目录 前言 一、构建es库中的数据 1.1 创建索引 1.2 插入数据 1.3 查询数据 二、对excel表格中的数据处理操作 2.1 导出es查询的数据 前言 任务描述: 当前有一份excel表格数据,里面存在缺失
目录
- 前言
- 一、构建es库中的数据
- 1.1 创建索引
- 1.2 插入数据
- 1.3 查询数据
- 二、对excel表格中的数据处理操作
- 2.1 导出es查询的数据
前言
任务描述:
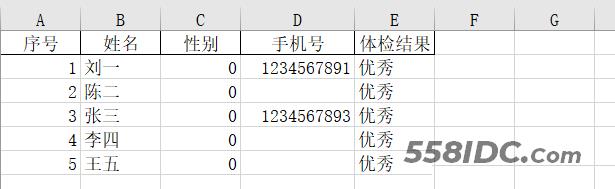
当前有一份excel表格数据,里面存在缺失值,需要对缺失的数据到es数据库中进行查找并对其进行把缺失的数据进行补全。
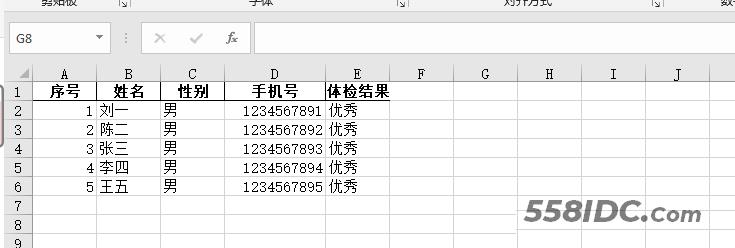
excel表格数据如下所示:
一、构建es库中的数据
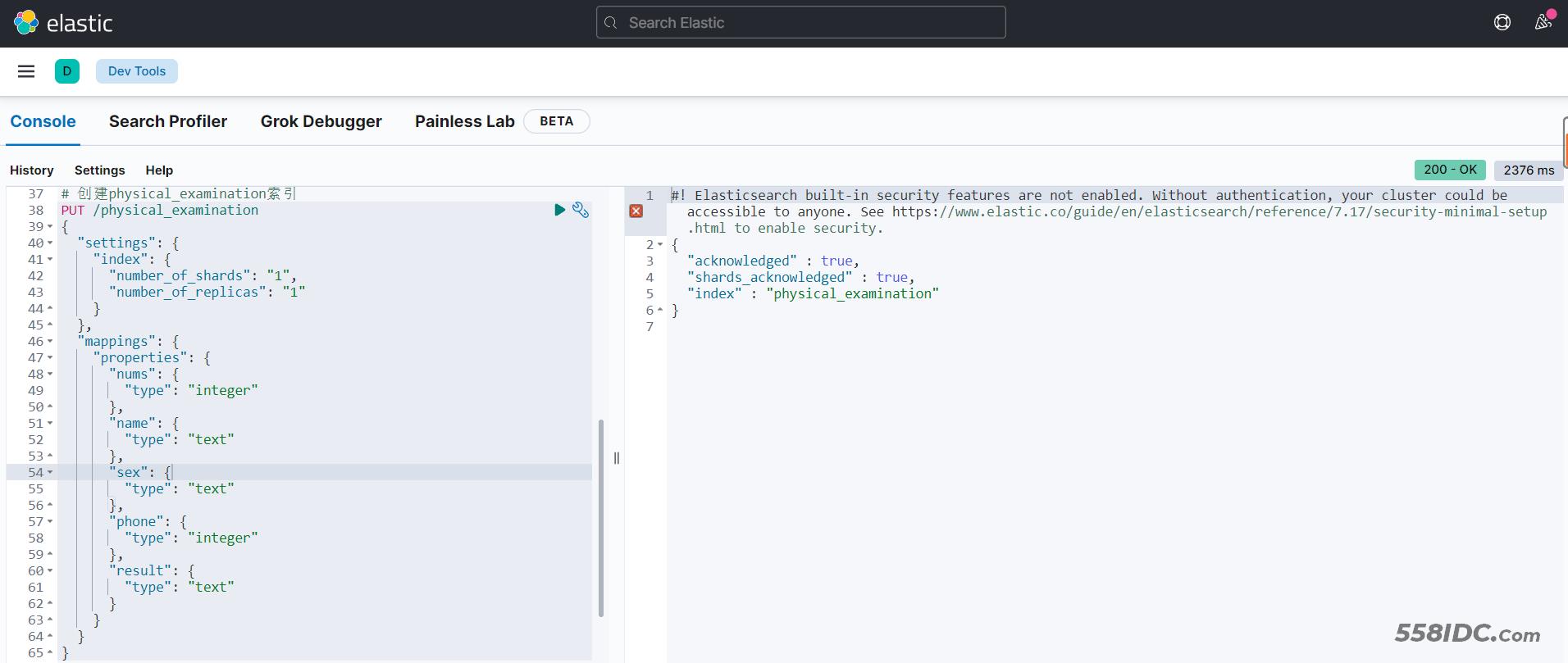
1.1 创建索引
# 创建physical_examination索引
PUT /physical_examination
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "1"
}
},
"mappings": {
"properties": {
"nums": {
"type": "integer"
},
"name": {
"type": "text"
},
"sex": {
"type": "text"
},
"phone": {
"type": "integer"
},
"result": {
"type": "text"
}
}
}
}
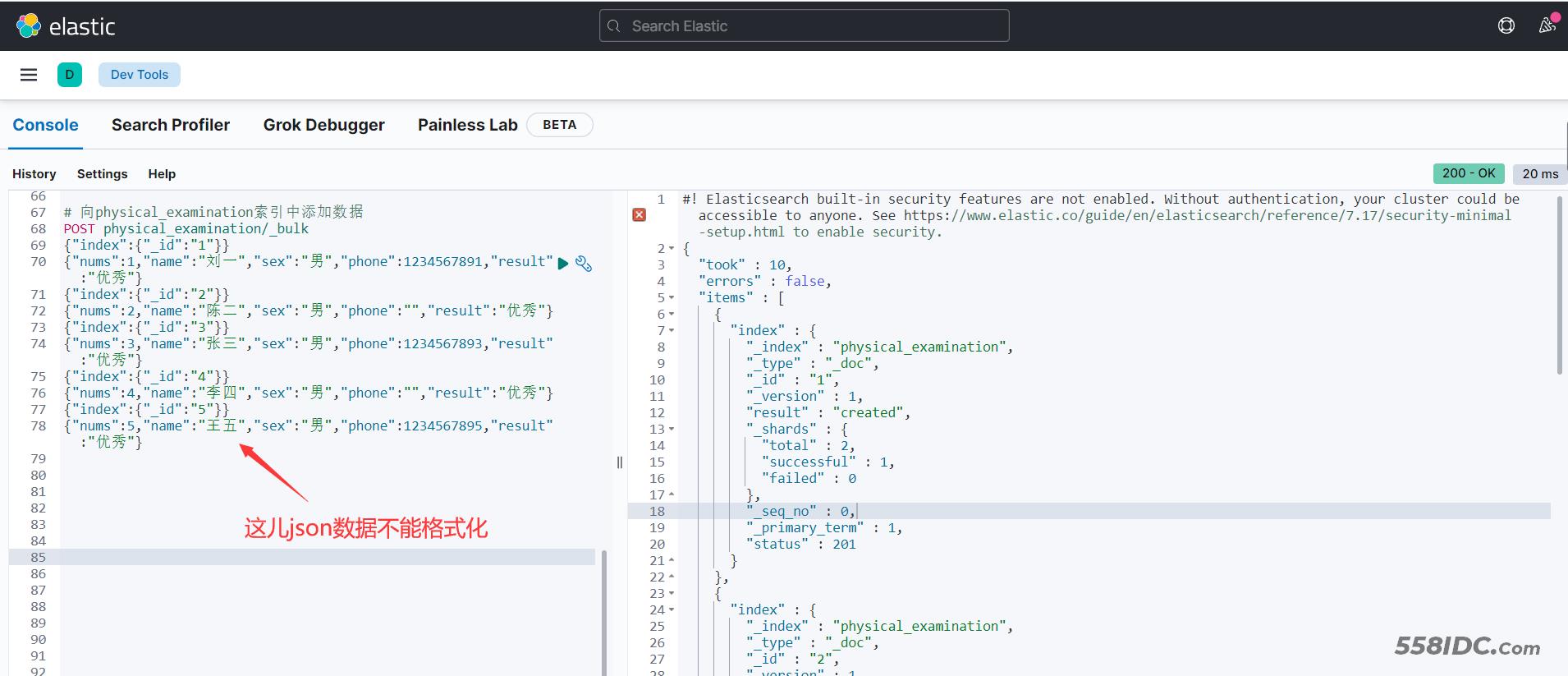
1.2 插入数据
【注意:json数据不能格式化换行,否则报错】
# 向physical_examination索引中添加数据
POST physical_examination/_bulk
{"index":{"_id":"1"}}
{"nums":1,"name":"刘一","sex":"男","phone":1234567891,"result":"优秀"}
{"index":{"_id":"2"}}
{"nums":2,"name":"陈二","sex":"男","phone":1234567892,"result":"优秀"}
{"index":{"_id":"3"}}
{"nums":3,"name":"张三","sex":"男","phone":1234567893,"result":"优秀"}
{"index":{"_id":"4"}}
{"nums":4,"name":"李四","sex":"男","phone":1234567894,"result":"优秀"}
{"index":{"_id":"5"}}
{"nums":5,"name":"王五","sex":"男","phone":1234567895,"result":"优秀"}
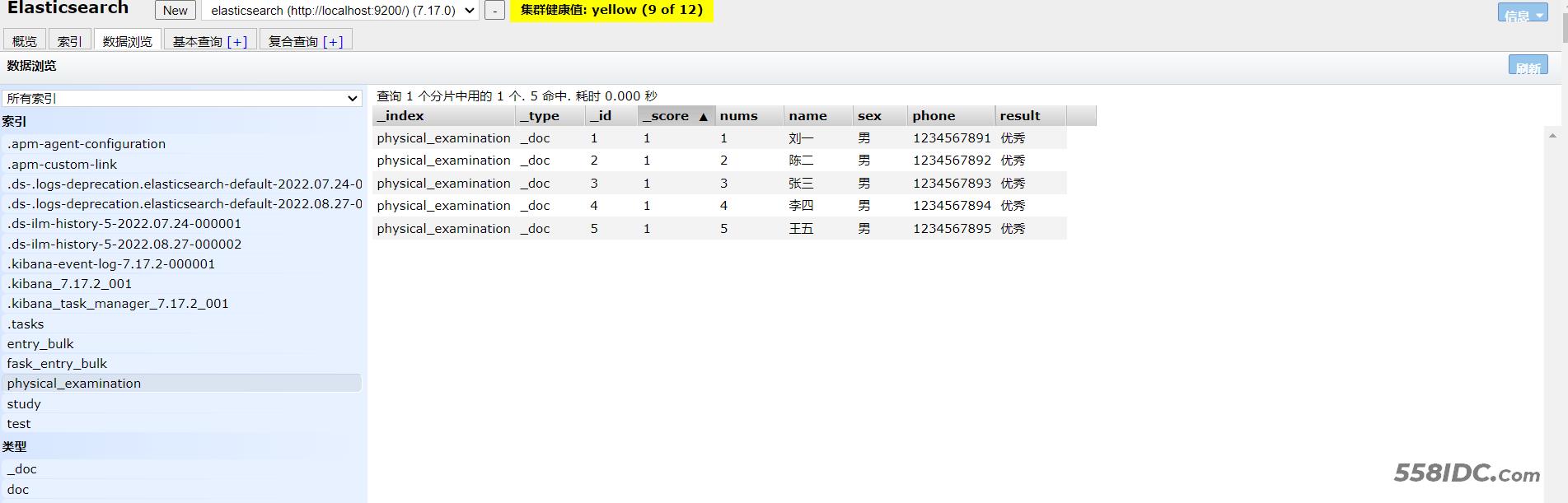
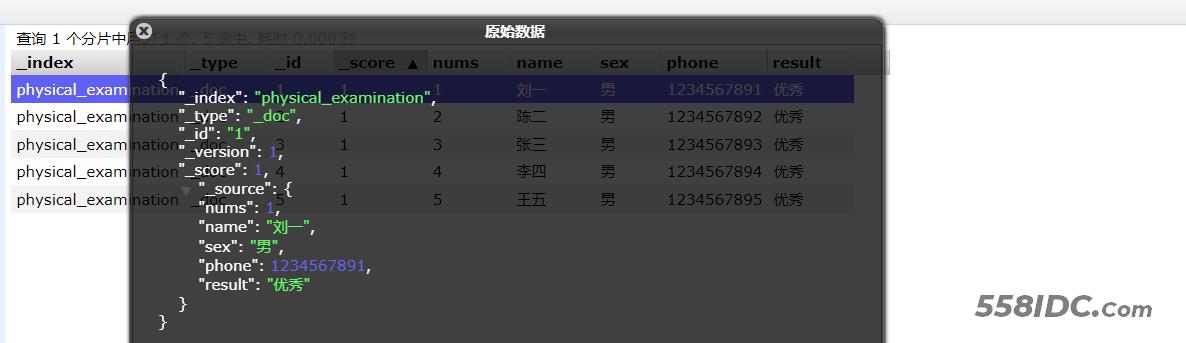
1.3 查询数据
【注意:默认查询索引下的所有数据】
# 查询索引中的所有数据
GET physical_examination/_search
{
"query": {
"match_all": {}
}
}
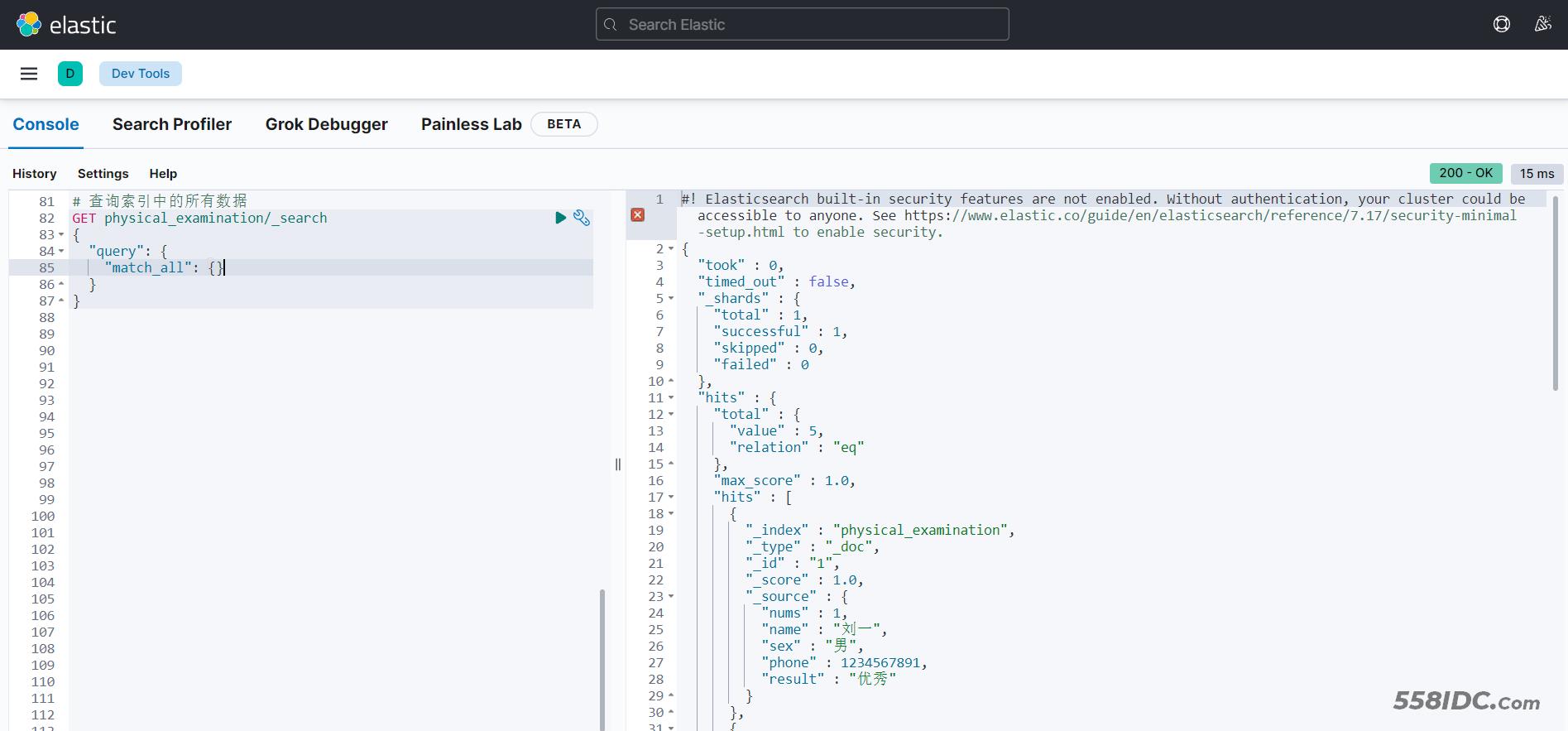
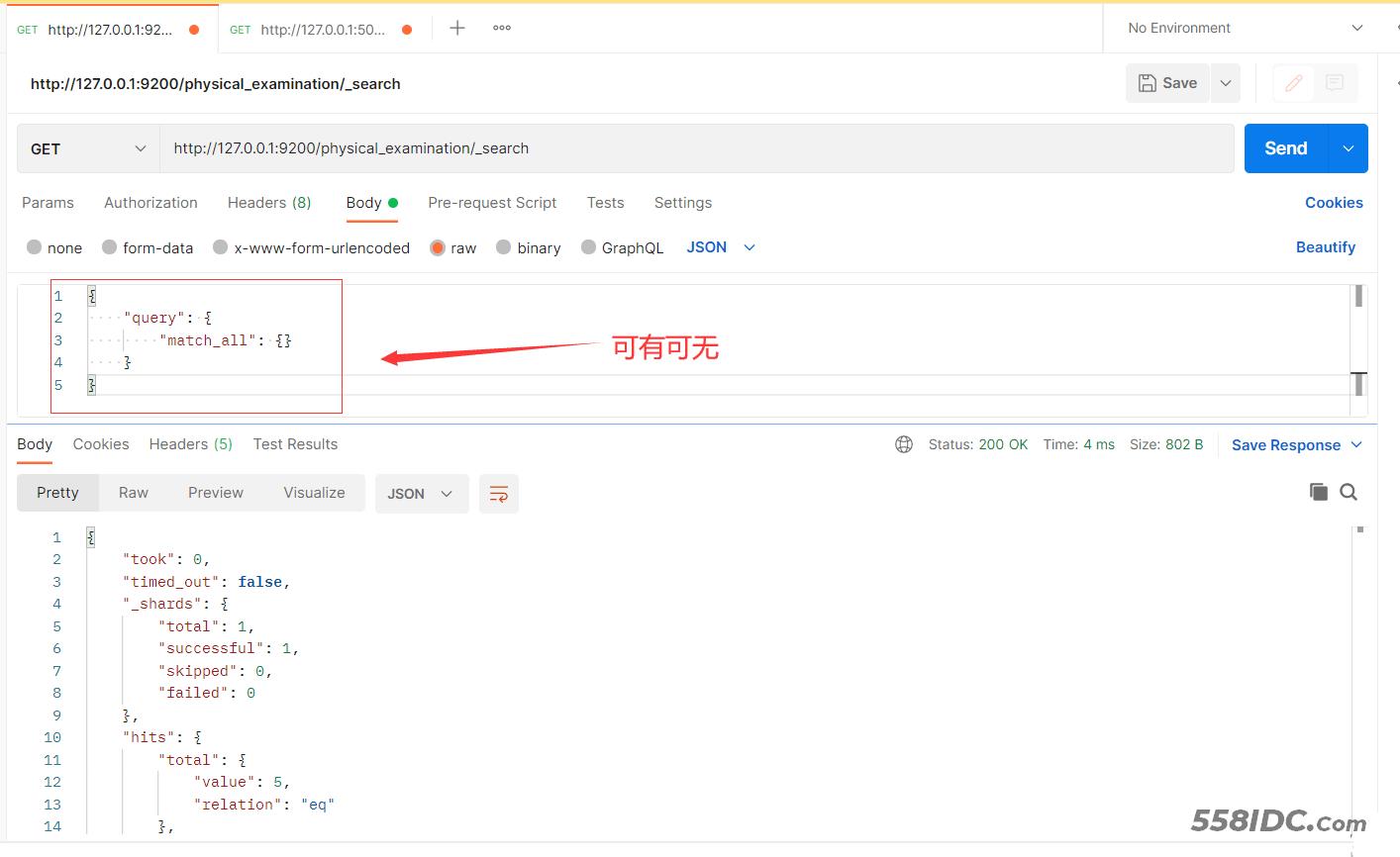
二、对excel表格中的数据处理操作
2.1 导出es查询的数据
- 方法一:直接在kibana或postman查询的结果中进行复制粘贴到一个文档。
- 方法二:使用kibana导出数据。
- 方法三:使用postman导出数据保存到本地。
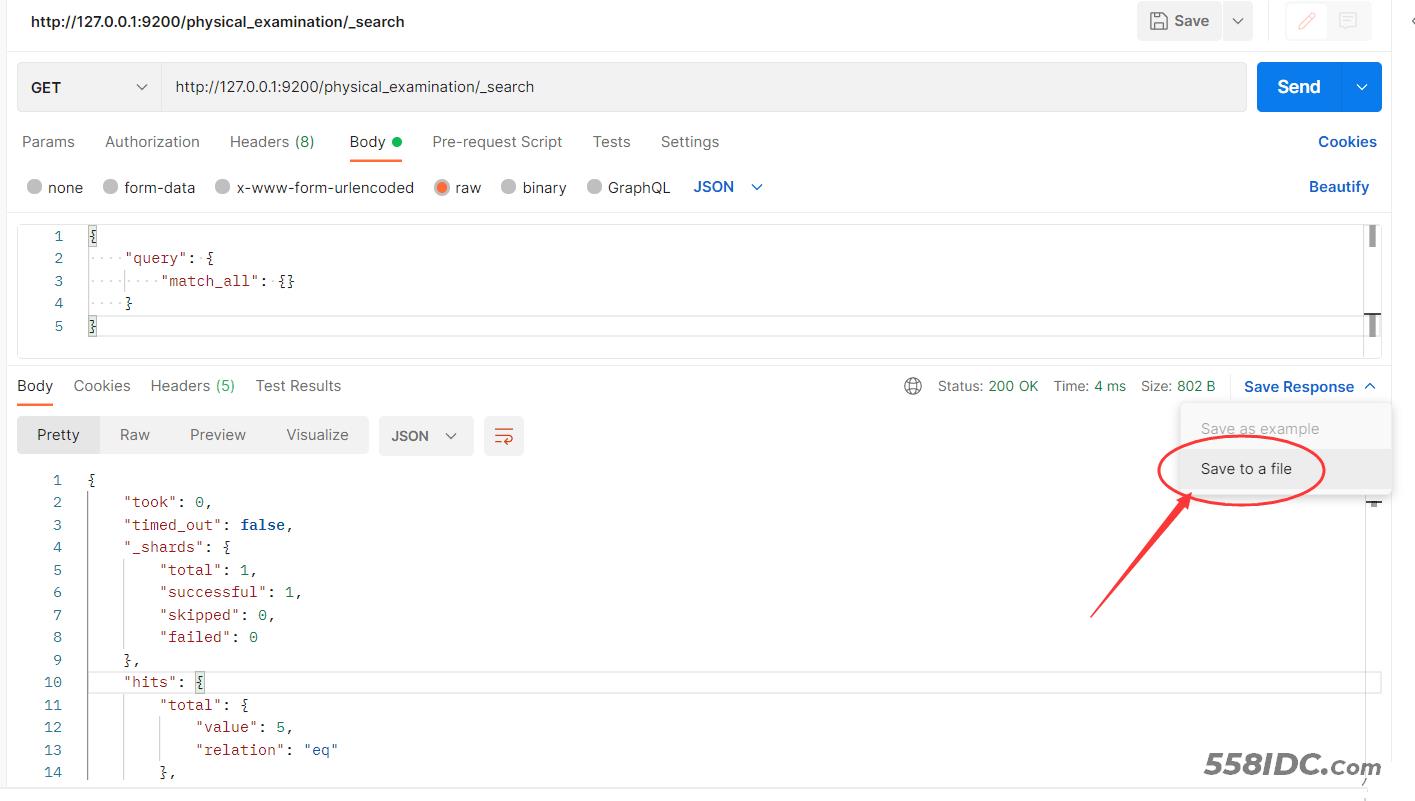
使用python处理数据,获取需要的数据。
示例代码:
# 读取json中体检信息
with open('./data/physical_examination.json', 'r', encoding='utf-8') as f:
data_json = f.read()
print(data_json)
# 处理json数据中的异常数据
if 'false' in data_json:
data_json = data_json.replace('false', "False")
data_json = eval(data_json)
print(data_json)
print(data_json['hits']['hits'])
print('*' * 100)
valid_data = data_json['hits']['hits']
need_data = []
for data in valid_data:
print(data['_source'])
need_data.append(data['_source'])
print(need_data)
读取缺失数据的excel表格,把缺失的数据填补进去。
# 读取需要填补数据的表格
data_xlsx = pd.read_excel('./data/体检表.xlsx', sheet_name='Sheet1')
# print(data_xlsx)
# 获取excel表格的行列
row, col = data_xlsx.shape
print(row, col)
# 修改表格中的数据
for i in range(row):
bb = data_xlsx.iloc[i]
print(bb['姓名'], bb['手机号'])
if pd.isnull(bb['手机号']):
bb['手机号'] = '666'
for cc in need_data:
if cc['name'] == bb['姓名']:
bb['手机号'] = cc['phone']
data_xlsx.iloc[i, 3] = bb['手机号']
print(bb['姓名'], bb['手机号'])
print("-" * 100)
print(data_xlsx)
将最终处理好的数据保存在新建的文件中。
# 保存数据到新文件中
data_xlsx.to_excel('./data/new_data.xlsx', sheet_name='Sheet1', index=False, header=True)
完整代码如下:
import pandas as pd
# 读取json中体检信息
with open('./data/physical_examination.json', 'r', encoding='utf-8') as f:
data_json = f.read()
print(data_json)
# 处理json数据中的异常数据
if 'false' in data_json:
data_json = data_json.replace('false', "False")
data_json = eval(data_json)
print(data_json)
print(data_json['hits']['hits'])
print('*' * 100)
valid_data = data_json['hits']['hits']
need_data = []
for data in valid_data:
print(data['_source'])
need_data.append(data['_source'])
print(need_data)
# 读取需要填补数据的表格
data_xlsx = pd.read_excel('./data/体检表.xlsx', sheet_name='Sheet1')
# print(data_xlsx)
# 获取excel表格的行列
row, col = data_xlsx.shape
print(row, col)
# 修改表格中的数据
for i in range(row):
bb = data_xlsx.iloc[i]
print(bb['姓名'], bb['手机号'])
if pd.isnull(bb['手机号']):
bb['手机号'] = '666'
for cc in need_data:
if cc['name'] == bb['姓名']:
bb['手机号'] = cc['phone']
data_xlsx.iloc[i, 3] = bb['手机号']
print(bb['姓名'], bb['手机号'])
print("-" * 100)
print(data_xlsx)
# 保存数据到新文件中
data_xlsx.to_excel('./data/new_data.xlsx', sheet_name='Sheet1', index=False, header=True)
运行效果,最终处理好的数据如下所示:
到此这篇关于Python使用pandas将表格数据进行处理的文章就介绍到这了,更多相关pandas表格数据处理内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!