Redis数据类型 通用操作 ## 判断key是否存在127.0.0.1:6379 EXISTS name(integer) 1127.0.0.1:6379 EXISTS name1(integer) 0## 修改key名字127.0.0.1:6379 RENAME name name1OK## 查看指定key的数据类型127.0.0.1:6379 TYPE name1
Redis数据类型
通用操作
## 判断key是否存在 127.0.0.1:6379> EXISTS name (integer) 1 127.0.0.1:6379> EXISTS name1 (integer) 0 ## 修改key名字 127.0.0.1:6379> RENAME name name1 OK ## 查看指定key的数据类型 127.0.0.1:6379> TYPE name1 string ## 删除key 127.0.0.1:6379> del name1 (integer) 1 ## 查看一个key的生存时间 127.0.0.1:6379[15]> ttl age (integer) -1 ## 以秒为单位设置生存时间 127.0.0.1:6379[15]> ttl age (integer) 95 ## 以毫秒为单位设置生存时间 127.0.0.1:6379[15]> PEXPIRE age 4000 ## 取消生存时间 127.0.0.1:6379[15]> PERSIST age字符串类型操作(strings)
增
## 设置key 127.0.0.1:6379> set name www ## 设置多个key 127.0.0.1:6379> MSET name www name1 wsh name2 qwe ## 查看多个key值 127.0.0.1:6379> MGET name name1 name2 1) "www" 2) "wsh" 3) "qwe" ## 先获取一个key的值,再设置或者修改key值 127.0.0.1:6379> getset xxx 123 (nil) 127.0.0.1:6379> get xxx "123" ## 设置key同时设置生存时间(秒为单位) 127.0.0.1:6379> set book hongloumeng ex 100 OK ## 设置key同时设置生存时间(毫秒为单位) 127.0.0.1:6379> set book hongloumeng px 100 OK ## 字符串自增 127.0.0.1:6379> incr zan (integer) 1 ## 指定增加数量 127.0.0.1:6379> incrby fans 10000 (integer) 10023 ## 自减 127.0.0.1:6379> decr fans (integer) 10012 ## 执行自减数量 127.0.0.1:6379> decrby fans 1000 (integer) 9012 ## 按照小数自增 127.0.0.1:6379> incrbyfloat zls 0.1 "1.4"删
127.0.0.1:6379> del rty (integer) 1改
## 字符串追加 127.0.0.1:6379> APPEND name hhh (integer) 6 127.0.0.1:6379> get name "wwwhhh" ## 修改第N个字符 127.0.0.1:6379> SETRANGE name 5 L 127.0.0.1:6379> get name "wwwhhL"查
## 查看一个key 127.0.0.1:6379> get name1 "wsh" ## 查看多个key 127.0.0.1:6379> MGET name name1 name2 1) "wwwhhL" 2) "wsh" 3) "qwe" ## 查看字符串的长度 127.0.0.1:6379> STRLEN name (integer) 6 127.0.0.1:6379> STRLEN name1 (integer) 3 ## 查看生存时间 127.0.0.1:6379> ttl name1 // 秒 (integer) 93 127.0.0.1:6379> pttl name1 // 毫秒 (integer) 91417 # 字符串截取 127.0.0.1:6379> GETRANGE name 0 3 "wwwh"hash类型(字典类型)
应用场景:
存储部分变更的数据,如用户信息,商品信息等。 最接近表结构的一种类型。
# 创建key hset keyname field value hset student_id_1 name zls hset student_id_1 name zls age 18 gender m hmset student_id_1 name zls age 18 gender m # 查询 hget keyname field hget student_id_1 name hgetall keyname hgetall student_id_1 hmget student_id_1 name age # 删除 127.0.0.1:6379> hdel student_id_1 age gender (integer) 2 127.0.0.1:6379> hgetall student_id_1 127.0.0.1:6379> del student_id_1 # 改 127.0.0.1:6379> hset student_id_1 name zls age 18 gender m (integer) 3 127.0.0.1:6379> hgetall student_id_1 1) "fans" 2) "8" 3) "zan" 4) "9" 5) "name" 6) "zls" 7) "age" 8) "18" 9) "gender" 10) "m"list类型(列表类型)
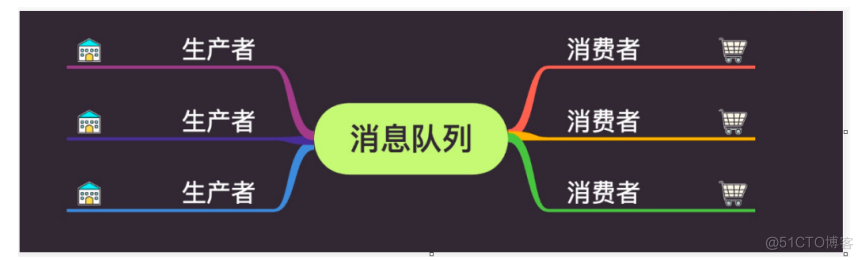
消息队列
在生活中,其实有很多的例子,都类似消息队列。
比如:工厂生产出来的面包,交给超市,商场来出售,客户通过超市,商场来买面包,客户不会针对某一个工厂去选择,只管从超市买出来,工厂也不会管是哪一个客户买了面包,只管生产出来之后,交给超市,商场来处理。
消息队列(Message Queue)是一种应用间的通信方式,消息发送后可以立即返回,有消息系统来确保信息的可靠专递,消息生产者只管把消息发布到MQ中而不管谁来取,消息消费者只管从MQ中取消息而不管谁发布的,这样发布者和使用者都不用知道对方的存在。
生产者 -> 消息队列 -> 消费者 kafka
为什么使用消息队列
首先,我们可以知道,消息队列是一种异步的工作机制,比如说日志收集系统,为了避免数据在传输过程中丢失,还有订单系统,下单后,会生成对应的单据,库存的扣减,消费信息的发送,一个下单,产生这么多的消息,都是通过一个操作的触发,然后将其他的消息放入消息队列中,依次产生。再就是很多网站的,秒杀活动之类的,前多少名用户会便宜,都是通过消息队列来实现的。
这些例子,都是通过消息队列,来实现,业务的解耦,最终数据的一致性,广播,错峰流控等等,从而完成业务的逻辑。
消息队列的产品
- RabbitMQ(最早金融公司,OpenStack)
- ZeroMQ(SaltStack)
- RocketMQ
- Kafka(Java)
- Redis(消息队列)
set(集合类型)
组1:1 2 3 4 5 组2: 1 3 5 7 9 交集:1 3 5 并集:1 2 3 4 5 7 9 差集:2 4 7 9 # 创建集合 127.0.0.1:6379> sadd zls_fans wyk hl (integer) 2 127.0.0.1:6379> sadd tly_fans mls gaofei wyk (integer) 3 # 查 ## 查询集合中的元素,有就返回1 没有就返回0 127.0.0.1:6379> sismember zls_fans hl (integer) 1 127.0.0.1:6379> sismember zls_fans cls (integer) 0 ## 查询集合中的所有元素 127.0.0.1:6379> SMEMBERS zls_fans 1) "hl" 2) "wyk" ## 查询集合中元素数量 127.0.0.1:6379> scard zls_fans (integer) 2 127.0.0.1:6379> scard tly_fans (integer) 3 ## 比较集合中的差异,取前面集合的不同之处 127.0.0.1:6379> sdiff hl_fans tly_fans zls_fans 1) "xiaoxuesheng" 127.0.0.1:6379> SMEMBERS hl_fans 1) "hl" 2) "mls" 3) "xiaoxuesheng" 127.0.0.1:6379> SMEMBERS tly_fans 1) "wyk" 2) "mls" 3) "gaofei" 127.0.0.1:6379> SMEMBERS zls_fans 1) "hl" 2) "wyk" 127.0.0.1:6379> sdiff hl_fans tly_fans 1) "hl" 2) "xiaoxuesheng" 127.0.0.1:6379> sdiff tly_fans hl_fans 1) "wyk" 2) "gaofei" 127.0.0.1:6379> sdiff tly_fans hl_fans zls_fans 1) "gaofei" ## 比较之后的差异,存放到新的集合中 127.0.0.1:6379> sdiffstore resault tly_fans hl_fans (integer) 2 127.0.0.1:6379> KEYS * 1) "hl_fans" 2) "resault" 3) "name2" 4) "tly_fans" 5) "name1" 6) "wechat" 7) "zls_fans" 127.0.0.1:6379> type resault set 127.0.0.1:6379> scard resault (integer) 2 127.0.0.1:6379> 127.0.0.1:6379> SMEMBERS resault 1) "wyk" 2) "gaofei" ## 交集(共同好友) 127.0.0.1:6379> SMEMBERS hl_fans 1) "hl" 2) "mls" 3) "xiaoxuesheng" 127.0.0.1:6379> SMEMBERS zls_fans 1) "hl" 2) "wyk" 127.0.0.1:6379> sinter hl_fans zls_fans 1) "hl" ## 并集 127.0.0.1:6379> sunion hl_fans zls_fans 1) "hl" 2) "wyk" 3) "mls" 4) "xiaoxuesheng" ## 将交集存入新集合 127.0.0.1:6379> sinterstore new_set hl_fans zls_fans (integer) 1 127.0.0.1:6379> SMEMBERS new_set 1) "hl" ## 将并集存入新集合 127.0.0.1:6379> sunionstore new_set2 hl_fans zls_fans (integer) 4 127.0.0.1:6379> SMEMBERS new_set2 1) "hl" 2) "wyk" 3) "mls" 4) "xiaoxuesheng" ## 取随机值 127.0.0.1:6379> srandmember zls_fans "mls" ## 改 ## 将集合的元素存入另一个集合 SMOVE 127.0.0.1:6379> SMEMBERS hl_fans 1) "hl" 2) "mls" 3) "xiaoxuesheng" 127.0.0.1:6379> SMEMBERS zls_fans 1) "hl" 2) "wyk" 127.0.0.1:6379> SMOVE hl_fans zls_fans mls (integer) 1 127.0.0.1:6379> SMEMBERS hl_fans 1) "hl" 2) "xiaoxuesheng" 127.0.0.1:6379> SMEMBERS zls_fans 1) "hl" 2) "wyk" 3) "mls" ## 删 127.0.0.1:6379> spop hl_fans "hl" 127.0.0.1:6379> SMEMBERS hl_fans 1) "xiaoxuesheng" ## 删除指定元素,返回删除元素的个数 127.0.0.1:6379> srem zls_fans hl (integer) 1 127.0.0.1:6379> SMEMBERS zls_fans 1) "wyk" 2) "mls" 127.0.0.1:6379> srem zls_fans xxx (integer) 0 #### 无序的 127.0.0.1:6379> sadd zls_fans 111 222 333 444 555 666 (integer) 6 127.0.0.1:6379> SMEMBERS zls_fans 1) "abc" 2) "111" 3) "mls" 4) "123" 5) "def" 6) "333" 7) "222" 8) "456" 9) "444" 10) "555" 11) "666" 12) "wyk"sorted-set(有序集合)
应用场景:
排行榜应用,取TOP N操作 这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序,这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可。
# 增 127.0.0.1:6379> zadd myzset 1 "one" 2 "two" 3 "three" # 查 ## 只查询成员 127.0.0.1:6379> zrange chengji 0 -1 1) "wyk" 2) "hl" 3) "zls" ## 查询成员和分数 127.0.0.1:6379> zrange chengji 0 -1 WITHSCORES 1) "wyk" 2) "1" 3) "hl" 4) "38" 5) "zls" 6) "100" ## 查询成员的索引 127.0.0.1:6379> zrank chengji wyk (integer) 0 127.0.0.1:6379> zrank chengji zls (integer) 2 ## 查询成员数量 127.0.0.1:6379> zcard chengji (integer) 3 ## 查看分数是指定范围的成员个数 30 <= score <=40 127.0.0.1:6379> zcount chengji 30 40 (integer) 1 127.0.0.1:6379> zcount chengji 30 101 (integer) 2 ## 获取指定成员分数 127.0.0.1:6379> ZSCORE chengji wyk "1" 127.0.0.1:6379> ZSCORE chengji zls "100" ## 查看分数是指定范围的成员名 127.0.0.1:6379> zcount chengji 30 40 (integer) 1 127.0.0.1:6379> zrangebyscore chengji 30 40 1) "hl" ## +inf表示最后一个成员,-inf表示第一个成员,意思是:检索所有数据,然后从下标为2的数据开始再往后输出3:(N-1)个数据 127.0.0.1:6379> zrangebyscore chengji -inf +inf limit 2 3 1) "hjx" 2) "xwq" 3) "zls" 127.0.0.1:6379> zrangebyscore chengji -inf +inf limit 2 2 1) "hjx" 2) "xwq" 127.0.0.1:6379> zrangebyscore chengji -inf +inf limit 2 1 1) "hjx" 127.0.0.1:6379> zrangebyscore chengji -inf +inf limit 2 4 1) "hjx" 2) "xwq" 3) "zls" # 删 ## 删除指定分数范围的成员,并返回删除的个数 127.0.0.1:6379> zrangebyscore chengji 30 40 1) "hl" 127.0.0.1:6379> zremrangebyscore chengji 30 40 (integer) 1 ## 按指定索引范围删除,返回删除个数 127.0.0.1:6379> zremrangebyrank chengji 0 2 (integer) 3 ## 倒序排名 127.0.0.1:6379> zrevrange chengji 0 -1 WITHSCORES 1) "zls" 2) "100" 3) "hjx" 4) "60" 5) "xwq" 6) "50" 7) "hl" 8) "38" 9) "wyk" 10) "1" ## 按照分数段查找成员,并倒序排序 127.0.0.1:6379> zrevrangebyscore chengji 101 30 WITHSCORES 1) "zls" 2) "100" 3) "hjx" 4) "60" 5) "xwq" 6) "50" 7) "hl" 8) "38" ## 按照分数查找成员,并倒序排序,然后按照索引号,取出指定的数据 127.0.0.1:6379> zrevrangebyscore chengji 101 30 WITHSCORES limit 1 2 1) "hjx" 2) "60" 3) "xwq" 4) "50" 127.0.0.1:6379> zrevrangebyscore chengji 101 30 WITHSCORES limit 1 3 1) "hjx" 2) "60" 3) "xwq" 4) "50" 5) "hl" 6) "38"