目录
- 前言
- 一、JDK-1.8-API文档说明(推荐阅读)
- 二、简单的使用
- 1、单个字符分隔
- 2、正则表达式
- 三、Java源码分析
- 1、源代码的测试代码
- 2、源代码运行原理图示
- 3、解读完代码后的总结(推荐阅读)
- 四、limit参数使用区别
- 1、limit=0
- 2、limit<0
- 3、limit>0
- 五、易错点(推荐阅读)
- 1、分割到第一个字符
- 2、转义字符\
- 3、正则表达式修饰符不可用
- 总结
前言
本章对Java如何实现字符串的分割,是基于jDK1.8版本中的String.split()方法。
本文篇幅较长,内容较为复杂涉及到许多小细节,都是我在使用时候以及查阅资料时候遇到的坑,建议反复观看!!
内容中含有对源码的解读,如果可以建议详细读懂源码,有助于对split的理解使用。
最后,长文警告,可按需观看!!
一、JDK-1.8-API文档说明(推荐阅读)
首先对java-JDK-1.8的文档进行解读,以下是我从文档中截取的两张图片,分别是关于split单参数方法与split双参数方法,如下图:


对以上内容提炼重点:
- 该方法是将字符串分割的方法,通过给定的String regex作为分割符分割。分割后生成一个字符串数组,该数组中子字符串的排序为他们在原字符串中的顺序。
- 如果没有找到对应的分隔符(regex)则返回一个长度为1的字符串数组,仅存放原字符串
- 对于单个参数的方法有:该方法是调用了限制参数(limit)为0的双参数split方法
- 对于双参数的方法有:limit是控制模式应用的次数因此限定了输出字符串数组的长度,并给出三种分类:
1)limit>0:模式最多应用n-1次,数组的长度不大于n,数组的最后一个条目将包含超出匹配分隔符的所有输入
2)limit<0:模式将被应用到尽可能多的次数,且数组可以有任何长度
3)limit=0:模式将被应用到尽可能多的次数,且数组可以有任何长度,并且尾随的空字符串将被丢弃
二、简单的使用
了解完jdk文档提供的基础使用方法,接下来进行以下简单的一个对于split方法的入门使用,首先是对于单个字符作为分隔符的使用以及对于使用正则表达式分割
1、单个字符分隔
/**
* 输出分隔后的字符数组
* 为了可以明显的看出空字符串的输出,如遇空字符串则输出为——“空字符串”
* @param split
*/
private void printSplit(String[] split) {
for (String temp : split) {
//空字符串的话输出--“空字符串”
if (temp.equals("")) {
System.out.println("空字符串");
} else {
System.out.println(temp);
}
}
}
/**
* 基础使用1:单个字符-:
*/
@Test
public void Test1() {
string = "boo:and:foo";
String[] split = string.split(":");
printSplit(split);
}
/**
* 基础使用1:单个字符-o
*/
@Test
public void Test2() {
string = "boo:and:foo";
String[] split = string.split("o");
printSplit(split);
}
Test1运行结果:
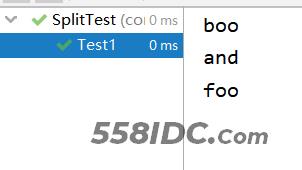
Test2运行结果:
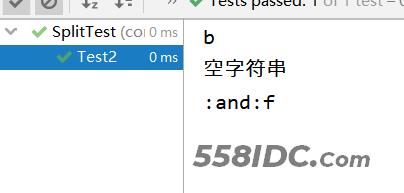
通过单个字符的分割可以看出,基本使用还是比较简单的,但是在第二个分割字符“o”时产生了一定的问题,就是分割到重复的字符“o”会在中间出现一个空字符串,以及尾部的空字符串居然并没有被分割进去
2、正则表达式
/**
* 基础使用2:正则表达式-1
*/
@Test
public void Test3() {
string = "asd-sdf+sda+sda";
//匹配-或者+
String[] split = string.split("[-\\+]");
printSplit(split);
}
/**
* 基础使用2:正则表达式-2
*/
@Test
public void Test4() {
string = "boo1:a2nd:fo3o";
//匹配正整数
String[] split = string.split("[0-9]*[1-9][0-9]*");
printSplit(split);
}
Test3运行结果:
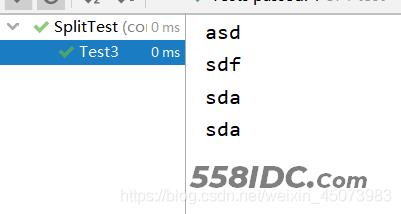
Test4运行结果:
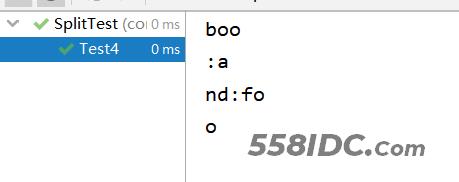
对于正则表达式的分割成功了,证明split中参数String regex是可以支持输入正则表达式进行分割的
三、Java源码分析
以下源码比较绕,建议是跟着下面的测试代码一边调试一边理解(ps:源码英文已转译)。
比较难的说明文字后面都有以下都会有一小部分的总结,如果实在看不懂看总结也可以~
/**
* 单个参数的方法其实就是调用了双参数的方法,第二个参数limit为0
*/
public String[] split(String regex) {
return split(regex, 0);
}
public String[] split(String regex, int limit) {
/*英文转译:
如果正则表达式是
(1)一个字符的字符串,并且这个字符不是
正则表达式的元字符".$|()[{^?* + \ \”,或
(2)两个字符的字符串,第一个字符是反斜杠和
第二个不是ascii数字或ascii字母。*/
//下面有对于if判断的拆解,因为篇幅占位大,放到本段代码末尾,建议先看
char ch = 0;
if (((regex.value.length == 1 &&
".$|()[{^?*+\\".indexOf(ch = regex.charAt(0)) == -1) ||
(regex.length() == 2 &&
regex.charAt(0) == '\\' &&
(((ch = regex.charAt(1))-'0')|('9'-ch)) < 0 &&
((ch-'a')|('z'-ch)) < 0 &&
((ch-'A')|('Z'-ch)) < 0)) &&
(ch < Character.MIN_HIGH_SURROGATE ||
ch > Character.MAX_LOW_SURROGATE))
//以上这一大片都是if判断条件↑
{
//定义上一个字符串分割结束的位置,起始为0
int off = 0;
//定义下一个分隔符在待分割字符串中的位置,,起始为0
int next = 0;
//boolean值,如果limit大于0为true ,小于等于0皆为false
boolean limited = limit > 0;
//定义分割后的字符串数组,因为String[]长度固定,不便于使用
ArrayList<String> list = new ArrayList<>();
/**
* while判断语句中做了两件事:
* 1)使用indexof查询off以后下一个ch的位置,并赋值给next
* 2)如果后续再找不到ch则退出循环
*
*if语句中也不简单,首先看【 !limited 】
*上面limited赋值中可知,如果limit大于0,则【!limited】恒为false
* 如果limit不大于于0,则【!limited】恒为true
*翻译为“人话”就是:
* 如果limit大于0则后续条件才需要判断,否则if条件一直都是true
* 进一步推论,如果limit不大于0,则else里面的语句块肯定不会执行
*
*其次看看第二个条件,【list.size() < limit - 1】:list的长度小于limit-1
*我们可以做出两种假设:
* 1)limit无限大,则这第二个条件一定恒为true
* 2)limit很小,那么只有这种情况才会出现list长度会小于limit的情况,也就是false
* 那么limit的分界线在哪呢?也就是limit的取值如何才会出现有false的情况
* 决定性因素肯定就是 原字符串分割出多少子字符串:
* 若limit是大于能分割出的子字符串,表达式一定为true
* 若limit是小于能分割出的子字符串个数,那表达式【list.size()=limit-1】则为false,并且进入else语句块。
*
*将两个条件整合到一起:也就是只有当limit>0并且小于能分割出子字符串个数时
*if才会出现false的情况,并且这时【list.size()=limit-1】,进入else语句块
*
*if{...}else{...}里面的语句块就比较简单了
* 通过substring进行分割字符串,并放入list中
* 然后将off往后移动
* else内的语句块也是一样的,不过添加的是最后一个子字符串
*/
while ((next = indexOf(ch, off)) != -1) {
if (!limited || list.size() < limit - 1) {
list.add(substring(off, next));
off = next + 1;
} else { // last one
//assert (list.size() == limit - 1);
list.add(substring(off, value.length));
off = value.length;
break;
}
}
// If no match was found, return this
//如果没有找到匹配项,则返回this
//off如果为0,那么就证明上述那个循环中并未找到匹配项
if (off == 0)
return new String[]{this};
// Add remaining segment
//添加剩余的部分
//同上,当limit不大于0的时候恒为true
//只有limit>0而且list长度大于等于limit才为false
//因为上面循环中list.size()=limit-1,进入else语句块,语句块中会再给list加入一个元素
//可知,这个if判断与上面else语句块两个互补,两个不会同时运行到
//这个与else语句块作用一致,都是将最后一个子字符串添加入list
if (!limited || list.size() < limit)
list.add(substring(off, value.length));
// Construct result
//构建结果
//如果limit为0,进行特殊处理
//首先字符串数组长度大于0并且获取最后一个字符数组的字符串长度为0
//简而言之,前提条件字符数组长度得大于0(小于0还分割个啥)
//其次寻找最后一个是否是空字符串,如果是,将长度减一,如果不是则退出循环
int resultSize = list.size();
if (limit == 0) {
while (resultSize > 0 && list.get(resultSize - 1).length() == 0) {
resultSize--;
}
}
//定义字符数组,将list转为String[]
//因为后面空字符长度被去掉了,于是空字符被省略了
String[] result = new String[resultSize];
return list.subList(0, resultSize).toArray(result);
}
//如果不符合if的条件就进入这个方法
return Pattern.compile(regex).split(this, limit);
}
//if条件的拆分
/*如果正则表达式是
(1)一个字符的字符串,并且这个字符不是
正则表达式的元字符".$|()[{^?* + \ \”,或
(2)两个字符的字符串,第一个字符是反斜杠和
第二个不是ascii数字或ascii字母。*/
(
(
(
regex.value.length == 1
&&
".$|()[{^?*+\\".indexOf(ch = regex.charAt(0)) == -1
//小细节,这里将ch赋值了,也就是将改字符赋值给了ch
)
||
(
regex.length() == 2
&&
regex.charAt(0) == '\\'
&&
(((ch = regex.charAt(1))-'0')|('9'-ch)) < 0
//小细节*2
&&
((ch-'a')|('z'-ch)) < 0
&&
((ch-'A')|('Z'-ch)) < 0
)
)
&&
(ch < Character.MIN_HIGH_SURROGATE ||ch > Character.MAX_LOW_SURROGATE)
)
1、源代码的测试代码
建议进入调试模式配合上面代码同步运行,有利于对代码的解读
/**
* 读源码:测试1,单个非特殊字符
* 结果为并未调用Pattern.compile
* if判断条件结果为true
*/
@Test
public void Test5() {
string = "boo:and:foo";
String[] split = string.split(":");
printSplit(split);
}
/**
* 读源码:测试1,两个字符,并且第一个字符为\第二个字符不为数字或者单词
* 结果为并未调用Pattern.compile
* if判断条件结果为true
* 这里需要注意,虽然regex是为\\$但是其实在Java解读中第一个为转义字符
* 所以传到方法中其实代码解读为\$
* 你们可以在调试的时候看一下这个入参的值便能发现
*/
@Test
public void Test6() {
string = "boo$and$foo";
String[] split = string.split("\\$");
printSplit(split);
}
/**
* 读源码:测试3,三个字符
* if判断条件结果为false
* 结果为调用了Pattern.compile
*/
@Test
public void Test7() {
string = "boo:and:foo";
String[] split = string.split("and");
printSplit(split);
}
2、源代码运行原理图示
下图为以":"作为分隔符的运行图示

3、解读完代码后的总结(推荐阅读)
1.if可以进入的条件为单个字符并且不为正则表达式元字符,或者双字符,第一个为反斜杠并且第二个字符不为数字与字母,如此一来,其实第二个条件就是允许输入正则表达式元字符,其实整个if条件就是如果是单个字符就可以允许输入,但是为了遵循正则表达式的规则才设置了两个字符的条件。
结论:String.split()这个方法对于单个字符(包括特殊字符,但是需要转义)是自己进行分割的,但是如果是**多个字符,这个方法就会去调用Pattern.compile(regex).split(this, limit);**这个方法
如果需要多次使用split方法并且都是多个字符作为分隔符,直接使用Pattern.compile(regex).split(this, limit);或许会带来更高的效率
2.内部采用substring()进行字符串的分割,然后传入list集合内部,于是如果待分割字符串中分隔符连续出现就会出现分割出空字符串,详情可见上面使用“o”进行分割出现了一个空字符串,会出现substring(n,n) 这种情况结果为空字符串
3.如果使用limit =0 的双参数方法,区别于limit <0,split会在生成结果前检查后端的空字符串并将其去掉,这就是为什么limit = 0的时候后面的空字符串会被丢弃
四、limit参数使用区别
1、limit=0
那么模式将被应用尽可能多的次数,数组可以是任何长度,并且结尾空字符串将被丢弃。
就是会首先运行出全部分割出的子字符串然后再将后面结尾的空格去掉
/**
* limit参数区别:=0
* 输出全部结果,去除结果后面全部空字符数组
*/
@Test
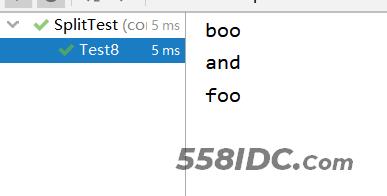
public void Test8() {
string = "boo:and:foo:::";
String[] split = string.split(":", 0);
printSplit(split);
}
Test8运行结果:
2、limit<0
模式将被应用尽可能多的次数,而且数组可以是任何长度。
分割出全部子字符串包含有全部分割结果
/**
* limit参数区别:<0
* 输出全部结果
*/
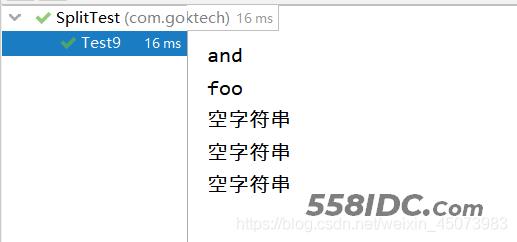
@Test
public void Test9() {
string = "boo:and:foo:::";
String[] split = string.split(":", -1);
printSplit(split);
}
Test9运行结果:
3、limit>0
模式将被最多应用 n - 1 次,数组的长度将不会大于 n,而且数组的最后一项将包含所有超出最后匹配的定界符的输入。
分割出的字符串长度只会小于等于limit,当limit小于能分割出的子字符串数量时,这个时候数组长度等于limit
如果limit大于能分割出的子字符串数量时,数组长度等于子字符串数量,小于limit
/**
* limit参数区别:>0 --小于分割出的字符数组长度
*/
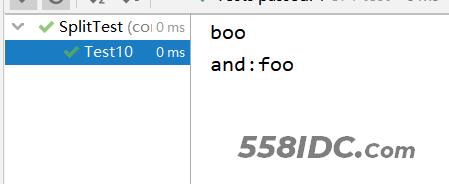
@Test
public void Test10() {
string = "boo:and:foo";
String[] split = string.split(":", 2);
printSplit(split);
}
/**
* limit参数区别:>0 --大于分割出的字符数组长度
*/
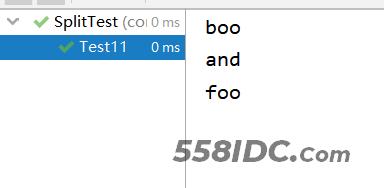
@Test
public void Test11() {
string = "boo:and:foo";
String[] split = string.split(":", 5);
printSplit(split);
}
Test10运行结果:
Test11运行结果:
五、易错点(推荐阅读)
1、分割到第一个字符
当第一个字符被分割到,则字符数组首个字符串为空
原因分析:在源码中可以看出,源码使用indexof进行查找下一个分隔符的位置,当找到分隔符为第一个的时候就会将next赋值为0,然后使用substring分割,于是两个参数就变成了subtring(0,0)必然分割出一个空字符串出来
如果开头的这个空字符串并非想要的理想输出,只能自己手动去除
/**
* 易错点:分割到第一个字符
*/
@Test
public void Test12() {
string = "boo$and$foo";
String[] split = string.split("b", 0);
printSplit(split);
}
Test12运行结果:

2、转义字符\
java中使用\必须再次进行一次转义,例如用“\\”代表“\”,并且正则表达式元字符都必须转义才能作为分隔符
原因分析:split这个方法其实可以看出还是推荐我们使用正则表达式进行分割的,在写String regex这个参数我建议还是看着正则表达式的书写方法进行书写的
源码中明确给出说明,正则表达式元字符前面都需要使用\转义——.$|()[{^?*+\

其次,java中\的使用也必须进行转义,在Java中双反斜杠表示一个反斜杠,书写中应该特别注意
推荐书写方法:先找个正则表达式验证的网站验证正则表达式的书写,然后复制进去java代码中,需要注意的是,在java 1.7之后将带有\的字符串粘贴到双引号中会自动再添加一个\
/**
* 易错点:转义字符\
*/
@Test
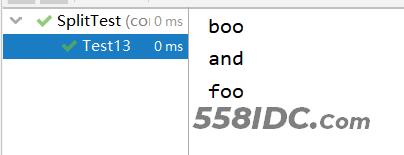
public void Test13() {
//因为java代码不能直接输入一个反斜杠,必须进行转义,这里的\\表达为\
string = "boo\\and\\foo";
//这里\\\\应该拆开看成为\\ \\,前面两个代表一个\后面两个代表一个\
//实际\\\\表达的含义应该为\\,对应正则表达式的语法\\表达为\
//所以在Java代码中\\\\在最终处理时候其实表达为\
String[] split = string.split("\\\\", 0);
printSplit(split);
}
/**
* 易错点:转义字符\
*/
@Test
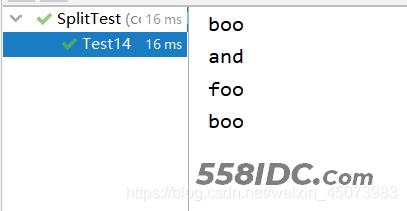
public void Test14() {
string = "boo+and-foo*boo";
//这里的+-*都是正则表达式的元字符,都需要使用\转义,然后在Java中再对\转义
//原正则表达式[\+\-\*]
String[] split = string.split("[\\+\\-\\*]", 0);
printSplit(split);
}
Test13运行结果:
Test14运行结果:
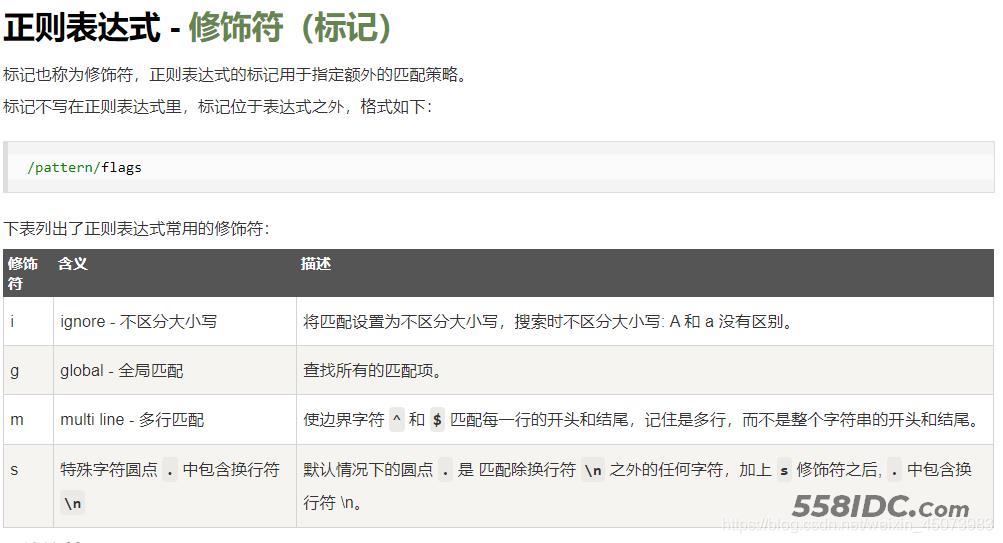
3、正则表达式修饰符不可用
基于运行测试发现正则表达式的修饰符在split中使用是无效的,使用的时候注意避开
/**
* 易错点:正则表达式修饰符不可用
* 理想输出[(boo:),(nd:foo)]
*/
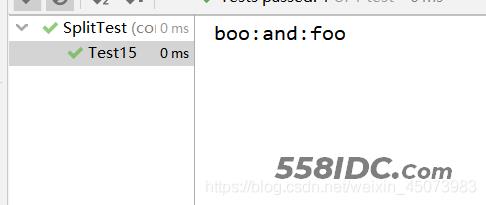
@Test
public void Test15() {
string = "boo:and:foo";
String[] split = string.split("/[a]/g", 0);
printSplit(split);
}
Test15运行结果:
总结
到此这篇关于Java实现字符串的分割的文章就介绍到这了,更多相关Java字符串分割内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!