使用pandas库来读取xlsx格式中的数据。 excel中数据: 示例代码1: import pandas as pd # data = pd.read_excel('./data/体检表.xlsx')# data = pd.read_excel('./data/体检表.xlsx', sheet_name='Sheet1')data = pd.read_excel
使用pandas库来读取xlsx格式中的数据。
excel中数据:
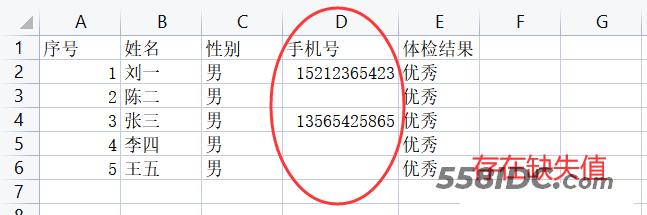
示例代码1:
import pandas as pd
# data = pd.read_excel('./data/体检表.xlsx')
# data = pd.read_excel('./data/体检表.xlsx', sheet_name='Sheet1')
data = pd.read_excel('./data/体检表.xlsx', sheet_name=0)
print(data)
print("*" * 100)
data = pd.read_excel('./data/体检表.xlsx', sheet_name=0, header=0, usecols=[1, 2, 4])
"""
sheet_name:返回指定的sheet,如果将sheet_name指定为None,则返回全表,如果需要返回多个表,可以将sheet_name指定为一个列表,例如['sheet1', 'sheet2']
header:指定数据表的表头,默认值为0,即将第一行作为表头。
usecols:读取指定的列,例如想要读取第一列和第二列数据
"""
print(data)
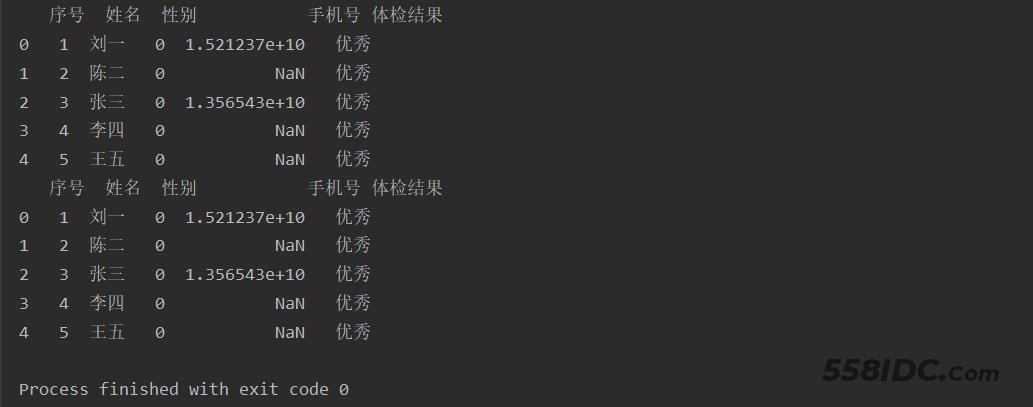
运行结果:

示例代码2: 【修改xlsx中的数据】
import pandas as pd
from pandas import DataFrame
data = pd.read_excel('./data/体检表.xlsx', sheet_name='Sheet1')
print(data)
# 将性别中的男修改为数字0,女修改为数字1
data['性别'][data['性别'] == '男'] = 0
data['性别'][data['性别'] == '女'] = 1
print(data)
"""
注意:这里的data为excel数据的一份拷贝,对data进行修改并不会直接影响到我们原来的excel,必须在修改后保存才能够修改excel。
"""
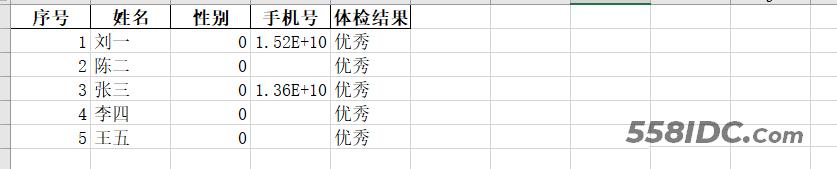
# 下面代码将会新建一个文件,如果存在则会覆盖整个文件,类似于‘w'模式
# DataFrame(data).to_excel('./data/体检表4.xlsx', sheet_name='Sheet1', index=False, header=True)
data.to_excel('./data/体检表2.xlsx', sheet_name='Sheet1', index=False, header=True)
运行结果:
到此这篇关于使用python+pandas读写xlsx格式中的数据的文章就介绍到这了,更多相关pandas读写xlsx数据内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!