芯片大家都不陌生。在当今疫情下,显卡,车机的芯片产量锐减影响了不少人的购物需求(反正你也买不到),也让不少人重新认识了半导体行业。闲来无事,我们可以获取一下T网站的芯片库存和芯片信息。
一、列表页请求分析
进入页面,就能看到我们需求的信息了。
但是,在页面请求完成之前,有一点点不对劲,就是页面的各个部份请求的速度是不一样的:
所以啊,需要的数据,大概率不是简单的get请求,所以要进一步去看,特意在开发者模式—Fetch/XHR选项卡中有一个请求,返回值正好是我们需要的内容:
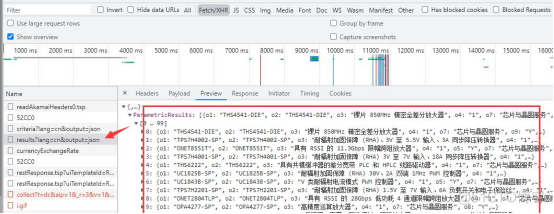
这一条链接返回了所有的数据,无需翻页,下面开始请求链接。
二、列表页请求
根据上面的链接,直接get请求,分析json即可,上代码:
2. url = "https://www.xx.com.cn/selectiontool/paramdata/family/3658/results?lang=cn&output=json"
3. headers = {
4. 'authority': 'www.xx.com.cn',
5. "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
6. "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
7. }
8. res = getRes(url,headers,'','','GET')//自己写的请求方法
9. nodes = res.json()['ParametricResults']
10. for node in nodes:
11. data = {}
12. data["itemName"] = node["o3"] #名称
13. data["inventory"] = node["p3318"] #库存
14. data["price"] = node["p1130"]['multipair1']['l'] #价格
15. data["infoUrl"] = f"https://www.xx.com.cn/product/cn/{node['o1']}"#详情URL
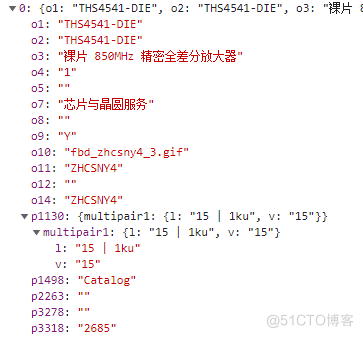
分析上面的json,可知 o3 是商品名,p3318是库存,p1130里面的内容有一个带单位的价格,o1是型号,可凑出详情链接,下面是请求结果:

三、详情页分析
终于拿到详情页链接了,该获取剩下的内容了。
打开开发者模式,没有额外的请求,只有一个包含内容的get请求。
那直接请求不就得了,上代码:
1. def getItemInfo(url):2. logger.info(f'正在请求详情url-{url}')
3. headers = {
4. 'authority': 'www.xx.com.cn',
5. 'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
6. 'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
7. 'referer':'https://www.xx.com.cn/product/cn/THS4541-DIE',
8.
9. }
10. res = getRes(url, headers,'', '', 'GET')//自己写的请求方法
11. content = res.content.decode('utf-8')
但是发现,请求的详情页,跟开发者模式的预览怎么不太一样?

我这里的第一反应就觉得,完了,这个需要cookie。
继续分析,清屏开发者模式,清除cookie,再次访问详情链接,在All选项卡中,可以发现:

本以为该请求一次的详情页链接请求了两次,两次中间还有一个xhr请求。
预览第一次请求,可以发现跟刚才本地请求的内容相差无几:
所以问题出在第二次的请求,进一步分析:
查看第二次的get请求,与第一次的请求相差了一堆cookie

简化cookie,发现这些cookie最关键的参数是ak_bmsc这一部分,而这一部分参数,就来自上一个xhr请求中的响应头set-cookie中:

分析这个xhr请求,请求链接
这是个post请求,先从payload参数下手:

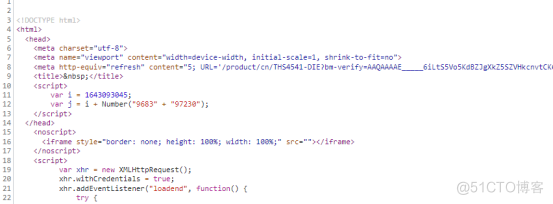
这个bm-verify参数,是不是有些眼熟?这就是第一次的get请求返回的内容吗,下面还有一个pow参数:

“pow”:j,这个j参数就在上面,声明了i和两个拼接的数字字符串转成int之后相加之后的结果:
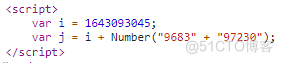
通过这一系列请求,返回了最终get请求所需要的cookie,讲的比较琐碎,上代码:
1. #详情需要cookie2. def getVerify(url):
3. infourl = url
4. headers = {
5. 'authority': 'www.xx.com.cn',
6. "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
7. "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
8. }
9. proxies = getApiIp()//取代理
10. if proxies:
11. #无cookie访问详情页拿参数bm-verify,pow
12. res = getRes(infourl,headers,proxies,'','GET')
13. if res:
14. #拿第一次请求的ak_bmsc
15. cookie = re.findall("ak_bmsc=.*?;",res.headers['set-cookie'])[0]
16. #拿bm-verify
17. verifys = re.findall('"bm-verify": "(.*?)"', res.text)[0]
18. #合并字符串转int相加取pow
19. a = re.findall('var i = (\d+);',res.text)[0]
20. b = re.findall('Number\("(.*?)"\);',res.text)[0]
21. b = int(b.replace('" + "',''))
22. pow = int(a)+b
23. post_data = {
24. 'bm-verify': verifys,
25. 'pow':pow
26. }
27. #转json
28. post_data = json.dumps(post_data)
29. if verifys:
30. logger.info('第一次参数获取完毕')
31. return post_data,proxies,cookie
32. else:
33. print('verify获取异常')
34. else:
35. print('verify请求出错')
36.
37. # 第二次带参数访问验证链接
38. def getCookie(url):
39. post_headers = {
40. "authority": "www.xx.com.cn",
41. "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
42. "accept": "*/*",
43. "content-type": "application/json",
44. "origin": "https://www.xx.com.cn",
45. "referer":url,
46. }
47. post_data,proxies,c_cookie = getVerify(url)
48. post_headers['Cookie'] = c_cookie
49. posturl = "https://www.xx.com.cn/_sec/verify?provider=interstitial"
50. check = getRes(posturl,post_headers,proxies,post_data,'POST')
51. if check:
52. #从请求头拿到ak_bmsc cookie
53. cookie = check.headers['Set-Cookie']
54. cookie = re.findall("ak_bmsc=.*?;",cookie)[0]
55. if cookie:
56. logger.info('Cookie获取完毕')
57. return cookie,proxies
58. else:
59. print('cookie获取异常')
60. else:
61. print('cookie请求出错')
简单的概括一下详情页的请求流程:
第一次请求,取得所需参数bm-verify,pow,cookie,提供给下一次的post请求(getVerify方法)
第二次请求,根据已知条件进行post请求,并获取响应头cookie的ak_bmsc(getCookie)
切记,在整个获取cookie的三次请求过程中,第二、三两次请求都需要伴随着上一次请求的ak_bmsc作为cookie传递,第二次请求需要第一次的ak_bmsc,最终请求需要第二次的ak_bmsc。
四、详情页请求
1. def getItemInfo(url):2. logger.info(f'正在请求详情url-{url}')
3. cookie,proxies = getCookie(url)
4. headers = {
5. 'authority': 'www.xx.com.cn',
6. 'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
7. 'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
8. 'referer':'https://www.xx.com.cn/product/cn/THS4541-DIE',
9. 'cookie':cookie
10. }
11. res = getRes(url, headers,proxies, '', 'GET')
12. content = res.content.decode('utf-8')
13. print(content)
14. exit()
15. sel = Selector(text=content)
16. Parameters = sel.xpath('//ti-tab-panel[@tab-title="参数"]/ti-view-more/div').extract_first()
17. Features = sel.xpath('//ti-tab-panel[@tab-title="特性"]/ti-view-more/div').extract_first()
18. Description = sel.xpath('//ti-tab-panel[@tab-title="描述"]/ti-view-more').extract_first()
19. if Parameters and Features and Description:
20. return Parameters,Features,Description
通过上一步cookie的获取,带着cookie再次访问详情链接,就可以顺利的获取内容并可以使用xpath进行解析,获取需要的内容。
五、代理设置
T网站详情页带cookie请求有100多次,如果用本地代理一直去请求,会有IP封锁的可能性出现,导致无法正常获取。所以,需要高效请求的话,优质稳定的代理IP必不可少,我这里使用的ipidea代理请求的T网站,数据很快就访问出来了。
地址:http://www.ipidea.net/ ,首次可以白嫖流量哦。本次使用的api获取,代码如下:
1. # api获取ip2. def getApiIp():
3. # 获取且仅获取一个ip
4. api_url = 'http://tiqu.ipidea.io:81/abroad?num=1&type=2&lb=1&sb=0&flow=1®ions=&port=1'
5. res = requests.get(api_url, timeout=5)
6. try:
7. if res.status_code == 200:
8. api_data = res.json()['data'][0]
9. proxies = {
10. 'http': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
11. 'https': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
12. }
13. print(proxies)
14. return proxies
15. else:
16. print('获取失败')
17. except:
18. print('获取失败')
六、代码汇总
1. # coding=utf-82. import requests
3. from scrapy import Selector
4. import re
5. import json
6. from loguru import logger
7.
8. # api获取ip
9. def getApiIp():
10. # 获取且仅获取一个ip
11. api_url = '获取代理地址'
12. res = requests.get(api_url, timeout=5)
13. try:
14. if res.status_code == 200:
15. api_data = res.json()['data'][0]
16. proxies = {
17. 'http': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
18. 'https': 'http://{}:{}'.format(api_data['ip'], api_data['port']),
19. }
20. print(proxies)
21. return proxies
22. else:
23. print('获取失败')
24. except:
25. print('获取失败')
26.
27. def getItemList():
28. url = "https://www.xx.com.cn/selectiontool/paramdata/family/3658/results?lang=cn&output=json"
29. headers = {
30. 'authority': 'www.xx.com.cn',
31. "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
32. "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
33. }
34. proxies = getApiIp()
35. if proxies:
36. # res = requests.get(url, headers=headers, proxies=proxies)
37. res = getRes(url,headers,proxies,'','GET')
38. nodes = res.json()['ParametricResults']
39. for node in nodes:
40. data = {}
41. data["itemName"] = node["o3"] #名称
42. data["inventory"] = node["p3318"] #库存
43. data["price"] = node["p1130"]['multipair1']['l'] #价格
44. data["infoUrl"] = f"https://www.ti.com.cn/product/cn/{node['o1']}"#详情URL
45. Parameters, Features, Description = getItemInfo(data["infoUrl"])
46. data['Parameters'] = Parameters
47. data['Features'] = Features
48. data['Description'] = Description
49. print(data)
50.
51. #详情需要cookie
52. def getVerify(url):
53. infourl = url
54. headers = {
55. 'authority': 'www.xx.com.cn',
56. "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
57. "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
58. }
59. proxies = getApiIp()
60. if proxies:
61. #访问详情页拿参数bm-verify,pow
62. res = getRes(infourl,headers,proxies,'','GET')
63. if res:
64. #拿第一次请求的ak_bmsc
65. cookie = re.findall("ak_bmsc=.*?;",res.headers['set-cookie'])[0]
66. #拿bm-verify
67. verifys = re.findall('"bm-verify": "(.*?)"', res.text)[0]
68. #字符串转int相加取pow
69. a = re.findall('var i = (\d+);',res.text)[0]
70. b = re.findall('Number\("(.*?)"\);',res.text)[0]
71. b = int(b.replace('" + "',''))
72. pow = int(a)+b
73. post_data = {
74. 'bm-verify': verifys,
75. 'pow':pow
76. }
77. #转json
78. post_data = json.dumps(post_data)
79. if verifys:
80. logger.info('第一次参数获取完毕')
81. return post_data,proxies,cookie
82. else:
83. print('verify获取异常')
84. else:
85. print('verify请求出错')
86.
87. # 第二次带参数访问验证链接
88. def getCookie(url):
89. post_headers = {
90. "authority": "www.xx.com.cn",
91. "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36",
92. "accept": "*/*",
93. "content-type": "application/json",
94. "origin": "https://www.xx.com.cn",
95. "referer":url,
96. }
97. post_data,proxies,c_cookie = getVerify(url)
98. post_headers['Cookie'] = c_cookie
99. posturl = "https://www.xx.com.cn/_sec/verify?provider=interstitial"
100. check = getRes(posturl,post_headers,proxies,post_data,'POST')
101. if check:
102. #从请求头拿到ak_bmsc cookie
103. cookie = check.headers['Set-Cookie']
104. cookie = re.findall("ak_bmsc=.*?;",cookie)[0]
105. if cookie:
106. logger.info('Cookie获取完毕')
107. return cookie,proxies
108. else:
109. print('cookie获取异常')
110. else:
111. print('cookie请求出错')
112.
113. def getItemInfo(url):
114. logger.info(f'正在请求详情url-{url}')
115. cookie,proxies = getCookie(url)
116. headers = {
117. 'authority': 'www.xx.com.cn',
118. 'accept': "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
119. 'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
120. 'referer':'https://www.xx.com.cn/product/cn/THS4541-DIE',
121. 'cookie':cookie
122. }
123. res = getRes(url, headers,proxies, '', 'GET')
124. content = res.content.decode('utf-8')
125. sel = Selector(text=content)
126. Parameters = sel.xpath('//ti-tab-panel[@tab-title="参数"]/ti-view-more/div').extract_first()
127. Features = sel.xpath('//ti-tab-panel[@tab-title="特性"]/ti-view-more/div').extract_first()
128. Description = sel.xpath('//ti-tab-panel[@tab-title="描述"]/ti-view-more').extract_first()
129. if Parameters and Features and Description:
130. return Parameters,Features,Description
131.
132. #专门发送请求的方法,代理请求三次,三次失败返回错误
133. def getRes(url,headers,proxies,post_data,method):
134. if proxies:
135. for i in range(3):
136. try:
137. # 传代理的post请求
138. if method == 'POST':
139. res = requests.post(url,headers=headers,data=post_data,proxies=proxies)
140. # 传代理的get请求
141. else:
142. res = requests.get(url, headers=headers,proxies=proxies)
143. if res:
144. return res
145. except:
146. print(f'第{i}次请求出错')
147. else:
148. return None
149. else:
150. for i in range(3):
151. proxies = getApiIp()
152. try:
153. # 请求代理的post请求
154. if method == 'POST':
155. res = requests.post(url, headers=headers, data=post_data, proxies=proxies)
156. # 请求代理的get请求
157. else:
158. res = requests.get(url, headers=headers, proxies=proxies)
159. if res:
160. return res
161. except:
162. print(f"第{i}次请求出错")
163. else:
164. return None
165.
166. if __name__ == '__main__':
167. getItemList()

通过上述步骤,已经能获取所需内容。
总结
整个T网站的数据获取,难点就在详情页的cookie,(其实也不是很难,只不过cookie太长比较费眼)理顺了整个请求流程,剩下的就是请求的过程。稳定高效的IP代理会让你事半功倍,通过api获取可变的代理也不易被网站封禁,从而更好地获取数据。简化cookie的时候使用合适的请求工具会更方便,比如postman,burp。
这次的整个流程到此结束,讲的比较啰嗦,若有错误或者更好的方法请大佬指正!