目录 1.Nuget搜索Tesseract 2.项目安装Tesseract 3.引用命名空间 4.上Github下载别人的训练库 5.选择图片进行识别 1.Nuget搜索Tesseract 2.项目安装Tesseract 3.引用命名空间 using Tesseract; 4.上Github下载别
目录
- 1.Nuget搜索Tesseract
- 2.项目安装Tesseract
- 3.引用命名空间
- 4.上Github下载别人的训练库
- 5.选择图片进行识别
1.Nuget搜索Tesseract
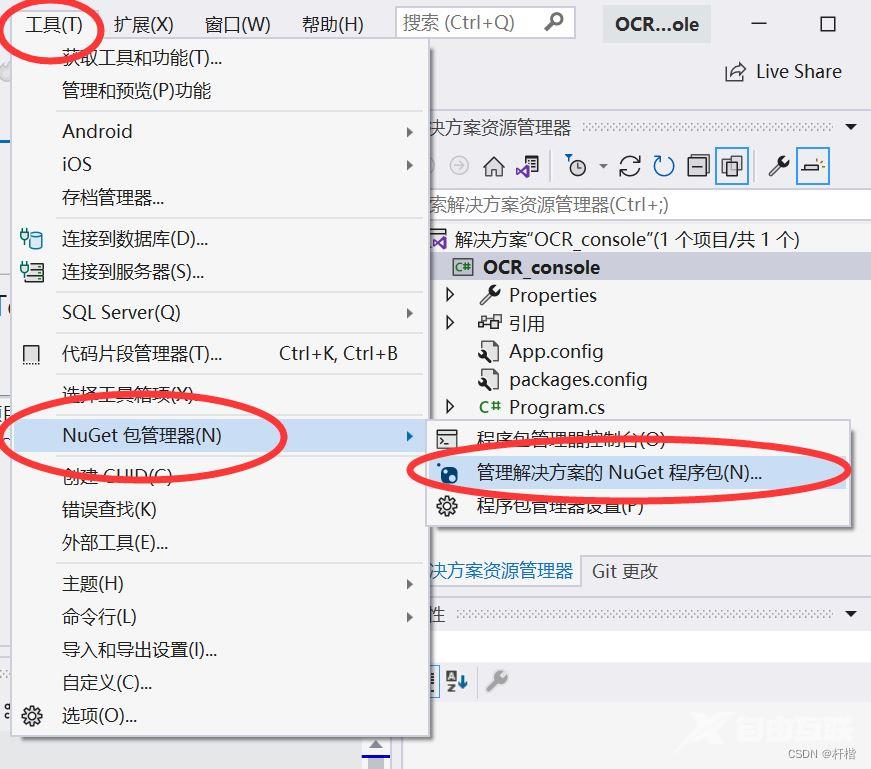
2.项目安装Tesseract

3.引用命名空间
using Tesseract;

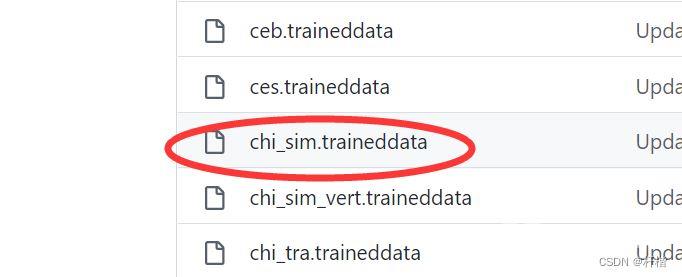
4.上Github下载别人的训练库
https://github.com/tesseract-ocr/tessdata 这里下载中文的chi_sim.traineddata,放到了D盘根目录
5.选择图片进行识别
我把图片命名为image.jpg放在了D盘根目录
//图片文件路径
string imageFileName = @"D:\image.png";
//创建位图对象
Bitmap image = new Bitmap(imageFileName);
//Tesseract.Page
Page page = new TesseractEngine(@"D:\", "chi_sim", EngineMode.Default).Process(PixConverter.ToPix(image));
//释放程序对图片的占用
image.Dispose();
//打印识别率
Console.WriteLine(String.Format("{0:P}", page.GetMeanConfidence()));
//打印识别文本 //替换'/n'为'(空)'//替换'(空格)'为'(空)'
Console.WriteLine(page.GetText().Replace("\n", "").Replace(" ", ""));
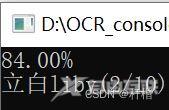
识别率为百分之84,识别文字为立白liby
到此这篇关于C#使用Tesseract进行Ocr识别的方法实现的文章就介绍到这了,更多相关C# Ocr识别内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!