

计算机视觉研究院专栏
作者:Edison_G
CVPR21文章我们也分享了很多最佳的框架,在现实场景中,目标检测依然是最基础最热门的研究课题,尤其目前针对小目标的检测,更加吸引了更多的研究员和企业去研究,今天我们“计算机视觉研究院”给大家分享一个小目标检测精度提升较大的新框架!

公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式

论文:
https://arxiv.org/pdf/1912.06319.pdf
1
简要
在各种环境中应用目标检测算法有很多局限性。特别是检测小目标仍然具有挑战性,因为它们分辨率低,信息有限。

有研究员提出了一种利用上下文的目标检测方法来提高检测小目标的精度。该方法通过连接多尺度特征,使用了来自不同层的附加特征作为上下文。研究员还提出了具有注意机制的目标检测,它可以关注图像中的目标,并可以包括来自目标层的上下文信息。实验结果表明,该方法在检测小目标方面的精度高于传统的SSD框架。
2
背景
下图显示了SSD框架无法检测到小目标时的案例情况。对小目标的检测还有很大的改进空间。

由于低分辨率低,像素有限,小目标检测很困难。例如,通过只看下图上的目标,人类甚至很难识别这些物体。然而,通过考虑到它位于天空中的背景,这个物体可以被识别为鸟类。因此,我们认为,解决这个问题的关键取决于我们如何将上下文作为额外信息来帮助检测小目标。

3
新框架分析
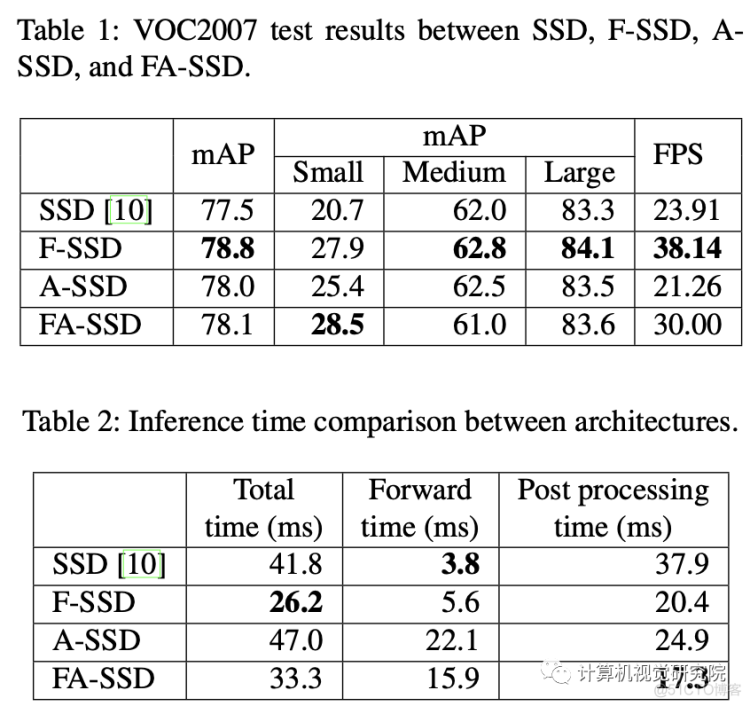
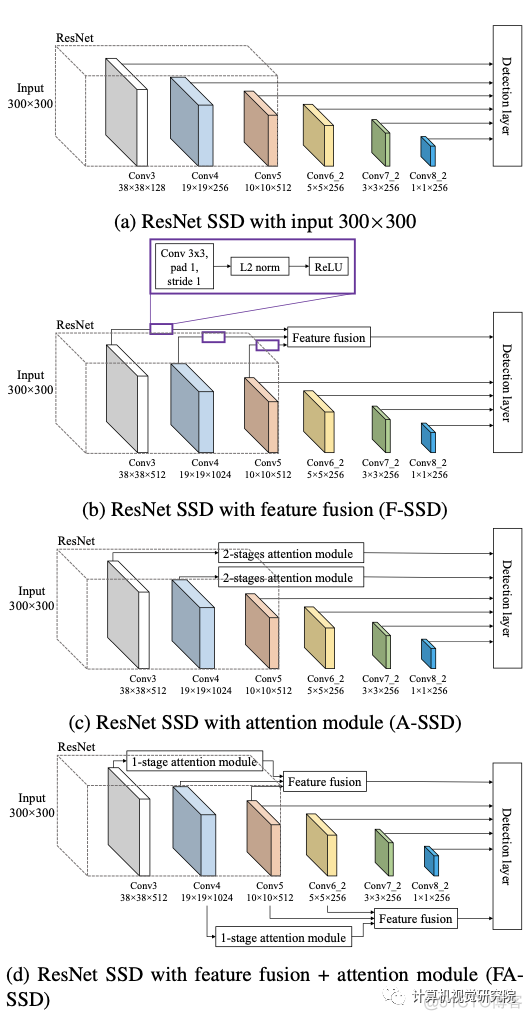
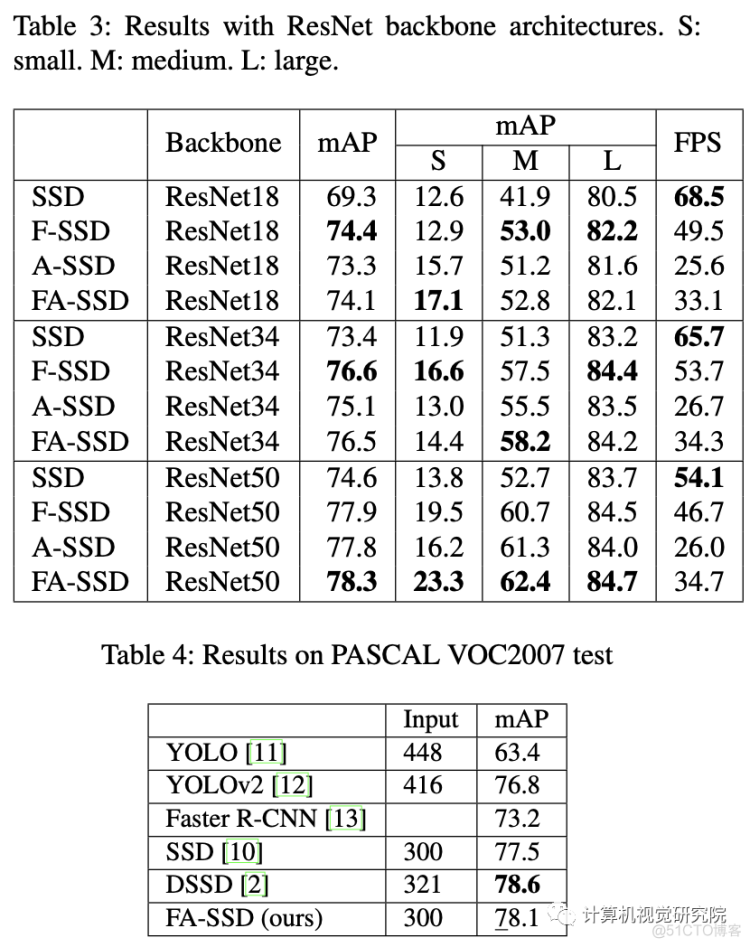
新框架将从基线SSD开始讨论,然后是研究者提出的提高小目标检测精度的组件。首先,SSD与特征融合,以获取上下文信息,名为F-SSD;第二,带有保留模块的SSD,使网络能够关注重要部件,名为A-SSD;第三,研究者结合了特征融合和注意力模块,名为FA-SSD。
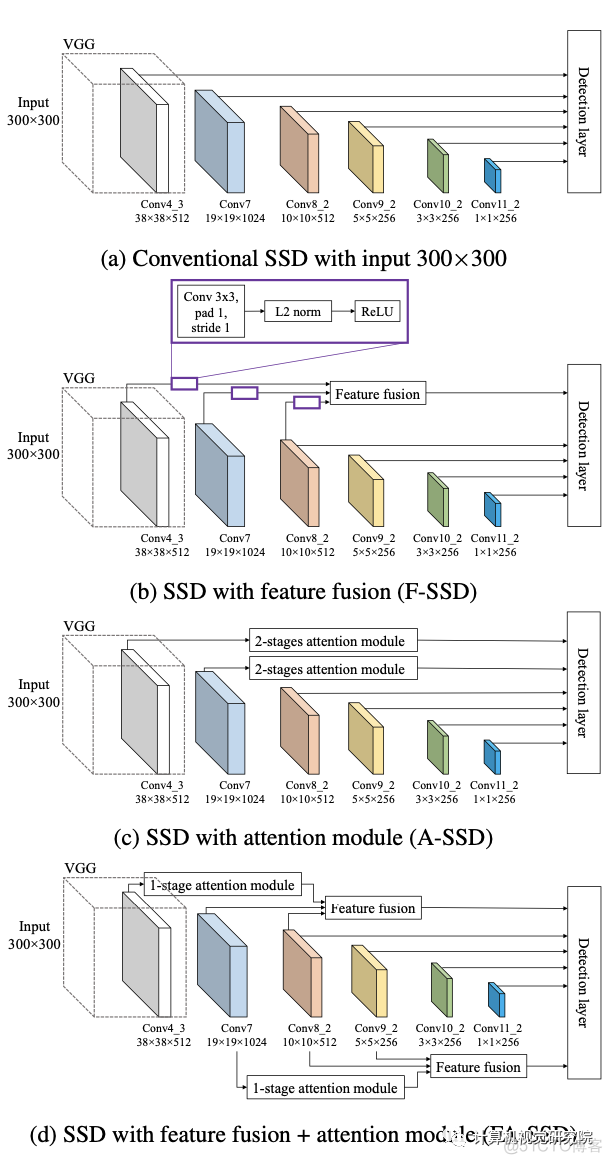
F-SSD: SSD with context by feature fusion
为了为给定的特征图(目标特征图)在我们想要检测目标的位置提供上下文,研究者将其与目标特征层更高层次的特征图(上下文特征)融合。例如,在SSD中,给定我们来自conv4_3的目标特性,我们的上下文特征来自两层,它们是conv7和conv8_2。
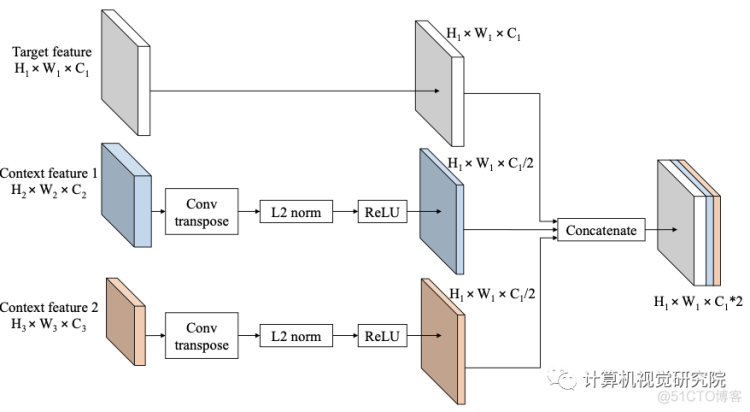
虽然新框架的特征融合可以推广到任何目标特征和任何更高的特征。然而,这些特征图具有不同的空间大小,因此研究者提出了如上图所示的融合方法。在通过连接特征进行融合之前,对上下文特征执行反卷积,使它们具有与目标特征相同的空间大小。将上下文特征通道设置为目标特征的一半,因此上下文信息的数量就不会超过目标特征本身。仅仅对于F-SSD,研究者还在目标特征上增加了一个额外的卷积层,它不会改变空间大小和通道数的卷积层。
此外,在连接特征之前,标准化步骤是非常重要的,因为不同层中的每个特征值都有不同的尺度。因此,在每一层之后进行批处理归一化和ReLU。最后通过叠加特征来连接目标特征和上下文特征。
A-SSD: SSD with attention module
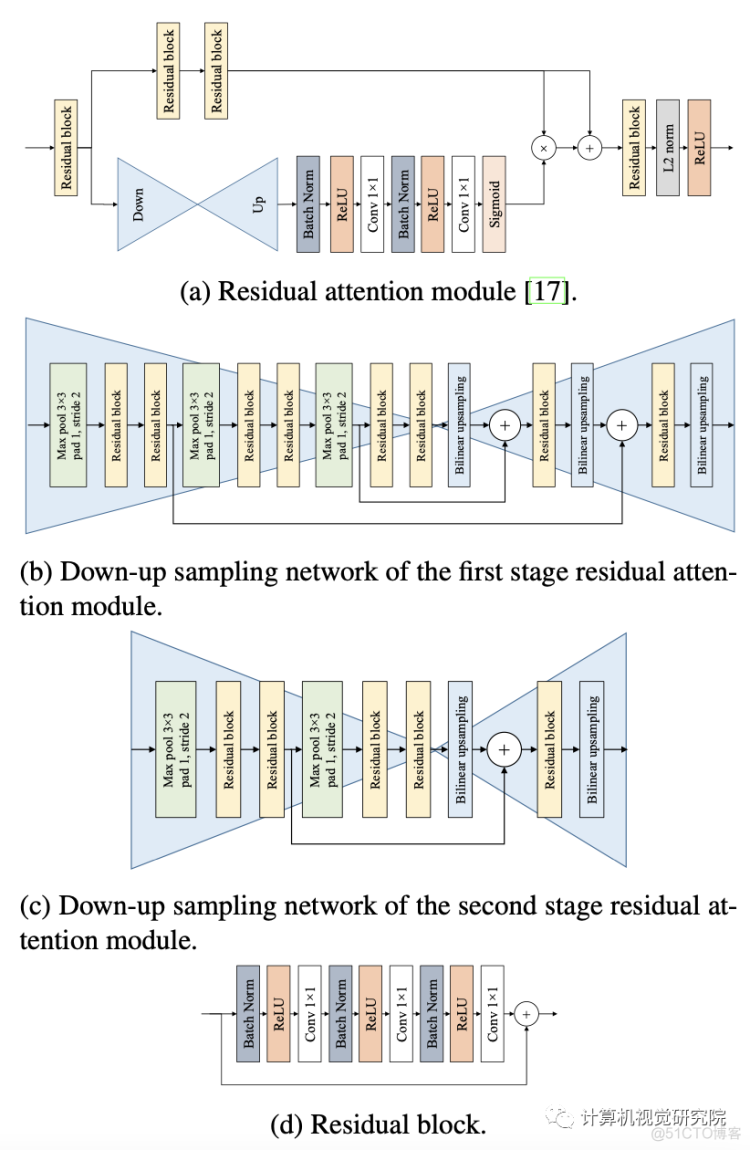
如上图,它由一个trunk分支和一个mask分支组成。trunk分支有两个残差块,每个块有3个卷积层,如上图d所示;mask分支通过使用残差连接执行下采样和上采样来输出注意图(图b为第一阶段和图c为第二阶段),然后完成sigmoid激活。残差连接使保持下采样阶段的特征。然后,来自mask分支的注意映射与trunk分支的输出相乘,产生已参与的特征。最后,参与的特征之后是另一个残差块,L2标准化,和ReLU。
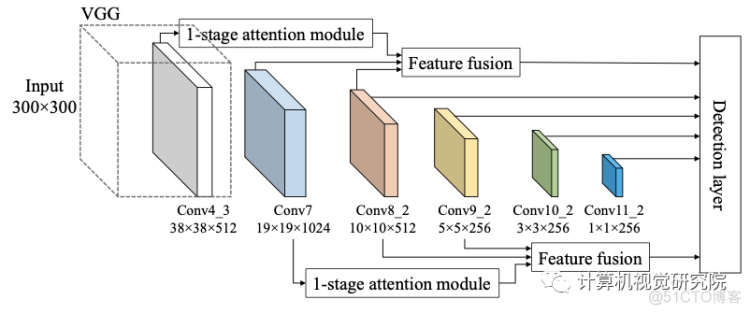
FA-SSD: Combining feature fusion and atten- tion in SSD
研究者提出了以上的两个特征的方法,它可以考虑来自目标层和不同层的上下文信息。与F-SSD相比,研究者没有在目标特征上执行一个卷积层,而是放置了one stage的注意模块,如下图所示。
4
实验
ResNet SSD with feature fusion + attention module (FA- SSD)

红色框是GT,绿色框是预测的

注意力模块的可视化。有些通道关注目标,有些通道关注上下文。conv4_3上的注意模块具有更高的分辨率,因此与conv7上的注意相比,可以关注更小的细节。
© THE END
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
