期时间内节点没有任何修改,并且没有任何子节点,则该节点会被删除,ttl时间为ms;
PERSISTENT_SEQUENTIAL_WITH_TTL,带有过期时间的永久有序节点;
91、关于rocketmq:
一个mq集群可以分为单master、多master、异步多Master多salve、同步多master多slave几种模式;
在主从模式(单副本)下,如果主节点宕机,集群判断主节点不可用时会让从节点接管对应主节点的消息生产与消费(X错误);
Nameserver每隔10s,扫描所有还存活的broker连接,若某个连接2min内没有发送心跳数据,则断开连接;
集群模式下,一个consumuer group中的consumer实例平均分摊消费消息;集群消息模式下,消息消费的偏移量信息会存储在broker上;
92、ElasticSearch支持事务一致性(X错误);
93、Redis并不能保证数据的强一致性,这意味着在实际中集群在特定的条件下可能会丢失写操作;
94、多选,关系数据库基本特征:
与列的次序无关;
不同的列有不同的列名;
与行的次序无关;
95、针对2.0.X版本的kafka生产者分区写入策略:
当生产消息时,key为null则采用轮询分区策略;
轮询分区策略是默认的分配策略;
按key分区分配策略有可能由于key值相同导致大量数据保存在同一个分区中;
采用自定义分区策略时需要实现partition接口;
96、说法正确:
call by value不会改变实际参数的数值;
call by reference不能改变实际参数的参考地址;
call by reference能改变实际参数的内容;
解析:
java中参数的传递有2种,一种是按值传递(传递的是具体的值,如基础数据类型),另一种是按引用传递(传递的是对象的引用,即对象的存储地址);
按值传递时在调用的方法中,参数只是实际参数的一个拷贝,所以不管参数在方法里面如何修改都不会改变原来参数值,即val的值一直保持不变;
按引用传递时,会产生一份新的引用(如y),此时x和y指向了同一个对象;
97、关于leader和follower的说法:消费者消费数据的对象都是leader;
98、触发器是响应以下任意语句而自动执行的一条或一组mysql语句,update|insert|delete;
99、返回当前日期的函数是curdate();
返回当前时间的函数是curtime();
100、hashmap的数据结构是数组|链表;
jdk1.8以前是数组+链表;
jdk1.8以后是数组+链表+红黑色;
2) 数据结构的物理结构:
指数据的逻辑结构在计算机中的存储形式,数据元素的存储结构形式有如下2种:
顺序存储结构,把数据元素存放在地址连续的存储单元里,其数据间的逻辑关系和物理关系是一致的;
链式存储结构,把数据元素存放在任意的存储单元里,这组存储单元可以是连续的,也可以是不连续的,找时把一个指针存放在数据元素的地址,可通过指针寻找到对应的数据元素;
两种结构各有优缺点,可相互结合运用,hashmap正好两种结构都用到了;
3) 数组,hashmap的主干结构是数组,即key经过hash计算后将节点对象存放到数组对应的位置上;
4) 链表,如果多个不同的key经过hash计算后得到的值相同,那么在数组对应位置上存储多个对象的链表,每个对象的属性除了key|value外还有next,即指向下一个节点的地址;
5) 红黑树,如果某一条链表的长度超过8(默认),则转为红黑树的存储方式;
101、可以设置数据精度的是float|double|decimal;
102、当preferred leader选举被自动触发时,Preferred replica partition leader选举策略被激活;
103、说法正确:
在mysql中用户在单机上操作的数据就存放在单机中;
在mysql中,可以建立多个数据库,但也可通过限定,使用户只能建立一个数据库;
要建立一张数据表,必须先建立数据表的结构;
104、jvm启动调优参数有:-Xmx|-Xms|-Xmn|-XX:MetaspaceSize;
105、redis的主从复制机制说法正确的:
实现数据的热备份;
当主节点出现问题时,可由从节点提供服务,实现快速的故障恢复;
分担服务器负载,提高服务器的并发量;
106、Which three tasks are handled by the optimizer?
Rewrite the WHERE clause.
Change the order in which the tables are joined.
Decide which indexes to use.
107、forward执行在客户端而sendRedirect()执行在服务端(X错误);
108、接入skywalking监控是需要改动代码的(X错误);
109、要保证消息持久化成功的条件:
消息已经到达持久化队列;
消息已经到达持久化交换器;
消息推送投递模式必须设置持久化;
110、微服务中有关Mock或Stub区别描述:
一个有助于运行测试的虚拟对象;
在某些可以硬编码条件下提供固定行为;
永远不会测试存根的任何其他行为;
支持测试存根的部分其他行为;(X错误)
111、能删除一列的是:alter table emp drop column cloumn_name;
112、Springboot项目中使用@importResource来兼容项目(spring框架);
113、mysql中锁粒度有:行级锁|表级锁|页级锁|间隙锁;
行级锁,是mysql中锁粒度最细的一种锁,表示只针对当前操作的行进行加锁,行级锁能大大减少数据库操作的冲突,其加锁粒度最小,但加锁的开销也最大,行级锁分为共享锁和排 他锁;
表级锁,是mysql中锁粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗最少,被大部分mysql引擎支持,表级锁分为表共享锁(共享锁)与表独占锁(排他锁);
页级锁,是mysql中锁粒度介于行级锁和表级锁中间的一种锁,表级锁速度快,但冲突多,行级锁冲突少,但速度慢,因此采取了折中的页级锁,一次锁定相邻的一组记录;
间隙锁,锁定一个范围,但不包括记录本身,gap锁的目的是为了防止同一事务的2次当前读,出现幻读的情况,该锁只会在隔离级别是rr或者以上的级别内存在,间隙涣的目的是为了让其他事务无法在间隙中新增数据;
114、kafka的容错性说法:
杀死集群中所有的副节点还可以使用;
只要还有一个副本,都不会影响Kafka使用,与结束的是主副broker无关;
杀死集群中的主节点还是可以使用;
不允许集群中节点失败;(X错误)
115、Spring中可以注入一个null和一个空字符串;
116、eureka和zk都可以提供服务注册与发现的功能,如下描述:
eureka是AP原则,可用性和分区容错性;
zk当主节点故障时,zk会在剩余节点重新选择主节点,耗时过长,虽然最终能恢复,但选取主节点期间会导致服务不可用,这是不能容忍的;
zk是CP原则,强一致性和分区容错性;
eureka各个节点是不平等的,一个节点挂掉会影响其他节点的正常运行;(X错误)
117、Mybatis二级缓存的存储作用域是Mapper(Namespace),并且不可以自定义存储源;(X错误)
118、windows可通过角色和功能添加的服务有:域名服务|文件服务|目录服务;
119、redis集群最大节点个数是16384;
120、dmesg命令可查看linux的启动信息;
121、Springboot中使用management.security.enabled=true禁用actuator端口安全;(X错误)
122、CAP原则又称CAP定理,指在一个分布式系统中,Consistency|Availability|Partition tolerance,Eureka的设计遵循哪些原则:AP满足可用性、分区容错性原则,但对一致性要求略低;
123、elasticsearch http默认使用的端口是9200;
124、合法的数组声明和构造语句:int[]ages=newint[100]、int[]a、int[][]a、inta[];
数组声明和初始化的语句:int[][]a4=newint[3][3]、inta1[]={3,4,5}、Stringa2[]={'string1', 'string1', 'string1'};而Stringa3[]=newString(3)、int[][3]a不正确;
125、windows系统日志存放的路径为%systemroot%\system32\config\SysEvent.EVT;
126、当broker正常关闭时,该broker上的所有leader副本都会下线,通过ControlledShutdownPartition leader选举策略为受影响的分区重新选举leader;
127、redis集群数据分区规则,正确的说法:
带虚拟节点的一致性hash分区通过槽解耦了数据和实际节点之间的关系;
哈希取余分区的主要问题是节点数量发生变化时会引发大规模的数据迁移;
一致性哈希分区的主要问题是当节点数是较少时,增加或删除节点会造成数据不平衡;
衡量哈希分区方法的好坏的标准是保证数据分布均匀和增删节点对数据分布的影响两个因素;(X错误)
128、为什么要选择微服务架构?
可在相对较短的时间内独立部署;
微服务可轻松适应其他框架或技术;
单个进程的失败不会影响整个系统;
一个服务可包含多个领域的接口;(X错误)
129、多选,redis主从复制机制:
可以实现rw分离;
可以实现自动故障转移;(X错误)
一个从节点可以没有主节点,也可以有多个从节点;(X错误)
数据的复制是双向的,既可以由主节点到从节点,也可以由从节点到主节点;(X错误)
130、不可作为java语言修饰符的是11,另_1|1.0|a1;
131、逻辑运算符优先级not|and|or;
132、下列说法错误的是:
生产者发送数据的对象是leader;
当集群中的某个节点发生故障时,replica上的partition数据不会丢失;
生产和消费者面向的都是一个topic;
partition是一个没有顺序的队列;(X错误)
133、Consider the ANALYZE TABLE command. In which two situations should this command be used?
after large amounts of table data have changed
when you want to update index distribution statistics
134、redis支持的zset数据型,说法:
redis使用ziplist(压缩列表)来实现zset类型时需要满足zset类型所有member的长度小于zset-max-ziplist-value;
redis使用ziplist(压缩列表)来实现zset类型时需要满足zset类型元素个数小于zset-max-ziplist-entries;
zset通过用户额外提供一个评分score的参数来为集合中的成员进行排序,并且是插入有序;
zset数据类型中成员及评分都是唯一不可重复的;(X错误)
135、redis中set是无序不可重复的;
136、redis应用场景,正确的是:
redis作为计算工具统计PV|UV等数据;
作为中间件广泛应用于分布式缓存;
redis可实现分布式锁;
redis作为数据库实现海量数据的存储;(X错误)
137、java进程,会为它分配内存,内存的一部分用于创建堆空间,当程序中创建对象的时候,就从堆空间中分配内存;
138、栈具有后进选出的特征;
139、下列哪种情况是造成服务器电源故障的可能原因:灰尘较大;
140、视图是一个虚表,视图的构造基于基本表或视图;
可以像查询表一样来查询视图;
视图定义包含limit子句时才能设置排序规则;
被修改数据的视图只能是一个基表的列;(X)
141、当创建了新分区,分区上线时,要执行leader选举,选举策略为offlinepartition leader选举;
142、redis集群的节点通信机制,正确的是:
集群端口用于节点之间的通信及连接客户端;
集群端口的端口号是普通端口的端口号+10000,数值可通过配置文件修改;
数据节点负责存储数据,非数据节点提供了两个tcp端口进行通信;
普通端口用于为客户端提供服务以及节点间数据迁移;(X错误)
143、PK被强制定义成not null或unique;
144、redis一个string类型的value最大可存储512M;
list类型的元素个数最多为2^32-1个;
set类型的元素个数最多为2^32-1个;
hash类型键值对个数最多为2^32-1个;
145、kafka是由apache软件基金会开发的开源平台,其开发语言是java和scala;
146、在kafka的ack机制,哪个ack参数会导致数据重复问题:-1.0;
147、视图优点:
简化查询语句;
提高安全性;
实现了逻辑数据独立性;
148、如果查看某个应用下所有服务器近一周的资源使用情况,通过星辰系统服务器监控模块查看;
149、声明合法的是,abstract final double hyperbolicCosine();
150、ElasticSearch支持动态变更数据类型;(X错误)
151、服务器主板CMOS电池故障可能会导致:时间日期漂移|加电自检报错;
152、Spring的AOP动态代理机制都有:JDK动态代理、CGLib库;
153、vue为v-on提供了事件修饰符,.prevent是防止执行预设行为的修饰符;
154、在安装软件时,哪一步需要root权限,make install;
155、DBA需要对数据库进行备份,一般会选用的方式有:完整备份、完整+增量;
156、关于“表1 left join 表2”的说法:都不正确
连接结果中只会保留表2中符合连接条件的记录;(X)
left join可用left outer join代替;(X)
连接结果会保留所有表1中的所有记录;(X)
157、多选,关于groupby,正确的是:
select sum(sales) from store_information groupby sales;
select store_name, price, sum(sales) from store_information groupby store_name, price;
select store_name, sum(sales) from store_information groupby store_name;
158、select insert('welcome', 3, 4, 'HA');的执行结果为weHAe;
159、Which two methods accurately monitor the size of your total database size over time?
monitoring datadir size in the operating system
monitoring the information_schema.TABLES table
160、通过执行redis命令搭建集群的说法,正确的是集群中指定主从关系使用cluster replicate命令;
161、Elasticsearch字符串默认的数据类型为,text|keyword;
text,会分词,然后进行索引,用于全文搜索,支持模糊、精确查询,不支持聚合;
keyword,不进行分词,直接索引,用于关键词搜索,支持模糊、精确查询,支持聚合;
如果不指定类型,es字符串将默认被同时映射成text和keyword类型;
162、关于kafka消费者消费方式的叙述:
消费者采用pull模式从broker中读取数据;
如果kafka没有数据,pull模式可能会使消费者陷入循环,返回空数据;
消费者消息发送速率是由broker决定的;
push模式可以适应消费速率不同的消费者;(X)
163、若需要定义一个类域或类方法,应用使用哪种修饰符,private;
164、哪个命令用来显示系统中各个分区中inode的使用情况,df -iB;
165、java程序中的起始类名必须与存放该类的文件名相同;
166、redis6.0版本后支持多线程执行命令(X);
redis6.0版本中的操作命令,flushall删除所有数据库的所有key;
167、sql语句,判断某个字段是不是null,用is null和is not null,不能用<> null;
168、声明游标用,declare cursor;
169、哪个不是String类的方法,girth()周长,而length()|toString()|hashCode()是;
170、关于redis的RDB持久化策略:
执行bgsave命令时要执行fork操作创建子进程;
RDB持久化是将当前进程数据以生成快照的方式保存到硬盘的过程;
默认的持久化机制是RDB;
RDB持久化模式可以做到实时的持久化;(X)
171、fileinputstream对于inputstream使用什么设计模式,装饰器模式;
172、redis中RDB文件的说法:
RDB文件格式中的check_sum字段数值用来在载入时判断文件是否损坏;
173、服务器出现报错后,前面板BRD上方亮起黄灯,是主板报错;
174、java的字符类型采用的是unicode编码方案,每个unicode码占用32个bit;
175、哪些情况下会发生针对该列创建了索引但是在查询的时候并没有使用:
列参与了数学运算或函数;
使用不等于查询;
当mysql分析全表扫描比使用索引快的时候;
在字符串like左边是通配符;
176、String类所定义的对象是用于存放长度固定的字符串,StringBuffer类所定义的对象是用于存放变动的字符串;
177、redis优点:
读写性能优异;
数据结构丰富;
支持事务;
支持数据持久化;
178、oracle表空间中,哪个表空间是运行一个数据库必须的一个表空间,system;
179、rebalance分配策略属于kafka消费者分区分配策略;(X错误)
180、关于runnable和thread的描述:
JVM的垃圾回收线程是守护线程;
thread类可通过interrupt()方法强制终止线程;
两者均有start()方法,用于启动一个线程;
thread类实现了runnable接口;
181、CacheConcurrencyStrategy的缓存方式:transactional|read_only|none,而nonstrict_read_write不是;
182、rocketmq生产环境,os为linux,哪个配置不推荐,autoCreateTopicEnable=true,另推荐的有useEpollNativeSelector=true|slaveReadEnable=true|autoCreateSubscriptinotallow=true;
183、zabbix_server默认服务端口是10051;
184、System.out.printlnm('5'+2)的输出结果应该是52;
185、下列输出结果是:10;
int a=0;
while (a<5) {
switch(a) {
case 0:
case 3:
a = a +2;
case 1:
case 2:
a = a+3;
default:
a = a+5;
}
}
System.out.rpint(a)
186、ElasticSearch写入可以从哪些方面调优:
写入前副本数设置为0;
写入前关闭refresh_interval设置为-1,禁用刷新机制;
写入过程中,采取bulk批量写入;
尽量使用应用生成的id;(X)
187、Controller给Broker发送的请求不包括:ActiveControllerCount,包括的有StopReplicaRequest|UpdateMetadataRequest|LeaderAndIsrRequest;
188、当Kafka中日志片段大小达到1G时,当前日志片段会被关闭;
189、哪个参数不影响kafka重平衡:message.max.bytes,影响的有session.timeout.ms|max.poll.interval.ms|heartbeat.interval.ms;
190、多选,tomcat的Container内部包含的子容器有:
Context,代表一个应用程序;
Wrapper,Wrapper封装Servlet;
Host,代表一个站点;
Engine,引擎;
191、在命令行容器中,可以作为结尾分隔符的有:;分号|\g|\G;
192、decimal是(可变精度浮点值)数据类型;
193、两个对象的hashCode()相同,则equals()也一定为true(X);
194、以下代码输出结果是:CB,CB;
public static void main(String[] args)) {
StringBuffer a = new StringBuffer('C');
StringBuffer b= new StringBuffer('B');
operator(a, b);
System.out.println(a +',' + b);
}
public static void operator(StringBuffer x, StringBuffer y) {
x = x.append(y);
y = x;
}
195、关于redis中事务和mysql中事务的区别,说法:
redis实现事务基于commands队列,mysql实现事务基于undo|redo日志;
redis不支持事务回滚,mysql支持事务回滚;
redis以multi事务的开始,以exec执行事务的commands队列,mysql以begin开启一个事务,以commit提交事务;
redis默认开启事务,mysql默认不开启事务;(X)
196、from命令属于DQL;
197、现有一日志文件,内含6条消息,第一消息的offset为0,最后一条消息的offset为5,设日志文件的HW(high watermark)为4,下面哪个消息对消费者而言是不可见的:4;
198、类加载的全过程是:加载、验证、准备、解析、初始化;
199、在全文搜索的函数中,用于指定被搜索的列是:match();
200、多选,用于刷新权限的是:
flush privileges;
mysqladmin -uroot -p reload
mysqladmin -uroot -p flush-privileges
201、多选,RocketMQ支持功能:
延迟发送;
业务解耦;
分布式高可用;
流量削峰;
202、redis集群的作用:
实现故障的自动转移;
突破了单机内存大小限制;
提高响应能力;
实现数据的自动备份;(X)
203、Dubbo默认使用Netty BIO框架;
204、RocketMQ中哪个角色承担路由注册的角色:nameserver;
205、在kafka3.2+之后,正式移除了对zookeeper的依赖;
206、java反射用到的核心类有:Field|Constructor|Class|Method;
207、Springboot中,哪个配置文件优先级最高,application.properties;
208、数据库信息的运行安全采取的主措施有:
应急;
风险分析;
备份与恢复;
审计跟踪;
209、redis中geospatial数据类型的操作指令:
geopos用于获取当前定位;
geohash用于返回一个或多个位置元素的geohash表示;
georadiusmember用于找出们于指定元素范围内的其他元素;
georadius用于找出指定元素半径范围内的其他元素;(X)
210、RestController注解是@Controller和@ResponseBody的合集,表示这是个控制器bean,并且是将函数的返回值直接填入http响应体中,是rest风格的控制器;
211、redis哨兵,描述:
哨兵会不断地检查主节点和从节点是否正常工作;
当主节点不能正常工作时,哨兵实现主节点的自动故障转移;
哨兵可将故障转移的结果发送给客户端;
哨兵可以将数据分散到多个节点;(X)
212、select * from city limit 5,10;描述获取第6条到第15条记录;
213、原生类中的数据类型均可任意转换(X);
214、不能用来修饰Interface的有:protected|static|private;
215、windows系统 批量更新补丁可采用:火绒杀毒企业版|WSUS;
216、ElasticSearch查询可能从哪些方面调优:
禁用批量terms,成百上千的场景;
设置合理的路由机制;
禁用wildcard;
充分利用倒排索引机制,能keyword类型尽量keyword;
217、mysql安装目录描述:
include目录用于存放一些头文件;
bin目录用于存放一些可执行文件;
lib目录用于存储一系列的库文件;
218、主键说法:
主键是不同表中各记录之间的简单指针;
主键的值对用户而言没有什么意义;
主键的主要作用是将记录和存放在其他表中的数据进行关联;
一个主键是唯一识别一个表的每一记录;
219、消费者通过(反序列化器)把从Kafka中收到的字节数组转换成相应的对象;
220、索引列的基数越大,数据区分度越高,索引的效果越好;
221、关于kafka高级API和低级API的说法:
使用低级API时,原有的kafka策略会失效;
使用高级API时,由kafka的rebalance来控制消费者分配的分区;
使用低级API时,可以自行存储offset;
使用高级API时,offset存储在flink中;(X)
222、服务器cpu使用率达到50%时可考虑申请扩容;
223、线程安全的map都有,HashTable|SynchronizedMap|ConcurrentHashMap;
224、What three are correct statements about MySQL backups?
They are used to prevent data corruption.
They are used to set up a replication slave.
They are used to recover data.
225、要得到最后一句select查询到的总行数,可以使用的函数是found_rows;
226、redis事务的说法:
redis的事务保证了一致性和隔离性,但并不保证原子性和持久性;
227、Innodb的自动增长字段值为1和2,那么删除2后,重启服务器,再次插入记录,自动增长字段的值为2;
228、哨兵节点支持的命令:
sentinel master mymaster用于获取监控的主节点mymaster的详细信息;
229、以下字符集中支持中文的是,gbk|big5|utf8;
中文字符集编码:unicode|gb2312|cp936|GBK|GB18030;
230、Multiversion Concurrency Control(MVCC) enables what type of backup? Hot;
231、MQ的集群消费和广播消费描述:
集群消费模式适用于消费端集群化部署,每条消息只需要被处理一次的场景;
广播模式适用于消费端集群化部署,每条消息需要被集群下的每个消费者处理的场景;
两者消息都会被不同节点重复消费;(X)
两者都支持顺序消息;(X)
232、redis主从复制缺陷:
写操作无法负载均衡;
故障恢复无法自动化;
存储能力受单机限制;
无法实现数据冗余;(X)
233、sentinel流控工具具备:流量控制|流量监控|服务降级,不具备请求合并;
234、结构化程序设计所规定的三种基本控制结构是:顺序|选择|循环;
235、临时关闭事件e_test,alter event e_test disable;;
236、消费者出现活锁问题时应该,增加max.poll.interval.ms相关参数;
237、kibana http默认端口5601;
238、管理员遇到服务器安全性问题,发现有服务器收到病毒感染,哪种方式可避免服务器被干扰,执行补丁更新程序;
239、官方推荐的redis支持java客户端,redisson;
240、java接口与接口之间可通过extends实现继承;
241、用压力测试测出机器写入速度20M/s一台,峰值的业务数据的速度是100M/s,副本数为6,预估需要部署kafka机器数量为:13台;
242、由继承性可知,程序中子类拥有的成员数目一定大于等于父类拥有的成员数目;(X)
243、nginx proxy_read_timeout默认值是60s;
244、cron表达式从左到右每个占位的含义是“秒分时日月周年”;
245、cat支持的监控模型有:transaction|heartbeat|metric|event;
246、哪个函数是public void a Method(){...}的重载函数:public int a Method(int m){...};
247、