在上一篇文章《驱动开发:内核字符串转换方法》中简单介绍了内核是如何使用字符串以及字符串之间的转换方法,本章将继续探索字符串的拷贝与比较,与应用层不同内核字符串拷贝与比较也需要使用内核专用的API函数,字符串的拷贝往往伴随有内核内存分配,我们将首先简单介绍内核如何分配堆空间,然后再以此为契机简介字符串的拷贝与比较。
首先内核中的堆栈分配可以使用ExAllocatePool()这个内核函数实现,此外还可以使用ExAllocatePoolWithTag()函数,两者的区别是,第一个函数可以直接分配内存,第二个函数在分配时需要指定一个标签,此外内核属性常用的有两种NonPagedPool用于分配非分页内存,而PagePool则用于分配分页内存,在开发中推荐使用非分页内存,因为分页内存数量有限。
内存分配使用ExAllocatePool函数,内存拷贝可使用RtlCopyMemory函数,需要注意该函数其实是对Memcpy函数的包装。
#include <ntifs.h>
VOID UnDriver(PDRIVER_OBJECT driver)
{
DbgPrint("驱动已卸载 \n");
}
// PowerBy: LyShark
NTSTATUS DriverEntry(IN PDRIVER_OBJECT Driver, PUNICODE_STRING RegistryPath)
{
UNICODE_STRING uncode_buffer = { 0 };
DbgPrint("hello lyshark \n");
wchar_t * wchar_string = L"hello lyshark";
// 设置最大长度
uncode_buffer.MaximumLength = 1024;
// 分配内存空间
uncode_buffer.Buffer = (PWSTR)ExAllocatePool(PagedPool, 1024);
// 设置字符长度 因为是宽字符,所以是字符长度的 2 倍
uncode_buffer.Length = wcslen(wchar_string) * 2;
// 保证缓冲区足够大,否则程序终止
ASSERT(uncode_buffer.MaximumLength >= uncode_buffer.Length);
// 将 wchar_string 中的字符串拷贝到 uncode_buffer.Buffer
RtlCopyMemory(uncode_buffer.Buffer, wchar_string, uncode_buffer.Length);
// 设置字符串长度 并输出
uncode_buffer.Length = wcslen(wchar_string) * 2;
DbgPrint("输出字符串: %wZ \n", uncode_buffer);
// 释放堆空间
ExFreePool(uncode_buffer.Buffer);
uncode_buffer.Buffer = NULL;
uncode_buffer.Length = uncode_buffer.MaximumLength = 0;
DbgPrint("驱动已加载 \n");
Driver->DriverUnload = UnDriver;
return STATUS_SUCCESS;
}
代码输出效果:
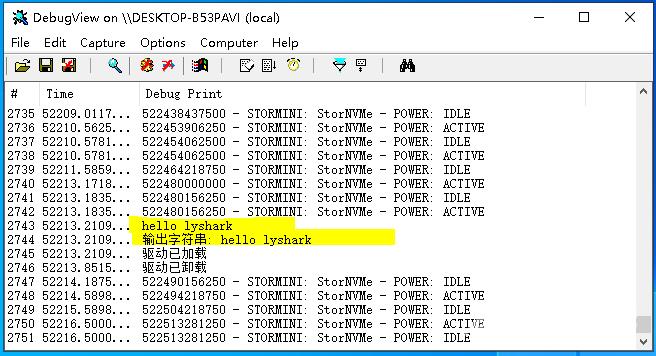
实现空间分配
字符串结构UNICODE_STRING可以定义数组,空间的分配也可以循环进行,例如我们分配十个字符串结构,并输出结构内的参数。
#include <ntifs.h>
VOID UnDriver(PDRIVER_OBJECT driver)
{
DbgPrint("驱动已卸载 \n");
}
// PowerBy: LyShark
NTSTATUS DriverEntry(IN PDRIVER_OBJECT Driver, PUNICODE_STRING RegistryPath)
{
UNICODE_STRING uncode_buffer[10] = { 0 };
wchar_t * wchar_string = L"hello lyshark";
DbgPrint("hello lyshark \n");
int size = sizeof(uncode_buffer) / sizeof(uncode_buffer[0]);
DbgPrint("数组长度: %d \n", size);
for (int x = 0; x < size; x++)
{
// 分配空间
uncode_buffer[x].Buffer = (PWSTR)ExAllocatePool(PagedPool, 1024);
// 设置长度
uncode_buffer[x].MaximumLength = 1024;
uncode_buffer[x].Length = wcslen(wchar_string) * sizeof(WCHAR);
ASSERT(uncode_buffer[x].MaximumLength >= uncode_buffer[x].Length);
// 拷贝字符串并输出
RtlCopyMemory(uncode_buffer[x].Buffer, wchar_string, uncode_buffer[x].Length);
uncode_buffer[x].Length = wcslen(wchar_string) * sizeof(WCHAR);
DbgPrint("循环: %d 输出字符串: %wZ \n", x, uncode_buffer[x]);
// 释放内存
ExFreePool(uncode_buffer[x].Buffer);
uncode_buffer[x].Buffer = NULL;
uncode_buffer[x].Length = uncode_buffer[x].MaximumLength = 0;
}
DbgPrint("驱动加载成功 \n");
Driver->DriverUnload = UnDriver;
return STATUS_SUCCESS;
}
代码输出效果:
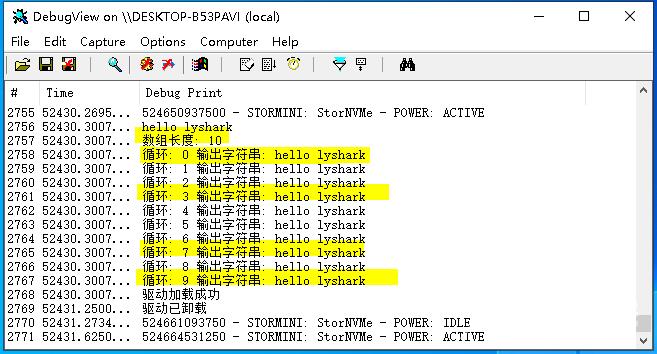
实现字符串拷贝
此处可以直接使用RtlCopyMemory函数直接对内存操作,也可以调用内核提供的RtlCopyUnicodeString函数来实现,具体代码如下。
#include <ntifs.h>
VOID UnDriver(PDRIVER_OBJECT driver)
{
DbgPrint("驱动已卸载 \n");
}
// PowerBy: LyShark
NTSTATUS DriverEntry(IN PDRIVER_OBJECT Driver, PUNICODE_STRING RegistryPath)
{
DbgPrint("hello lyshark \n");
UNICODE_STRING uncode_buffer_source = { 0 };
UNICODE_STRING uncode_buffer_target = { 0 };
// 该函数可用于初始化字符串
RtlInitUnicodeString(&uncode_buffer_source, L"hello lyshark");
// 初始化target字符串,分配空间
uncode_buffer_target.Buffer = (PWSTR)ExAllocatePool(PagedPool, 1024);
uncode_buffer_target.MaximumLength = 1024;
// 将source中的内容拷贝到target中
RtlCopyUnicodeString(&uncode_buffer_target, &uncode_buffer_source);
// 输出结果
DbgPrint("source = %wZ \n", &uncode_buffer_source);
DbgPrint("target = %wZ \n", &uncode_buffer_target);
// 释放空间 source 无需销毁
// 如果强制释放掉source则会导致系统蓝屏,因为source是在栈上的
RtlFreeUnicodeString(&uncode_buffer_target);
DbgPrint("驱动加载成功 \n");
Driver->DriverUnload = UnDriver;
return STATUS_SUCCESS;
}
代码输出效果:
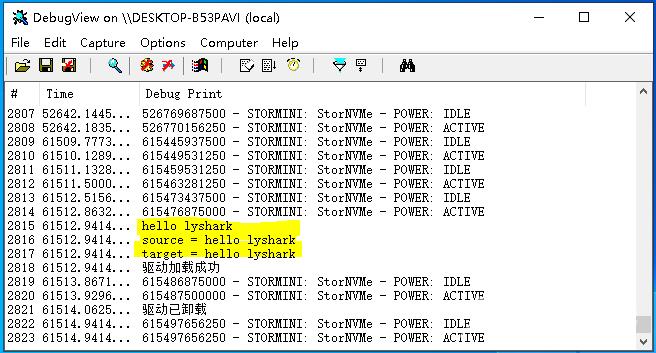
实现字符串比较
如果需要比较两个UNICODE_STRING字符串结构体是否相等,那么可以使用RtlEqualUnicodeString这个内核函数实现,该函数第三个参数是返回值类型,如果是TRUE则默认返回真,否则返回假,具体代码如下。
#include <ntifs.h>
VOID UnDriver(PDRIVER_OBJECT driver)
{
DbgPrint("驱动已卸载 \n");
}
// PowerBy: LyShark
NTSTATUS DriverEntry(IN PDRIVER_OBJECT Driver, PUNICODE_STRING RegistryPath)
{
DbgPrint("hello lyshark \n");
UNICODE_STRING uncode_buffer_source = { 0 };
UNICODE_STRING uncode_buffer_target = { 0 };
// 该函数可用于初始化字符串
RtlInitUnicodeString(&uncode_buffer_source, L"hello lyshark");
RtlInitUnicodeString(&uncode_buffer_target, L"hello lyshark");
// 比较字符串是否相等
if (RtlEqualUnicodeString(&uncode_buffer_source, &uncode_buffer_target, TRUE))
{
DbgPrint("字符串相等 \n");
}
else
{
DbgPrint("字符串不相等 \n");
}
DbgPrint("驱动加载成功 \n");
Driver->DriverUnload = UnDriver;
return STATUS_SUCCESS;
}
代码输出效果:

有时在字符串比较时需要统一字符串格式,例如全部变大写以后在做比较等,此时可以使用RtlUpcaseUnicodeString函数将小写字符串为大写,然后在做比较,代码如下。
#include <ntifs.h>
VOID UnDriver(PDRIVER_OBJECT driver)
{
DbgPrint("驱动已卸载 \n");
}
// PowerBy: LyShark
NTSTATUS DriverEntry(IN PDRIVER_OBJECT Driver, PUNICODE_STRING RegistryPath)
{
DbgPrint("hello lyshark \n");
UNICODE_STRING uncode_buffer_source = { 0 };
UNICODE_STRING uncode_buffer_target = { 0 };
// 该函数可用于初始化字符串
RtlInitUnicodeString(&uncode_buffer_source, L"hello lyshark");
RtlInitUnicodeString(&uncode_buffer_target, L"HELLO LYSHARK");
// 字符串小写变大写
RtlUpcaseUnicodeString(&uncode_buffer_target, &uncode_buffer_source, TRUE);
DbgPrint("小写输出: %wZ \n", &uncode_buffer_source);
DbgPrint("变大写输出: %wZ \n", &uncode_buffer_target);
// 销毁字符串
RtlFreeUnicodeString(&uncode_buffer_target);
DbgPrint("驱动加载成功 \n");
Driver->DriverUnload = UnDriver;
return STATUS_SUCCESS;
}
代码输出效果:
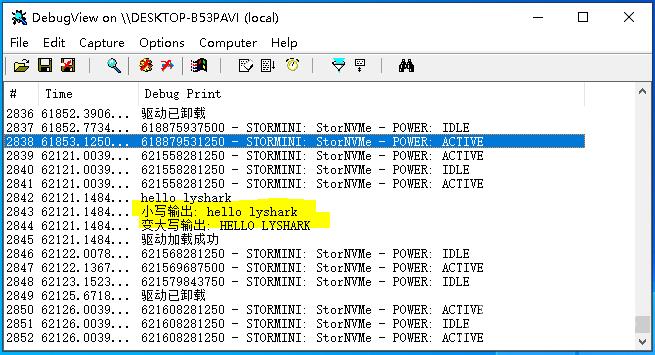
以上就是详解C语言内核字符串拷贝与比较的详细内容,更多关于C语言内核字符串拷贝 比较的资料请关注自由互联其它相关文章!