

计算机视觉研究院专栏
作者:Edison_G
在3D目标检测挑战赛中,华为诺亚方舟实验室与HUAWEI Octopus自动驾驶云服务联合团队Noah CV Lab&Octopus,取得了3D detection track第一名。华为汽车是由华为公司生产的新能源智能汽车。自动驾驶中的目标检测怎么做到的呢?

一、简要
在恶劣的驾驶情况下,例如弱/强照明和恶劣天气,雷达通常比相机更稳定。然而,与相机捕捉的RGB图像不同,雷达信号的语义信息很难提取。

于是就有研究者提出了一种深度雷达目标检测网络(RODNet),纯粹利用精心处理的方位频率热图格式的雷达频率数据有效地检测目标。引入了三种不同的基于三维自动编码器的架构来从输入随机映射的每个片段中预测目标置信度分布。最后的检测结果然后使用新的后处理方法来计算,称为基于位置的非极大最大抑制(L-NMS)。

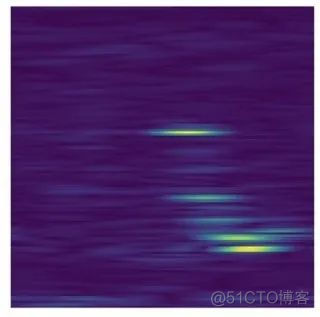

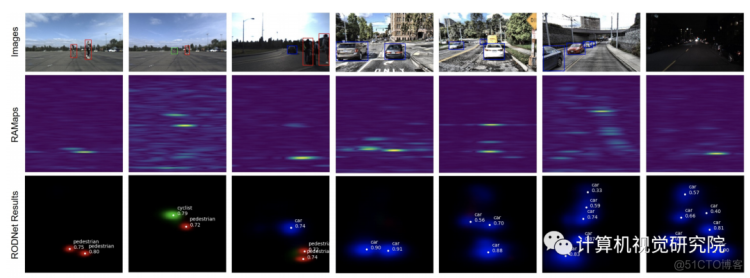
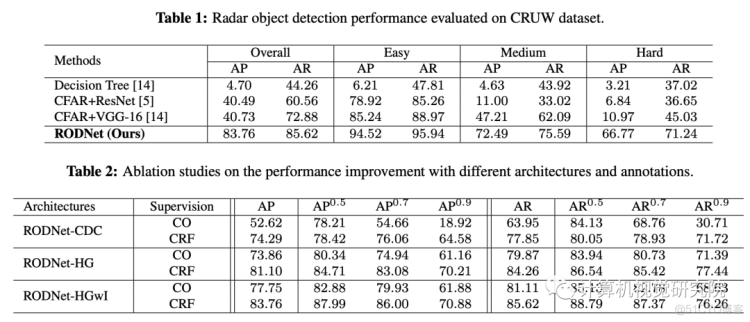
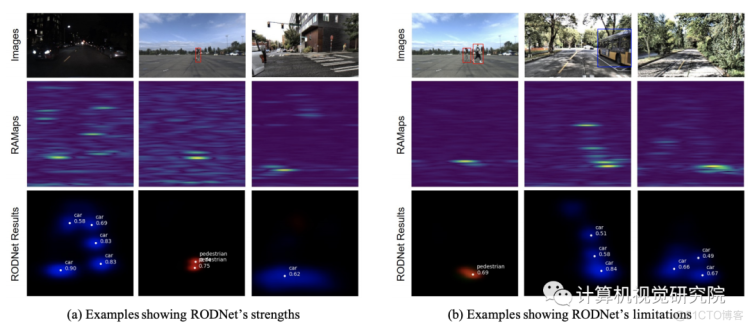
这次,研究者没有使用繁重的人类标记的真实标签(GT),而是使用相机-雷达融合(CRF)策略自动生成的三维定位方法的注释来训练RODNet。为了训练和评估新方法,研究者还构建了一个新的数据集——CRUW,其中包含各种驾驶场景中的同步视频和实时地图。经过详细的实验,RODNet在没有摄像头存在的情况下显示出了良好的目标检测性能。
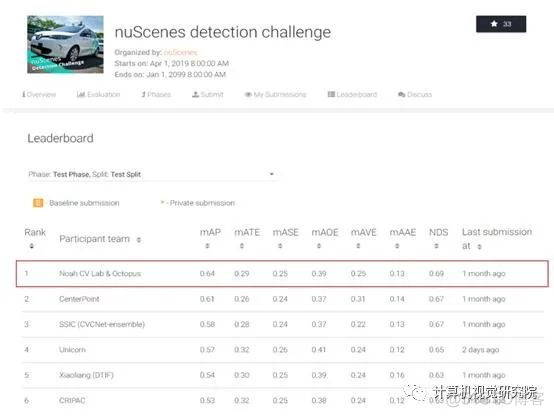
华为比赛
二、背景
2D目标检测在自动驾驶领域存在很多问题,因为自动驾驶的空间首先是在3D层面上的,而且需要使用RGB图像、RGB-D深度图像和激光点云,输出物体类别及在三维空间中的长宽高、旋转角等信息。这一类检测称为3D目标检测。
3D目标检测
随着two-stages的Faster-RCNN和one-stage的Yolo&SSD的出现,2D目标检测达到了空前的高度,各种新的方法不断涌现,但是在无人驾驶、机器人等应用场景下,普通2D检测并不能提供感知环境所需要的全部信息,2D检测仅能提供目标物体在二维图片中的位置和对应类别的置信度,但是在真实的三维世界中,物体都是有三维形状的,大部分应用都需要有目标物体的长宽高还有偏转角等信息。
例如下图中,在自动驾驶场景下,需要从图像中提供目标物体三维大小及旋转角度等指标,在鸟瞰投影的信息对于后续自动驾驶场景中的路径规划和控制具有至关重要的作用。

目前3D目标检测正处于高速发展时期,目前主要是综合利用单目相机、双目相机、多线激光雷达来进行3D目标检测,从目前成本上讲,激光雷达>双目相机>单目相机,从目前的准确率上讲,激光雷达>双目相机>单目相机。但是随着激光雷达的不断产业化发展,成本在不断降低,目前也出现一些使用单目相机加线数较少的激光雷达进行综合使用的技术方案。
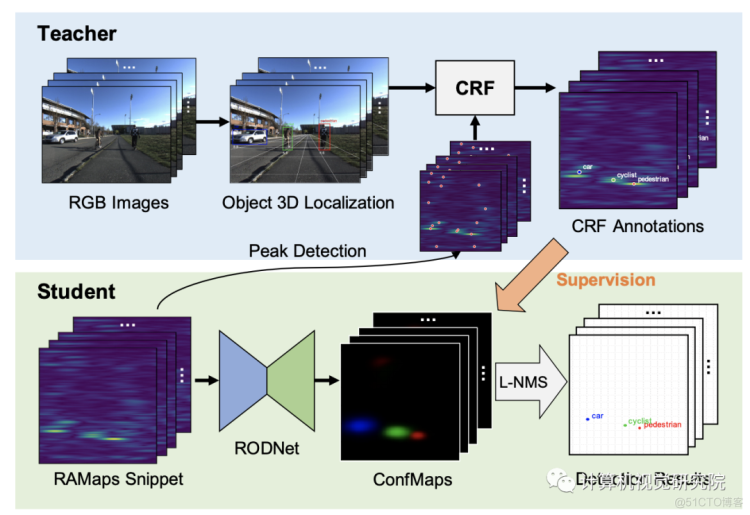
针对RODNet的网络结构,研究者实现了基于[Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. In European conference on computer vision, pages 483–499]和[Mingmin Zhao, Tianhong Li, Mohammad Abu Alsheikh, Yonglong Tian, Hang Zhao, Antonio Torralba, and Dina Katabi. Through-wall human pose estimation using radio signals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7356–7365]的三维卷积自编码器网络。考虑到区分不同目标所需的时间长度不同,在RODNet中提出了灵感来自spatial inception[Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition]的temporal inception卷积层。
三、新框架
RODNet Architectur
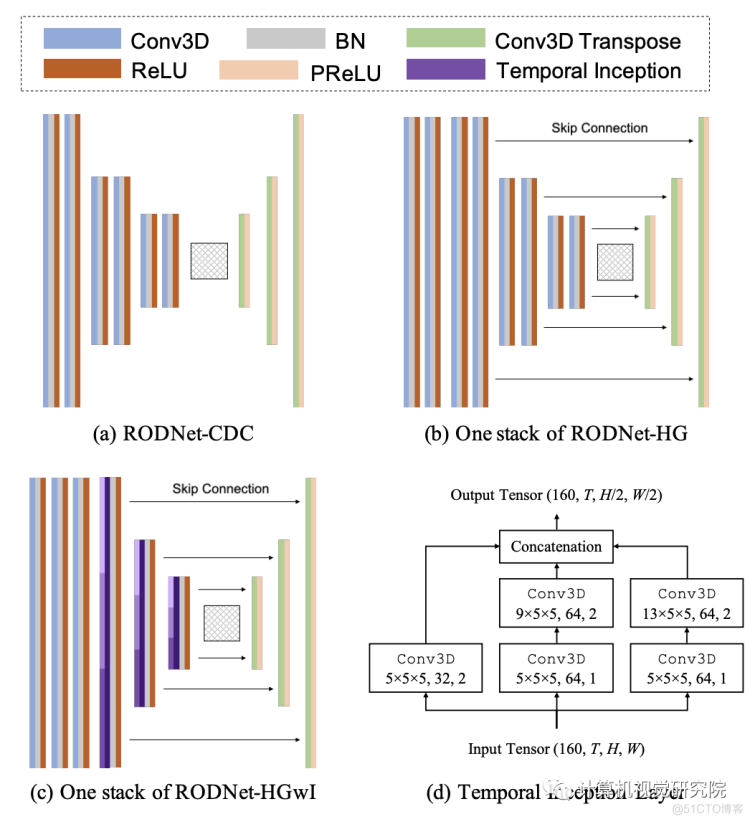
RODNet的三种不同的网络架构如上图所示,分别命名为3D Convolution-Deconvolutio(RODNet-CDC)、 3D stacked hourglas(RODNet-HG)和具有temporal inception的3D stacked hourglas(RODNet-HGwI)。RODNet-CDC是一个浅的3D CNN网络,它挤压时空域的特征,以更好地提取时间信息。至于RODNet-HGwI,用不同 temporal kernel scale(5,9,13)的3D卷积层代替每个inception中的时间起始层,从RAMap中提取不同长度的时间特征。
L-NMS: Identify Detections from ConfMap
要从 ConfMap获得最终检测,仍然需要一个后处理步骤。在这里,研究者采用了非极大抑制(NMS)的想法,它经常用于基于图像的目标检测,以从探测器中删除冗余的边界框。
在这里,NMS使用联合节点上的IoU作为标准来确定是否应删除边界框。然而,在我们的问题中并没有关于边界框的定义。因此,受COCO数据集中定义的人体姿态评估的目标关键点相似度(OKS)的启发,研究者定义了一种新的度量,称为目标位置相似度(OLS),以扮演IoU的作用,它描述了两个检测的距离、它们的类别和尺度信息之间的关系。更具体地说:
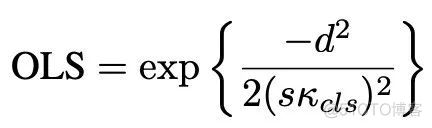
在定义了OLS之后,提出了一个基于位置的NMS(L-NMS),其过程可以总结如下:
1)Get all the peaks in all C channels in ConfMaps within a
3 × 3 window as a peak set P = {pn}
2)Pick the peak p ∗ ∈ P with the highest confidence and remove
it from the peak set. Calculate OLS with each of the rest peaks pi ,
where pi≠p∗
3)If OLS between p∗ and pi is greater than a threshold, remove pi
from the peak set
4)Repeat Steps 2 and 3 until the peak set becomes empty
四、实验
CRUW datase收集
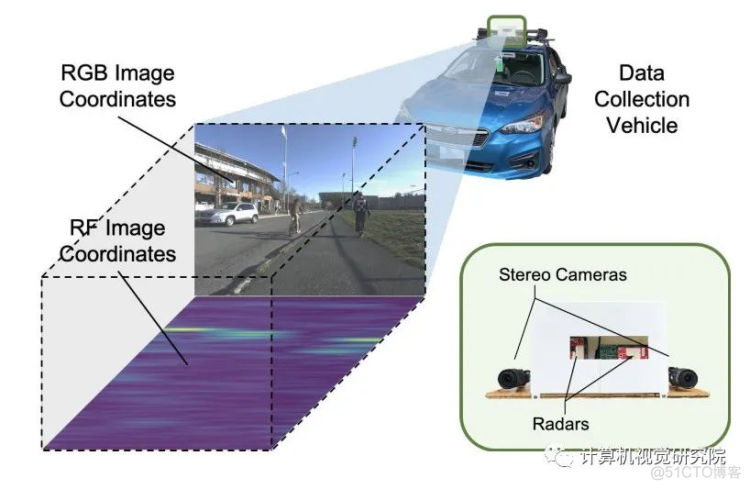

Different scenes in the datase
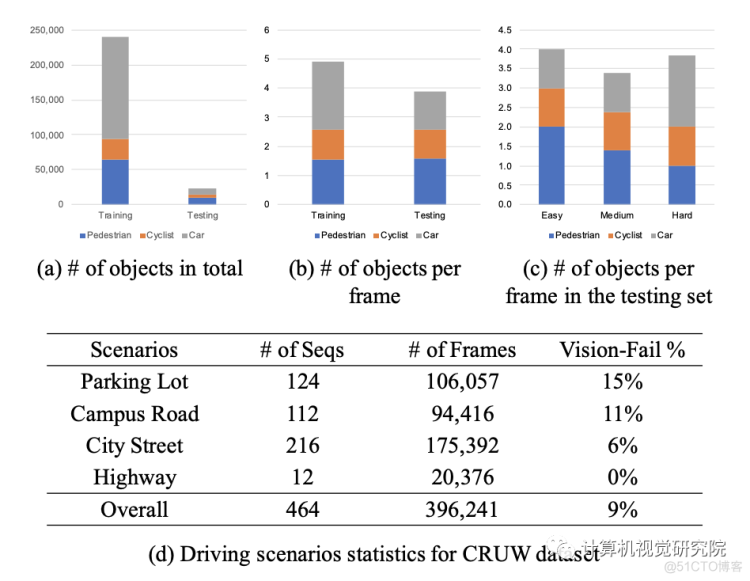
数据分布

计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
论文下载 | 回复“ROD”获取论文