需求:将压缩文件snappy的数据同步到mysql数据库 snappy可以作为orc文件的压缩格式存在,所以在添加依赖包的时候,直接添加orc的依赖包就可以了 还有一点注意的是,在创建hive表的时候
需求:将压缩文件snappy的数据同步到mysql数据库
snappy可以作为orc文件的压缩格式存在,所以在添加依赖包的时候,直接添加orc的依赖包就可以了
还有一点注意的是,在创建hive表的时候,指明snappy压缩
下面是一个hive建表举例
create table stu_orc(id int,name string)stored as orc
tblproperties ('orc.compress'='snappy');
一、添加依赖包
在dinky的plugins目录和flink的lib目录下,添加orc依赖jar包,并重启dinky和flink
下载地址参考:https://www.bookstack.cn/read/ApacheFlink-1.13-zh/6f9399b3e1a8dd04.md
再次提醒,下载的时候注意flink的版本,要跟自己的flink版本匹配
二、创建作业
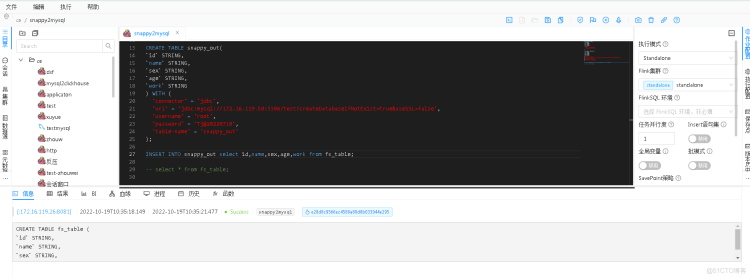
三、编写flinksql代码
我这里提前准备好snappy压缩文件,提前创建Hive的snappy表,并插入数据,hdfs上下载好snappy格式的数据文件
CREATE TABLE fs_table (`id` STRING,
`name` STRING,
`sex` STRING,
`age` STRING,
`work` STRING
) WITH (
'connector'='filesystem',
'path'='/home/data/snappy',
'format'='orc'
);
CREATE TABLE snappy_out(
`id` STRING,
`name` STRING,
`sex` STRING,
`age` STRING,
`work` STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://172.16.119.50:3306/test?createDatabaseIfNotExist=true&useSSL=false',
'username' = 'root',
'password' = 'Tj@20220710',
'table-name' = 'snappy_out'
);
INSERT INTO snappy_out select id,name,sex,age,work from
四、运行作业
检测sql语句没有语法问题后,选定提前部署的flink集群,直接运行作业
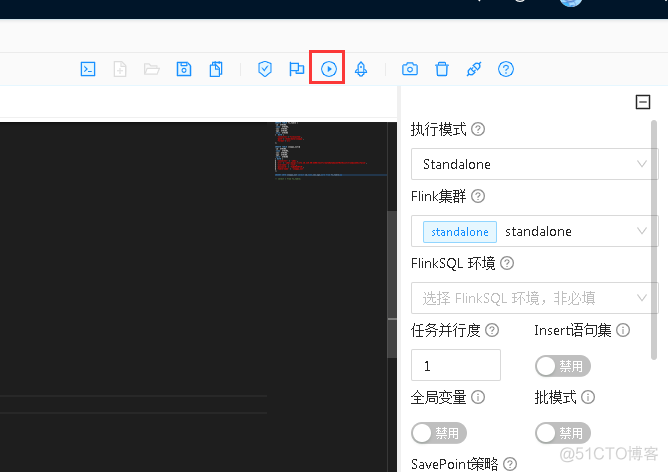
运行成功
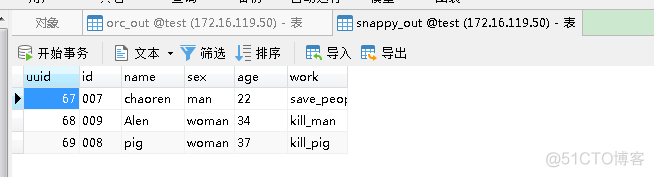
查看mysql表的数据,确认数据是否同步过来